1. 背景
有一个这样的数据集:字段和字段的值是两列
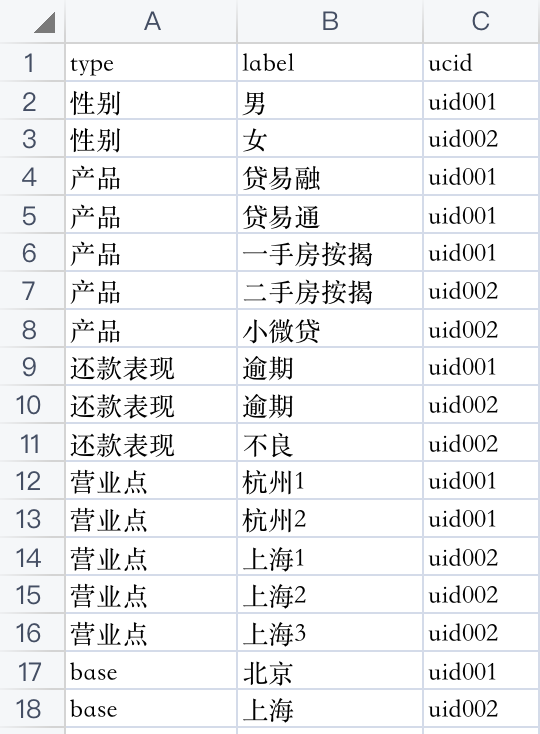
目的是将这个数据转换成规整的一个特征是一列的数据:
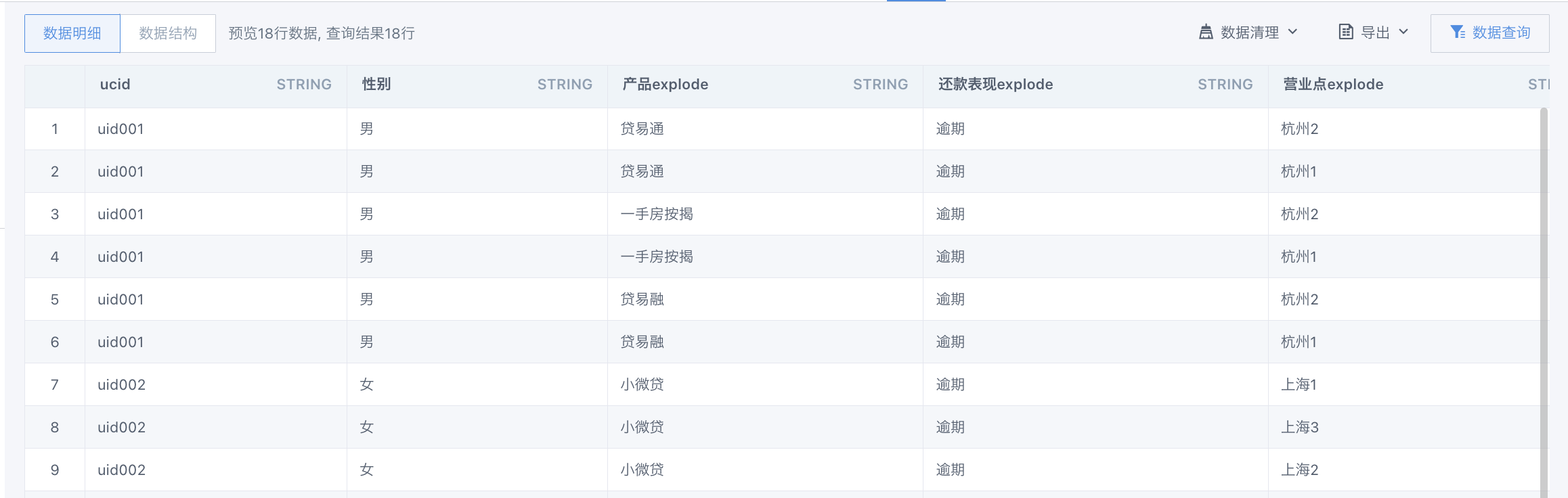
2. 做法
第一步:先造出列
select ucid
,CASE WHEN type ='性别' THEN label end `性别`
,CASE WHEN type ='产品' THEN label end `产品`
,CASE WHEN type ='还款表现' THEN label end `还款表现`
,CASE WHEN type ='营业点' THEN label end `营业点`
,CASE WHEN type ='base' THEN label end `base`
From input
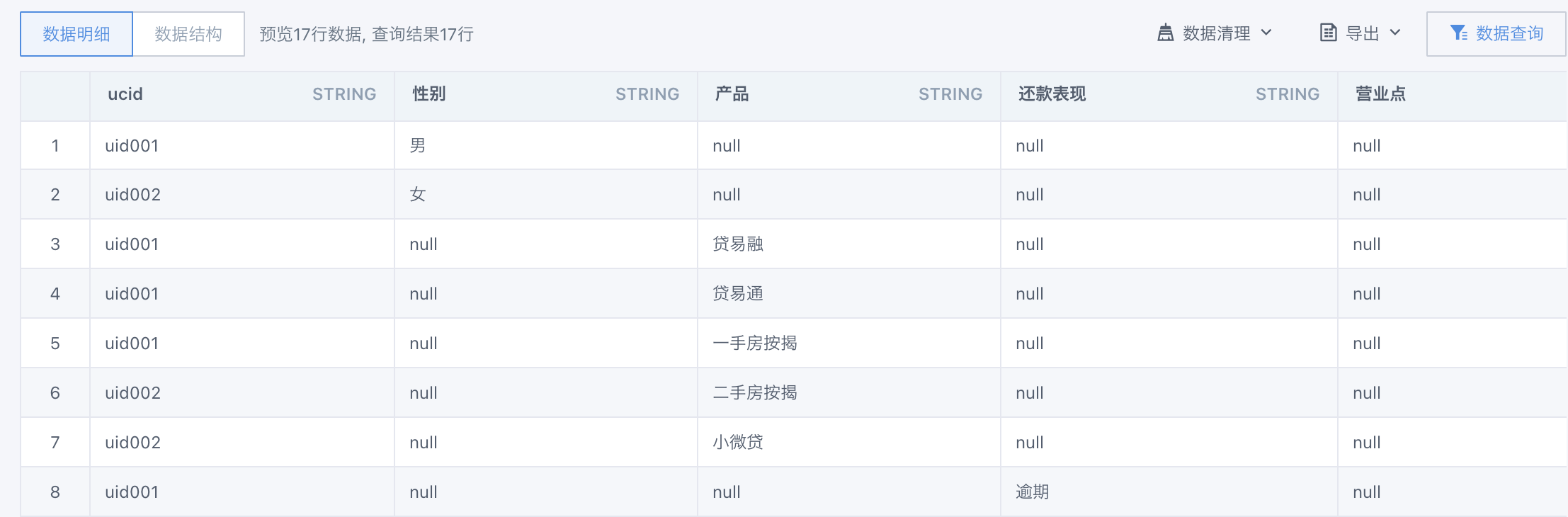
第二步:多行合并为一行

select ucid
,concat_ws(',',collect_set(CASE WHEN type ='性别' THEN label end)) `性别`
,concat_ws(',',collect_set(CASE WHEN type ='产品' THEN label end)) `产品`
,concat_ws(',',collect_set(CASE WHEN type ='还款表现' THEN label end)) `还款表现`
,concat_ws(',',collect_set(CASE WHEN type ='营业点' THEN label end)) `营业点`
,concat_ws(',',collect_set(CASE WHEN type ='base' THEN label end)) `base`
From input
group by `ucid`
第三步:特征枚举值展开
select ucid, explode(split(`产品`,',')) as `产品` from (
select ucid
,concat_ws(',',collect_set(CASE WHEN type ='性别' THEN label end)) `性别`
,concat_ws(',',collect_set(CASE WHEN type ='产品' THEN label end)) `产品`
,concat_ws(',',collect_set(CASE WHEN type ='还款表现' THEN label end)) `还款表现`
,concat_ws(',',collect_set(CASE WHEN type ='营业点' THEN label end)) `营业点`
,concat_ws(',',collect_set(CASE WHEN type ='base' THEN label end)) `base`
From input
group by `ucid`
)
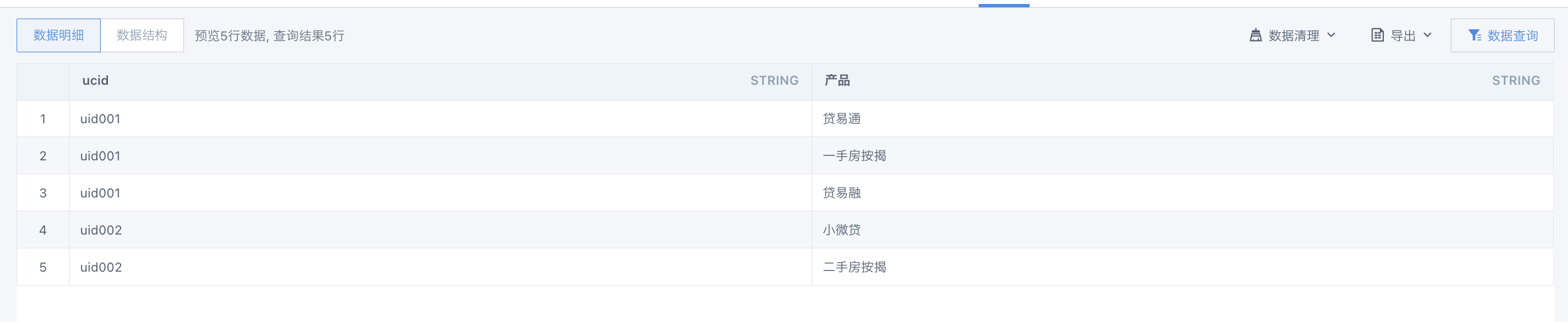
上面是示范展开一列。由于一个select里只能有一个explode,因此,为了得到最终想要的数据,需要explode多层(哭哭)
select ucid, `性别`, `产品explode`, `还款表现explode`, `营业点explode`, `base` ,explode(split(`营业点`,',')) as `营业点explode` from (
select *, explode(split(`还款表现`,',')) as `还款表现explode` from (
select *, explode(split(`产品`,',')) as `产品explode` from (
select ucid
,concat_ws(',',collect_set(CASE WHEN type ='性别' THEN label end)) `性别`
,concat_ws(',',collect_set(CASE WHEN type ='产品' THEN label end)) `产品`
,concat_ws(',',collect_set(CASE WHEN type ='还款表现' THEN label end)) `还款表现`
,concat_ws(',',collect_set(CASE WHEN type ='营业点' THEN label end)) `营业点`
,concat_ws(',',collect_set(CASE WHEN type ='base' THEN label end)) `base`
From input
group by `ucid`
)))
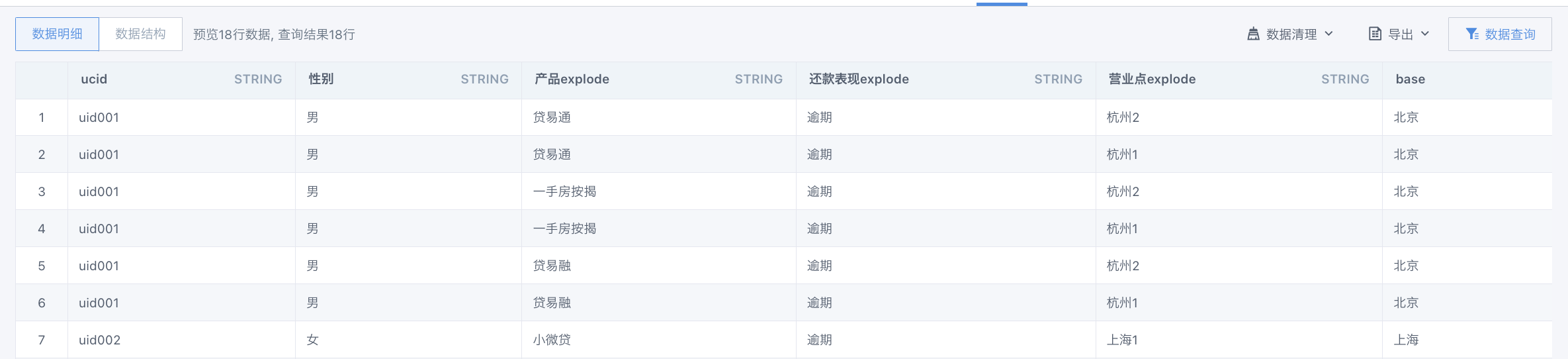
其实 spark SQL 3.3.2可以用lateral view 实现一次explode多个字段:
https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-lateral-view.html
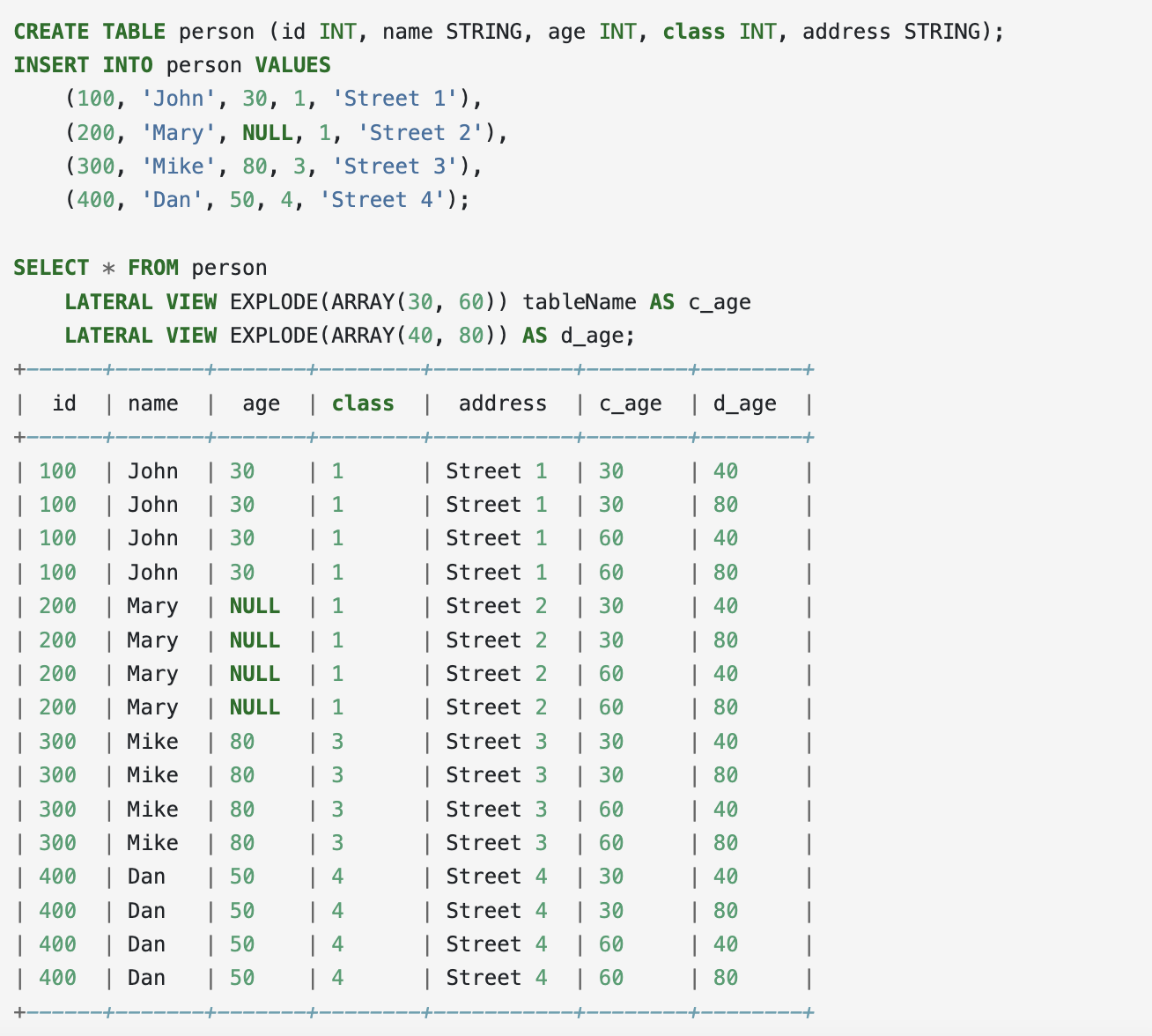
CREATE TABLE person (id INT, name STRING, age INT, class INT, address STRING);
INSERT INTO person VALUES
(100, 'John', 30, 1, 'Street 1'),
(200, 'Mary', NULL, 1, 'Street 2'),
(300, 'Mike', 80, 3, 'Street 3'),
(400, 'Dan', 50, 4, 'Street 4');
SELECT * FROM person
LATERAL VIEW EXPLODE(ARRAY(30, 60)) tableName AS c_age
LATERAL VIEW EXPLODE(ARRAY(40, 80)) AS d_age;
3. 函数
1. concat_ws 和concat的联系与区别
concat(col1, col2, ..., colN) - Returns the concatenation of col1, col2, ..., colN.,可以拼接多个字符串
concat_ws(sep[, str | array(str)]+) - Returns the concatenation of the strings separated by sep.
返回用指定分隔符进行拼接的字符串,指定的分隔符放在第一个参数位置,后面的参数默认为需要进行拼接的字符串。
二者的区别在于:
concat中若有一个参数为null ,则返回null。而concat_ws,不会因为存在null 值就返回null 。
select concat("-","DS","A", "B",null) from input
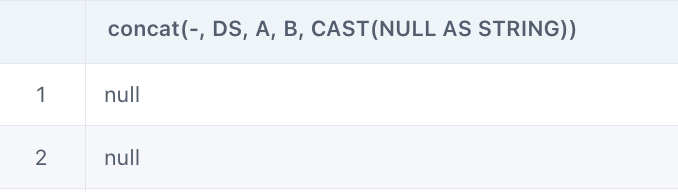
select concat_ws("-","DS","A", "B",null) from input

2. collect_set 函数
collect_set(expr) - Collects and returns a set of unique elements.
3. explode 函数
explode里面的参数,可以是 array ,也可以是 map
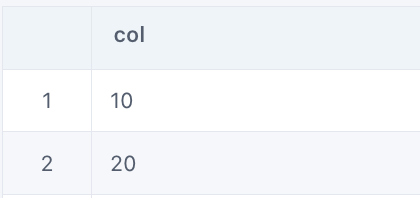
explode(expr) - Separates the elements of array expr into multiple rows, or the elements of map expr into multiple rows and columns. Unless specified otherwise, uses the default column name col for elements of the array or key and value for the elements of the map
select explode(array(10, 20)) from input
array如果需要分割,需要和split嵌套使用
SELECT explode(split('1,2,3',',')) from input

SELECT explode(map('A','1','B','2','C','3')) from input

时间的展开:
select `date`,`min_date`,`max_date`,
explode(sequence(
`min_date`,`max_date`,interval 1 day
)) as `展开日期`
# day是day颗粒度,也可以换成month