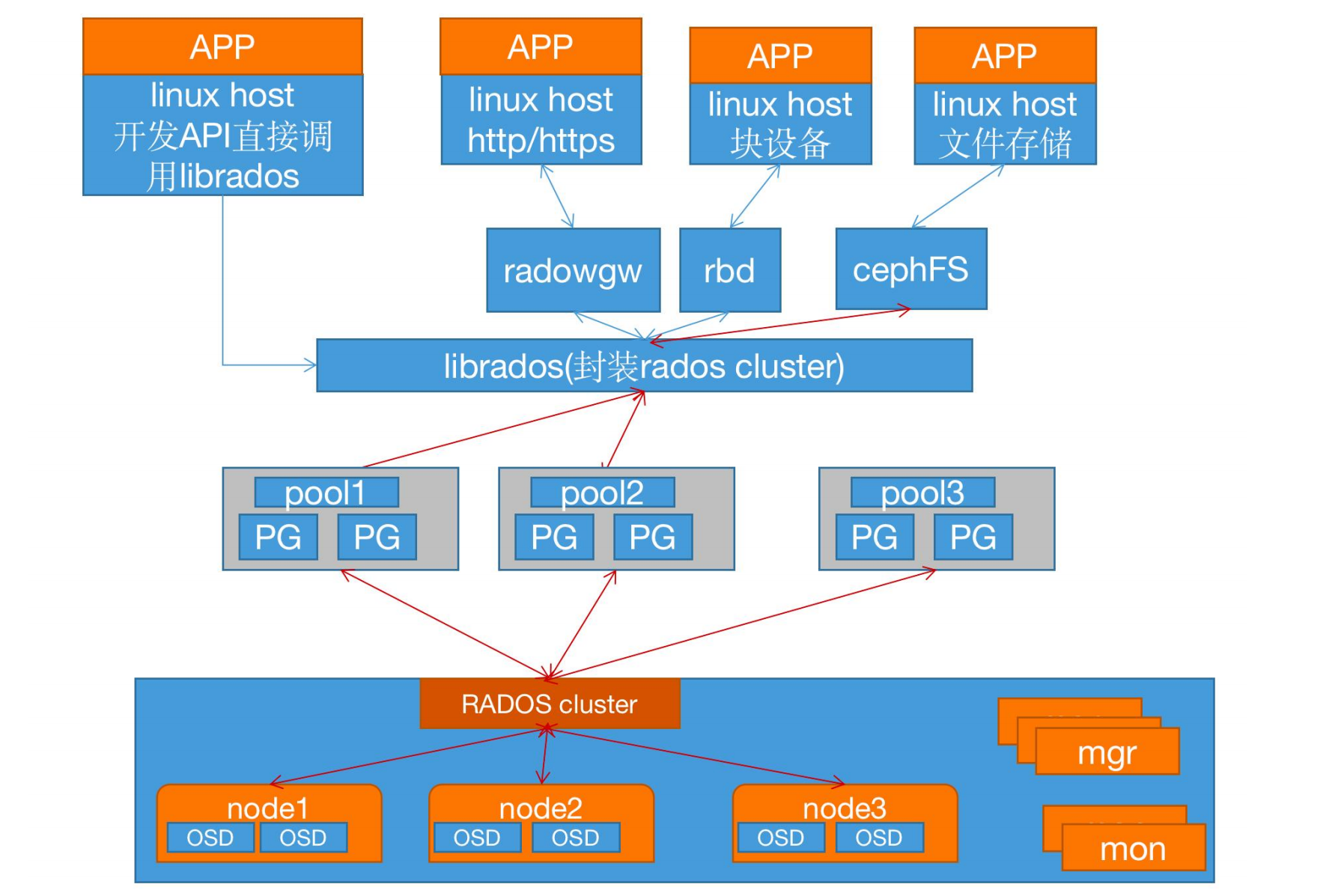
LIBRADOS、RADOSGW、RBD 和 Ceph FS 统称为 Ceph 客户端接口。RADOSGW、RBD、Ceph FS 是基于 LIBRADOS 提供的多编程语言接口开发的。
1.1、一个 ceph 集群的组成部分:
若干的 Ceph OSD(对象存储守护程序)
至少需要一个 Ceph Monitors 监视器(1,3,5,7...)
两个或以上的 Ceph 管理器 managers,运行 Ceph 文件系统客户端时
还需要高可用的 Ceph Metadata Server(文件系统元数据服务器)。
RADOS cluster:由多台 host 存储服务器组成的 ceph 集群
OSD(Object Storage Daemon):每台存储服务器的磁盘组成的存储空间
Mon(Monitor):ceph 的监视器,维护 OSD 和 PG 的集群状态,一个 ceph 集群至少要有一个mon,可以是一三五七等等这样的奇数个。
Mgr(Manager):负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载等。
(1) Monitor(ceph-mon) ceph 监视器:
在一个主机上运行的一个守护进程,用于维护集群状态映射(maintains maps of thecluster state),比如 ceph 集群中有多少存储池、每个存储池有多少 PG 以及存储池和 PG的映射关系等, monitor map, manager map, the OSD map, the MDS map, and the CRUSH map,这些映射是 Ceph 守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的身份验证(认证使用 cephX 协议)。通常至少需要三个监视器才能实现冗余和高可用性。
(2) Managers(ceph-mgr)的功能:
在一个主机上运行的一个守护进程,Ceph Manager 守护程序(ceph-mgr)负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载。CephManager 守护程序还托管基于 python 的模块来管理和公开 Ceph 集群信息,包括基于 Web的 Ceph 仪表板和 REST API。高可用性通常至少需要两个管理器。
(3) Ceph OSDs(对象存储守护程序 ceph-osd):
提供存储数据,操作系统上的一个磁盘就是一个 OSD 守护程序,OSD 用于处理 ceph集群数据复制,恢复,重新平衡,并通过检查其他 Ceph OSD 守护程序的心跳来向 Ceph监视器和管理器提供一些监视信息。通常至少需要 3 个 Ceph OSD 才能实现冗余和高可用性。
(4) MDS(ceph 元数据服务器 ceph-mds):
代表 ceph 文件系统(NFS/CIFS)存储元数据,(即 Ceph 块设备和 Ceph 对象存储不使用MDS)
(5) Ceph 的管理节点
1.ceph 的常用管理接口是一组命令行工具程序,例如 rados、ceph、rbd 等命令,ceph 管理员可以从某个特定的 ceph-mon 节点执行管理操作
2.推荐使用部署专用的管理节点对 ceph 进行配置管理、升级与后期维护,方便后期权限管理,管理节点的权限只对管理人员开放,可以避免一些不必要的误操作的发生。
(6) ceph 术语
http://docs.ceph.org.cn/glossary/
2、ceph 逻辑组织架构
Pool:存储池、分区,存储池的大小取决于底层的存储空间。
PG(placement group):一个 pool 内部可以有多个 PG 存在,pool 和 PG 都是抽象的逻辑概念,一个 pool 中有多少个 PG 可以通过公式计算。
OSD(Object Storage Daemon,对象存储设备):每一块磁盘都是一个 osd,一个主机由一个或多个 osd 组成.
ceph 集群部署好之后,要先创建存储池才能向 ceph 写入数据,文件在向 ceph 保存之前要先进行一致性 hash 计算,计算后会把文件保存在某个对应的 PG 的,此文件一定属于某个pool 的一个 PG,在通过 PG 保存在 OSD 上。
数据对象在写到主 OSD 之后再同步对从 OSD 以实现数据的高可用。
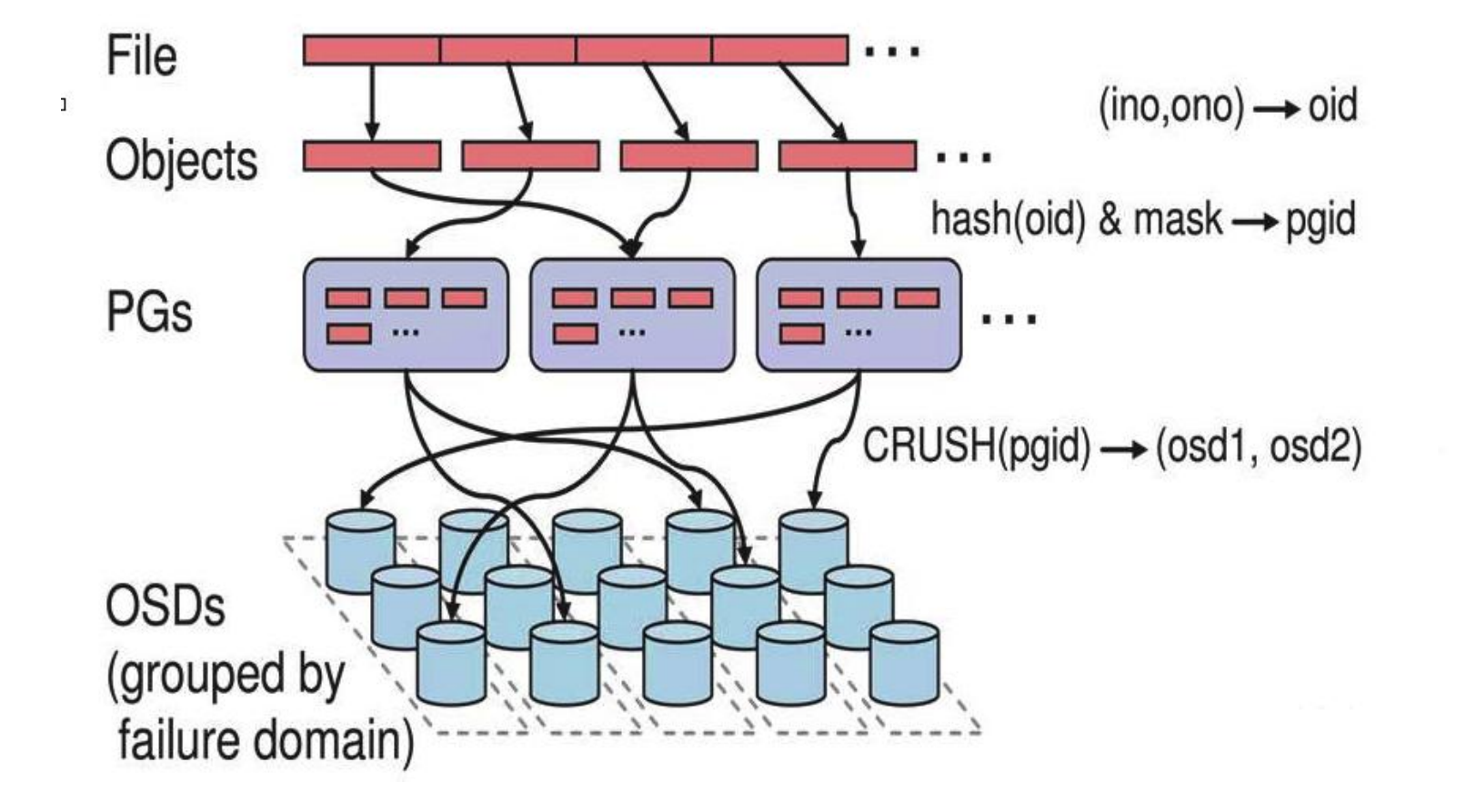
注:存储文件过程:
第一步: 计算文件到对象的映射:
计算文件到对象的映射,假如 file 为客户端要读写的文件,得到 oid(object id) = ino + ono
ino:inode number (INO),File 的元数据序列号,File 的唯一 id。
ono:object number (ONO),File 切分产生的某个 object 的序号,默认以 4M 切分一个块大小。
第二步:通过 hash 算法计算出文件对应的 pool 中的 PG:
通过一致性 HASH 计算 Object 到 PG, Object -> PG 映射 hash(oid) & mask-> pgid
第三步: 通过 CRUSH 把对象映射到 PG 中的 OSD
通过 CRUSH 算法计算 PG 到 OSD,PG -> OSD 映射:
[CRUSH(pgid)->(osd1,osd2,osd3)]
在线进制转换:https://tool.oschina.net/hexconvert
64-1=63(0~63=累计 64 个),
1100100=100(对象的 hash 值) 100&64=36,200&64=8
0111111=63(PG 总数)
--------------------------
0100100=36(与运算结果)
第四步:PG 中的主 OSD 将对象写入到硬盘
第五步: 主 OSD 将数据同步给备份 OSD,并等待备份 OSD 返回确认
第六步: 主 OSD 将写入完成返回给客户端
二、部署 ceph 集群
1、系统环境初始化
时间同步(各服务器时间必须一致)
关闭 selinux 和防火墙(如果是 Centos)
配置主机域名解析或通过 DNS 解析
2、部署 RADOS 集群:
https://mirrors.aliyun.com/ceph/ #阿里云镜像仓库
http://mirrors.163.com/ceph/ #网易镜像仓库
https://mirrors.tuna.tsinghua.edu.cn/ceph/ #清华大学镜像源
2.1、仓库准备
各节点配置 ceph yum 仓库:
导入 key 文件:
#支持 https 镜像仓库源:
apt install -y apt-transport-https ca-certificates curl software-properties-common
导入 key:
wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
2.2、添加ceph镜像源(所有节点)
focal是ubuntu20.04版本,其它版本需要换
# echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific focal main" >> /etc/apt/sources.list
apt update
2.3、创建 ceph 集群部署用户 cephadmin:
推荐使用指定的普通用户部署和运行 ceph 集群,普通用户只要能以非交互方式执行 sudo命令执行一些特权命令即可,新版的 ceph-deploy 可以指定包含 root 的在内只要可以执行 sudo 命令的用户,不过仍然推荐使用普通用户,ceph 集群安装完成后会自动创建ceph 用户(ceph 集群默认会使用 ceph 用户运行各服务进程,如 ceph-osd 等),因此推荐使用除了 ceph 用户之外的比如 cephuser、cephadmin 这样的普通用户去部署和 管理ceph 集群。
cephadmin 仅用于通过 ceph-deploy 部署和管理 ceph 集群的时候使用,比如首次初始化集群和部署集群、添加节点、删除节点等,ceph 集群在 node 节点、mgr 等节点会使用ceph 用户启动服务进程。
在包含 ceph-deploy 节点的存储节点、mon 节点和 mgr 节点等创建 cephadmin 用户。
groupadd -r -g 2088 cephadmin && useradd -r -m -s /bin/bash -u 2088 -g 2088 cephadmin && echo cephadmin:123456 | chpasswd
各服务器允许 cephadmin 用户以 sudo 执行特权命令:
echo "cephadmin ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
配置免秘钥登录:
在 ceph-deploy 节点配置秘钥分发,允许 cephadmin 用户以非交互的方式登录到各 cephnode/mon/mgr 节点进行集群部署及管理操作,即在 ceph-deploy 节点生成秘钥对,然后分发公钥到各被管理节点:
su - cephadmin
ssh-keygen
ssh-copy-id cephadmin@10.247.8.201 ......
配置主机名解析:
10.247.8.201 ceph-deploy.example.local ceph-deploy
10.247.8.202 ceph-mon1.example.local ceph-mon1
10.247.8.203 ceph-mon2.example.local ceph-mon2
10.247.8.204 ceph-mon3.example.local ceph-mon3
10.247.8.205 ceph-mgr1.example.local ceph-mgr1
10.247.8.206 ceph-mgr2.example.local ceph-mgr2
10.247.8.207 ceph-node1.example.local ceph-node1
10.247.8.208 ceph-node2.example.local ceph-node2
10.247.8.209 ceph-node3.example.local ceph-node3
10.247.8.210 ceph-node4.example.local ceph-node4
2.4、安装 ceph 部署工具:
在 ceph 部署服务器安装部署工具 ceph-deploy
Ubuntu:
Ubuntu 20.04已经无法通过apt来安装python2的pip2了,只能安装python3的pip。
sudo apt install python2
wget https://bootstrap.pypa.io/pip/2.7/get-pip.py
sudo python2 get-pip.py
python2 -m pip install ceph-deploy
2.5、初始化 mon 节点:
su - cephadmin
mkdir ceph-cluster
cd ceph-cluster
Ubuntu 各服务器需要单独安装 Python2:
sudo apt install python2.7 -y
sudo ln -sv /usr/bin/python2.7 /usr/bin/python2
ceph-deploy new --cluster-network 172.25.0.0/24 --public-network 10.247.8.0/24 ceph-mon1.example.local ceph-mon2.example.local ceph-mon3.example.local

2.6、安装 ceph-mon 服务:
在各 mon 节点按照组件 ceph-mon,并通初始化 mon 节点,mon 节点 HA 还可以后期横向扩容。
Ubuntu 安装 ceph-mon:
apt-cache madison ceph-mon
apt install ceph-mon
ceph 集群添加 ceph-mon 服务(ceph-deploy)
ceph-deploy mon create-initial
2.7、验证 mon 节点:
验证在 mon 定节点已经自动安装并启动了 ceph-mon 服务,并且后期在 ceph-deploy 节点初始化目录会生成一些 bootstrap ceph mds/mgr/osd/rgw 等服务的 keyring 认证文件,这些初始化文件拥有对 ceph 集群的最高权限,所以一定要保存好。
ps -ef | grep ceph-mon
2.8、分发 admin 秘钥:
在 ceph-deploy 节点把配置文件和 admin 密钥拷贝至 Ceph 集群需要执行 ceph 管理命令的节点,从而不需要后期通过 ceph 命令对 ceph 集群进行管理配置的时候每次都需要指定ceph-mon 节点地址和 ceph.client.admin.keyring 文件,另外各 ceph-mon 节点也需要同步ceph 的集群配置文件与认证文件。
ceph-deploy admin ceph-node1 ceph-node2 ceph-node3 ceph-node4
如果在 ceph-deploy 节点管理集群:
sudo apt install ceph-common #先安装 ceph 的公共组件(管理的节点都要装)
ceph-deploy admin ceph-deploy

认证文件的属主和属组为了安全考虑,默认设置为了 root 用户和 root 组,如果需要 ceph用户也能执行 ceph 命令,那么就需要对 ceph 用户进行授权,
setfacl -m u:cephadmin:rw /etc/ceph/ceph.client.admin.keyring
2.9、部署 ceph-mgr 节点:
mgr 节点需要读取 ceph 的配置文件,即/etc/ceph 目录中的配置文件
#初始化 ceph-mgr 节点:(mgr节点上)
apt install ceph-mgr
ceph-deploy mgr create ceph-mgr1
验证 ceph-mgr 节点:
ps -ef | grep ceph
出现如图问题
使用这个命令:ceph config set mon auth_allow_insecure_global_id_reclaim false
2.10、初始化 node 节点:
此步骤必须执行,否 ceph 集群的后续安装步骤会报错。
ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 ceph-node3 ceph-node4
--no-adjust-repos #不修改已有的 apt 仓库源(默认会使用官方仓库)
--nogpgcheck #不进行校验
此 过 程 会 在 指 定 的 ceph node 节 点 按 照 串 行 的 方 式 逐 个 服 务 器 安 装 ceph-baseceph-common 等组件包:
列出 ceph node 节点磁盘:
ceph-deploy disk list ceph-node1 #列出远端存储 node 节点的磁盘信息
使用 ceph-deploy disk zap 擦除各 ceph node 的 ceph 数据磁盘:
ceph-node1 ceph-node2 ceph-node3 ceph-node4的存储节点磁盘擦除过程如下:
ceph-deploy disk zap ceph-node1 /dev/vda
ceph-deploy disk zap ceph-node1 /dev/vdb
ceph-deploy disk zap ceph-node1 /dev/vdd
ceph-deploy disk zap ceph-node1 /dev/vde
ceph-deploy disk zap ceph-node2 /dev/vdb
ceph-deploy disk zap ceph-node2 /dev/vdc
ceph-deploy disk zap ceph-node2 /dev/vdd
ceph-deploy disk zap ceph-node2 /dev/vde
ceph-deploy disk zap ceph-node3 /dev/vda
ceph-deploy disk zap ceph-node3 /dev/vdb
ceph-deploy disk zap ceph-node3 /dev/vdd
ceph-deploy disk zap ceph-node3 /dev/vde
ceph-deploy disk zap ceph-node4 /dev/vda
ceph-deploy disk zap ceph-node4 /dev/vdb
ceph-deploy disk zap ceph-node4 /dev/vdd
ceph-deploy disk zap ceph-node4 /dev/vde

2.11、添加 OSD:
数据分类保存方式:
Data:即 ceph 保存的对象数据
Block: rocks DB 数据即元数据
block-wal:数据库的 wal 日志
ceph-deploy osd create ceph-node1 --data /dev/vdb
ceph-deploy osd create ceph-node1 --data /dev/vdd
ceph-deploy osd create ceph-node1 --data /dev/vde
ceph-deploy osd create ceph-node2 --data /dev/vdb
ceph-deploy osd create ceph-node2 --data /dev/vdc
ceph-deploy osd create ceph-node2 --data /dev/vdd
ceph-deploy osd create ceph-node2 --data /dev/vde
ceph-deploy osd create ceph-node3 --data /dev/vda
ceph-deploy osd create ceph-node3 --data /dev/vdb
ceph-deploy osd create ceph-node3 --data /dev/vdd
ceph-deploy osd create ceph-node3 --data /dev/vde
ceph-deploy osd create ceph-node4 --data /dev/vda
ceph-deploy osd create ceph-node4 --data /dev/vdb
ceph-deploy osd create ceph-node4 --data /dev/vdd
ceph-deploy osd create ceph-node4 --data /dev/vde
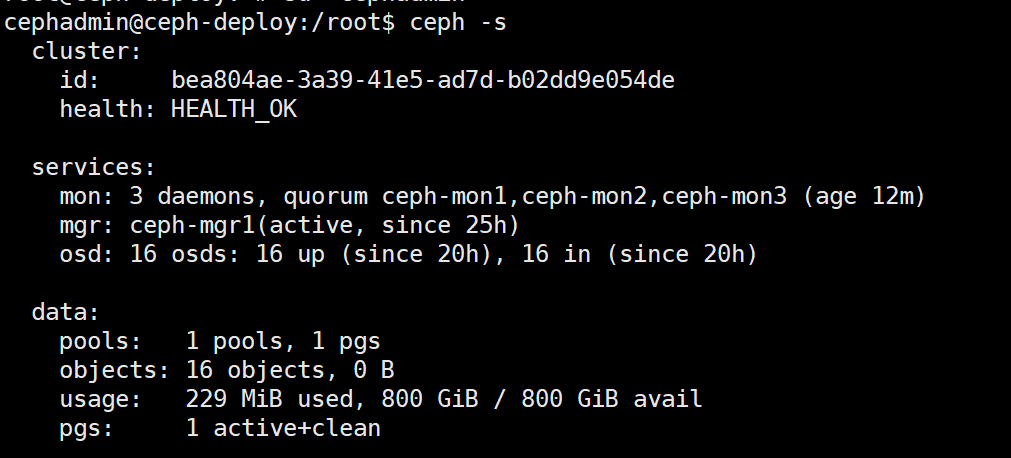
使用ceph -s查看添加OSD之后集群状态
2.12、删除OSD操作
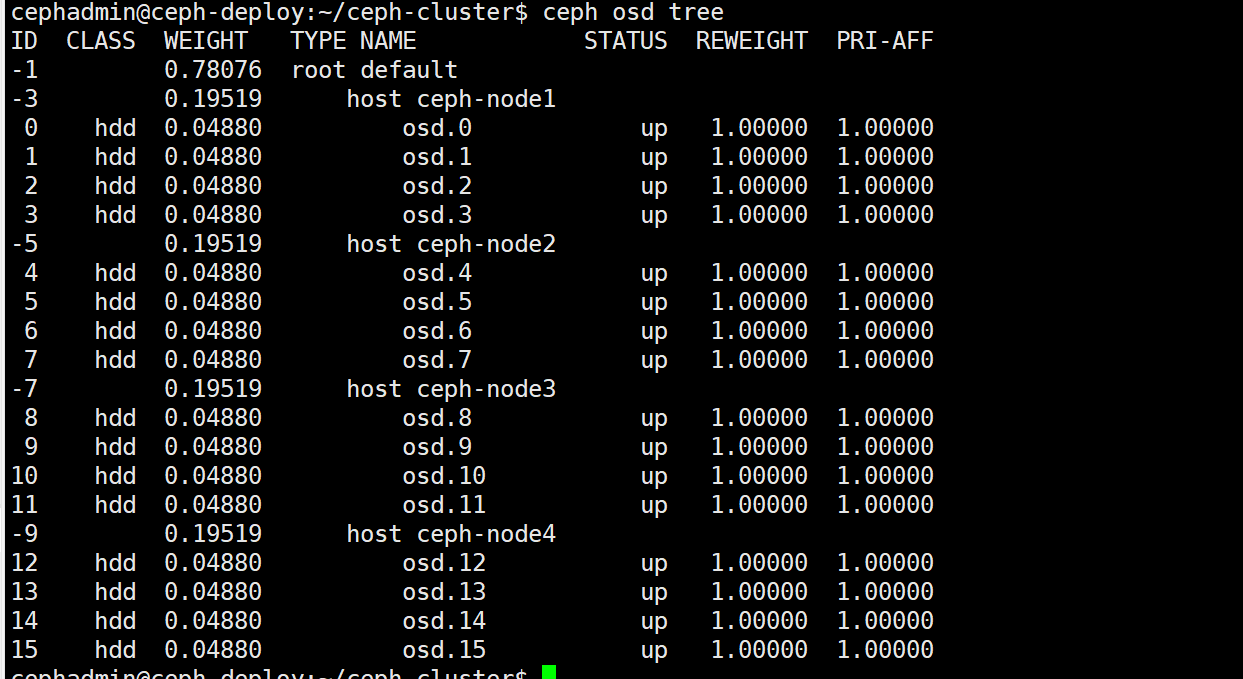
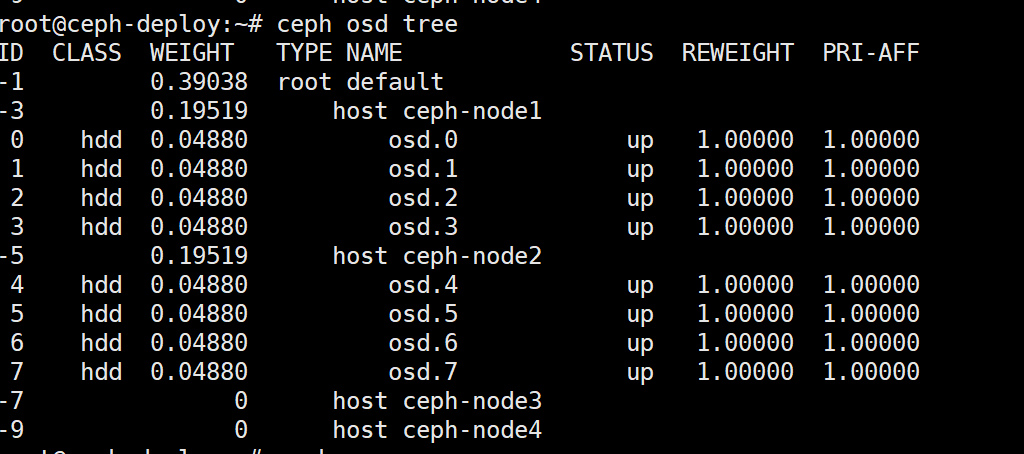
ceph osd tree查看down的osd id
1. 停用设备:ceph osd out {osd-num}
2. 停止进程:sudo systemctl stop ceph-osd@{osd-num} 有可能显示未加载如下图操作步骤
3. 移除设备:ceph osd purge {id} --yes-i-really-mean-it
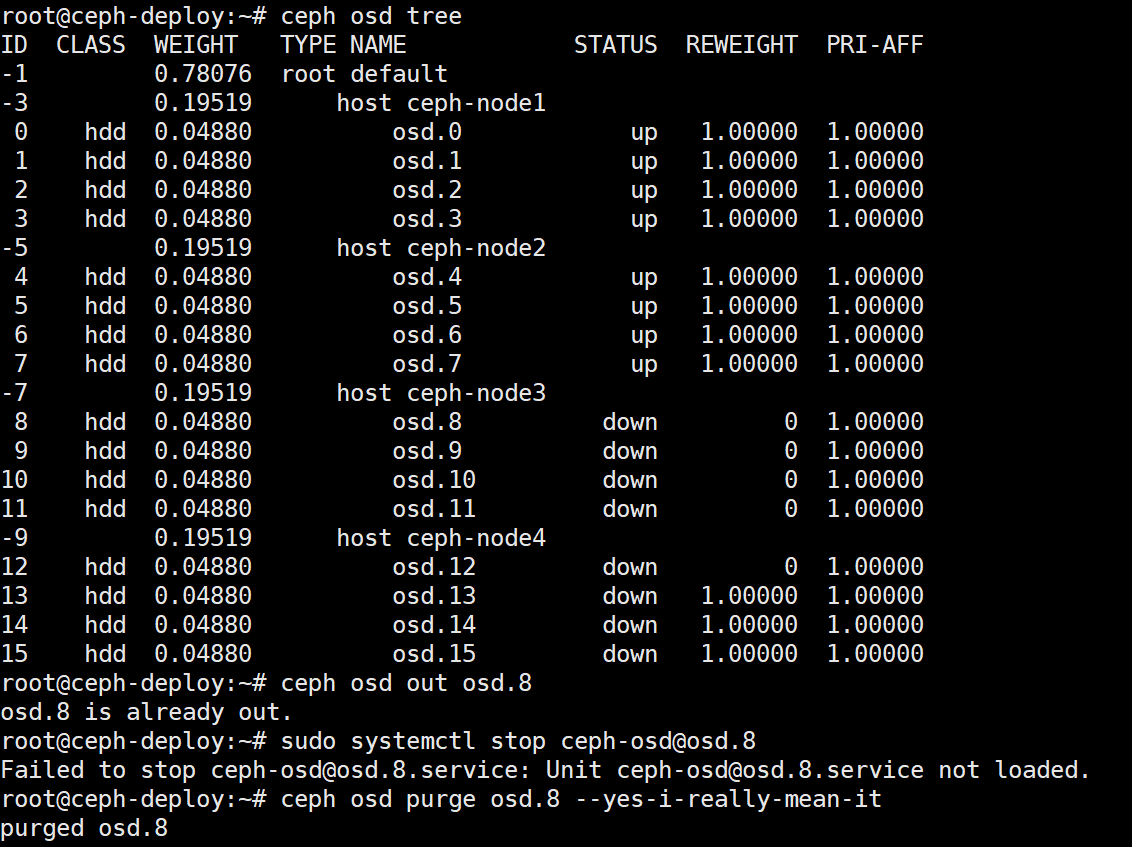
删除后:
3、块存储、文件存储及对象存储的使用场景
块存储:
RBD(RADOS Block Devices)即为块存储设备,RBD 可以为 KVM、vmware 等虚拟化技术和云服务(如 OpenStack、kubernetes)提供高性能和无限可扩展性的存储后端,客户端基于 librbd 库即可将 RADOS 存储集群用作块设备,不过,用于 rbd 的存储池需要事先启用rbd 功能并进行初始化。
块存储不像文件存储,依赖路径,它只负责数据的读取和写入,可以实现快速检索,因此效率很高。适用于对响应时间要求高的系统,例如
数据库。
ceph radosgw(RGW)对象存储网关:
RGW 提供的是 REST 风格的 API 接口,客户端通过 http 与其进行交互,完成数据的增删改查等管理操作。
radosgw 用在需要使用 RESTful API 接口访问 ceph 数据的场合,因此在使用 RBD 即块存储得场合或者使用 cephFS 的场合可以不用启用 radosgw 功能。
目前国内有大量的云服务提供商,他们把对象存储当作云存储在卖。他们通常会把存储业务分为3个等级,即标准型、低频型、归档型。对应的应用场景如下:
标准类型:移动应用 | 大型网站 | 图片分享 | 热点音视频
低频访问类型:移动设备 | 应用与企业数据备份 | 监控数据 | 网盘应用
归档类型:各种长期保存的档案数据 | 医疗影像 | 影视素材
部署 radosgw 服务:
apt-cache madison radosgw
apt install radosgw=16.2.10-1focal
ceph-deploy --overwrite-conf rgw create ceph-mgr1
验证 radosgw 服务:
验证 ceph 状态
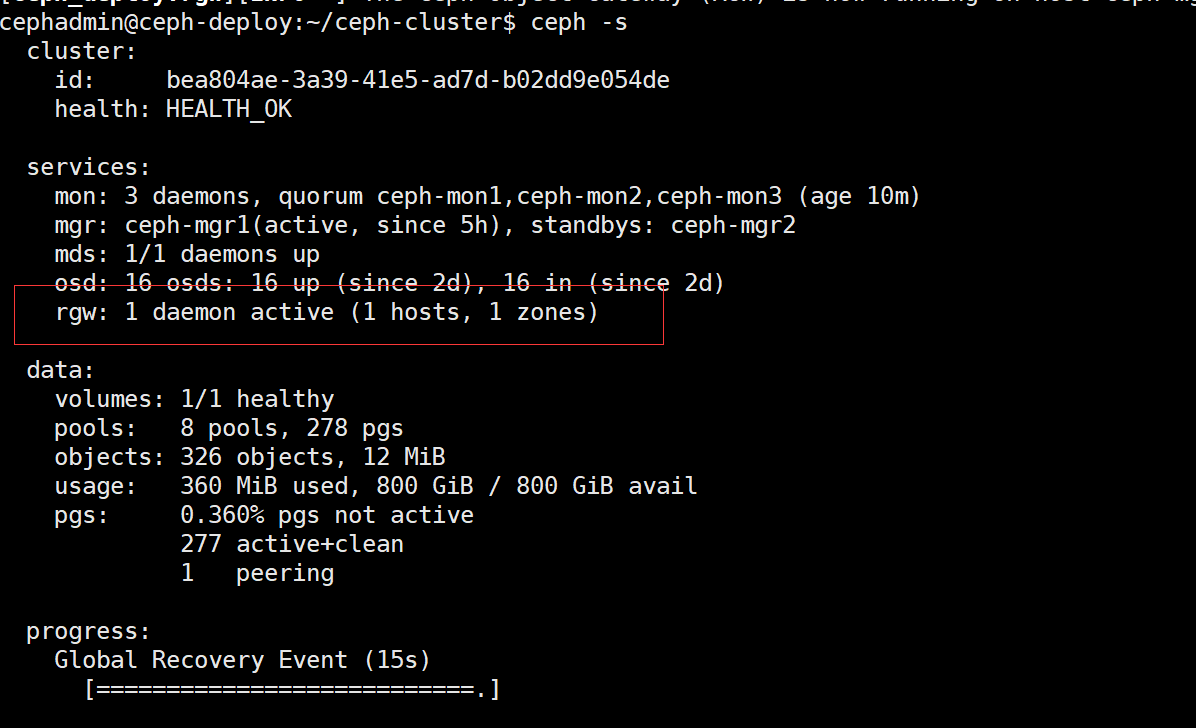
验证 radosgw 存储池
初始化完成 radosgw 之后,会初始化默认的存储池如下:
Ceph-FS 文件存储
https://docs.ceph.com/en/latest/cephfs/
Ceph FS 即 ceph filesystem,可以实现文件系统共享功能,客户端通过 ceph 协议挂载并使用 ceph 集群作为数据存储服务器。Ceph FS 需要运行 Meta Data Services(MDS)服务,其守护进程为 ceph-mds,ceph-mds进程管理与 cephFS 上存储的文件相关的元数据,并协调对 ceph 存储集群的访问。
文件存储是基于文件级别的存储,它是把一个文件放在一个硬盘上,即使文件太大拆分时,也放在同一个硬盘上。适用场景:文件较大,总读取带宽要求较高;多个文件同时写入;长时间存放的文件。
4、基于 ceph 块存储实现块设备挂载及使用
4.1、创建 RBD
ceph osd pool create myrbd1 64 64 #创建存储池,指定 pg 和 pgp 的数量,pgp 是对存在于 pg 的数据进行组合存储,pgp 通常等于 pg 的值
ceph osd pool application enable myrbd1 rbd #对存储池启用 RBD 功能
rbd pool init -p myrbd1 #通过 RBD 命令对存储池初始化

4. 2、创建并验证 img
不过,rbd 存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用,rbd 命令可用于创建、查看及删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作,例如,下面的命令能够创建一个名为 myimg1 的映像:
rbd create myimg1 --size 5G --pool myrbd1
rbd create myimg2 --size 3G --pool myrbd1 --image-format 2 --image-feature layering
#后续步骤会使用 myimg2 镜像 ,但是由于 centos 系统内核较低不支持更多 image-feature特性、因此无法挂载使用,所以只开启部分特性。除了 layering 其他特性需要高版本内核支持
rbd ls --pool myrbd1 #列出指定的 pool 中所有的 img
rbd --image myimg1 --pool myrbd1 info #查看指定 rdb 的信息
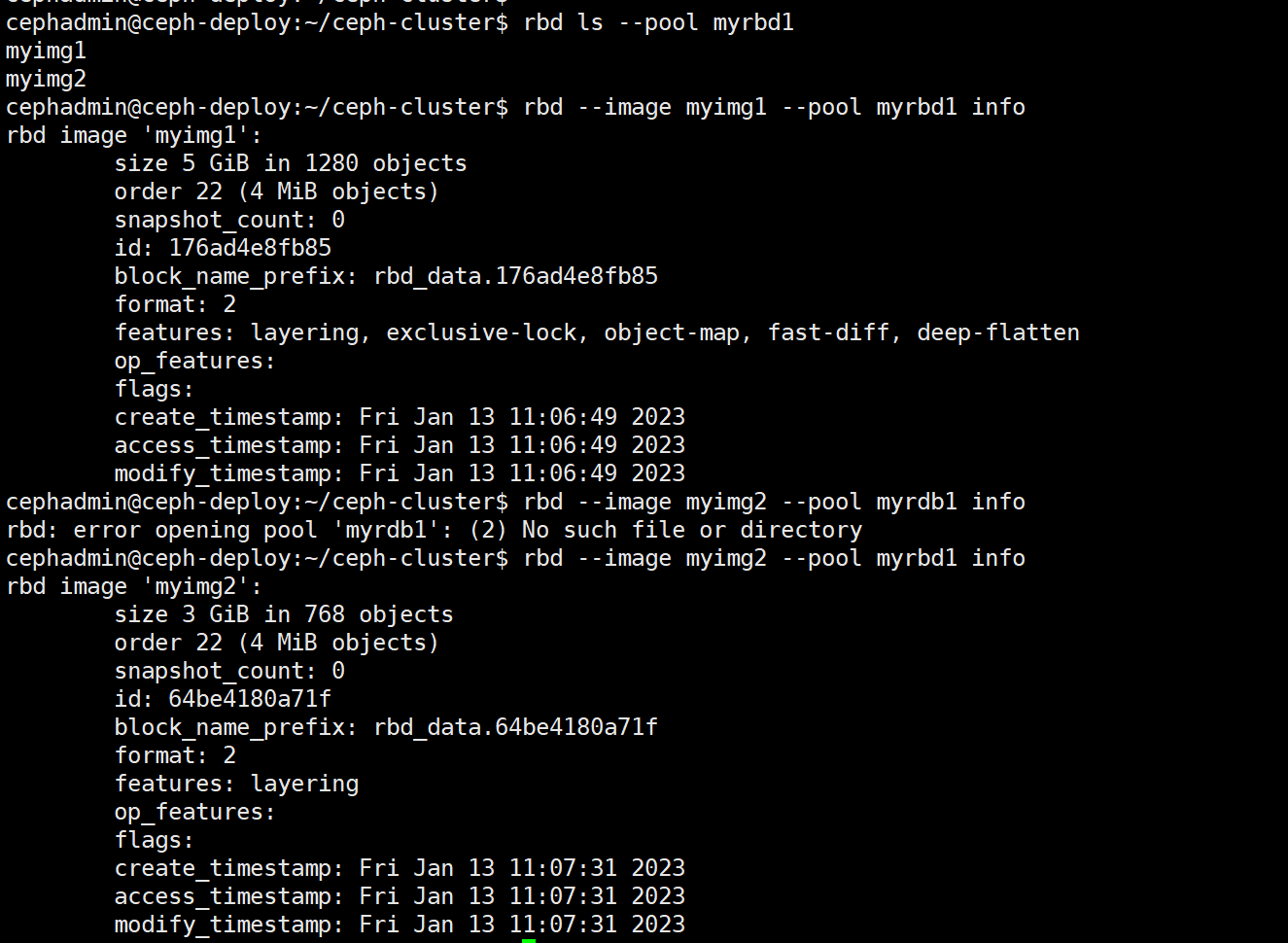
4.3、客户端使用块存储
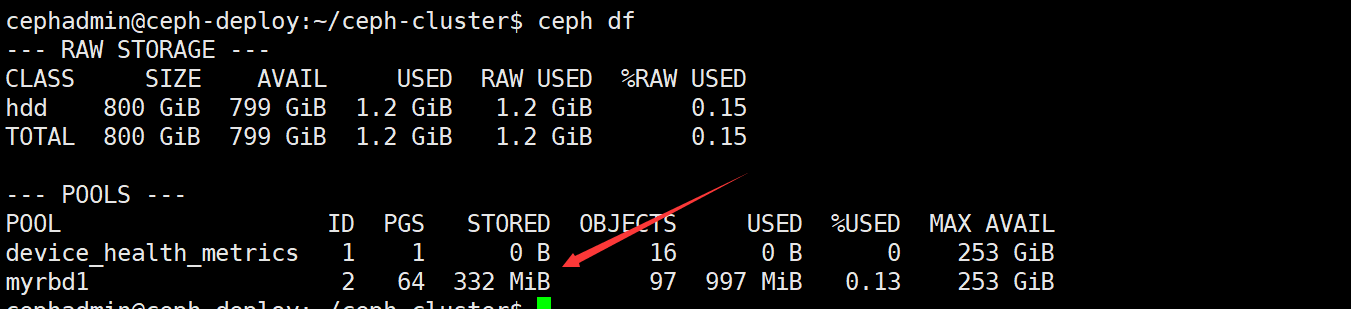
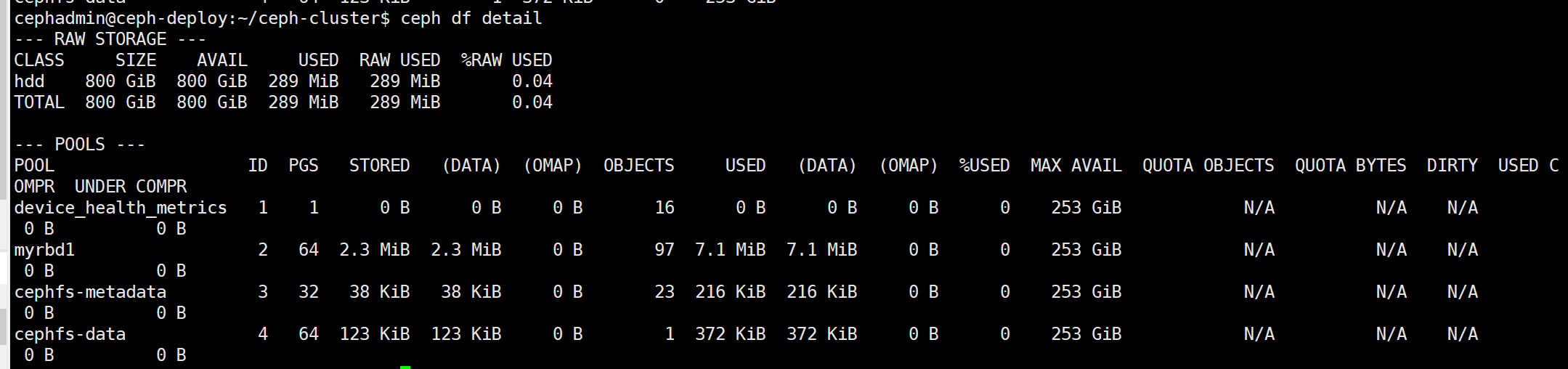
查看当前 ceph 状态 ceph df

centos 系统客户端配置 yum 源及 ceph 认证文件
配置 yum 源:
# yum install epel-release
# yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm -y
# yum install ceph-common
从部署服务器同步认证文件:
scp ceph.conf ceph.client.admin.keyring root@10.247.8.190:/etc/ceph/
客户端映射 img
rbd -p myrbd1 map myimg2
rbd -p myrbd1 map myimg1
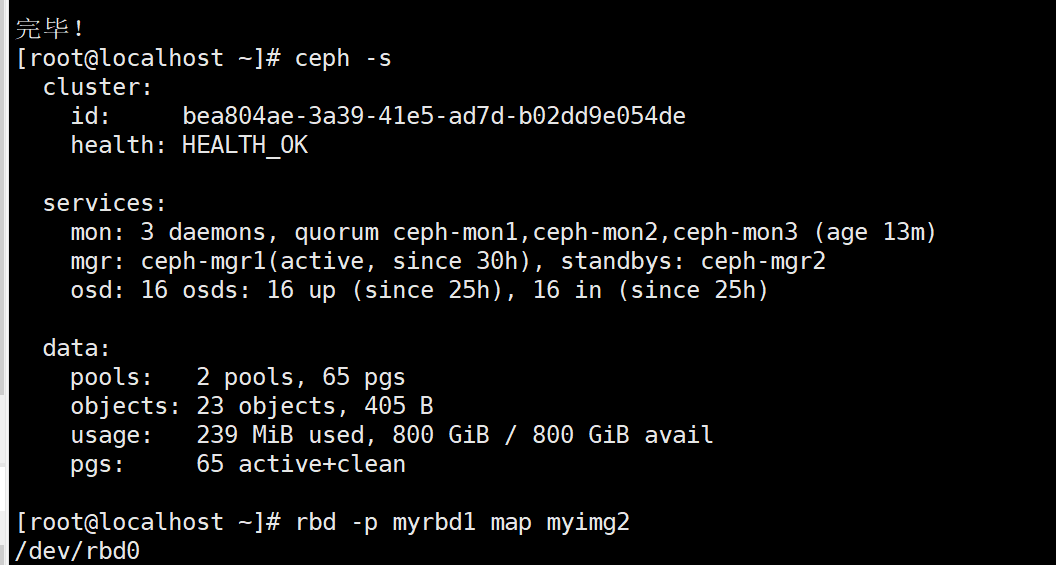
客户端格式化磁盘并挂载使用
客户端验证
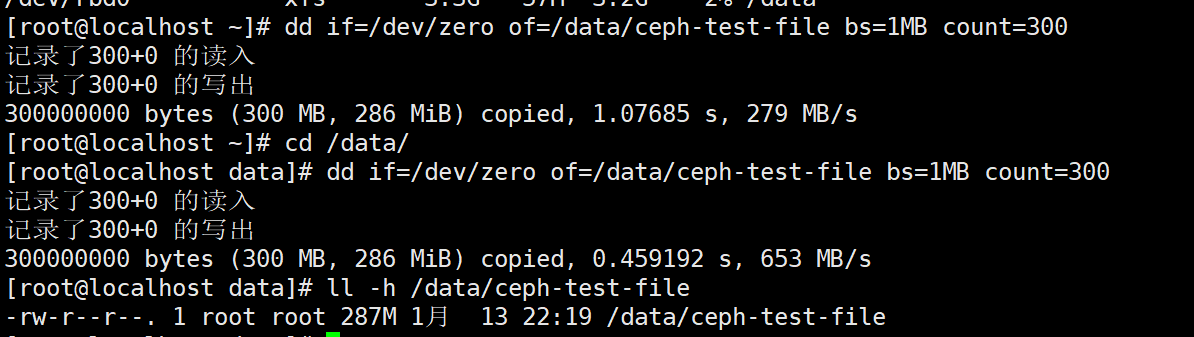
dd if=/dev/zero of=/data/ceph-test-file bs=1MB count=300
ll -h /data/ceph-test-file
rm -rf /data/ceph-test-file
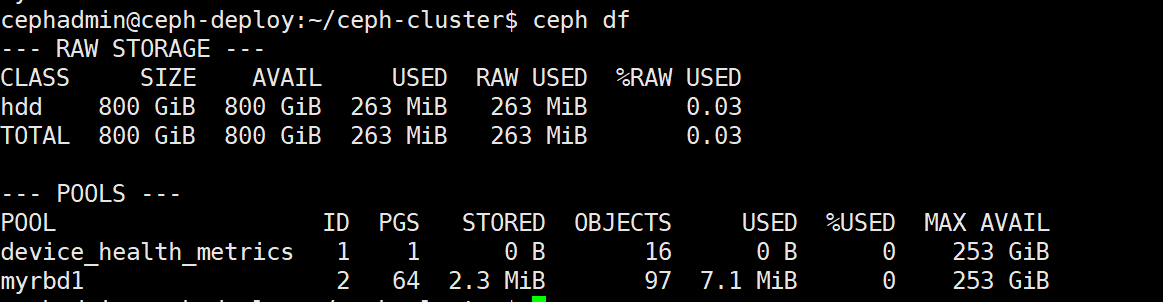
删除完成的数据只是标记为已经被删除,但是不会从块存储立即清空,因此在删除完成后使用 ceph df 查看并没有回收空间:
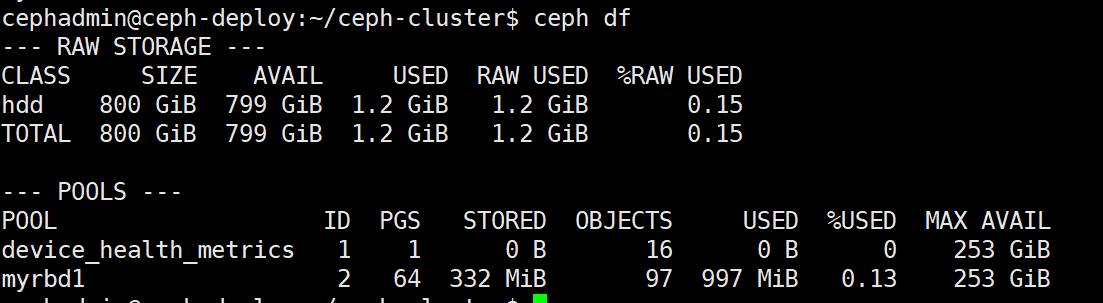
但是后期可以使用此空间,如果需要立即在系统层回收空间,需要执行以下命令:
fstrim -v /data #/data 为挂载点,fstrim 命令来自于英文词组“filesystem trim”的缩写,其功能是回收文件系统中未使用的块资源。

或配置挂载选项:
mount -t xfs -o discard /dev/rbd0 /data/ #主要用于 SSD,立即触发闲置的块回收
5、基于cephFS实现多主机数据共享
https://docs.ceph.com/en/latest/cephfs/
Ceph FS 即 ceph filesystem,可以实现文件系统共享功能,客户端通过 ceph 协议挂载并使用 ceph 集群作为数据存储服务器。Ceph FS 需要运行 Meta Data Services(MDS)服务,其守护进程为 ceph-mds,ceph-mds进程管理与 cephFS 上存储的文件相关的元数据,并协调对 ceph 存储集群的访问。
如下图:
数据的元数据保存在单独的一个存储池 cephfs-metadata(名字可自定义),因此元数据也是基于 3 副本提高可用性,另外使用专用的 MDS 服务器在内存缓存元数据信息以提高对客户端的读写响应性能。
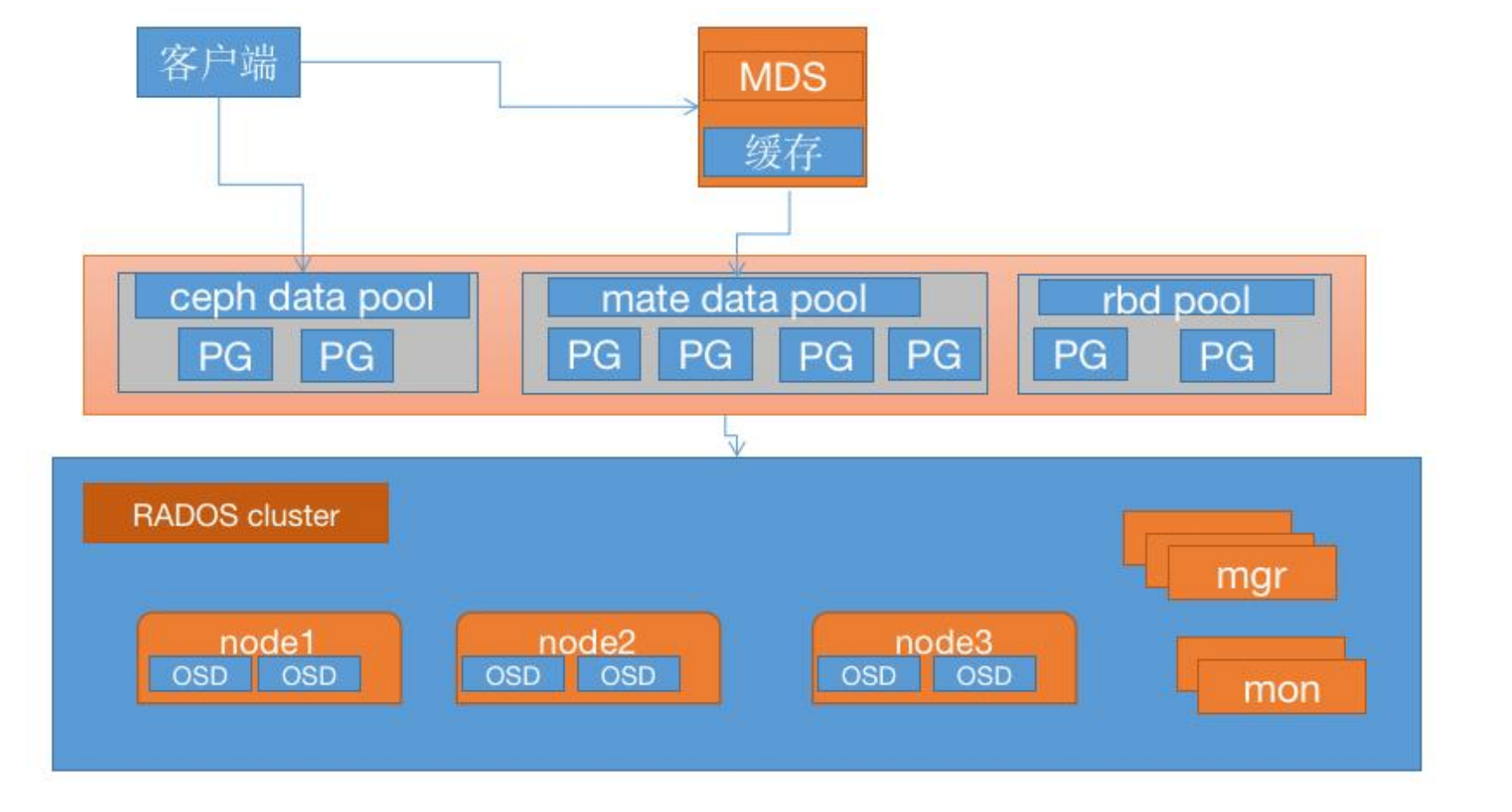
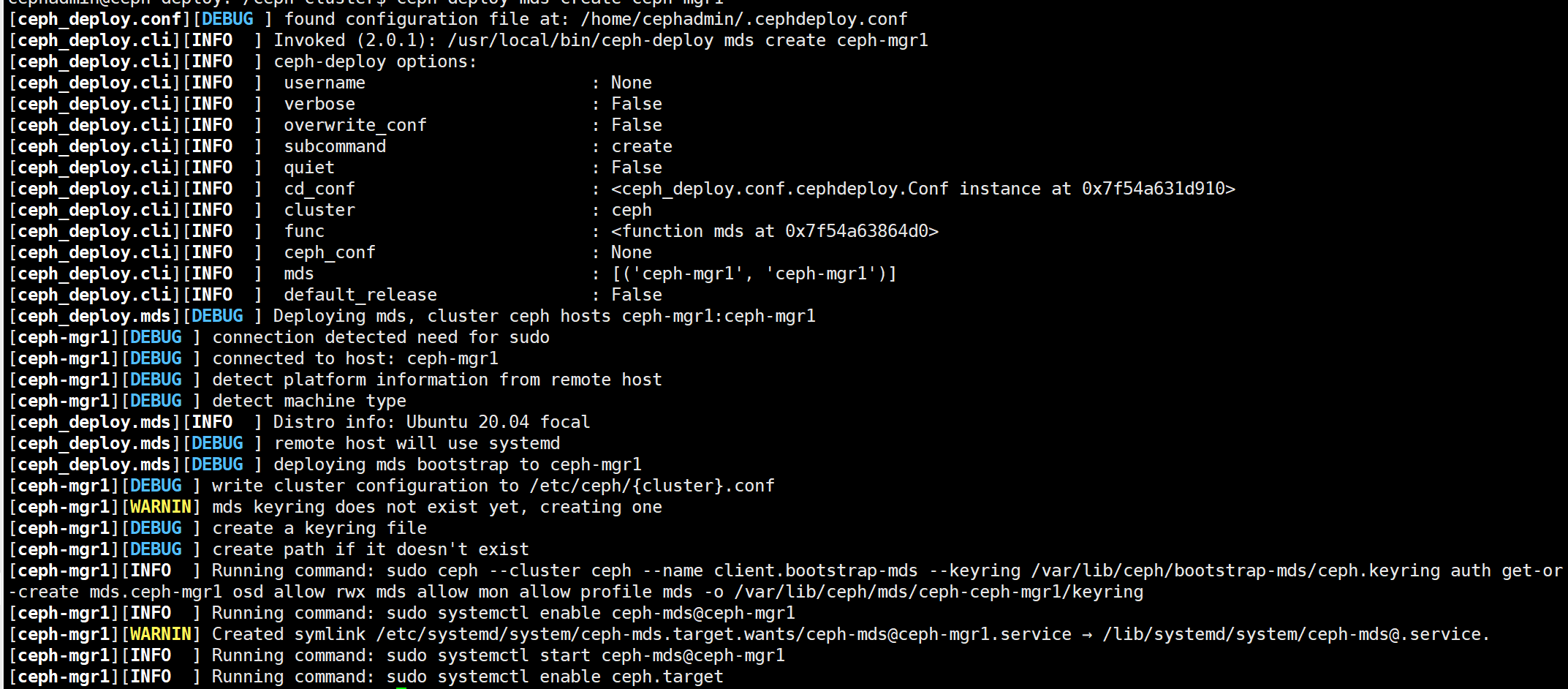
5.1、部署 MDS 服务:
在指定的 ceph-mds 服务器部署 ceph-mds 服务,可以和其它服务器混用(如 ceph-mon、ceph-mgr)
Ubuntu:
root@ceph-mgr1:~# apt-cache madison ceph-mds
root@ceph-mgr1:~# apt install ceph-mds=16.2.10-1focal

Centos:
[root@ceph-mgr1 ~]# yum install ceph-mds -y
部署:
[cephadmin@ceph-deploy ceph-cluster]$ ceph-deploy mds create ceph-mgr1
MDS 服务目前还无法正常使用,需要为 MDS 创建存储池用于保存 MDS 的数据。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph mds stat
1 up:standby
5.3、创建 CephFS metadata 和 data 存储池
使用 CephFS 之前需要事先于集群中创建一个文件系统,并为其分别指定元数据和数据相关的存储池,如下命令将创建名为 mycephfs 的文件系统,它使用 cephfs-metadata 作为元数据存储池,使用 cephfs-data 为数据存储池:
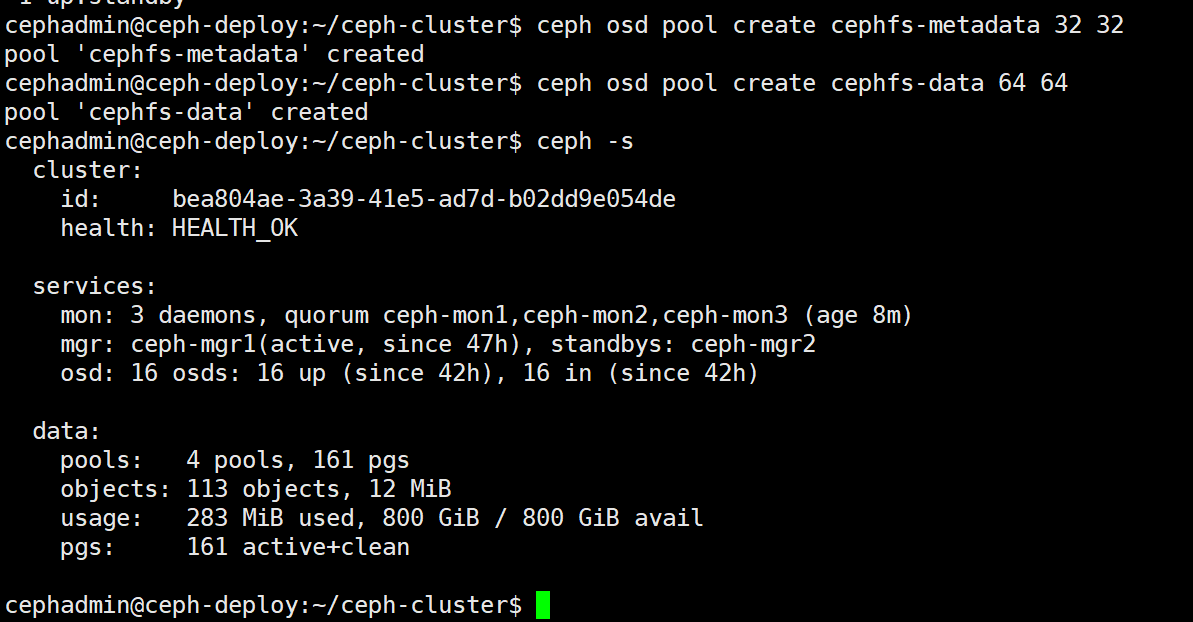
ceph osd pool create cephfs-metadata 32 32 #pool 'cephfs-metadata' created #保存 metadata 的 pool
ceph osd pool create cephfs-data 64 64 #pool 'cephfs-data' created #保存数据的 pool
ceph -s #当前 ceph 状态
5.4、创建 cephFS 并验证
ceph fs new mycephfs cephfs-metadata cephfs-data
ceph fs ls
ceph fs status mycephfs #查看指定 cephFS 状态
5.5、验证 cepfFS 服务状态:
# mycephfs:1 {0=ceph-mgr1=up:active} #cephfs 状态现在已经转变为活动状态
5.6、客户端挂载 cephFS:
在 ceph 的客户端测试 cephfs 的挂载,需要指定 mon 节点的 6789 端口:
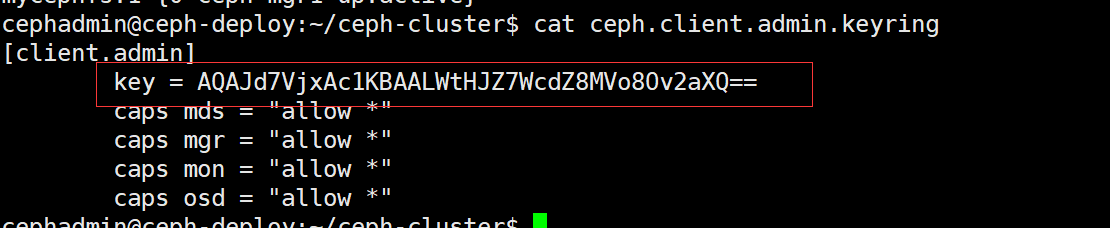
mount -t ceph 10.247.8.202:6789:/ /data -o name=admin,secret=AQAJd7VjxAc1KBAALWtHJZ7WcdZ8MVo8Ov2aXQ==
验证挂载点

cp /var/log/syslog /mnt/ #验证数据

测试数据写入:
dd if=/dev/zero of=/mnt/ceph-fs-file bs=4M count=25

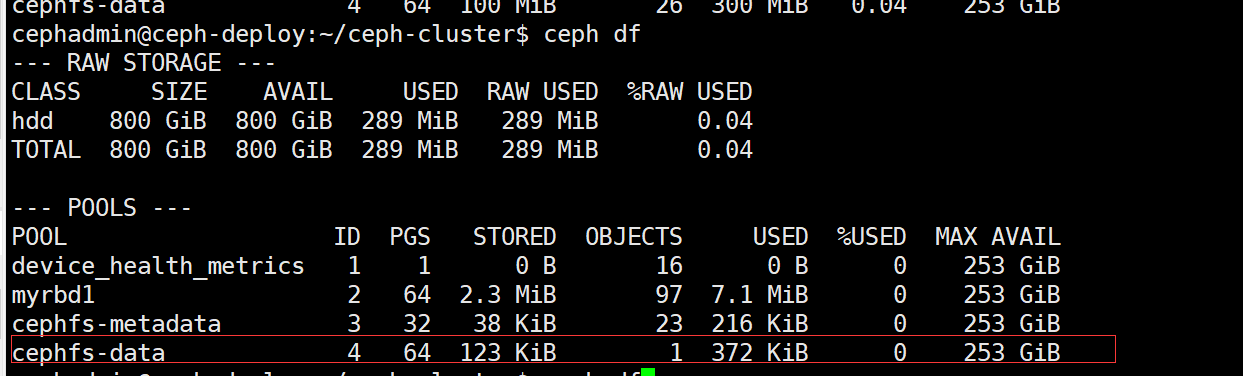
验证 ceph 存储池数据空间:

不同服务器修改共享数据,都会自动更新


删除数据
rm -rf /data/ceph-fs-file
6、命令总结:
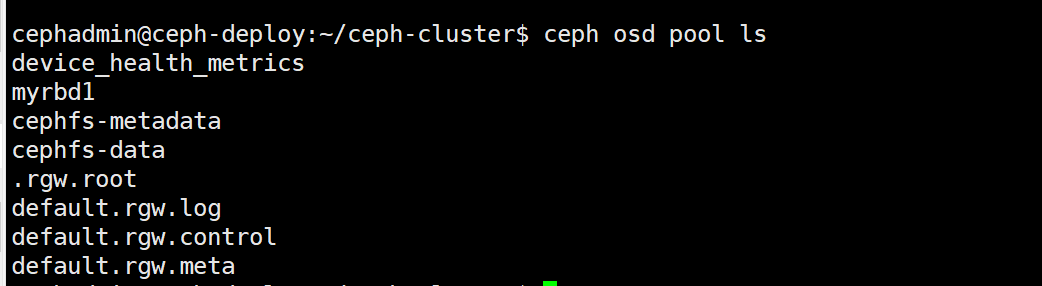
只显示存储池:
ceph osd pool ls
列出存储池并显示 id
ceph osd lspools

查看 pg 状态

查看指定 pool 或所有的 pool 的状态
ceph osd pool stats mypool

查看集群存储状态

查看集群存储状态详情
ceph df detail
查看 osd 状态
ceph osd stat
"16 osds: 16 up (since 2d), 16 in (since 2d); epoch: e357"

显示 OSD 和节点的对应关系
ceph osd tree
查看 mon 节点状态:
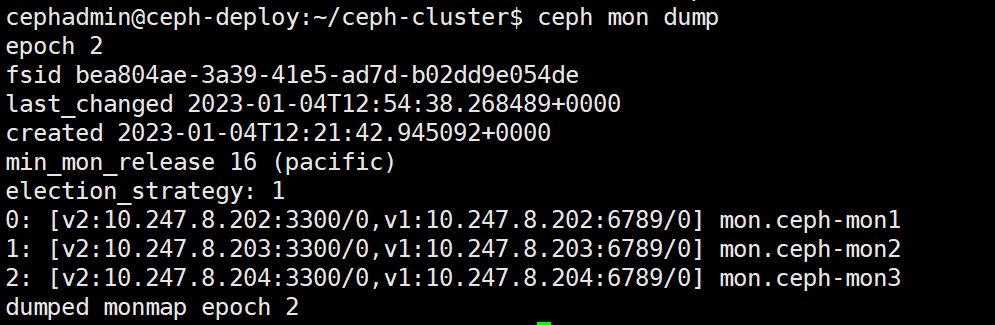
ceph mon stat

查看 mon 节点的 dump 信息