前言 小目标检测需要检测头扫描图像特征图上的大量位置,这对于计算和节能的轻量化通用检测器来说是非常困难的。为了在有限的计算量下准确检测小目标,本文提出了一种计算复杂度极低的两阶段轻量级检测框架,称为TinyDet。它能够实现用于密集Anchor的高分辨率特征图,以更好地覆盖小目标,作者提出了用于减少计算的稀疏连接卷积,增强了主干中的早期特征,并解决了用于精确小目标检测的特征错位问题。
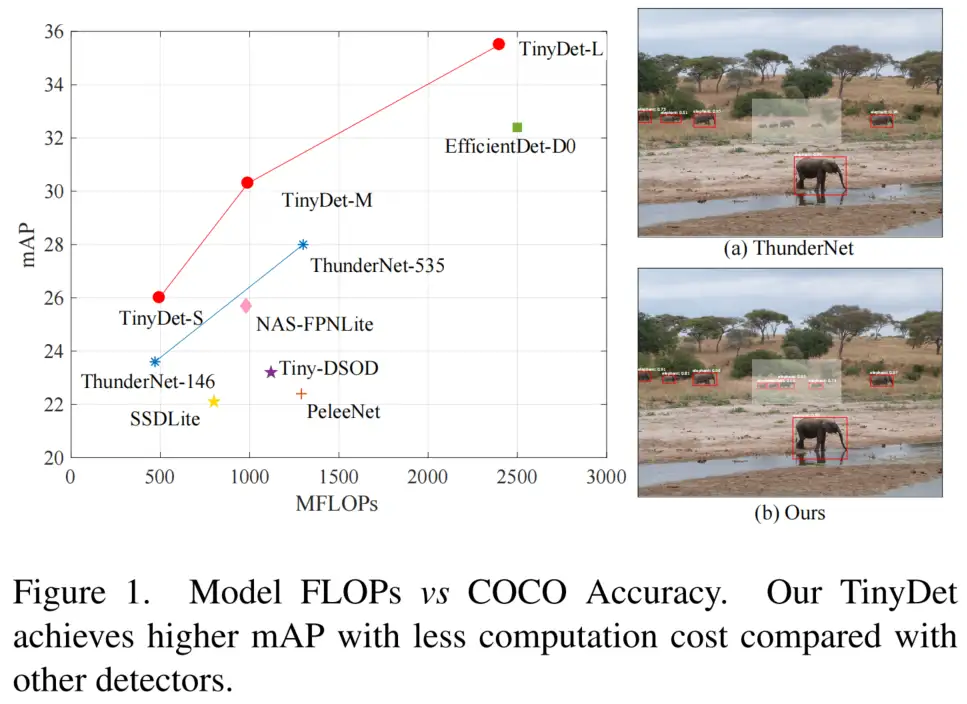
在COCO基准上,TinyDet-M实现了30.3AP,并且只有991MFLOP,这是第1个AP超过30,FLOP小于1GFLOP的检测器;此外,TinyDet-S和TinyDet-L在不同的计算限制下都取得了很好的性能。
本文转载自集智书童
作者 | 小书童
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

Github:https://github.com/hustvl/TinyDet
1、简介
目标检测在计算机视觉中发挥着重要作用,并逐渐成为自动驾驶、遥感和视频监控等许多应用的技术基础。然而,高级检测模型的推理过程需要花费大量的计算资源,这使得它们很难应用于资源受限的移动或边缘设备。
为了广泛应用人工智能,计算高效、节能的“微小人工智能”模型越来越受欢迎。本文中设计了一个轻量级的通用目标检测框架,称为TinyDet,用于高效准确的目标检测,尤其是小目标,计算成本低。
近年来,为了在计算成本和精度之间更好地进行权衡,已经提出了许多创新的、具有代表性的轻量级检测模型。为了降低计算成本,通常以较大的比例缩小输入图像,并在小的特征图上执行目标检测。
例如,Pelee采用304×304输入,并且Pelee中用于检测的最大特征图是19×19。ThunderNet采用320×320输入,仅使用分辨率为20×20的单个特征图进行检测。相比之下,像具有特征金字塔网络(FPN)的Faster R-CNN这样的大型模型需要800×1333的输入,最大的特征图大到200×333。
利用小的输入图像和小的特征图进行目标检测有助于降低计算成本。然而,小的特征图没有详细的信息,位置分辨率也很差。以前的轻量化检测器检测小目标的能力非常有限。它们牺牲了对小目标的检测性能以获得高效率。
检测小目标的能力对于基于目标检测的应用非常重要,并且是评估目标检测模型的关键因素。如COCO数据集所示,大约41%的目标较小(面积<322)。
本文的目标是提高轻量级通用检测网络中的小目标检测性能。基于设计轻量级网络的良好实践,作者提出了TinyDet,这是一种具有高分辨率(HR)特征图的两阶段检测器,用于密集Anchor。HR特征图显著提高了小目标的检测能力,但也带来了更多的计算成本。
为了解决分辨率和计算之间的矛盾,作者通过引入稀疏连接卷积(SCConv)提出了TinyFPN和TinyRPN,该卷积既保持了高分辨率又保持了低计算量。作者还改进了骨干网络,以获得更好的小目标检测性能。小目标检测更多地依赖于浅层特征中的详细信息。通过为早期阶段分配更多的计算来保留更详细的信息。
此外,作者观察到在轻量化检测器中存在严重的特征错位。特征错位逐层累积并传递到检测部分,影响RPN和RCNN Head的回归精度。小目标对这种位置错位更加敏感。通过消除错位,可以显著提高小目标的检测性能。
本文的贡献可以概括为:
- 在轻量级检测网络中,首次启用高分辨率检测特征图(即80×80)进行密集Anchor,这对于检测小目标至关重要;
- 提出了具有稀疏连接卷积的TinyFPN和TinyRPN,以使用高分辨率检测特征图执行高效的目标检测;
- 通过增强Backbone的早期阶段并解决TinyDet中的错位问题,进一步提高了小目标的检测结果;
- TinyDet模型在COCO test-dev2017集合上具有强大的性能和很少的计算预算,如图1所示。TinyDet-M仅用991 MFLOP就实现了30.3 mAP,这是轻量级检测器中最先进的结果。值得注意的是,小目标检测性能出众,TinyDet-S和TinyDet-M的AP是ThunderNets的两倍。
2、相关工作
2.1、Lightweight Object Detector
近年来,用于通用目标检测的轻量级模型得到了快速发展。首先,轻量级分类网络设计方法的进步直接推动了轻量级目标检测的发展。轻量级分类网络通常被直接用作检测器的主干来提取特征,例如,手工设计的MobileNetV2被用于SSLite,搜索到的神经架构EfficientNet被用于EfficientDet。但检测和分类需要不同的主干。
为了更好地匹配检测任务的特征,在许多轻量级检测器中,基于现有的分类网络,提出了专门的骨干。其次,开发良好的目标检测管道也为轻量化检测器的研究奠定了坚实的基础。
大多数轻量化检测器采用紧凑的单阶段结构。PeleeNet只使用传统卷积构建,而不使用流行的移动卷积。RefineDetLite专门为CPU设备设计。EfficientDet提出了一种加权双向特征金字塔网络,用于快速的特征融合,并在广泛的资源约束下构建了一种可扩展的检测架构。
具有更复杂Pipeline的两阶段检测器通常被认为在推理阶段更耗时。然而,一些人证明,如果第二阶段足够轻,两阶段检测器也可以像单阶段检测器一样高效。两阶段范式在检测小目标方面往往表现得更好。因此,本文遵循两阶段范式,通过考虑效率和准确性来设计检测器。
2.2、Small Object Detection
从视频和图像中检测小目标在计算机视觉、遥感、自动驾驶等领域备受关注。Liu等人通过缩小大目标的尺寸,创建了更多的小目标训练示例。D-SSD、C-SSD、F-SSD和ION专注于为小目标检测构建适当的上下文特征。Hu等人使用粗略的图像金字塔,并使用两次上采样的输入图像来检测小人脸。
也有一些研究使用生成对抗性网络(GAN)生成用于小目标检测的超分辨特征。更大的输入分辨率和超分辨率方法带来了更多的计算成本,并且不适合于轻量级检测器的设计。
本文的工作与高分辨率网络(HRNet)略有关联,它在整个网络中为位置敏感的视觉识别任务保持高分辨率表示。作者发现,没有论文专注于在轻量级通用检测器中检测小目标。在本文中以精确的小目标检测为目标,同时保持较低的计算预算。
2.3、稀疏卷积
在设计轻量级检测网络时,减少深度卷积神经网络中的冗余是一个重要的探索方向。许多先前的工作致力于通过使卷积中的连接更稀疏来减少冗余。Liu等人采用稀疏分解得到稀疏卷积网络,降低了计算复杂度。
深度可分离卷积是一种因子分解卷积,被广泛用于减少计算和模型大小。并且在ShufflfleNet中使用了组卷积来进行有效的模型设计。本文的工作以一种新颖的形式将深度卷积和组卷积相结合,以构建极其轻量级的FPN和RPN。
3、本文方法
在本节中将详细介绍TinyDet的设计,并说明一个具有低FLOPs的通用检测器如何执行精确的小目标检测。作者遵循两阶段检测范式,它对小目标检测更友好。
该检测器包含4个部分:增强的Backbone、TinyFPN、TinyRPN和R-CNN Head。为清晰起见,在本节中只提供了TinyDet-M的细节,并在附录中留下了TinyDet-S和TinyDet-L的细节。
3.1、Backbone
1、详细的信息增强
Backbone中具有高分辨率的早期特征图包含丰富的详细信息,这对于识别和定位小目标至关重要。现有的轻量级Backbone网络通常会快速下采样特征图,从而在高分辨率阶段保留较少的层和通道。此方法可以很好的最小化计算复杂度,但也牺牲了许多特征信息。
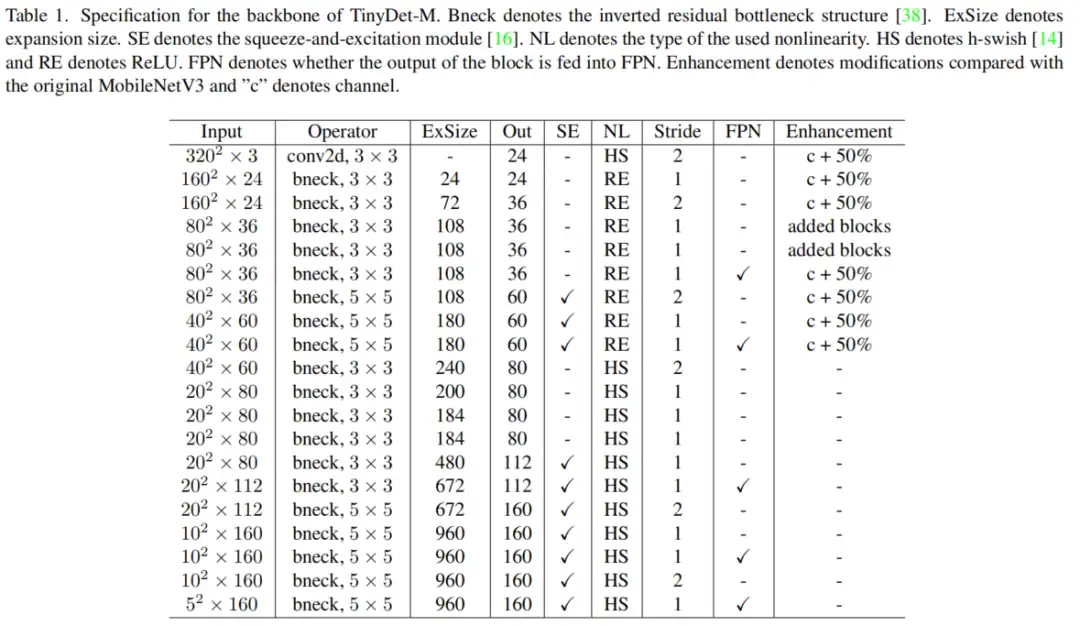
为了提高检测小目标的性能,作者提出了一种基于高性能网络的详细信息增强Backbone MobileNetV3。表1显示了详细的网络配置。与其他广泛使用的轻量级Backbone网络相比,在早期阶段分配了更多的计算,分辨率更高。通过这种设计,可以提取并保存更详细的信息,用于检测小目标。
2、解决特征对齐问题
stride为2的卷积被广泛用于降低特征图的分辨率。在检测中,甚至输入分辨率也是一种常见的做法。由于奇数输入像素破坏了不同金字塔级别之间的比例关系,使得输入和输出之间的坐标映射变得复杂。然而,即使在输入分辨率上的stride卷积也可能导致特征错位。
如图2(a)所示,考虑到步长为2且输入分辨率为偶数的卷积层,在卷积计算过程中,忽略一个填充像素,导致空间不对称和0.5个像素的特征错位。由几个stride卷积引起的特征失准在整个网络中逐层累积,并在更高级别变得更加显著。
对于具有高输入分辨率的大型模型,错位可以忽略不计,但对于具有低分辨率的轻量化检测器,错位是显著的。它严重降低了性能。RoI Pooling/Align 操作将为每个目标Proposal提取未对齐的特征。小目标检测需要更精确的定位,并且受到的影响更大。
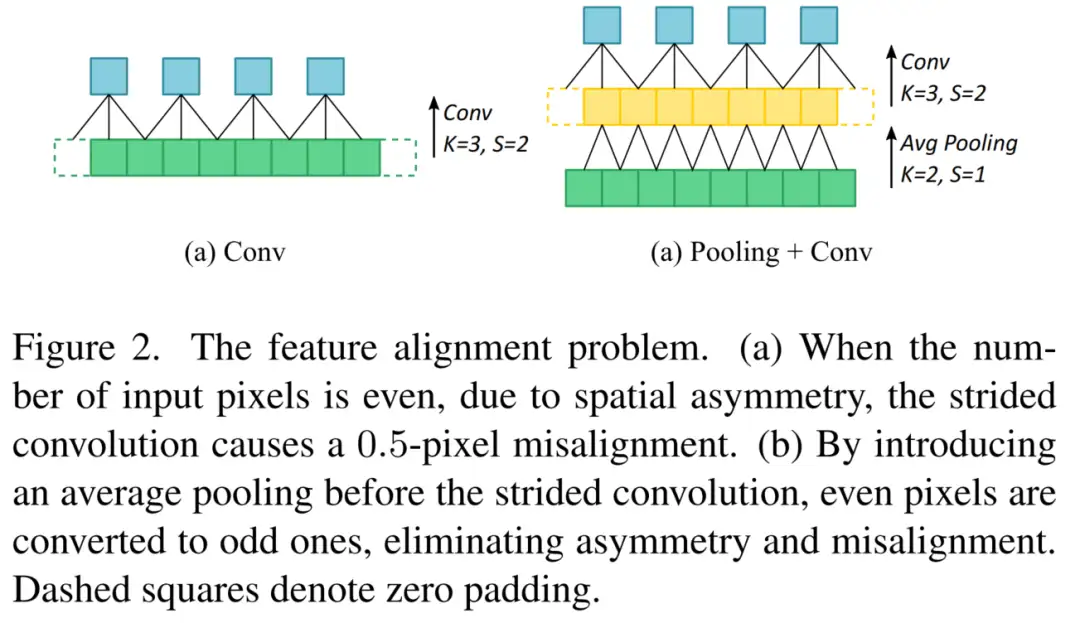
为了缓解TinyDet中的特征错位,作者在每个Stride卷积之前采用平均池化层。如图2(b)所示,平均池化操作将偶数像素转换为奇数像素,避免了Stride卷积中的不对称性,并校正了未对准的问题。在优化网络时,可以将相邻的卷积层和平均池化层融合为一个层,以提高推理效率。
特征偏差的理论计算
作者提供了由Stride卷积引起的特征错位的理论计算。对于Stride为2的卷积,假设kernel大小为k,padding大小为,并且与输入图像相比,输入特征图的Stride为s。如图2(a)所示,一个填充像素被丢弃,特征中心被移动0.5个像素。当映射到输入图像时,未对准为s/2像素。特征错位会影响后续层,并逐层累积。
在TinyDet中,Backbone网络中存在6个Stride卷积层,分别导致0.5、1、2、4、8、16个像素的错位。在FPN和RPN中,累积的未对准多达31.5个像素。对于输入尺寸较小的轻量化检测器来说,错位是非常显著的。考虑到320×320的输入分辨率,错位比例高达31.5/320≈9.8%,这导致了特征与其空间位置之间的严重失配。
有效感受野的可视化
为了更好地证明特征错位的影响,作者采用有效感受野(ERF)图来可视化特征图的错位。

如图3(a)所示,可以观察到ERF明显偏离了相应Anchor的几何中心。RPN中的像素级预测和R-CNN中的基于区域的特征提取将基于未对准的特征。通过应用平均池化层,消除了错位(图3(b))。
3.2、TinyFPN and TinyRPN
1、高分辨率检测特征图
在计算成本的限制下,以前的轻量级检测器通常采用低分辨率的特征图进行检测(SSDLite中为38×38,Pelee中为19×19,ThunderNet中为20×20)。然而,小型特征图的空间分辨率较低。低分辨率特征图无法为位于任意位置的目标提供空间匹配的特征,尤其是对于小目标。
在本文中实现了对高分辨率特征图的目标检测。从Backbone提取5个特征图进行检测,分别具有步长4、8、16、32和64。
请注意,Stride为4的特征图的分辨率为80×80,这是轻量级检测器中使用的最高分辨率特征图。有关高分辨率设置重要性的更多分析,请参见第3.3节。
2、用于计算缩减的稀疏连接卷积
由于高分辨率的设计,检测部分的计算预算变得非常高。尽管深度可分离卷积已被广泛用于现有轻量级检测器的检测部件设计,以降低计算成本,但作者发现它在高分辨率设置中是不够的。因此,利用稀疏连接卷积(SCConv),专门用于FPN和RPN中的效率和高分辨率。
如图4所示,SCConv是depth-wise卷积和point-wise group 卷积的组合。与普通深度可分离卷积相比,SCConv进一步减少了通道之间的连接。第4.3节中的实验表明,这种稀疏设置对检测性能的影响很小,并大大降低了计算成本。

作者基于SCConv提出了TinyFPN和TinyRPN。在TinyFPN中(图4),SCConv在特征融合后应用,代替正常的3×3卷积。为高分辨率金字塔级别的SCConv设置了更大的组号,即更稀疏的连接,以降低计算成本。
TinyRPN(图4)由一个SCConv和2个并行的1×1卷积组成,分别用于分类和回归。TinyRPN的参数在所有金字塔级别上共享。第4.3节提供了关于SCConvs组设置的消融研究。
3.3、用于密集Anchoring的高分辨率特征图
Translation方差是目标检测中的一个挑战。检测器应该对平移不敏感,并处理位于任意位置的目标。Anchor的引入缓解了目标检测中的Translation方差问题。大量Anchor在整个图像上均匀平铺,每个Anchor只负责预测出现在某个区域中的目标,该区域被定义为响应区域。在训练过程中,根据目标的IOU和分配策略将目标分配给Anchor。然而,当Anchor的空间密度不够时,在Anchor的分配过程中会出现两个问题,如下所述。
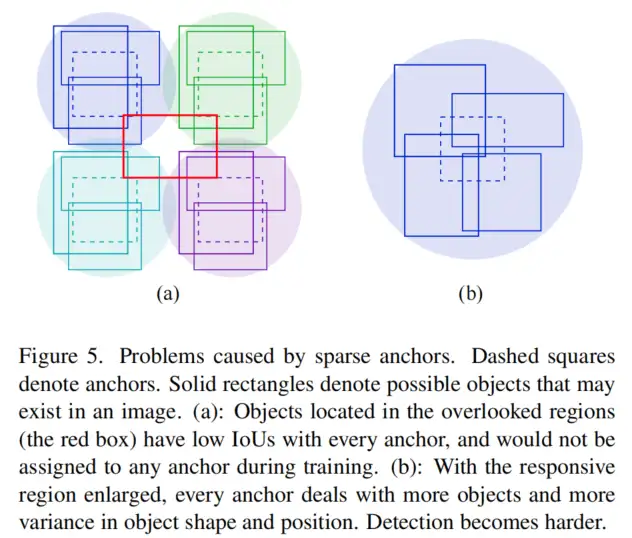
- 在分配IoU阈值固定的情况下,响应区域是固定的。如图5(a)所示,当Anchor不够密集时,响应区域无法覆盖整个图像。这里把未被覆盖的区域称为被忽视的区域。在训练过程中,位于被忽视区域的目标,尤其是小目标,永远不会分配给任何Anchor。因此,在推断阶段,由于这里缺乏Anchor,这些目标不太可能被检测到。
- 如果降低分配IoU阈值,响应区域会扩大,而被忽略的区域会缩小甚至消失。但是扩大的响应区域使得检测器很难获得准确的结果。每个Anchor处理更多的目标以及目标形状和位置的更多变化,如图5(b)所示。
如上所述,Anchor密度应该足够高以覆盖可能的目标。因此,在TinyDet中,保留高分辨率的特征图以进行密集Anchor定。为了了解密集Anchor冲击检测性能,特别是对小目标的检测性能,将TinyDet与ThunderNet进行了比较。

在图6中可视化了最小Anchor的分布。在ThunderNet中,相邻Anchor之间的距离为16个像素。很难在空间上将小目标与Anchor进行匹配。而TinyDet中的像素只有4个像素。密集平铺的Anchor可以更好地覆盖小目标。
从数量上讲,提出了GT误判率(GTMR)来评估赋值过程。GTMR被定义为未被分配给任何Anchor的那些GT目标在所有目标中的比例。它反映了在一定的分配策略下Anchor和目标之间的匹配质量。
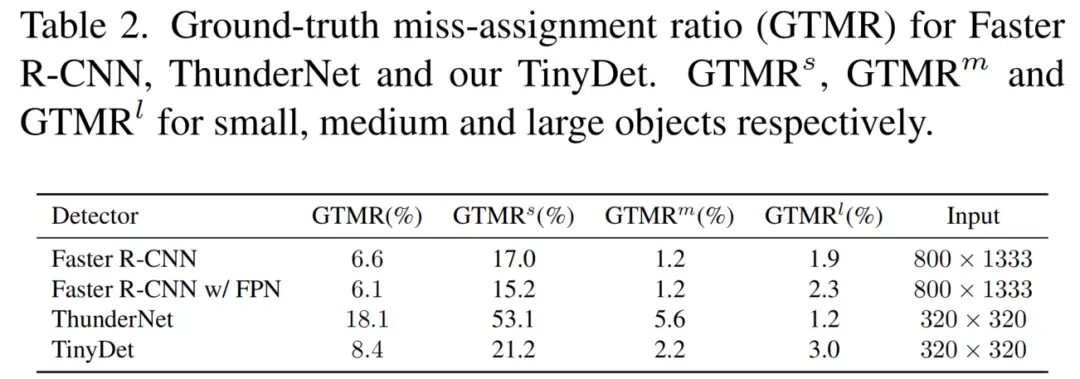
如表2所示,ThunderNet的GTMR高达18.1%,远高于Faster R-CNN。TinyDet获得了相当低的GTMR,8.4%,尽管与ThunderNet一样轻。值得注意的是,ThunderNet的小目标的GTMR非常高;而在具有高分辨率特征图和密集拼接Anchor的TinyDet中,小目标的GTMR远低于ThunderNet。小目标可以在空间上与Anchor更好地匹配。
4、实验
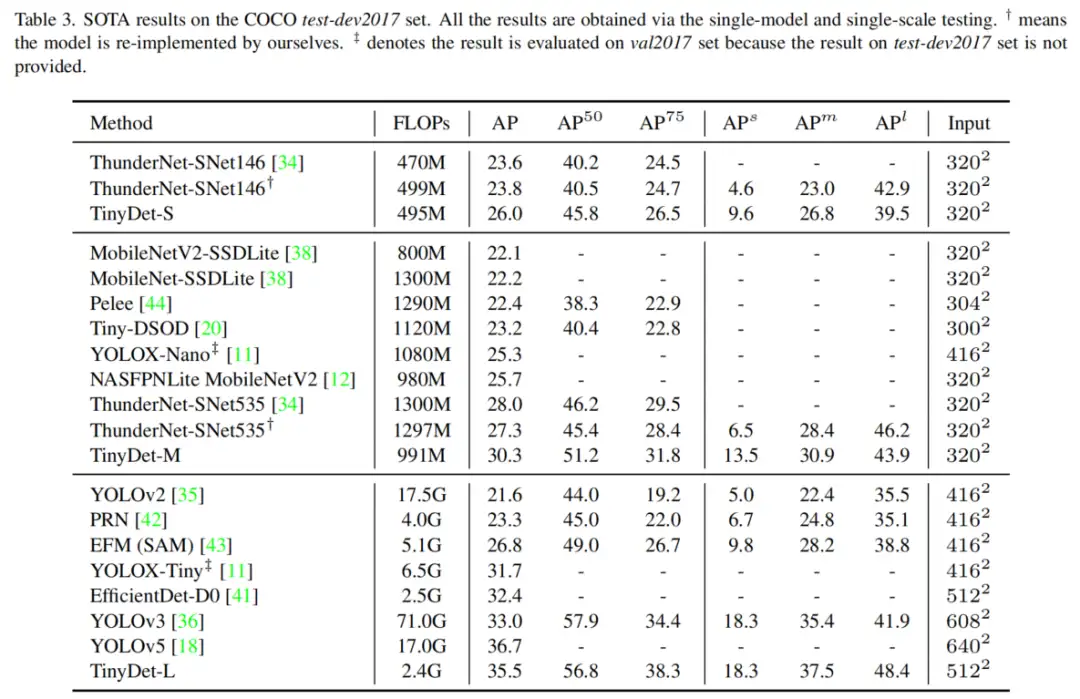
4.1、SOTA对比
4.2、消融实验
1、Backbone的消融研究
如第3.1.1节所述,增强了基于MobileNetV3的Backbone中的详细信息,这对于改进高分辨率的特征表示非常重要。作者提供3种MobileNetV3变体:MobileNetV3-B、-C和-BC,以证明增强主干的有效性。
与最初的MobileNetV3相比,MobileNetV3-B在stride为4的阶段增加了2个额外的block,MobileNet V3-C在早期阶段包含的通道增加了50%。MobileNetBC是MobileNetV3-B和MobileNetV2-C的组合,这是为TinyDet提出的Backbone。
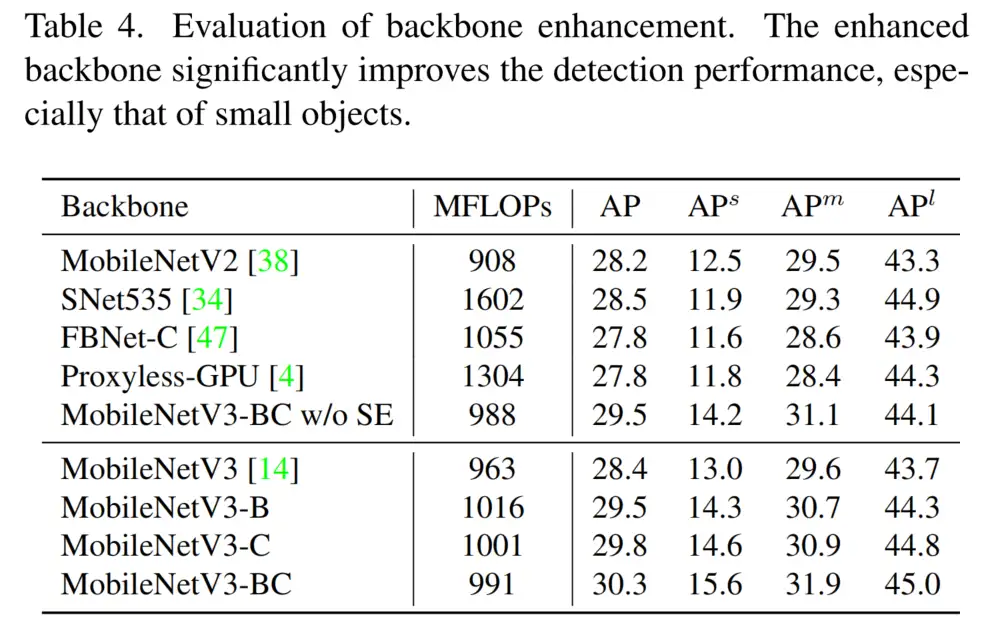
表4显示了不同配置的比较。为了公平比较,作者调整了TinyFPN和TinyRPN的组号,以保持总计算预算相似(约1 GFLOP)。MobileNetV3BC性能优于MobileNetV3和其他变体。增加层数和通道数分别使AP提高了1.1%和1.4%。当两者都采用时,AP提高了1.9%。
此外,AP上的增益(+2.6)比APm(+1.3)和APl(+11.3)更显著。随着更多的计算被分配到早期阶段,详细的信息得到了增强,并更有利于小目标检测。
作者还将MobileNetV3BC与其他具有代表性的轻量级主干进行了比较(表4)。为了进行公平的比较,删除了SE模块。MobileNetV3 BC比手动设计的主干(SNet535和MobileNetV2)和自动搜索的主干(FBNet和Proxyless)都能获得更好的结果。
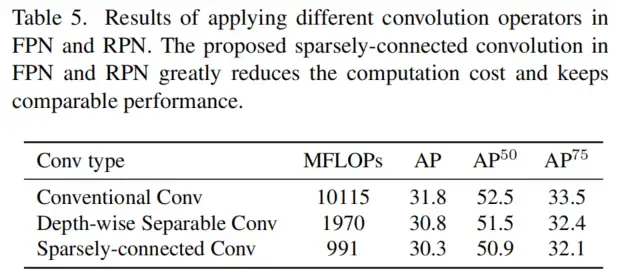
2、TinyFPN和TinyRPN中SCConv的消融研究
为了使FPN和RPN轻量级,将深度卷积和逐点群卷积组合为稀疏连接卷积(SCConv)。如表5所示,与FPN和RPN中的传统卷积或深度可分离卷积相比,SCConv大大降低了计算成本,并取得了可比的结果。
结果证实,TinyFPN和TinyRPN中的SCConv对检测性能几乎没有降低。对于轻量化检测器的设计,在检测头中采用SCConv是一种在保持高检测性能的同时节省计算成本的有效方法。
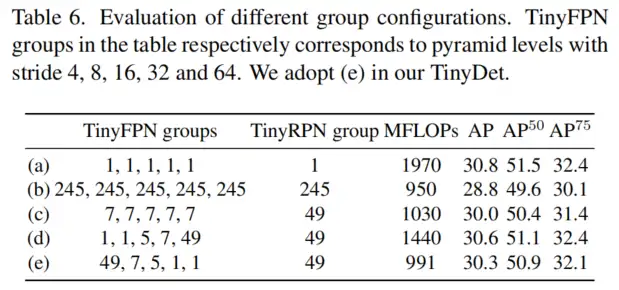
作者还评估了TinyFPN和TinyRPN中SCConvs的不同组号设置。结果如表6所示。从(c)行和(e)行的比较中发现为不同的金字塔级别设置不同的组号比设置相同的组号要好。一个好的做法是在FPN中,底部金字塔使用更多的组,顶部金字塔使用更少的组(表6(e))。
3、特征对齐的消融研究
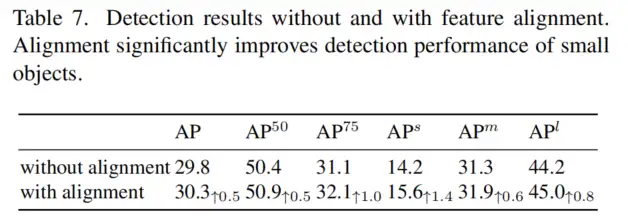
作者评估了第3.1.2节中描述的特征错位如何影响表7中的检测性能。通过使用简单的平均池化来更好地调整主干特征,在AP上获得了0.5%的增益。
请注意,AP的增益(+1.4%)高于APm(+0.6%)或APl(+0.8%)。这是因为小目标对特征错位更敏感,并且从这种校正中受益更多。
4、局限性
这项研究存在局限性。目前,无法将速度与其他检测器进行比较。原因有两方面:
- 首先,检测器的速度高度依赖于推理SDK(例如,苹果的CoreML和谷歌的TensorFlowLite)。对于ThunderNet,它使用了第3方高性能推理SDK,该SDK尚未公开。这使得在相同的硬件条件下进行公平的速度比较是不可行的。
- 其次,大多数推理SDK主要针对计算内容模型进行优化,较少关注内存带宽。然而,TinyDet具有计算效率,并且需要面向带宽的优化。这种不一致性使TinyDet在速度上处于次优状态。
目前,在2种类型的ARM CPU上提供了TinyDet的推理延迟,这两种CPU具有单线程且没有任何优化(表8)。

5、参考
[1].TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习