Cost Aggregation with Transformers for Sparse Correspondence:2022
背景:
该论文结合了SuperGlue和CATs,将里面所有手工制作的部分都代替了。将CATs引入该模型,用Transformer取代手工制作的成本聚合方法,用于具有自关注层全局接受域的可学习成本聚合。(PS:成本聚合: 成本聚合是指在立体匹配等任务中,对计算得到的匹配成本进行整合,以减小误差、噪声和不一致性。成本聚合的目标是在每个像素位置上选择合适的匹配,同时考虑相邻像素之间的一致性。这有助于提高深度图或光流场的准确性。成本聚合通常涉及计算聚合代价(Cost Aggregation Cost)并应用某种滤波或聚合函数。)
具体方法(只讲述与SuperGlue不同的地方):

上图是总体框架,可以看出注意图神经网络并没有改进,所以主要讲述后面的分数预测(加入成本聚合)部分。
分数预测:
Sij矩阵的获得与SuperGlue获得方法相同。
得到Sij矩阵后,将其输入到上图的网络中,因为transformer aggregator由于位置嵌入而期望采用固定大小的输入,但是Sij矩阵由于不同的图像提取的关键点数量不同而尺寸不固定。所以将S填充到K×K的固定形状中,S中的填充区域指的是完全不匹配的配对。我们使用一个填充值p,该值为 S 的最小值的负值,以便Transformer能够意识到填充区域的上下文含义,并成功地优化分数矩阵。
在初始实验中,作者考虑过零填充,但这是不可行的,因为在分数图的分布中,零是具有意义的,会对后续操作产生影响。在填充过程中,同时存储填充区域的索引数组,这将在后续过程中用于注意力掩码。
Transformer Aggregator:
对比CATs中的方法,该论文去除了外观关联,因为它不容易与框架中的填充兼容,并且使分数矩阵很大,在某些稀疏对应的情况下可能会导致内存问题。且该论文忽略了维度关系,因为输入的分数矩阵就是一维的,并不像CATs的输入,是不同层的特征图上采样拼接后的结果。
在Transformer中的自注意机制中,使用注意力掩码(attention masking)来最小化Softmax操作中填充区域的影响,让填充区域对Softmax没有影响。这就使用了上述存储的索引数组,有索引数组的地方尽量使Softmax后的结果趋向于0。
Swapping Self-Attention:
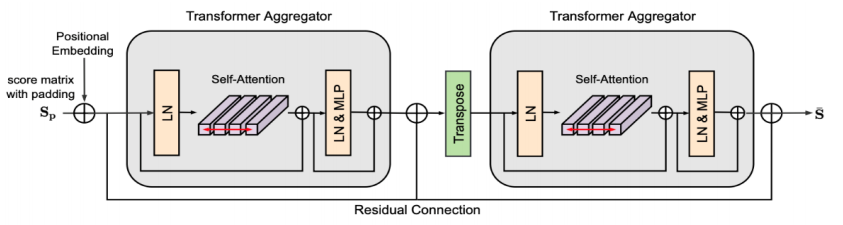
为了使得匹配分数矩阵对输入图像的顺序不敏感,并施加一致的匹配分数,应该使用互为倒数的分数作为辅助来推断可信的对应关系。首先将填充的匹配分数矩阵输入第一个Transformer聚合器。然后,对输出和掩码进行转置,并将其输入到后一个聚合器。其中,共享两个Transformer聚合器的参数,以获得互为倒数的分数。在每一步中,都使用残差连接来稳定学习过程并为匹配提供更好的初始化。(由图可以观察出)
这个步骤的主要目的是通过应用自注意力机制,利用双向的匹配分数信息,获得更一致和可靠的对应关系。
归一化与损失函数与SuperGlue相同。
训练过程:
为了训练网络,提出了一个两阶段的训练方案。
1)首先在不使用 transformer aggregator 的情况下对注意图神经网络进行训练;
2)在确定注意图神经网络参数的同时对整个网络进行训练。为了公平的比较,我们让SuperGlue和SuperCATs在注意图神经网络中共享相同的权重。
实验结果:提高了SuperGlue的匹配精度。
注意:成本聚合的目标是在每个像素位置上选择合适的匹配,同时考虑相邻像素之间的一致性。所以CATs方法实际是对密集匹配方法进行研究。但本论文去除了CATs的一些因素,使其适应于稀疏匹配。
- Correspondence Transformers Aggregation 笔记 Sparsecorrespondence transformers aggregation笔记 transformers white-box reduction sparse image transformers recognition笔记 transformers huggingface started笔记 pretrainedmodel transformers modeloutput笔记 correspondence correspondence learning outliers feature sparse sparse4d sparse4