网上看到这篇文章,觉得很不错,这里转载记录一下。
转自:提高kafka消费速度之从源码去了解Spring-kafka的concurrency参数 - 简书
第一部分、引言
在spring应用中,如果我们需要订阅kafka消息,通常情况下我们不会直接使用kafka-client,而是使用了更方便的一层封装spring-kafka。特别是在springboot微服务中,基于注解和配置的spring-kafka可以给我们带来更简单更便捷的开发方式。不过,它不仅仅只是简单的封装的kafka-client,仔细看他的源码会发现里面大有文章,不得不惊呼大神写这个框架的牛逼。
本文介绍了常见的几种在spring-kafka中提高kafka消费速度的方式,并重点介绍了使用多线程并发消费的方式,通过解读源码真正理解该多线程消费模型。
partition与consumer的限制:“一个partition只能对应一个消费线程”。
注意:本文涉及到的case是在partition数大于consumer实例数的情况。比如现在有5台部署了consumer实例机器,要去消费30个partition,是这种情况下的提升消费速度优化。
如果你现在面临的情况是那种partition数很少,又受限于“一个partition只能对应一个消费线程”的限制。
比如partition数只有1,这种情况就必须要“把拉取动作和处理动作分开” 可以参考以下模型 —— 消息拉下来之后就丢给线程池handle并自动提交offset,也可以让消息在handler完之后手动提交offset(无论哪种方式都是不安全的,建议参考类似于TCP的滑动窗口控制的方式来控制消费位移的提交)
默认情况下, Spring-Kafka @KafkaListener 串行消费的。缺点显而易见生产者生产的数据过多时,消费端容易导致消息积压的问题。
当然了, 我们可以通过启动多个进程,实现 多进程的并发消费。 当然了也取决于你的TOPIC的 partition的数量。
试想一下, 在单进程的情况下,能否实现多线程的并发消费呢? Spring Kafka 为我们提供了这个功能,而且使用起来相当简单。 重点是把握原理,灵活运用。
@KafkaListener 的 concurrecy属性 可以指定并发消费的线程数 。
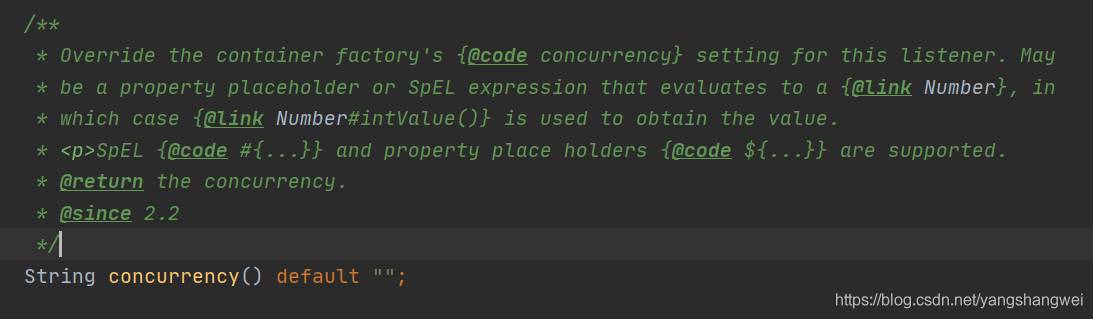
举个例子 : 如果设置 concurrency=2 时,Spring-Kafka 就会为该 @KafkaListener标注的方法消费的消息 创建 2个线程,进行并发消费。 当然了,这是有前置条件的。 不要超过 partitions 的大小
- 当concurrency < partition 的数量,会出现消费不均的情况,一个消费者的线程可能消费多个partition 的数据
- 当concurrency = partition 的数量,最佳状态,一个消费者的线程消费一个 partition 的数据
- 当concurrency > partition 的数量,会出现有的消费者的线程没有可消费的partition, 造成资源的浪费
分布式情况:总consumer线程数=concurrency*机器数量;
第二部分:提高消费速度的几种操作
kakfa是我们在项目开发中经常使用的消息中间件。由于它的写性能非常高,因此,经常会碰到Kafka消息队列拥堵的情况。遇到这种情况时,有时我们不能直接清理整个topic,因为还有别的服务正在使用该topic。因此只能额外启动一个或多个相同名称的consumer-group的消费者实例来加快消息消费(如果该topic只有一个partition,实际上再启动一个新的消费者,没有作用)。——这是最原始的提高消费速度的方式。
然后我们介绍一下引入spring-kafka有哪些操作(其实都是可以用代码实现,只是你要自己做这层二次封装)
一、用多线程并发消费
通过设置concurrency参数的方式。先看代码,我们可以使用两种不同的途径设置该参数:
第一种方式,直接在factory里面设置。
我们给ConcurrentKafkaListenerContainerFactory设置了concurrency等于3,也可以通过在application.properties中添加spring.kafka.listener.concurrency=3的方式配置factory.
-
@Bean
-
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
-
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
-
factory.setConsumerFactory(consumerFactory());
-
factory.setConcurrency(3);
-
factory.setBatchListener(true);
-
factory.getContainerProperties().setPollTimeout(3000);
-
return factory;
-
}
本人不推荐使用该方式,因为设置它的意思是给factory里面的每个listener都设置了3个线程,但其实有些listener监听的topic并没有那么多分区。推荐用第二种方式。
第二种方式,在@KafkaListener设置,支持SpEL表达式。
-
单独给某个listener配置并发线程数,这种方式在逻辑上更为合理。
-
@KafkaListener(topics = {"${kafka.calculate.topic}"}, concurrency = "3")
-
public void listen(ConsumerRecord<String, String> record) {
-
// doing
-
}
先介绍一下spring-kafka在工作的时候启动的一堆线程:
- 分为两类线程,一类是Consumer线程,另一类是Listener线程。
- Consumer线程: 用来直接调用kafka-client的poll()方法获取消息。
- Listener线程: 真正调用处理我们代码中标有
@KafkaListener注解方法的线程。
如果不使用spring-kafka,而是直接用kafka-client的话,那么正常我们会整一个while循环,在循环里面调用poll(),然后处理消息,这在kafka broker看来就是一个Consumer。如果你想用多个Consumer, 除了多启动几个进程以外,也可以在一个进程使用多个线程执行此while()循环。spring-kafka就是这么干的。
因此,先看结论:
对于concurrency=3这个参数的值的设定来说,它设置的其实是每个@KafkaListener的并发数。spring-kafka在初始化的时候会启动concurrency个Consumer线程来执行@KafkaListener里面的方法。
这里如果你是用第一种方式,在factory里面直接设置concurrency,那么每个加了@KafkaListener注解的都会新建concurrency个线程,这样如果listener订阅的topic没那么多分区,new那么多线程只会带来格外的性能开销,这样是我不推荐在factory指定concurrency的原因。
源代码
最后一部分将会带大家阅读源码证明以上这段话
另外:
看到这里可能会问,那我说的Listener线程没用到啊。不急,继续往下看,在源码中已经给出了:
-
protected void pollAndInvoke() {
-
if (!this.autoCommit && !this.isRecordAck) {
-
processCommits();
-
}
-
processSeeks();
-
checkPaused();
-
ConsumerRecords<K, V> records = this.consumer.poll(this.pollTimeout);
-
this.lastPoll = System.currentTimeMillis();
-
checkResumed();
-
debugRecords(records);
-
if (records != null && records.count() > 0) {
-
if (this.containerProperties.getIdleEventInterval() != null) {
-
this.lastReceive = System.currentTimeMillis();
-
}
-
// 这里可以看到如果是自动提交offset,会直接把consumer poll下来的消息给到listener执行,
-
// 即kafka consumer所在线程会直接调用我们的@KafkaListener方法
-
invokeListener(records);
-
}
-
else {
-
checkIdle();
-
}
-
}
-
如果是手动提交offset,即enable-auto-commit设置为false,则是将消息投放到阻塞队列中,另一边由Listener线程取出执行。
所以,当concurrency=3,自动提交设置为false时,如果你程序里有两个方法标记了@KafkaListener,那么此时会启动 2 * 3 = 6 个Consumer线程,6个Listener线程。
这个信息在排查错误的时候非常重要,但官方文档居然没怎么提线程的事(不够详细),只是在介绍KafkaContainerListener。
另外例如:
对于spring.kafka.listener.concurrency=3这个参数来说,它设置的是每个@KafkaListener的并发个数。每添加一个@KafkaListener, spring-kafka都会启动concurrency条Consumer线程来监听这些topic(注解可以指定监听多个topic):
- 当
enable-auto-commit设为true时会直接在当前线程,即kafka consumer所在线程调用我们的@KafkaListener方法, - 如果
enable-auto-commit设为false,则是将消息投放到阻塞队列中,另一边由Listener线程取出执行。
有源码为证:
-
// if the container is set to auto-commit, then execute in the
-
// same thread
-
// otherwise send to the buffering queue
-
if (this.autoCommit) {
-
invokeListener(records);
-
}
-
else {
-
if (sendToListener(records)) {
-
if (this.assignedPartitions != null) {
-
// avoid group management rebalance due to a slow
-
// consumer
-
this.consumer.pause(this.assignedPartitions);
-
this.paused = true;
-
this.unsent = records;
-
}
-
}
-
}
所以,当concurrency=3,自动提交设置为false时,如果你程序里有两个方法标记了@KafkaListener,那么此时会启动 2 * 3 = 6 个Consumer线程,6个Listener线程。
这个信息在排查错误的时候非常重要,但官方文档居然没怎么提线程的事(不够详细),只是在介绍KafkaContainerListener。
二、批量消费
涉及到两个参数,
- 一个是factory.setBatchListener(true) —— 启动批量消费,
- 一个是propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50) —— 设置批量消费每次最多消费多少条记录。
官方文档对max.poll.records的定义是:
这个参数定义了poll()方法最多可以返回多少条消息,默认值为500。注意这里的用词是"最多",也就是说如果在拉取消息的时候新消息不足500条,那有多少返回多少;如果超过500条,就只返回500。
这个500默认值是比较坑人的,如果你的消息处理逻辑比较重,比如需要查数据库,调用接口,甚至是复杂计算,那么你很难保证能够在max.poll.interval.ms内处理完500条消息,也就是说,如果上游真的突然大爆发生产了成千上万条消息,而平摊到每个消费者身上的消息达到了500的又无法按时消费完成的话,会触发消费者实例的rebalance, 然后这批消息会被分配到另一个消费者中,还是会处理不完,又会触发rebalance, 这样这批消息就永远也处理不完,而且一直在重复处理。
所以在配置的时候要避免出现上述问题,可以提前评估好处理一条消息最长需要多少时间,然后务必覆盖默认的max.poll.records参数。在spring-kafka中这个原生参数对应的参数项是max-poll-records。对于消息处理比较重的操作,建议把这个值改到50以下会保险一些。
配置代码如下:
-
@Bean
-
public Map<String, Object> consumerConfigs() {
-
Map<String, Object> propsMap = new HashMap<>();
-
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, propsConfig.getBroker());
-
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, propsConfig.getEnableAutoCommit());
-
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100");
-
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");
-
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
-
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
-
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, propsConfig.getGroupId());
-
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, propsConfig.getAutoOffsetReset());
-
// 这里设置批量消费的消息个数
-
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50);
-
return propsMap;
-
}
-
@Bean
-
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
-
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
-
factory.setConsumerFactory(consumerFactory());
-
factory.setConcurrency(4);
-
// 记得要开启批量消费,不然只是单次poll的消息增多而已
-
factory.setBatchListener(true);
-
factory.getContainerProperties().setPollTimeout(3000);
-
return factory;
-
}
三、分区消费
这种方式我个人觉得不是很适用分布式部署的情况,所以基本上不会考虑用它。。具体操作代码如下:
-
@KafkaListener(id = "id0", topicPartitions = { @TopicPartition(topic = TPOIC, partitions = { "0" }) })
-
public void listenPartition0(List<ConsumerRecord<?, ?>> records) {
-
log.info("Id0 Listener, Thread ID: " + Thread.currentThread().getId());
-
log.info("Id0 records size " + records.size());
-
-
for (ConsumerRecord<?, ?> record : records) {
-
// doing
-
}
-
}
-
-
@KafkaListener(id = "id1", topicPartitions = { @TopicPartition(topic = TPOIC, partitions = { "1" }) })
-
public void listenPartition1(List<ConsumerRecord<?, ?>> records) {
-
log.info("Id1 Listener, Thread ID: " + Thread.currentThread().getId());
-
log.info("Id1 records size " + records.size());
-
-
for (ConsumerRecord<?, ?> record : records) {
-
// doing
-
}
第三部分:从源码去了解Spring-kafka的concurrency参数
直接找到我们的ConcurrentKafkaListenerContainerFactory类中,concurrency的使用:
-
@Override
-
protected void initializeContainer(ConcurrentMessageListenerContainer<K, V> instance, KafkaListenerEndpoint endpoint) {
-
super.initializeContainer(instance, endpoint);
-
if (endpoint.getConcurrency() != null) {
-
instance.setConcurrency(endpoint.getConcurrency());
-
}
-
else if (this.concurrency != null) {
-
instance.setConcurrency(this.concurrency);
-
}
-
}
继续在ConcurrentMessageListenerContainer中我们找到了concurrency的使用:
-
@Override
-
protected void doStart() {
-
if (!isRunning()) {
-
checkTopics();
-
ContainerProperties containerProperties = getContainerProperties();
-
TopicPartitionInitialOffset[] topicPartitions = containerProperties.getTopicPartitions();
-
// 这里你会发现如果你设置的concurrency 大于分区数,spring-kafka也会让它等于分区的个数,肯定不会超过分区数。
-
// 可这是在一个JVM里面的concurrency,如果你是多个消费者实例部署在多个服务器上(实际生产都是这么做),**那么你的concurrency 值记得还要除以机器数**。
-
if (topicPartitions != null && this.concurrency > topicPartitions.length) {
-
this.logger.warn("When specific partitions are provided, the concurrency must be less than or "
-
+ "equal to the number of partitions; reduced from " + this.concurrency + " to "
-
+ topicPartitions.length);
-
this.concurrency = topicPartitions.length;
-
}
-
setRunning(true);
-
// 这里可以很清晰的看到,concurrency是指KafkaMessageListenerContainer的个数,即concurrency表明的是spring会创建多个KafkaMessageListenerContainer。
-
// 那么KafkaMessageListenerContainer类又干了什么?这里是for循环顺序创建了concurrency个KafkaMessageListenerContainer,那么spring又是如何并发的?这里会猜想是new了线程去处理
-
for (int i = 0; i < this.concurrency; i++) {
-
KafkaMessageListenerContainer<K, V> container;
-
if (topicPartitions == null) {
-
container = new KafkaMessageListenerContainer<>(this, this.consumerFactory, containerProperties);
-
}
-
else {
-
container = new KafkaMessageListenerContainer<>(this, this.consumerFactory,
-
containerProperties, partitionSubset(containerProperties, i));
-
}
-
String beanName = getBeanName();
-
container.setBeanName((beanName != null ? beanName : "consumer") + "-" + i);
-
if (getApplicationEventPublisher() != null) {
-
container.setApplicationEventPublisher(getApplicationEventPublisher());
-
}
-
container.setClientIdSuffix("-" + i);
-
container.setGenericErrorHandler(getGenericErrorHandler());
-
container.setAfterRollbackProcessor(getAfterRollbackProcessor());
-
container.setEmergencyStop(() -> {
-
stop(() -> {
-
// NOSONAR
-
});
-
publishContainerStoppedEvent();
-
});
-
container.start();
-
this.containers.add(container);
-
}
-
}
-
}
继续往下看KafkaMessageListenerContainer干了什么?
进入41行的start方法:这是父类AbstractMessageListenerContainer的start方法
-
@Override
-
public final void start() {
-
checkGroupId();
-
synchronized (this.lifecycleMonitor) {
-
if (!isRunning()) {
-
Assert.isTrue(this.containerProperties.getMessageListener() instanceof GenericMessageListener,
-
() -> "A " + GenericMessageListener.class.getName() + " implementation must be provided");
-
doStart();
-
}
-
}
-
}
再进入第8行的doStart方法:
发现doStart是一个抽象方法,于是我们需要回到AbstractMessageListenerContainer的子类KafkaMessageListenerContainer中,查看doStart方法具体做了什么:
-
@Override
-
protected void doStart() {
-
if (isRunning()) {
-
return;
-
}
-
if (this.clientIdSuffix == null) { // stand-alone container
-
checkTopics();
-
}
-
ContainerProperties containerProperties = getContainerProperties();
-
// 这里是做一些参数校验
-
checkAckMode(containerProperties);
-
-
Object messageListener = containerProperties.getMessageListener();
-
Assert.state(messageListener != null, "A MessageListener is required");
-
if (containerProperties.getConsumerTaskExecutor() == null) {
-
SimpleAsyncTaskExecutor consumerExecutor = new SimpleAsyncTaskExecutor(
-
(getBeanName() == null ? "" : getBeanName()) + "-C-");
-
containerProperties.setConsumerTaskExecutor(consumerExecutor);
-
}
-
Assert.state(messageListener instanceof GenericMessageListener, "Listener must be a GenericListener");
-
// 设置消息来到之后,需要回调的listener和listenerType类型
-
GenericMessageListener<?> listener = (GenericMessageListener<?>) messageListener;
-
ListenerType listenerType = deteremineListenerType(listener);
-
// 这里创建了一个ListenerConsumer,看到这里我们也明白了为什么顺序创建了concurrency个KafkaMessageListenerContainer,却可以做到并发?
-
// 理由很简单:因为在KafkaMessageListenerContainer类内部中,对于ListenerConsumer的处理逻辑,是新起线程执行,所以才可以做到并发。
-
// 这里又一次说明了设置好concurrency值的重要性,如果处理不好,会new过多闲置的ListenerConsumer,因为一个partition只对应一个消费线程。
-
this.listenerConsumer = new ListenerConsumer(listener, listenerType);
-
setRunning(true);
-
this.listenerConsumerFuture = containerProperties
-
.getConsumerTaskExecutor()
-
.submitListenable(this.listenerConsumer);
-
}
继续,我们进入ListenerConsumer的构造函数里面:
-
ListenerConsumer(GenericMessageListener<?> listener, ListenerType listenerType) {
-
Assert.state(!this.isAnyManualAck || !this.autoCommit,
-
() -> "Consumer cannot be configured for auto commit for ackMode "
-
+ this.containerProperties.getAckMode());
-
// 这里可以看到每个ListenerConsumer首先创建了一个Kafka定义的Consumer,然后,设置了consumer的订阅的topic、分区偏移量信息以及重新分配分区的监听对象。
-
this.consumer = KafkaMessageListenerContainer.this.consumerFactory.createConsumer(
-
this.consumerGroupId,
-
this.containerProperties.getClientId(),
-
KafkaMessageListenerContainer.this.clientIdSuffix,
-
this.containerProperties.getConsumerProperties());
-
-
if (this.transactionManager != null) {
-
this.transactionTemplate = new TransactionTemplate(this.transactionManager);
-
}
-
else {
-
this.transactionTemplate = null;
-
}
-
subscribeOrAssignTopics(this.consumer);
-
GenericErrorHandler<?> errHandler = KafkaMessageListenerContainer.this.getGenericErrorHandler();
-
this.genericListener = listener;
-
if (listener instanceof BatchMessageListener) {
-
this.listener = null;
-
this.batchListener = (BatchMessageListener<K, V>) listener;
-
this.isBatchListener = true;
-
this.wantsFullRecords = this.batchListener.wantsPollResult();
-
}
-
else if (listener instanceof MessageListener) {
-
this.listener = (MessageListener<K, V>) listener;
-
this.batchListener = null;
-
this.isBatchListener = false;
-
this.wantsFullRecords = false;
-
}
-
else {
-
throw new IllegalArgumentException("Listener must be one of 'MessageListener', "
-
+ "'BatchMessageListener', or the variants that are consumer aware and/or "
-
+ "Acknowledging"
-
+ " not " + listener.getClass().getName());
-
}
-
this.listenerType = listenerType;
-
this.isConsumerAwareListener = listenerType.equals(ListenerType.ACKNOWLEDGING_CONSUMER_AWARE)
-
|| listenerType.equals(ListenerType.CONSUMER_AWARE);
-
if (this.isBatchListener) {
-
validateErrorHandler(true);
-
this.errorHandler = new LoggingErrorHandler();
-
this.batchErrorHandler = determineBatchErrorHandler(errHandler);
-
}
-
else {
-
validateErrorHandler(false);
-
this.errorHandler = determineErrorHandler(errHandler);
-
this.batchErrorHandler = new BatchLoggingErrorHandler();
-
}
-
Assert.state(!this.isBatchListener || !this.isRecordAck,
-
"Cannot use AckMode.RECORD with a batch listener");
-
if (this.containerProperties.getScheduler() != null) {
-
this.taskScheduler = this.containerProperties.getScheduler();
-
this.taskSchedulerExplicitlySet = true;
-
}
-
else {
-
ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
-
threadPoolTaskScheduler.initialize();
-
this.taskScheduler = threadPoolTaskScheduler;
-
}
-
this.monitorTask = this.taskScheduler.scheduleAtFixedRate(this::checkConsumer,
-
this.containerProperties.getMonitorInterval() * 1000); // NOSONAR magic #
-
if (this.containerProperties.isLogContainerConfig()) {
-
this.logger.info(this);
-
}
-
Map<String, Object> props =
-
KafkaMessageListenerContainer.this.consumerFactory.getConfigurationProperties();
-
this.checkNullKeyForExceptions = checkDeserializer(findDeserializerClass(props, false));
-
this.checkNullValueForExceptions = checkDeserializer(findDeserializerClass(props, true));
-
}
看到这里差不多真相大白了,在梳理一遍:
ConcurrentKafkaListenerContainerFactory类中的concurrency设置了KafkaMessageListenerContainer对象创建的个数,每个KafkaMessageListenerContainer对象创建了一个ListenerConsumer对象,ListenerConsumer对象有封装了一个kafkaConsumer对象。
所以concurrency最终设置的是kafkaConsumer对象的个数。这个也和ConcurrentKafkaListenerContainerFactory类中setConcurrency方法的注释是一致的。
配置说明
参考:【spring-kafka】@KafkaListener详解与使用 - 掘金
说明
-
从2.2.4版开始,您可以直接在注释上指定Kafka使用者属性,这些属性将覆盖在使用者工厂中配置的具有相同名称的所有属性。您不能通过这种方式指定group.id和client.id属性。他们将被忽略;
-
可以使用#{…}或属性占位符(${…})在SpEL上配置注释上的大多数属性。 比如:
@KafkaListener(id = "consumer-id",topics = "SHI_TOPIC1",concurrency = "${listen.concurrency:3}",clientIdPrefix = "myClientId")concurrency = "${listen.concurrency:3}", 属性concurrency将会从容器中获取listen.concurrency的值,如果不存在就默认用3
concurrency并发数
KafkaListener的concurrency会覆盖KafkaListenerContainerFactory消费者工厂中的concurrency,这里的并发数就是多线程消费;
比如说单机情况下,你设置了3,相当于就是启动了3个客户端来分配消费分区;
分布式情况:总线程数=concurrency*机器数量;
并不是设置越多越好,具体如何设置请看 属性concurrency的作用及配置(RoundRobinAssignor 、RangeAssignor)
-
/**
-
* 监听器工厂
-
* @return
-
*/
-
@Bean
-
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> concurrencyFactory() {
-
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
-
new ConcurrentKafkaListenerContainerFactory<>();
-
factory.setConsumerFactory(kafkaConsumerFactory());
-
factory.setConcurrency(6);
-
return factory;
-
}
@KafkaListener(id = "consumer-id5",idIsGroup = false,topics = "SHI_TOPIC3", containerFactory = "concurrencyFactory",concurrency = "1)虽然使用的工厂是concurrencyFactory(concurrency配置了6); 但是他最终生成的监听器数量 是1;
总结
调大concurrency的值,真的会提高系统消息消费的能力吗?
此时问题可以理解为:增加kafkaConsumer可以提高系统消息消费能力吗?答案很明显:不一定。
因为我们知道,kafka中一个consumer最多消费一个分区,在topic分区数量一定的情况下:
- 如果consumer的数量小于分区数量,那么增加consumer是可以提高系统消息消费能力的。
- 如果consumer的数量大于等于分区数量,那么此时一味提高consumer数量,系统的消息消费能力是不会提高的,反而还有可能下降。这是因为每次rebalance操作,所有的consumer都会参与,当consumer数量大时,rebalance的耗时会增加,因此系统的性能会有所下降。