--------------
Golang线程池实现百万级高并发
本文基于Golang实现线程池,从而可以达到百万级别的高并发请求。本文实现的代码在https://github.com/lk668/threadpool可见。
1. Golang并发简介
Golang原生的goroutine可以很轻松实现并发编程。Go语言的并发是基于用户态的并发,这种并发方式就变得非常轻量,能够轻松运行几万并发逻辑。Go 的并发属于 CSP 并发模型的一种实现,CSP 并发模型的核心概念是:不要通过共享内存来通信,而应该通过通信来共享内存。
2. 并发方案演进
2.1 直接使用goroutine
直接使用goroutine启动一个新的线程来进行任务的执行
1
|
go handler(request)
|
2.2 缓冲队列
利用channel实现一个缓冲队列,每次请求先放入缓冲队列,然后从缓冲队列读取数据,一次执行
1
|
type Job interface{
|
该方案在请求量低于缓冲队列长度时,可以应对并发请求。但是当并发请求量大于缓冲队列长度时,channel会出现阻塞情况。
2.3 线程池实现百万级高并发
更好的实现方案是利用job队列+线程池来实现,具体如下所示:
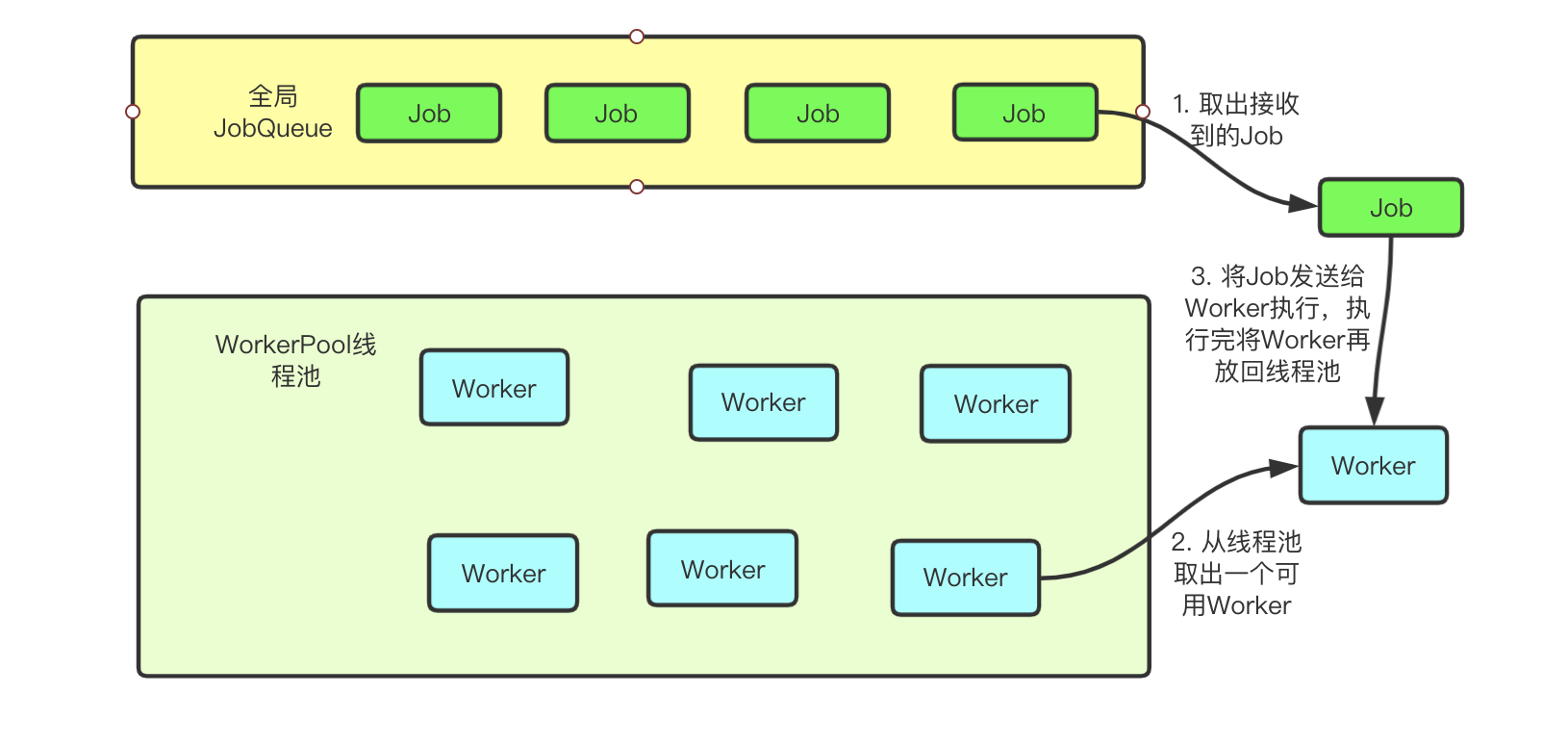
有个全局JobQueue,用来存储需要执行的Job,有个WorkerPool的线程池,用来存储空闲的Worker。当JobQueue中有Job时,从JobQueue获取Job对象,从WorkerPool获取空闲Worker,将Job对象发送给Worker,进行执行。每个Worker都是一个独立的Goroutine。从而真正意义上实现高并发。
代码实现主要分为三部分
2.3.1 Job定义
Job是一个interface,其下有个函数RunTask,用户定制化的任务,需要实现RunTask函数。JobChan是一个Job channel结构。Job是高并发需要执行的任务
1
|
type Job interface {
|
2.3.2 Worker定义
Worker就是高并发里面的一个线程,启动的时候是一个Goroutine。Worker结构一需要一个JobChan,用来接收从全局JobQueue里面获取的Job对象。有个Quit的channel,用来接收退出信号。需要一个Start函数,将自己注册到WorkerPool,然后监听Job,有Job传入时,处理Job的RunTask,处理完成之后,重新将自己添加回WorkerPool。
1
|
// Worker结构体
|
2.3.3 WorkerPool定义
WorkerPool是一个线程池,用来存储Worker。所以需要一个Size变量,用来表示这个Pool存储的Worker的个数。需要一个JobQueue,用来充当全局JobQueue的作用,所有的job先存储到该全局JobQueue中。有个WorkerQueue是个channel,用来存储空闲的Worker,有Job来的时候,从WorkerQueue里面取出一个Worker,执行相应的任务,执行完成以后,重新将Worker放回WorkerQueue。
WorkerPool需要一个启动函数,一个是来启动Size数量的Worker线程,一个是需要启动一个新的线程,来接收Job。
1
|
// 线程池
|
2.3.4 代码调用举例
接下来,举例分析如何使用该线程池。首先需要定义你要执行的任务,实现RunTask函数。然后初始化一个WorkerPool,将模拟百万请求的数据发送给全局JobQueue。交给线程池进行任务处理。
1
|
//需要执行任务的结构体
|
参考