Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation
论文作者:Junliang Yu, H. Yin, Xin Xia, Tong Chen, Li-zhen Cui, Quoc Viet Hung Nguyen
论文来源:SIGIR 2022
论文地址:download
论文代码:download
1 Introduction
本文是针对图对比学习在推荐系统中的应用而提出的相关方法。通常做对比学习的时候,需要对数据进行增广,得到相同数据的不同视图(view),然后进行对比学习,对于图结构也是一样,需要对用户-商品二部图进行结构扰动从而获得不同视图,然后进行对比学习最大化不同图扩充之间的节点表征一致性。
贡献:
-
- 通过实验阐明了为什么 CL 可以提高推荐性能,并说明了 InfoNCE 损失,而不是图的增强,是决定性的因素;
- 提出一种简单而有效的无图增强 CL 推荐方法,可以平滑地调节均匀性;
- 对三个基准数据集进行了全面的实验研究,结果表明,该方法在推荐精度和模型训练效率方面比基于图增强的方法具有明显的优势;
2 相关工作
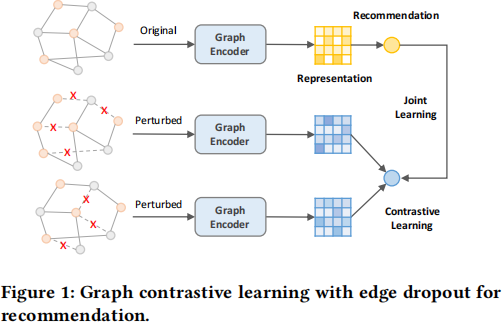
作者使用 SGL 进行了如下实验,探究图结构扰动在图对比学习中的作用。
SGL 训练目标如下:
$\mathcal{L}_{\text {joint }}=\mathcal{L}_{\text {rec }}+\lambda \mathcal{L}_{c l}$
$\mathcal{L}_{c l}=\sum_{i \in \mathcal{B}}-\log \frac{\exp \left(\mathbf{z}_{i}^{\prime \top} \mathbf{z}_{i}^{\prime \prime} / \tau\right)}{\sum_{j \in \mathcal{B}} \exp \left(\mathbf{z}_{i}^{\prime \top} \mathbf{z}_{j}^{\prime \prime} / \tau\right)}$
其中, $\mathbf{z}^{\prime}\left(\mathbf{z}^{\prime \prime}\right)$ 是从两个不同图增强中学习到的 $L_{2}$ 归一化后的节点表示。对比学习损失函数最大 化正样本之间的一致性,即来自同一节点的增强表示 $\mathbf{z}_{i}^{\prime}$ 和 $\mathbf{z}_{i}^{\prime \prime}$ ; 同时,最小化负样本之间的一致性,即两个不同节点的增强表示 $\mathbf{z}_{i}^{\prime}$ 和 $\mathbf{z}_{j}^{\prime \prime}$ 。
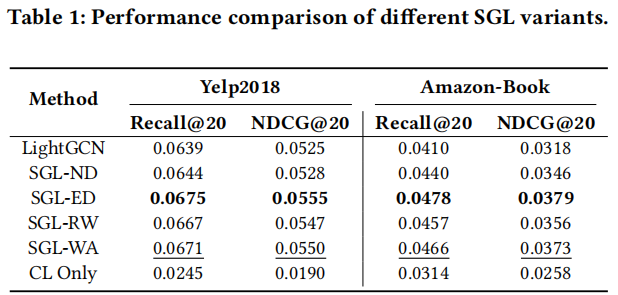
注意:ND 为 node dropout,ED 为 edge dropout,RW 为随机游走,WA 不进行数据增广。可以发现,不进行数据增广的情况下,只比增强低一点,说明其作用很小。
注意:SGL-WA :
$\mathcal{L}_{c l}=\sum_{i \in \mathcal{B}}-\log \frac{\exp (1 / \tau)}{\sum_{j \in \mathcal{B}} \exp \left(\mathbf{z}_{i}^{\top} \mathbf{z}_{j} / \tau\right)}$
3 InfoNCE 的影响
对比损失的优化有两个特性:
-
- alignment of features from positive pairs;
- uniformity of the normalized feature distribution on the unit hypersphere;
Note:
$\mathcal{L}_{\text {align }}(f ; \alpha) \triangleq \underset{(x, y) \sim p_{\text {pos }}}{\mathbb{E}}\left[\|f(x)-f(y)\|_{2}^{\alpha}\right], \quad \alpha>0$
$\begin{array}{l}\mathcal{L}_{\text {uniform }}(f ; t) &\triangleq \log \underset{x, y \text { i.i.d. }}{\mathbb{E}} p_{\text {data }}\left[G_{t}(u, v)\right] \\&=\log \underset{x, y \stackrel{\text { i.i.d. }}{\sim} p_{\text {data }}}{\mathbb{E}}\left[e^{-t\|f(x)-f(y)\|_{2}^{2}}\right], \quad t>0 \\\end{array}$
实验
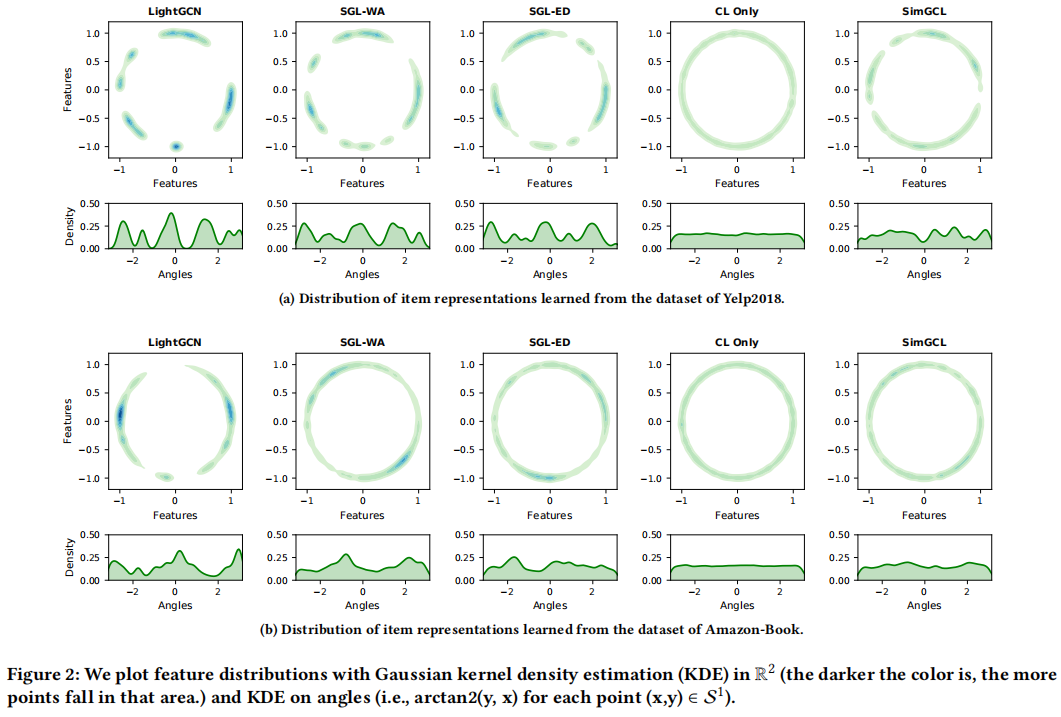
实验表明:
-
- LigthGCN 学习到的特征表示聚类现象更明显;
- SGL 结合对比学习的特征表示相对均匀;
- CL only 只有对比学习的特征分布均匀;
本文认为有两个原因可以解释高度聚集的特征分布:
-
- 消息传递机制,随着层数的增加,节点嵌入变得局部相似;
- 推荐数据中的流行度偏差,,由于推荐数据通常遵循长尾分布,当 $?$ 是一个具有大量交互的流行项目时,用户嵌入将会不断更新到 $?$ 的方向;
结论:即分布的均匀性是对 SGL 中的推荐性能有决定性影响的潜在因素,而不是图增强。优化 CL 损失可以看作是一种隐式的去偏倚的方法,因为一个更均匀的表示分布可以保留节点的内在特征,提高泛化能力。
4 方法
作者直接在表示中添加随机噪声,以实现有效的增强:
$\mathbf{e}_{i}^{\prime}=\mathbf{e}_{i}+\Delta_{i}^{\prime}, \quad \mathbf{e}_{i}^{\prime \prime}=\mathbf{e}_{i}+\Delta_{i}^{\prime \prime}$
约束:
-
- $\|\Delta\|_{2}=\epsilon $ 控制扰动在大小为 $\epsilon$ 的超球面上;
- $\Delta=\bar{\Delta} \odot \operatorname{sign}\left(\mathbf{e}_{i}\right), \bar{\Delta} \in \mathbb{R}^{d} \sim U(0,1) $ 控制扰动后的嵌入和原嵌入在同一超空间中;
图示如下:
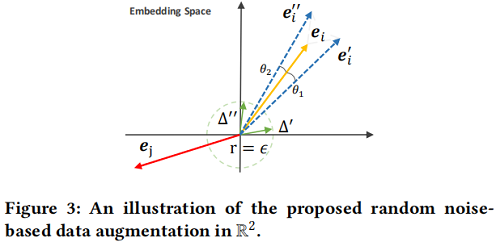
以 LightGCN 作为图编码器,在每一层增加随机噪声,可以得到最终的节点表示:
$\begin{array}{l}\mathbf{E}^{\prime}=&\frac{1}{L}\left(\left(\tilde{\mathrm{A}} \mathbf{E}^{(0)}+\Delta^{(1)}\right)+\left(\tilde{\mathrm{A}}\left(\tilde{\mathrm{A}} \mathbf{E}^{(0)}+\Delta^{(1)}\right)+\Delta^{(2)}\right)\right)+\ldots \\&\left.+\left(\tilde{\mathrm{A}}^{L} \mathbf{E}^{(0)}+\tilde{\mathrm{A}}^{L-1} \Delta^{(1)}+\ldots+\tilde{\mathrm{A}} \Delta^{(L-1)}+\Delta^{(L)}\right)\right)\end{array}$
注意,这里丢掉了最开始的输入表示 $\mathbf{E}^{(0)}$ ,因为作者实验发现,不增加初始输入会带来性能提升, 但对于 LigthGCN 会有性能下降。
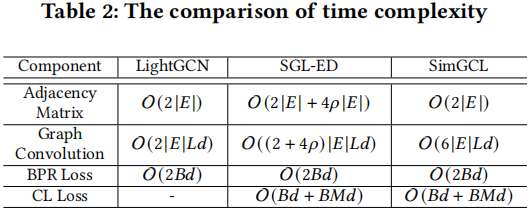
可以发现,相较于 SGL,SimGCL 的卷积复杂度会更高一些,作者也给出了如下图的理论分析。同时,作者也提到在实际实现中,由于卷积操作在GPU运算,且 SimGCL 只需要一次图构建,所以整 体上效率更高。
5 实验结果

参考:
[1] Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
- Graph Recommendation Augmentations Contrastive Necessarygraph recommendation augmentations contrastive lightgcl recommendation contrastive effective generative-contrastive recommendation contrastive representation recommendation degeneration contrastive recommendation contrastive effective lightgcl recommendation contrastive adaptive learning augmentations necessary quot necessary objects pull git necessary objects error