StandAlone HA的原理
基于Zookeeper做状态的维护,开启多个Master进程,一个作为活跃,其他的作为备份,当活跃进程宕机,备份Master进行接管。
步骤
前提: 确保Zookeeper 和 HDFS 均已经启动
先在spark-env.sh中, 删除: SPARK_MASTER_HOST=node1
原因: 配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现
# 指定Zookeeper的连接地址
# 指定在Zookeeper中注册临时节点的路径
将spark-env.sh 分发到每一台服务器上
scp spark-env.sh node2:/export/server/spark/conf/
scp spark-env.sh node3:/export/server/spark/conf/
停止当前StandAlone集群
sbin/stop-all.sh
启动集群:
# 在node1上 启动一个master 和全部worker
sbin/start-all.sh
# 注意, 下面命令在node2上执行
sbin/start-master.sh
# 在node2上启动一个备用的master进程
master主备切换
提交一个spark任务到当前alivemaster上:
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 1000
在提交成功后, 将alivemaster直接kill掉
不会影响程序运行: 当新的master接收集群后, 程序继续运行, 正常得到结果.
结论 HA模式下, 主备切换 不会影响到正在运行的程序.
SparkOnYarn本质
Master角色由YARN的ResourceManager担任。
Worker角色由YARN的NodeManager担任。
Driver角色运行在YARN容器内 或 提交任务的客户端进程中。
真正干活的Executor角色运行在YARN提供的容器内。
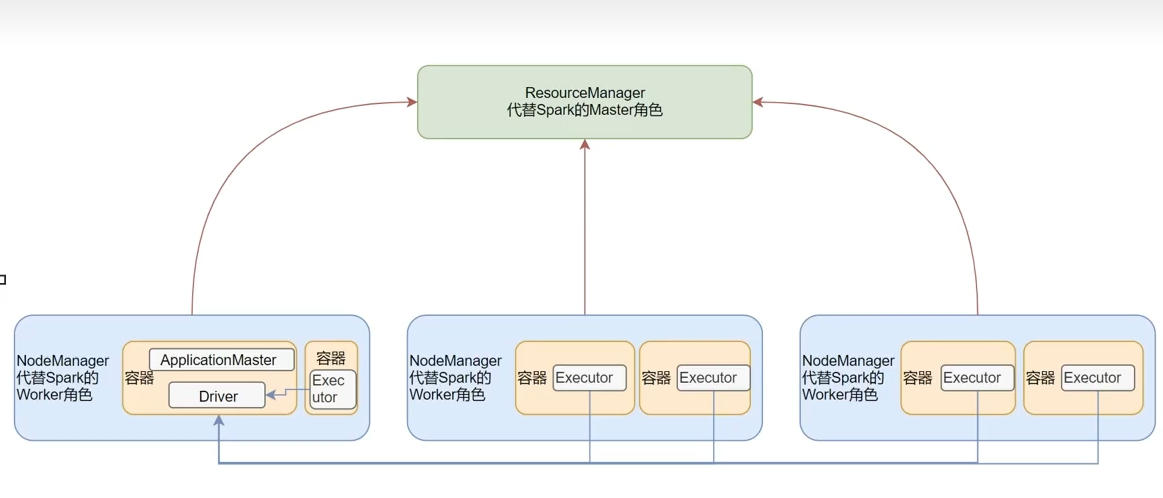
部署模式DeployMode
SparkOnYARN有两种运行模式,一种是Cluster模式一种是Client模式。这两种模式的区别就是Driver运行的位置。
Cluster模式:Driver运行在YARN容器内部 ,和ApplicationMaster在同一个容器中;
Client模式:Driver运行在客户端进程中,比如Driver运行在Spark-submit程序的进程中。
