四、常用并发工具类
在JDK的并发包里提供了几个非常有用的并发容器和并发工具类。供我们在多线程开发中进行使用。
ConcurrentHashMap
在集合类中HashMap是比较常用的集合对象,但是HashMap是线程不安全的(多线程环境下可能会存在问题)。为了保证数据的安全性我们可以使用Hashtable,但是Hashtable的效率低下。
基于以上两个原因我们可以使用JDK1.5以后所提供的ConcurrentHashMap。
点击查看代码
package com.vayne.concurrent;
import java.util.Date;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.concurrent.ConcurrentHashMap;
/**
* @author vayne
* @date 2023-11-03
*/
public class ConcurrentHM {
public static void main(String[] args) throws InterruptedException {
// HashMap<String, String> map = new HashMap<>();
// Hashtable<String, String> map = new Hashtable<>();
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
new Thread(() -> {
for (int i = 0; i < 500; i++) {
map.put(String.valueOf(i),String.valueOf(i));
}
}).start();
new Thread(() -> {
for (int i = 500; i < 1000; i++) {
map.put(String.valueOf(i),String.valueOf(i));
}
}).start();
Thread.sleep(2000);
for(int x = 1 ; x < 1000 ; x++) {
// HashMap中的键就是当前循环变量的x这个数据的字符串表现形式 , 根据键找到值,然后在进行判断
if( !String.valueOf(x).equals( map.get(String.valueOf(x)) ) ) {
System.out.println(x + ":" + map.get(String.valueOf(x)));
}
}
}
}
通过控制台的输出结果,我们可以看到在多线程操作HashMap的时候,可能会出现线程安全问题。
Hashtable保证线程安全的原理:
部分源码:
点击查看代码
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {
// Entry数组,一个Entry就相当于一个元素
private transient Entry<?,?>[] table;
// Entry类的定义
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash; // 当前key的hash码值
final K key; // 键
V value; // 值
Entry<K,V> next; // 下一个节点
}
// 存储数据
public synchronized V put(K key, V value){...}
// 获取数据
public synchronized V get(Object key){...}
// 获取长度
public synchronized int size(){...}
...
}
Hashtable保证线程安全性的是使用方法全局锁进行实现的。在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHash保证线程安全的原理:
jdk1.7版本:
点击查看ConcurrentHash的重要成员变量
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable {
/**
* Segment翻译中文为"段" , 段数组对象
*/
final Segment<K,V>[] segments;
// Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色,将一个大的table分割成多个小的table进行加锁。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile int count; // Segment中元素的数量,由volatile修饰,支持内存可见性;
transient int modCount; // 对table的大小造成影响的操作的数量(比如put或者remove操作);
transient int threshold; // 扩容阈值;
transient volatile HashEntry<K,V>[] table; // 链表数组,数组中的每一个元素代表了一个链表的头部;
final float loadFactor; // 负载因子
}
// Segment中的元素是以HashEntry的形式存放在数组中的,其结构与普通HashMap的HashEntry基本一致,不同的是Segment的HashEntry,其value由 // volatile修饰,以支持内存可见性,即写操作对其他读线程即时可见。
static final class HashEntry<K,V> {
final int hash; // 当前节点key对应的哈希码值
final K key; // 存储键
volatile V value; // 存储值
volatile HashEntry<K,V> next; // 下一个节点
}
}
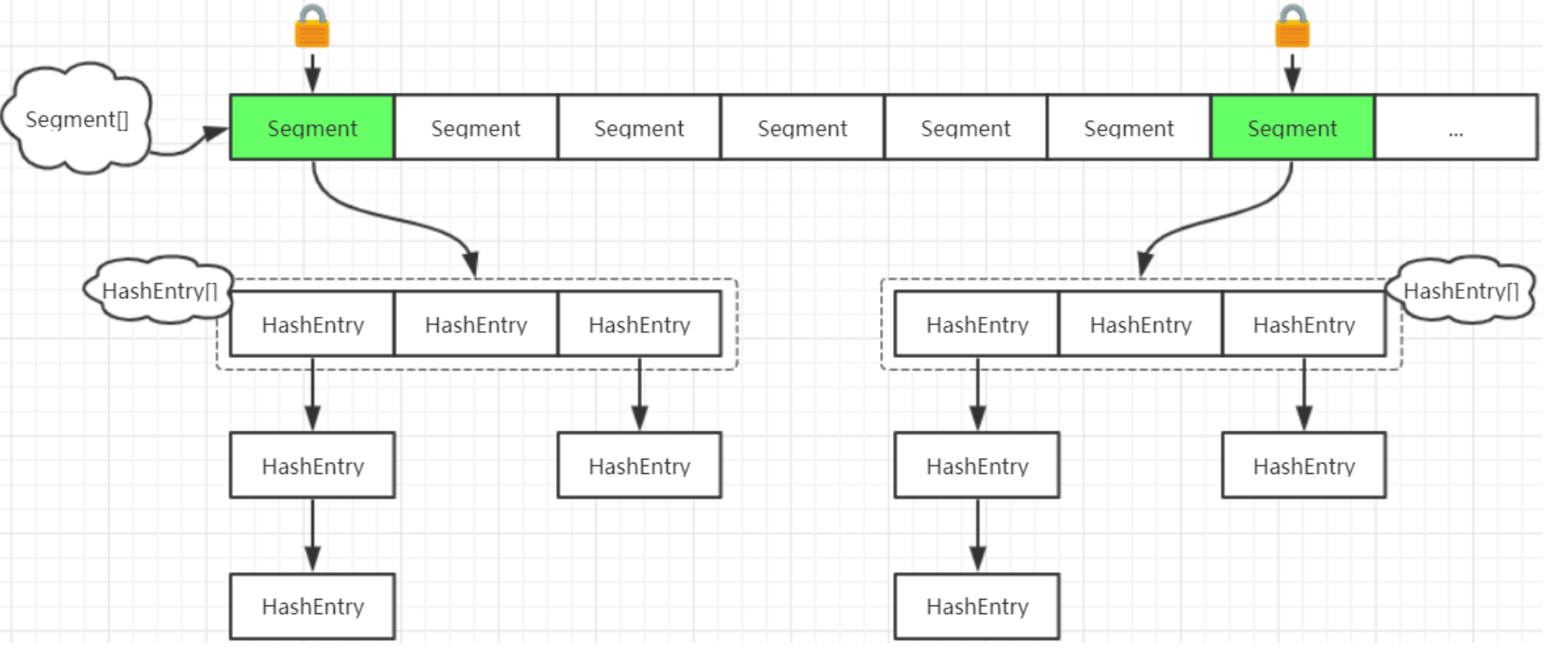
简单来讲,就是ConcurrentHashMap比HashMap多了一次hash过程,第1次hash定位到Segment,第2次hash定位到HashEntry,然后链表搜索找到指定节点。
在进行写操作时,只需锁住写元素所在的Segment即可(这种锁被称为分段锁),其他Segment无需加锁,从而产生锁竞争的概率大大减小,提高了并发读写的效率。
该种实现方式的缺点是hash过程比普通的HashMap要长(因为需要进行两次hash操作)。
点击put方法实现代码
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable {
public V put(K key, V value) {
// 定义一个Segment对象
Segment<K,V> s;
// 如果value的值为空,那么抛出异常
if (value == null) throw new NullPointerException();
// hash函数获取key的hashCode,然后做了一些处理
int hash = hash(key);
// 通过key的hashCode定位segment
int j = (hash >>> segmentShift) & segmentMask;
// 对定位的Segment进行判断,如果Segment为空,调用ensureSegment进行初始化操作(第一次hash定位)
if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
// 调用Segment对象的put方法添加元素
return s.put(key, hash, value, false);
}
// Segment是一种可ReentrantLock,在ConcurrentHashMap里扮演锁的角色,将一个大的table分割成多个小的table进行加锁。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// 添加元素
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 尝试对该段进行加锁,如果加锁失败,则调用scanAndLockForPut方法;在该方法中就要进行再次尝试或者进行自旋等待
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 获取HashEntry数组对象
HashEntry<K,V>[] tab = table;
// 根据key的hashCode值计算索引(第二次hash定位)
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;)
// 若不为null
if (e != null) {
K k;
// 判读当前节点的key是否和链表头节点的key相同(依赖于hashCode方法和equals方法)
// 如果相同,值进行更新
if ((k = e.key) == key || (e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
} else { // 若头结点为null
// 将新节点添加到链表中
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果超过阈值,则进行rehash操作
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
}
}
** jdk1.8版本:**
在JDK1.8中为了进一步优化ConcurrentHashMap的性能,去掉了Segment分段锁的设计。在数据结构方面,则是跟HashMap一样,使用一个哈希表table数组。(数组 + 链表 + 红黑树) 。
而线程安全方面是结合CAS机制 + 局部锁实现的,减低锁的粒度,提高性能。同时在HashMap的基础上,对哈希表table数组和链表节点的value,next指针等使用volatile来修饰,从而实现线程可见性。
ConcurrentHashMap中的重要成员变量:
点击重要成员变量代码
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable {
// Node数组
transient volatile Node<K,V>[] table;
// Node类的定义
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 当前key的hashCode值
final K key; // 键
volatile V val; // 值
volatile Node<K,V> next; // 下一个节点
}
// TreeNode类的定义
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // 父节点
TreeNode<K,V> left; // 左子节点
TreeNode<K,V> right; // 右子节点
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 节点的颜色状态
}
}
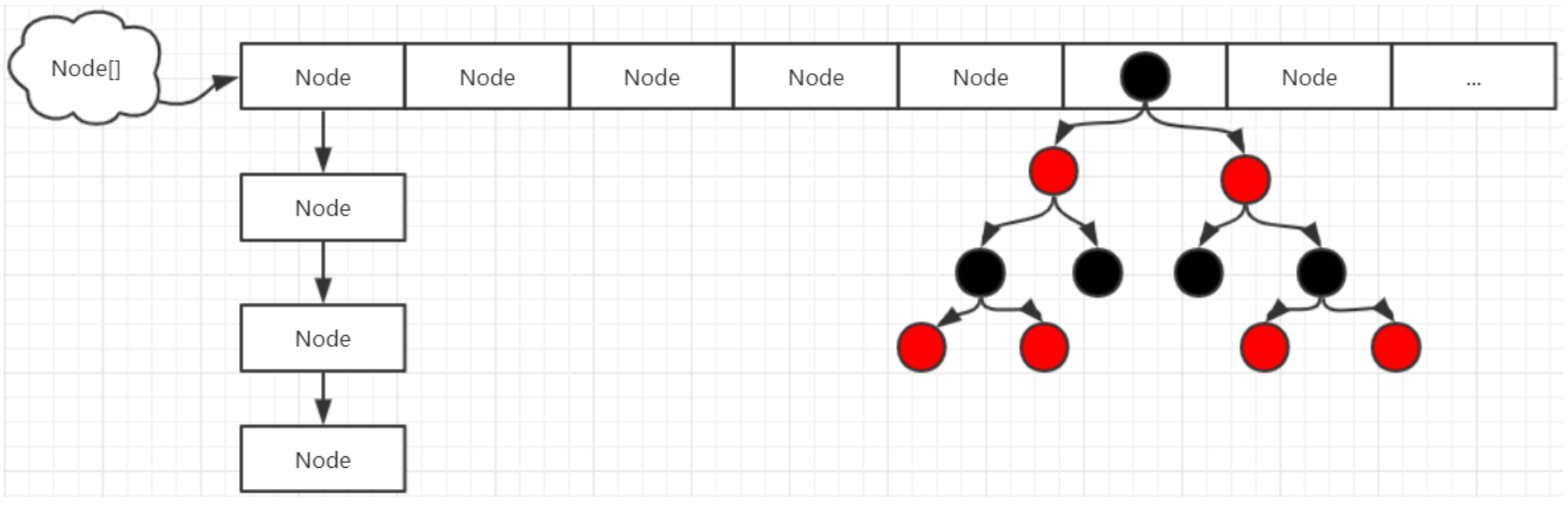
点击put方法代码
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable {
// 添加元素
public V put(K key, V value) {
return putVal(key, value, false);
}
// putVal方法定义
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key为null直接抛出异常
if (key == null || value == null) throw new NullPointerException();
// 计算key所对应的hashCode值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 哈希表如果不存在,那么此时初始化哈希表
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 通过hash值计算key在table表中的索引,将其值赋值给变量i,然后根据索引找到对应的Node,如果Node为null,做出处理
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 新增链表头结点,cas方式添加到哈希表table
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// f为链表头结点,使用synchronized加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 节点已经存在,更新value即可
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 该key对应的节点不存在,则新增节点并添加到该链表的末尾
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
} else if (f instanceof TreeBin) { // 红黑树节点,则往该红黑树更新或添加该节点即可
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 判断是否需要将链表转为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
// CAS算法的核心类
private static final sun.misc.Unsafe U;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
...
} catch (Exception e) {
throw new Error(e);
}
}
// 原子获取链表节点
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// CAS更新或新增链表节点
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
}
-
如果当前需要put的key对应的链表在哈希表table中还不存在,即还没添加过该key的hash值对应的链表,则调用casTabAt方法,基于CAS机制来实现添加该链表头结点到哈希表table中,避免该线程在添加该链表头结的时候,其他线程也在添加的并发问题;如果CAS失败,则进行自旋,通过继续第2步的操作;
-
如果需要添加的链表已经存在哈希表table中,则通过tabAt方法,基于volatile机制,获取当前最新的链表头结点f,由于f指向的是ConcurrentHashMap的哈希表table的某条链表的头结点,故虽然f是临时变量,由于是引用共享的该链表头结点,所以可以使用synchronized关键字来同步多个线程对该链表的访问。在synchronized(f)同步块里面则是与HashMap一样遍历该链表,如果该key对应的链表节点已经存在,则更新,否则在链表的末尾新增该key对应的链表节点。
CountDownLatch
CountDownLatch允许一个或多个线程等待其他线程完成操作以后,再执行当前线程;比如我们在主线程需要开启2个其他线程,当其他的线程执行完毕以后我们再去执行主线程,针对这个需求我们就可以使用CountDownLatch来进行实现。CountDownLatch中count down是倒着数数的意思;CountDownLatch是通过一个计数器来实现的,每当一个线程完成了自己的任务后,可以调用countDown()方法让计数器-1,当计数器到达0时,调用CountDownLatch的await()方法的线程阻塞状态解除,继续执行。
CountDownLatch的相关方法
public CountDownLatch(int count) // 初始化一个指定计数器的CountDownLatch对象
public void await() throws InterruptedException // 让当前线程等待
public void countDown() // 计数器进行减1
点击查看代码
package com.vayne.countdownlatch;
import java.util.concurrent.CountDownLatch;
public class CountDownLatchThread01 implements Runnable {
// CountDownLatch类型成员变量
private CountDownLatch countDownLatch ;
public CountDownLatchThread01(CountDownLatch countDownLatch) { // 构造方法的作用:接收CountDownLatch对象
this.countDownLatch = countDownLatch ;
}
@Override
public void run() {
try {
Thread.sleep(10000);
System.out.println("10秒以后执行了CountDownLatchThread01......");
} catch (InterruptedException e) {
e.printStackTrace();
}
// 调用CountDownLatch对象的countDown方法对计数器进行-1操作
countDownLatch.countDown();
}
}
----------------------------------------------------------------------
package com.vayne.countdownlatch;
import java.util.concurrent.CountDownLatch;
/**
* @author vayne
* @date 2023-11-05
*/
public class CountDownLatchThread02 implements Runnable{
private CountDownLatch countDownLatch ;
public CountDownLatchThread02(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {
Thread.sleep(3000);
System.out.println("3秒后执行了CountDownLatchThread02");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
countDownLatch.countDown();
}
}
------------------------------------------------------------------
package com.vayne.countdownlatch;
import java.util.concurrent.CountDownLatch;
/**
* @author vayne
* @date 2023-11-05
*/
public class Test {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
CountDownLatchThread01 countDownLatchThread01 = new CountDownLatchThread01(countDownLatch);
CountDownLatchThread02 countDownLatchThread02 = new CountDownLatchThread02(countDownLatch);
Thread thread = new Thread(countDownLatchThread01);
Thread thread1 = new Thread(countDownLatchThread02);
thread1.start();
thread.start();
countDownLatch.await();
System.out.println("main线程执行了");
}
}
CountDownLatchThread02线程先执行完毕,此时计数器-1;CountDownLatchThread01线程执行完毕,此时计数器-1;当计数器的值为0的时候,主线程阻塞状态接触,主线程向下执行。
CyclicBarrier
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
例如:公司召集5名员工开会,等5名员工都到了,会议开始。我们创建5个员工线程,1个开会线程,几乎同时启动,使用CyclicBarrier保证5名员工线程全部执行后,再执行开会线程。
CyclicBarrier的相关方法:
public CyclicBarrier(int parties, Runnable barrierAction) // 用于在线程到达屏障时,优先执行barrierAction,方便处理更复杂的业务场景
public int await() // 每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞
案例演示:模拟员工开会
实现步骤:
- 创建一个员工线程类(EmployeeThread),该线程类中需要定义一个CyclicBarrier类型的形式参数
- 创建一个开会线程类(MettingThread)
- 测试类
- 创建CyclicBarrier对象
- 创建5个EmployeeThread线程对象,把第一步创建的CyclicBarrier对象作为构造方法参数传递过来
- 启动5个员工线程
点击案例代码
package com.vayne.cyclicbarrier;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* @author vayne
* @date 2023-11-05
*/
public class EmployeeThread implements Runnable{
private CyclicBarrier cyclicBarrier;
private int time;
public EmployeeThread(CyclicBarrier cyclicBarrier,int time) {
this.cyclicBarrier = cyclicBarrier;
this.time = time;
}
@Override
public void run() {
try {
Thread.sleep(time*1000);
System.out.println(Thread.currentThread().getName() + "在第" + time + "秒到达了会议室等待开会");
cyclicBarrier.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (BrokenBarrierException e) {
throw new RuntimeException(e);
}
}
}
----------------------------------------------------------------
package com.vayne.cyclicbarrier;
/**
* @author vayne
* @date 2023-11-05
*/
public class MettingThread implements Runnable{
@Override
public void run() {
System.out.println("所有人都已经到了,我们开始开会吧!!");
}
}
--------------------------------------------------------------
package com.vayne.cyclicbarrier;
import java.util.concurrent.CyclicBarrier;
/**
* @author vayne
* @date 2023-11-05
*/
public class Test {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(5,new MettingThread());
for (int i = 0; i < 5; i++) {
EmployeeThread employeeThread = new EmployeeThread(cyclicBarrier, i);
new Thread(employeeThread).start();
}
}
}
Semaphore
Semaphore字面意思是信号量的意思,它的作用是控制访问特定资源的线程数目。
举例:现在有一个十字路口,有多辆汽车需要进经过这个十字路口,但是我们规定同时只能有两辆汽车经过。其他汽车处于等待状态,只要某一个汽车经过了这个十字路口,其他的汽车才可以经过,但是同时只能有两个汽车经过。如何限定经过这个十字路口车辆数目呢? 我们就可以使用Semaphore。
Semaphore的常用方法
public Semaphore(int permits) permits 表示许可线程的数量
public void acquire() throws InterruptedException 表示获取许可
public void release() 表示释放许可
案例演示:模拟汽车通过十字路口
实现步骤:
- 创建一个汽车的线程任务类(CarThreadRunnable),在该类中定义一个Semaphore类型的成员变量
- 创建测试类
- 创建线程任务类对象
- 创建5个线程对象,并启动。(5个线程对象,相当于5辆汽车)
点击查看代码
package com.vayne.semaphore;
import java.util.concurrent.Semaphore;
/**
* @author vayne
* @date 2023-11-05
*/
public class CarThreadRunnable implements Runnable{
private Semaphore semaphore;
public CarThreadRunnable(Semaphore semaphore){
this.semaphore = semaphore;
}
@Override
public void run() {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"进入了十字路口");
Thread.sleep(3000);
System.out.println(Thread.currentThread().getName()+"驶离了十字路口");
semaphore.release();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
-----------------------------------------------------------------
package com.vayne.semaphore;
import java.util.concurrent.Semaphore;
/**
* @author vayne
* @date 2023-11-05
*/
public class Test {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(2);
for (int i = 0; i < 5; i++) {
CarThreadRunnable carThreadRunnable = new CarThreadRunnable(semaphore);
new Thread(carThreadRunnable).start();
}
}
}
Exchanger
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。
举例:比如男女双方结婚的时候,需要进行交换结婚戒指。
Exchanger常用方法
public Exchanger() // 构造方法
public V exchange(V x) // 进行交换数据的方法,参数x表示本方数据 ,返回值v表示对方数据
这两个线程通过exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,
将本线程生产出来的数据传递给对方。
案例演示:模拟交互结婚戒指
实现步骤:
- 创建一个男方的线程类(ManThread),定义一个Exchanger类型的成员变量
- 创建一个女方的线程类(WomanThread),定义一个Exchanger类型的成员变量
- 测试类
- 创建一个Exchanger对象
- 创建一个ManThread对象,把第一步所创建的Exchanger作为构造方法参数传递过来
- 创建一个WomanThread对象,把第一步所创建的Exchanger作为构造方法参数传递过来
- 启动两个线程
点击查看代码
package com.vayne.exchange;
import java.util.concurrent.Exchanger;
/**
* @author vayne
* @date 2023-11-05
*/
public class ManThread extends Thread {
private Exchanger exchanger;
public ManThread(Exchanger exchanger) {
this.exchanger = exchanger;
}
@Override
public void run() {
System.out.println("男人掏出了他的戒指");
try {
Object exchange = exchanger.exchange("女生戒指");
System.out.println("男生拿到了"+exchange);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
---------------------------------------------------------------
package com.vayne.exchange;
import java.util.concurrent.Exchanger;
/**
* @author vayne
* @date 2023-11-05
*/
public class WomanThread extends Thread{
private Exchanger exchanger;
public WomanThread(Exchanger exchanger) {
this.exchanger = exchanger;
}
@Override
public void run() {
System.out.println("女人掏出了她的戒指");
try {
Object result = exchanger.exchange("男生戒指");
System.out.println("女生拿到了" + result);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
----------------------------------------------------------
package com.vayne.exchange;
import java.util.concurrent.Exchanger;
/**
* @author vayne
* @date 2023-11-05
*/
public class Test{
public static void main(String[] args) {
Exchanger<String> exchanger = new Exchanger<>();
ManThread manThread = new ManThread(exchanger);
WomanThread womanThread = new WomanThread(exchanger);
manThread.start();
womanThread.start();
}
}
ThreadLocal
线程安全(是指广义上的共享资源访问安全性,因为线程隔离是通过副本保证本线程访问资源安全性,它不保证线程之间还存在共享关系的狭义上的安全性)的解决思路:
- 互斥同步: synchronized 和 ReentrantLock
- 非阻塞同步: CAS, AtomicXXXX
- 无同步方案: 栈封闭,本地存储(Thread Local),可重入代码
这个章节将详细的讲讲 本地存储(Thread Local)。官网的解释是这样的:
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own, independently initialized copy of the variable. {@code ThreadLocal} instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID) 该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal 实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。
总结而言:ThreadLocal是一个将在多线程中为每一个线程创建单独的变量副本的类; 当使用ThreadLocal来维护变量时, ThreadLocal会为每个线程创建单独的变量副本, 避免因多线程操作共享变量而导致的数据不一致的情况。
提到ThreadLocal被提到应用最多的是session管理和数据库链接管理,这里以数据访问为例帮助你理解ThreadLocal:
点击查看代码
class ConnectionManager {
private static Connection connect = null;
public static Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public static void closeConnection() {
if (connect != null)
connect.close();
}
}
很显然,在多线程中使用会存在线程安全问题:
第一,这里面的2个方法都没有进行同步,很可能在openConnection方法中会多次创建connect;
第二,由于connect是共享变量,那么必然在调用connect的地方需要使用到同步来保障线程安全,因为很可能一个线程在使用connect进行数据库操作,而另外一个线程调用closeConnection关闭链接。
为了解决上述线程安全的问题,第一考虑:互斥同步你可能会说,将这段代码的两个方法进行同步处理,并且在调用connect的地方需要进行同步处理,比如用Synchronized或者ReentrantLock互斥锁。
这里再抛出一个问题:这地方到底需不需要将connect变量进行共享?事实上,是不需要的。假如每个线程中都有一个connect变量,各个线程之间对connect变量的访问实际上是没有依赖关系的,即一个线程不需要关心其他线程是否对这个connect进行了修改的。即改后的代码可以这样:
点击查看代码
class ConnectionManager {
private Connection connect = null;
public Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public void closeConnection() {
if (connect != null)
connect.close();
}
}
class Dao {
public void insert() {
ConnectionManager connectionManager = new ConnectionManager();
Connection connection = connectionManager.openConnection();
// 使用connection进行操作
connectionManager.closeConnection();
}
}
这样处理确实也没有任何问题,由于每次都是在方法内部创建的连接,那么线程之间自然不存在线程安全问题。但是这样会有一个致命的影响:导致服务器压力非常大,并且严重影响程序执行性能。
由于在方法中需要频繁地开启和关闭数据库连接,这样不仅严重影响程序执行效率,还可能导致服务器压力巨大。
那么这种情况下使用ThreadLocal是再适合不过的了,因为ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。下面就是网上出现最多的例子:
点击查看代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class ConnectionManager {
private static final ThreadLocal<Connection> dbConnectionLocal = new ThreadLocal<Connection>() {
@Override
protected Connection initialValue() {
try {
return DriverManager.getConnection("", "", "");
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
};
public Connection getConnection() {
return dbConnectionLocal.get();
}
}
注意下ThreadLocal的修饰符
ThreaLocal的JDK文档中说明:ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread。如果我们希望通过某个类将状态(例如用户ID、事务ID)与线程关联起来,那么通常在这个类中定义private static类型的ThreadLocal 实例。
Threadlocal原理
ThreadLocal如何实现的线程隔离呢?
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap threadLocals = getMap(t);
if (threadLocals != null) {
ThreadLocalMap.Entry e = threadLocals.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
我们观察ThreadLocal的核心方法set发现:
-
首先获取当前线程对象t, 然后从线程t中获取到ThreadLocalMap的成员属性threadLocals
-
如果当前线程的threadLocals已经初始化(即不为null) 并且存在以当前ThreadLocal对象为Key的值, 则直接返回当前线程要获取的对象(本例中为Connection);
-
如果当前线程的threadLocals已经初始化(即不为null)但是不存在以当前ThreadLocal对象为Key的的对象, 那么重新创建一个Connection对象, 并且添加到当前线程的threadLocals Map中,并返回
-
如果当前线程的threadLocals属性还没有被初始化, 则重新创建一个ThreadLocalMap对象, 并且创建一个Connection对象并添加到ThreadLocalMap对象中并返回。
如果存在则直接返回很好理解, 那么对于如何初始化的代码又是怎样的呢?
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
-
首先调用我们上面写的重载过后的initialValue方法, 产生一个Connection对象
-
继续查看当前线程的threadLocals是不是空的, 如果ThreadLocalMap已被初始化, 那么直接将产生的对象添加到ThreadLocalMap中, 如果没有初始化, 则创建并添加对象到其中;
同时, ThreadLocal还提供了直接操作Thread对象中的threadLocals的方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
这样我们也可以不实现initialValue, 将初始化工作放到DBConnectionFactory的getConnection方法中:
public Connection getConnection() {
Connection connection = dbConnectionLocal.get();
if (connection == null) {
try {
connection = DriverManager.getConnection("", "", "");
dbConnectionLocal.set(connection);
} catch (SQLException e) {
e.printStackTrace();
}
}
return connection;
}
那么我们看过代码之后就很清晰的知道了为什么ThreadLocal能够实现变量的多线程隔离了; 其实就是用了Map的数据结构给当前线程缓存了, 要使用的时候就从本线程的threadLocals对象中获取就可以了, key就是当前线程;
当然了在当前线程下获取当前线程里面的Map里面的对象并操作肯定没有线程并发问题了, 当然能做到变量的线程间隔离了;
现在我们知道了ThreadLocal到底是什么了, 又知道了如何使用ThreadLocal以及其基本实现原理了是不是就可以结束了呢? 其实还有一个问题就是ThreadLocalMap是个什么对象, 为什么要用这个对象呢?
ThreadLocalMap
本质上来讲, 它就是一个Map, 但是这个ThreadLocalMap与我们平时见到的Map有点不一样
- 它没有实现Map接口;
- 它没有public的方法, 最多有一个default的构造方法, 因为这个ThreadLocalMap的方法仅仅3. 在ThreadLocal类中调用, 属于静态内部类
- ThreadLocalMap的Entry实现继承了WeakReference<ThreadLocal<?>>
- 该方法仅仅用了一个Entry数组来存储Key, Value; Entry并不是链表形式, 而是每个bucket里面仅仅放一个Entry;
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
// 获取线程本地存储表的引用,并根据key的哈希码和表长度计算槽位位置i
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 遍历槽位位置i及其后续位置的条目,直到到达表末尾,然后从表头再开始
ThreadLocal<?> k = e.get();
// 获取当前条目的key
if (k == key) {
// 如果当前条目的key与指定的key相等
e.value = value;
// 更新条目的value
return;
}
if (k == null) {
// 如果当前条目的key为空
replaceStaleEntry(key, value, i);
// 替换为新的条目
return;
}
}
tab[i] = new Entry(key, value);
// 在槽位位置i创建新的条目
int sz = ++size;
// 更新条目数量
if (!cleanSomeSlots(i, sz) && sz >= threshold)
// 检查是否需要清理槽位并重新哈希
rehash();
}
先进行简单的分析, 对该代码表层意思进行解读:
-
看下当前threadLocal的在数组中的索引位置 比如: i = 2, 看 i = 2 位置上面的元素(Entry)的Key是否等于threadLocal 这个 Key, 如果等于就很好说了, 直接将该位置上面的Entry的Value替换成最新的就可以了;
-
如果当前位置上面的 Entry 的 Key为空, 说明ThreadLocal对象已经被回收了, 那么就调用replaceStaleEntry
-
如果清理完无用条目(ThreadLocal被回收的条目)、并且数组中的数据大小 > 阈值的时候对当前的Table进行重新哈希 所以, 该HashMap是处理冲突检测的机制是向后移位, 清除过期条目 最终找到合适的位置;
ThreadLocal造成内存泄露的问题
网上有一个栗子:
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadLocalDemo {
static class LocalVariable {
private Long[] a = new Long[1024 * 1024];
}
// (1)
final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>());
// (2)
final static ThreadLocal<LocalVariable> localVariable = new ThreadLocal<LocalVariable>();
public static void main(String[] args) throws InterruptedException {
// (3)
Thread.sleep(5000 * 4);
for (int i = 0; i < 50; ++i) {
poolExecutor.execute(new Runnable() {
public void run() {
// (4)
localVariable.set(new LocalVariable());
// (5)
System.out.println("use local varaible" + localVariable.get());
localVariable.remove();
}
});
}
// (6)
System.out.println("pool execute over");
}
}
如果用线程池来操作ThreadLocal 对象确实会造成内存泄露, 因为对于线程池里面不会销毁的线程, 里面总会存在着<ThreadLocal, LocalVariable>的强引用, 因为final static 修饰的 ThreadLocal 并不会释放, 而ThreadLocalMap 对于 Key 虽然是弱引用, 但是强引用不会释放, 弱引用当然也会一直有值, 同时创建的LocalVariable对象也不会释放, 就造成了内存泄露; 如果LocalVariable对象不是一个大对象的话, 其实泄露的并不严重, 泄露的内存 = 核心线程数 * LocalVariable对象的大小;所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法
那么如何优雅的进行remove方法,从而避免由于忘记remove而导致的OOM内存泄漏,其实我们可以在企业开发中借助对应的AOP切面编程或者Filter或Interceptor,完成优雅的remove。
ThreadLocal应用场景
除了上述的数据库管理类的例子,我们再看看其它一些应用:
每个线程维护了一个“序列号”:
public class SerialNum {
// The next serial number to be assigned
private static int nextSerialNum = 0;
private static ThreadLocal serialNum = new ThreadLocal() {
protected synchronized Object initialValue() {
return new Integer(nextSerialNum++);
}
};
public static int get() {
return ((Integer) (serialNum.get())).intValue();
}
}
Session的管理:
private static final ThreadLocal threadSession = new ThreadLocal();
public static Session getSession() throws InfrastructureException {
Session s = (Session) threadSession.get();
try {
if (s == null) {
s = getSessionFactory().openSession();
threadSession.set(s);
}
} catch (HibernateException ex) {
throw new InfrastructureException(ex);
}
return s;
}
使用场景:在线程内部创建ThreadLocal
还有一种用法是在线程类内部创建ThreadLocal,基本步骤如下:
在多线程的类(如ThreadDemo类)中,创建一个ThreadLocal对象threadXxx,用来保存线程间需要隔离处理的对象xxx。
在ThreadDemo类中,创建一个获取要隔离访问的数据的方法getXxx(),在方法中判断,若ThreadLocal对象为null时候,应该new()一个隔离访问类型的对象,并强制转换为要应用的类型。
在ThreadDemo类的run()方法中,通过调用getXxx()方法获取要操作的数据,这样可以保证每个线程对应一个数据对象,在任何时刻都操作的是这个对象。
public class ThreadLocalTest implements Runnable{
ThreadLocal<Student> StudentThreadLocal = new ThreadLocal<Student>();
@Override
public void run() {
String currentThreadName = Thread.currentThread().getName();
System.out.println(currentThreadName + " is running...");
Random random = new Random();
int age = random.nextInt(100);
System.out.println(currentThreadName + " is set age: " + age);
Student Student = getStudentt(); //通过这个方法,为每个线程都独立的new一个Studentt对象,每个线程的的Studentt对象都可以设置不同的值
Student.setAge(age);
System.out.println(currentThreadName + " is first get age: " + Student.getAge());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println( currentThreadName + " is second get age: " + Student.getAge());
}
private Student getStudentt() {
Student Student = StudentThreadLocal.get();
if (null == Student) {
Student = new Student();
StudentThreadLocal.set(Student);
}
return Student;
}
public static void main(String[] args) {
ThreadLocalTest t = new ThreadLocalTest();
Thread t1 = new Thread(t,"Thread A");
Thread t2 = new Thread(t,"Thread B");
t1.start();
t2.start();
}
}
class Student{
int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}