一、多任务处理
多任务处理指的是同时进行几个独立活动的能力
在单处理器(单CPU)系统中,一次只能执行一个任务。而多任务处理是通过在不同任务之间多路复用CPU的执行时间来实现的,即将CPU执行操作从一个任务切换到另一个任务。
不同任务之间的执行切换机制称为上下文切换,将一个任务的执行环境更改为另一个任务的执行环境。如果切换速度足够快,就会给人一种同时执行所有任务的错觉。这种逻辑并行性称为“并发”。
在有多个CPU或处理器也可以通过同时执行不同的任务来实现多任务处理。多任务处理是所有操作系统的基础,也是并行编程的基础
二、进程的概念
操作系统是一个多任务处理系统。在操作系统中,任务也称为进程。在实际应用中,任务和进程这两个术语可以互换使用。在第2章中,我们把执行映像定义为包含执行代码、数据和堆栈的存储区。
进程的正式定义:进程是对映像的执行
操作系统内核将一系列执行视为使用系统资源的单一实体。系统资源包括内存空间、I/O设备以及最重要的CPU时间。在操作系统内核中,每个进程用一个独特的数据结构表示,叫作进程控制块(PCB)或任务控制块(线程控制块)(TCB)等。在本书中,我们直接称它为PROC结构体。与包含某个人所有信息的个人纪录一样,PROC结构体包含某个进程的所有信息。在实际操作系统中,PROC结构体可能包含许多字段,而且数量可能很庞大
typedef struct proc{
struct proc *next;
int *ksp;
int pid;
int ppid;
int status;
int priority;
int kstack[1024];
} PROC;
在PROC结构体中,next是指向下一个PROC结构体的指针。ksp字段是保存的堆栈指针。当某进程放弃使用CPU时,它会将执行上下文保存在堆栈中,并将堆栈指针保存在PROC.ksp中,以便以后恢复。在PROC结构体的其他字段中,pid是标识一个进程的进程ID编号,ppid是父进程ID编号,status是进程的当前状态,priority是进程调度优先级,kstack是进程执行时的堆栈。操作系统内核通常会在其数据区中定义有限数量的PROC结构体,表示为:
PROC proc[NPROC]; // NPROC a constant, e.g. 64
用来表示系统中的进程。在一个单CPU系统中,一次只能执行一个进程。操作系统内核通常会使用正在运行的或当前的全局变量PROC指针,指向当前正在执行的PROC。在有多个CPU的多处理操作系统中,可在不同CPU上实时、并行执行多个进程。因此,在一个多处理器系统中正在运行的[NCPU]可能是一个指针数组,每个指针指向一个正在特定CPU上运行的进程。为简便起见,我们只考虑单CPU系统。
三、Unix/Linux中的进程
(1)进程来源
当操作系统启动时,操作系统内核的启动代码会强行创建一个PID=0的初始进程,即通过分配PROC结构体(通常是proc[0])进行创建,初始化PROC内容,并让运行指向proc[0]。然后,系统执行初始进程P0。大多数操作系统都以这种方式开始运行第一个进程。P0继续初始化系统,包括系统硬件和内核数据结构。然后,它挂载一个根文件系统,使得系统可以使用文件。在未初始化系统之后,P0复刻出一个子进程P1,并把进程切换为以用户模式运行P1。
(2)INIT和守护进程
当进程P1开始运行时,它将其执行映像更改为INIT程序。因此,P1通常被称为INIT进程,因为它的执行映像是init程序。P1开始复刻出许多子进程。P1的大部分子进程都是用来提供系统服务的。它们在后台运行,不与任何用户交互。这样的进程称为守护进程。
syslogd: log daemon process
inetd: Internet service daemon process
httpd: HTTP server daemon process
etc.
(3)登陆进程
除了守护进程之外,P1还复刻了许多LOGIN进程,每个终端上一个,用于用户登录。
用户账户保存在/etc/passwd和/etc/shadow文件中。每个用户账户在表单的/etc/passwd文件中都有一行对应的记录
name:x:gid:uid:desciption:home:program
其中,name为用户登录名,x表示登陆时检查密码,gid为用户组ID,uid为用户ID,home为用户主目录,program为用户登录后执行的初始程序。其他用户信息保存在/etc/shadow文件中。shadow文件的每一行都包含加密的用户密码,后面是可选的过期限制信息,如过期日期和时间等。当用户尝试使用登录名和密码登录时,Linux将检查/etc/shadow文件,以验证用户的身份。
(4)sh进程
当用户成功登录时,LOGIN进程会获取用户的gid和uid,从而成为用户的进程。它将目录更改为用户的主目录并执行列出的程序,通常是命令解释程序sh。现在,用户进程执行sh,因此用户进程通常称为sh进程。它提示用户执行命令。一些特殊命令,如cd(更改目录)、退出、注销等,由sh自己直接执行。其他大多数命令是各种bin目录(如/bin、/sbin、/usr/bin、/usr/local/bin等)中的可执行文件。对于每个(可执行文件)命令,sh会复刻一个子进程,并等待子进程终止。子进程将其执行映像更改为命令文件并执行命令程序。子进程在终止时会唤醒父进程sh,父进程会收集子进程终止状态、释放子进程PROC结构体并提示执行另一个命令等。除简单的命令之外,sh还支持I/O重定向和通过管道连接的多个命令。
(5)进程的执行模式
在Unix/Linux中,进程以两种不同的模式执行,即内核模式和用户模式,简称Kmode和Umode。在每种执行模式下,一个进程有一个执行映像
在进程的生命周期中,会在Kmode和Umode之间发生多次迁移。每个进程都在Kmode下产生并开始执行。事实上,它在Kmode下执行所有相关操作,包括终止。在Kmode模式下,通过将CPU的状态寄存器从K模式更改为U模式,可轻松切换到Umode。但是,一旦进入Umode,就不能随意更改CPU的状态了,原因很明显。Umode进程只能通过以下三种方式进入Kmode:
(1)中断:中断是外部设备发送给CPU的信号,请求CPU的服务。当在Umode下执行时,CPU中断是启用的,因此它将响应任何中断。在中断发生时,CPU将进入Kmode来处理中断,这将导致进程进入Kmode。
(2)陷阱:陷阱是错误条件,例如无效地址、非法指令、除以0等,这些错误条件被CPU识别为异常,使得CPU进入Kmode来处理错误。在Unix/Linux中,内核陷阱处理程序将陷阱原因转换为信号编号,并将信号传递给进程。对于大多数信号,进程的默认操作是终止。
(3)系统调用:系统调用(简称syscall)是一种允许Umode进程进入Kmode以执行内核函数的机制。当某进程执行完内核函数后,它将期望结果和一个返回值返回到Umode,该值通常为0(表示成功)或-1(表示错误)。如果发生错误,外部全局变量errno(在errno.h中)会包含一个ERROR代码,用于标识错误。用户可使用库函数
perror("error message");
来打印某个错误消息,该消息后面跟着一个描述错误的字符串。
每当一个进程进入Kmode时,它可能不会立即返回到Umode。在某些情况下,它可能根本不会返回到Umode。例如,_exit() syscall 和大多数陷阱会导致进程在内核中终止,这样它永远都不会返回到Umode。当某进程即将退出Kmode时,操作系统内核可能会切换进程以运行另一个具有更高优先级的进程。
四、进程管理的系统调用
在本节中,我们将讨论Linux中与进程管理相关的以下系统调用。
fork()、wait()、exec()、exit()
每个都是发出实际系统调用的库函数:
int syscall(int a, int b, int c, int d);
其中,第一个参数a表示系统调用号,b、c、d表示对应核函数的参数。在基于Intel x86的Linux中,系统调用是由汇编指令INT 0x80实现的,使得CPU进入Linux内核来执行由系统调用号a标识的核函数。
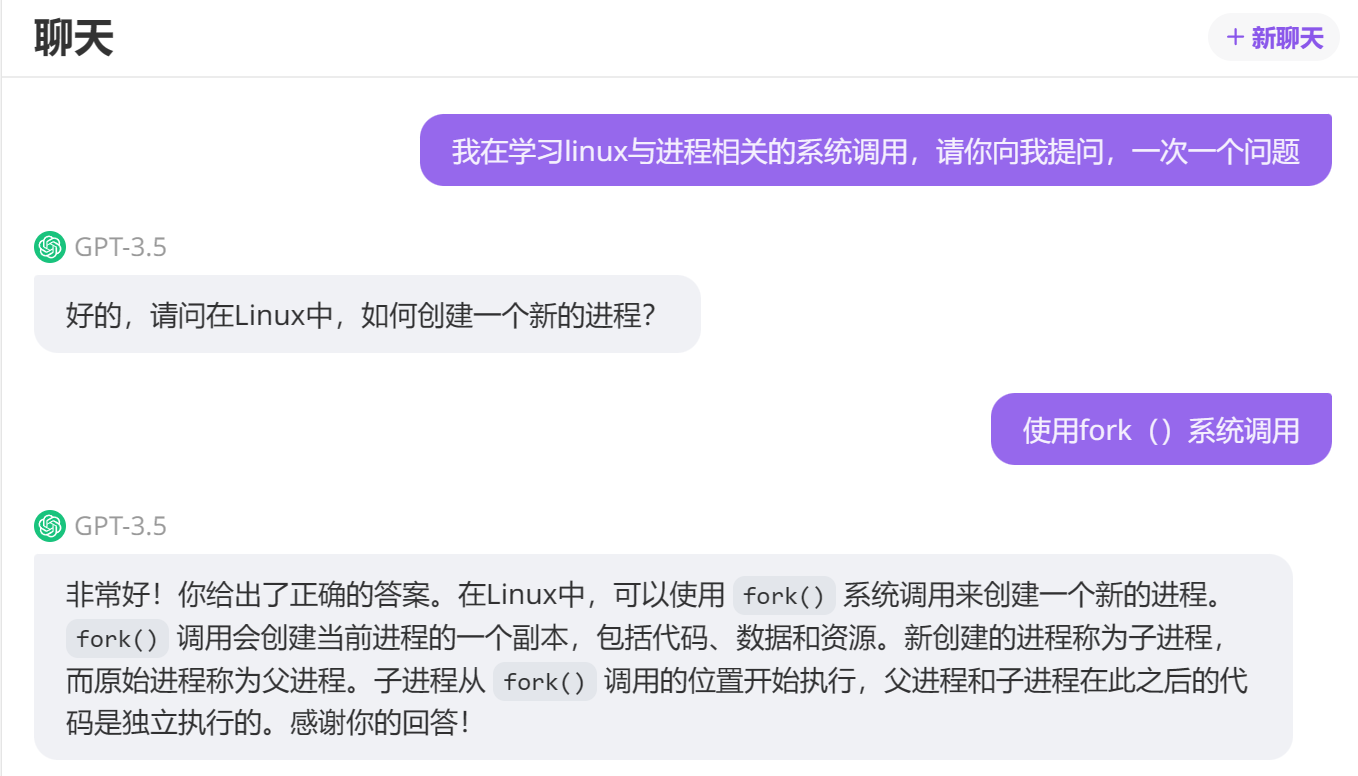
(1)fork
Usage: int pid = fork();
fork()创建子进程并返回子进程的pid,如果fork()失败则返回-1。
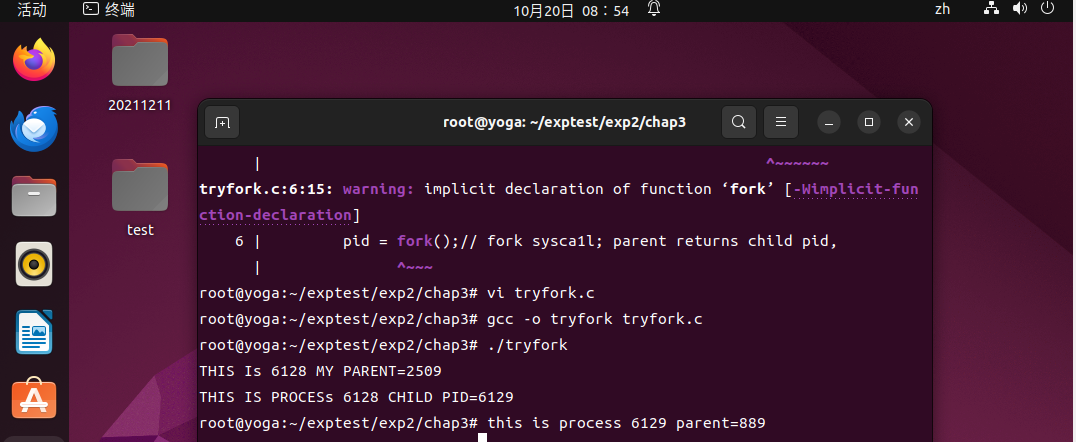
//tryfork.c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int pid;
printf ( "THIS Is %d MY PARENT=%d\n" ,getpid(),getppid() );
pid = fork();// fork sysca1l; parent returns child pid,
if (pid){ // PARENTEXECUTES THIS PART
printf ("THIS IS PROCESs %d CHILD PID=%d\n",getpid(),pid);
}
else{ // child executes this part
printf ("this is process %d parent=%d\n",getpid(),getppid());
}
return 0;
}
(2)进程的执行顺序
//ordexe.c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(){
int pid=fork();// fork a child
if(pid) {// PARENT
printf ("PARENT %d CHILD=%d\n",getpid(),pid);
//sleep(1); // sleep 1 second ==> let child run next
printf ( "PARENT%d EXIT\n",getpid());
}
else{
// child
printf ("child %d start my parent=%d\n",getpid(),getppid());
sleep(2); // sleep 2 seconds => let parent die first
printf ("child %d exit my parent=%d\n",getpid(),getppid());
}
return 0;
}
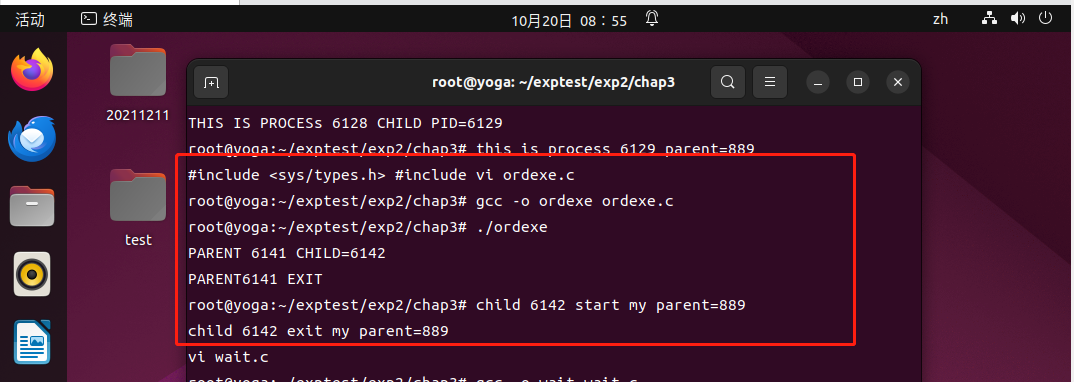
(3)进程终止
1.正常终止:当内核中的某个进程终止时,他会将_exit(value)系统调用中的值记录为进程PROC结构体中的退出状态。并通知他的二父进程并使该进程成为僵尸进程。父进程课通过系统调用找到僵尸子进程,获得其pid和退出状态
2.异常终止:当某进程遇到异常时,他会陷入操作系统内核。内核的异常处理程序将陷阱错位类型转换为一个幻数,称为信号,将信号传递给进程,时进程终止。
(4)等待子进程终止
//wait.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main(){
int pid, status;
pid = fork();
if(pid){ // PARENT:
printf("PARENT %d wAITS FOR CHILD %d TO DIE\n",getpid(),pid);
pid=wait(&status);// wait for zOMBIE child process
printf ("DEAD CHILD=%d,status=0x%04x\n",pid, status);
}
else{// child:
printf("child %d dies by exit(VALUE)\n",getpid());
exit (100);
}
}

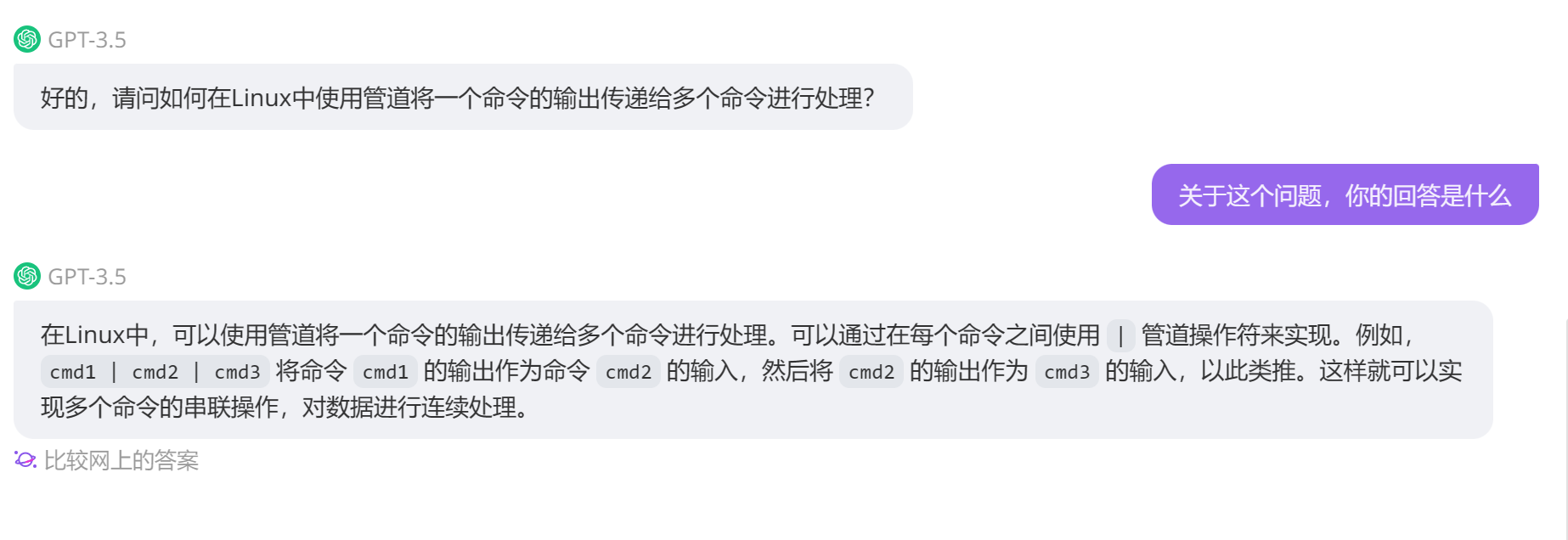
五、管道
(1)管道命令处理
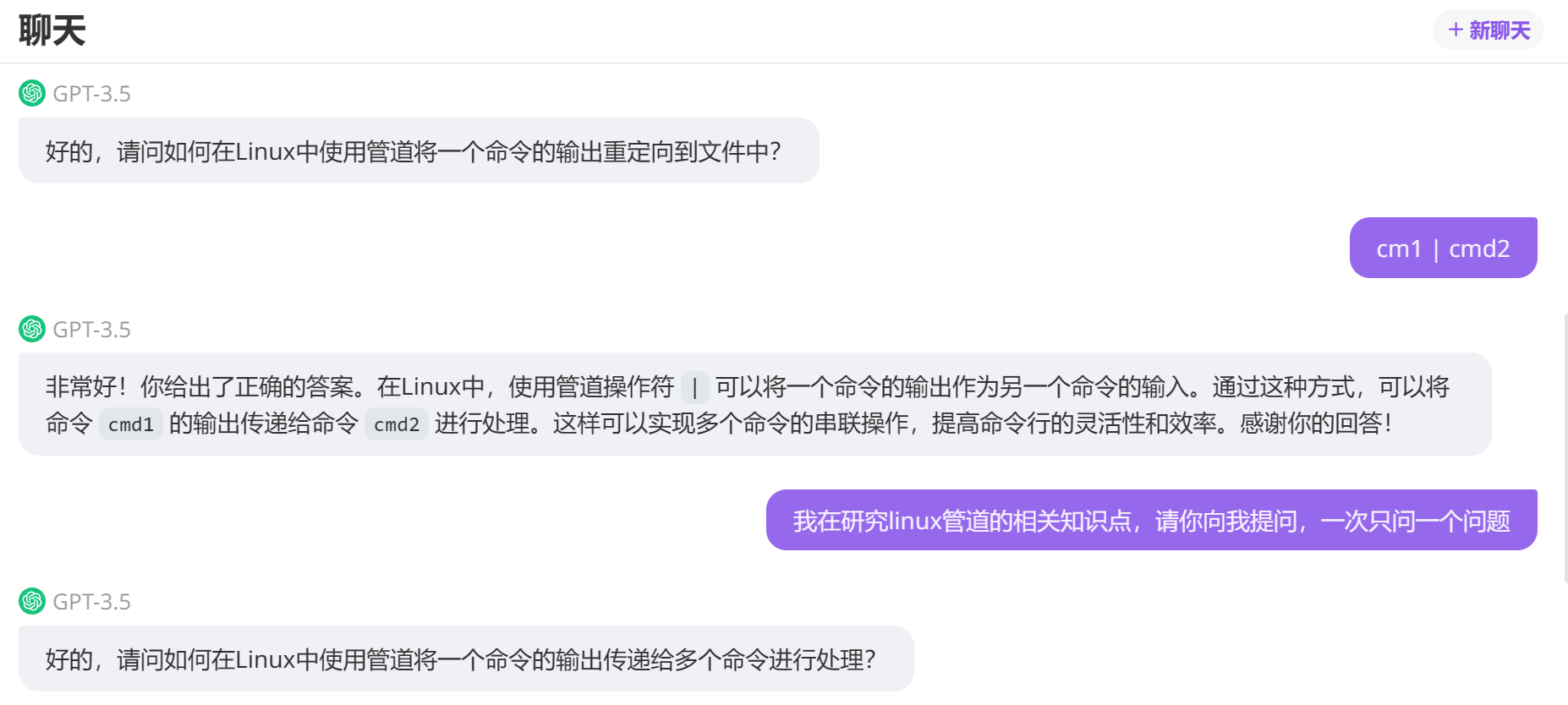
在Unix/Linux中,命令行:cmd1 | cmd2
sh将通过一个进程运行cmd1,并通过另一个进程运行cmd2,他们通过一个管道连接在一起,因此cmd1的输出变为cmd2的输入
(2)命令管道
1.在sh中,通过mknod命令创建一个命令管道:
mknod mypipe p
2.或在C语言中发出mknod()系统调用
int r = mknod("mypipe",s_IFIFP,0);
3.进程可像访问普通文件一样发个文命名管道。
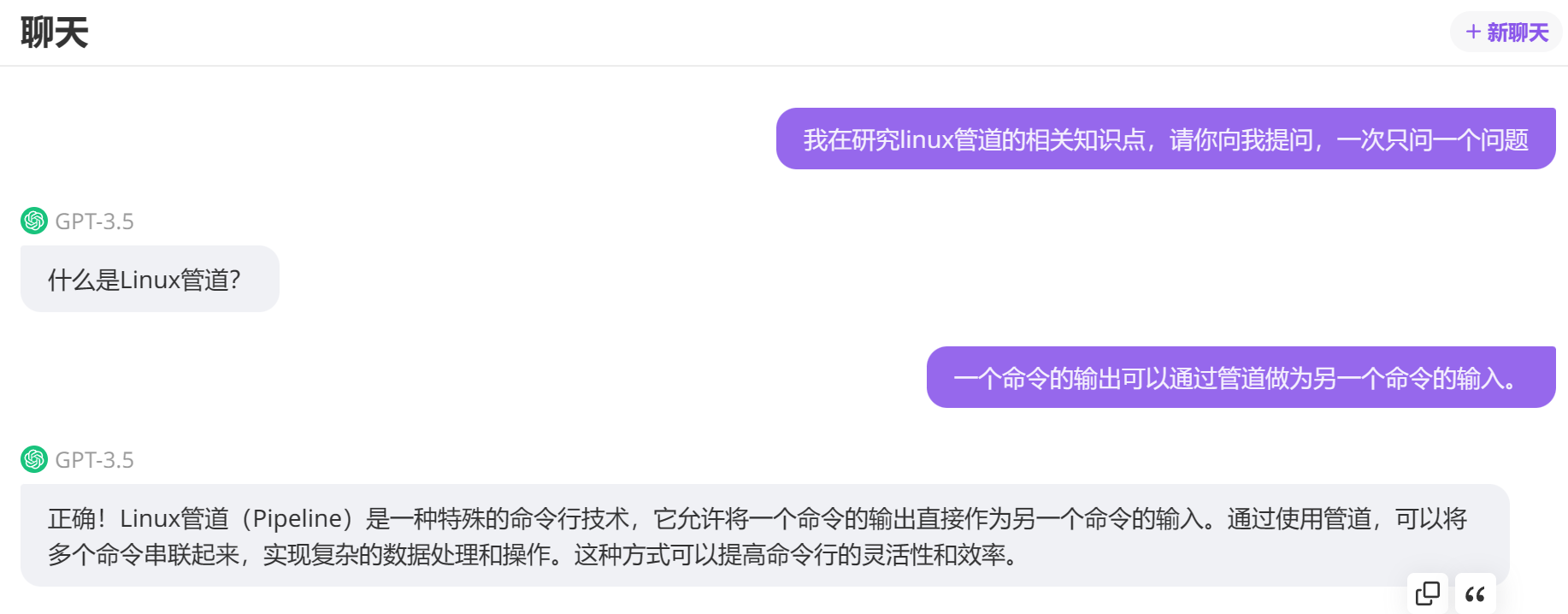
六、CHATGPT提问

七、代码链接
https://gitee.com/yogahuu/exptest/commit/b5ad3a3d4daf4b799f46b02518fd4bf61fdc6a2a