本文系原创,转载请说明出处
Please Subscribe Wechat Official Account:信安科研人,获取更多的原创安全资讯
参考发表在2020年软工顶会ISSTA的论文《An Empirical Study on ARM Disassembly Tools》
作者公开研究在:https://github.com/valour01/arm_disasssembler_study
一 研究简述
问:本文想做什么,得出了什么结论?
找出ARM反汇编工具的假设和现实之间的差异,即ARM反汇编工具反汇编代码的效果到底怎么样?什么因素影响着反汇编的效果?
问:为什么要做这个工作?
研究背景
1、嵌入式设备逐渐增多,大部分嵌入式设备使用的是ARM架构,安全评估的需求逐渐增多
2、安全评估中的动态分析方法需要运行firmware,嵌入式设备的外设(如I/O)多样性对运行firmware(基于仿真的测试方法)是个巨大的阻碍——静态分析仍然有效,即使用静态分析方法评估firmware的安全性
现有工作的局限性or现有需要改进的地方
现有静态分析方法大多使用现成的工具来反汇编stripped的ARM二进制程序,这些方法都基于一个前提:假定这些现有的工具很可靠,已经解决了反汇编技术中存在的问题。
然而,这种假设真的可靠吗?
"Stripped"的二进制文件是指已经剥离了符号表和调试信息的可执行文件或共享库。在编译源代码并生成可执行文件或共享库时,编译器通常会将一些额外的信息存储在二进制文件中,包括符号表、调试信息、编译器指令等。
符号表包含了源代码中定义的变量名、函数名以及其他符号的信息,用于在调试和符号解析过程中进行源代码到二进制文件之间的映射。调试信息包括源代码的行号、变量存储位置以及其他与调试相关的信息,以帮助开发者进行程序调试和错误排查。
然而,一旦程序开发和调试阶段已经完成,为了减小二进制文件的大小并保护源代码的隐私,可以使用剥离过程将这些符号表和调试信息等额外信息从二进制文件中移除。剥离之后的文件被称为"stripped"的二进制文件。
Stripped的二进制文件相比非stripped的二进制文件具有较小的文件大小,因为移除了不相关的信息。但是,它们相对于调试和符号解析来说缺乏可读性和可理解性,因为符号和调试信息已经丢失。
问:ARM反汇编的挑战点?
1、内联数据
在汇编语言中,内联数据指的是将数据直接嵌入到汇编指令中,而不是从外部源加载数据。这样可以方便地在汇编代码中使用常量、配置值或其他静态数据。
2、ARM提供两种指令集
3、没有明确的函数调用指令。
在ARM架构下,函数调用是通过一系列指令来实现的。常见的方式是使用跳转指令(例如BL指令)来跳转到函数的入口地址,并将返回地址保存在堆栈中。函数执行完毕后,通过返回指令(例如BX指令)来回到调用点,并从堆栈中恢复返回地址。
研究内容
按照不同的编译器、编译器选项、二进制混淆方法,构造了近2000个ARM二进制,在8个现有反汇编工具上评估,评估这些工具的定位or识别指令边界和函数边界的能力,以判断反汇编的效果。
评估标准:
评估这些工具的定位或识别指令边界和函数边界的能力
研究结论
"We find that the existence of both ARM and Thumb instruction sets, and the reuse of the BL instruction for both function calls and branches bring serious challenges to disassembly tools"
也就是:ARM和Thumb指令集的共存以及BL指令在函数调用和分支中的重用给反汇编工具的反汇编准确率带来了挑战。
二 背景知识
2.1 ARM架构CPU和指令集
指令集架构,又称指令集或指令集体系,是计算机体系结构中与程序设计有关的部分,包含了基本数据类型,指令集,寄存器,寻址模式,存储体系,中断,异常处理以及外部I/O。指令集架构包含一系列的opcode即操作码,以及由特定处理器执行的基本命令。
ARM架构,过去称作高级精简指令集机器(英语:Advanced RISC Machine,更早称作艾康精简指令集机器,Acorn RISC Machine),是一个
ARM架构和处理器关系如下表(来自

ARM指令集

![]()
ARM和Thumb是ARM架构下的两种指令集。
ARM指令集是基于32位的指令编码,具有较高的性能和灵活性,适合用于需要高性能和复杂功能的应用。
Thumb指令集是ARM架构下的一种16位的指令编码,相比于32位的ARM指令集,Thumb指令集具有更低的代码密度和较低的功耗消耗,适用于资源有限的嵌入式系统和移动设备。
Thumb指令集包括两种模式:
1. Thumb-1:最初引入的Thumb指令集,只能执行16位的Thumb指令。
2. Thumb-2:引入了更多的32位指令,同时兼容32位的ARM指令集,可以在Thumb和ARM模式之间切换。
在运行时,ARM处理器可以选择性地在ARM模式和Thumb模式之间切换,根据需要执行不同大小的指令。这样可以在需要高性能时切换到ARM模式,而在需要低功耗和较小的代码大小时切换到Thumb模式。(对应了研究结论中的指令集共存)
Thumb和ARM之间的切换方法:
BLX label指令将ARM切换到Thumb指令集,或者从Thumb切换到ARM指令集。
BX Rm指令通过寄存器Rm的第0位确定目标指令集。如果为0,则目标指令集是ARM;否则是Thumb。
其他分支指令(如POP {PC, Rm ...})的目标指令集也取决于目标地址的最后一位。这给静态确定目标指令集的反汇编工具带来了严重挑战,特别是对于采用线性扫描策略的反汇编工具。
这对反汇编工具来说带来了严重的阻碍,尤其是对于那些利用线性扫描策略(第2.2节)的工具来说,静态确定目标指令集的问题变得更为复杂。
需要注意的是,Thumb指令集的指令宽度较小,可能会导致性能相对较低,一些复杂的操作可能需要多条指令来完成。因此,在选择使用ARM模式还是Thumb模式时,需要权衡性能和代码密度之间的因素,根据具体的应用场景做出选择。
2.2 间接跳转和直接跳转、函数调用
2.2.1 x86汇编间接和直接跳转
section .text
; 直接跳转
jmp target_label ; 直接跳转到目标标签
; 其他指令...
target_label:
; 在这里执行目标标签的代码
; ...
; 间接跳转
mov eax, jmp_ptr ; 将跳转地址装入寄存器 eax
jmp eax ; 间接跳转到 eax 寄存器中的地址
; 其他指令...
jmp_ptr:
dd target_address ; 间接跳转的目标地址
target_address:
; 在这里执行目标地址的代码
; ...在这个例子中,首先展示了直接跳转的情况。使用 jmp 指令直接跳转到标签 target_label 处。当执行到该指令时,程序将无条件地跳转到 target_label 的地址,继续执行后续的指令。
接下来是间接跳转的情况。首先,将目标地址存储在一个内存位置 target_address 中,然后通过装载这个地址到寄存器 eax 中(使用 mov 指令),再通过 jmp eax 指令实现间接跳转。当执行到这个间接跳转指令时,程序将根据 eax 寄存器中存储的地址,动态决定跳转到哪个标签处继续执行。
这个例子展示了直接跳转和间接跳转的汇编代码。直接跳转使用的是一个静态确定的目标地址,而间接跳转使用的是一个动态计算得到的跳转地址。
2.2.2 ARM架构的间接和直接跳转
请注意,这里给的是x86的跳转例子,而对于ARM架构的跳转:
-
直接跳转(Direct Jump):
直接跳转使用
B指令,可用于无条件跳转到一个特定的标签或地址。B target_label ; 无条件跳转到目标标签或地址 ; 其他指令... target_label: ; 在这里执行目标标签的代码 ; ...
-
间接跳转(Indirect Jump):
间接跳转使用
BX或BLX指令,通过寄存器中的内容来间接确定跳转的目标地址。MOV R0, target_address ; 将目标地址存储到寄存器 R0 中 BX R0 ; 通过 R0 寄存器中的地址进行间接跳转 ; 其他指令... target_address: ; 在这里执行目标地址的代码 ; ...
2.2.3 x86函数调用
什么是函数调用?函数调用允许程序在需要时跳转到特定的代码段(函数),执行函数中定义的一系列操作,并在函数执行完毕后返回到调用点,继续执行后续的指令。
当涉及到x86汇编的函数调用时,主要使用CALL和RET指令。下面是一个x86汇编语言的例子:
section .data
; 数据段
section .text
; 代码段
global _start
_start:
; 主程序开始
call my_function
; 继续执行后续指令
; ...
my_function:
; 函数体中的代码
; ...
; 返回到调用点
ret
在上述示例中,
1 call 指令用于调用函数 my_function,它会将当前指令的下一条指令的地址(即返回地址)压入栈中,并跳转到 my_function 的起始地址开始执行。
在函数执行完毕后,通过 ret 指令从栈中取出保存的返回地址,并将控制权返回到调用点继续执行后续指令。
2.2.4 ARM架构的函数调用
下面是一个汇编代码的示例,展示了如何进行函数调用:
; 函数声明
.global my_function
; 主程序
main:
; 调用函数
BL my_function
; 继续执行后续指令
; ...
; 函数定义
my_function:
; 函数体中的代码
; ...
; 返回到调用点
BX LR
在上述示例中,程序首先声明了一个名为 my_function 的函数。然后,在主程序的代码中,使用 BL 指令调用了这个函数。
1 函数调用过程中,当前指令的地址被保存到链接寄存器(LR)中,然后执行相应的函数体代码。
2 在函数执行完毕后,通过 BX LR 指令从链接寄存器(LR)中取出保存的返回地址,返回到调用点继续执行后续指令。
需要注意的是,BL指令在ARM架构中既可以用于函数调用(子程序调用),也可以用于分支跳转。
当BL指令用于函数调用时,它将当前指令的地址(或加上偏移量)保存在链接寄存器(LR)中,然后跳转到目标函数执行。在函数执行完成后,通过从链接寄存器(LR)中获取保存的返回地址,实现返回到调用点。
当BL指令用于分支跳转时,它直接跳转到目标标签或地址处执行,不涉及返回地址的保存。这在某些情况下可以用于实现条件分支、循环跳转等功能。
2.3 反汇编技术
现阶段的反汇编技术一般分为两种,一种是线性扫描(linear sweep),另一种是递归遍历。
详细的技术原理我找到了俩讲解详细明了的博客:
线性扫描:如其名,线性扫描线性的扫描每一段代码,因此线性扫描的优点是反汇编覆盖率是100%,缺点是无法识别数据和代码之间的边界,导致将数据识别成代码。代表工具objdump。
递归遍历:从一个二进制文件的的入口点开始反汇编,当遇到一个新分支后,将新分支定为新的入口点,继续反汇编,如此循环,直到没有新的分支出现。优点是能够识别数据区域,且当程序中存在直接跳转分支且分支目标可以在编译或加载时静态确定时,处理器可以根据这个目标来切换不同的指令集。缺点就是基本无法达到100%覆盖率。代表工具IDA。
对于这两种技术的优缺点,作者给出了一个例子:
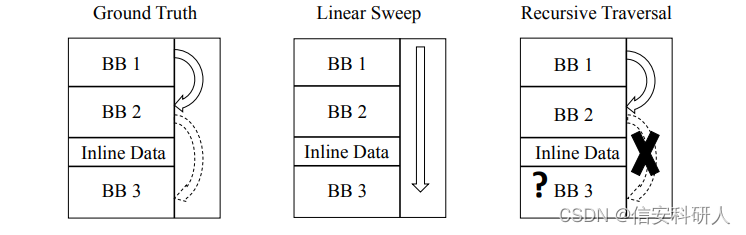
![]()
基本要素:BB代表基本块,BB2和BB3之间有inline Data,代表内联数据。BB1到BB2是直接跳转,BB2到BB3是间接跳转。
线性扫描持续扫描所有的数据。递归扫描面临一个棘手的问题,上面说到直接跳转倒是容易识别,但是间接跳转就不一定了。
尽管已经有一些方法被提出来用于检测跳转表(一种间接分支方法)的目标,但如何可靠地检测其他类型的间接分支(例如函数指针)仍然是一个尚未解决的研究问题。
作者发现成功解析间接跳转目标可以提高反汇编的准确率。
2.4 函数识别
反汇编工具如何识别出函数?
通常利用函数的签名来检测函数。例如通过扫描二进制文件中已知的函数开始和结尾来进行函数识别。
然而,这种方法的局限性在于函数签名(如开始和结尾)可能会缺失。此外,维护一个常新的签名数据库是一项繁琐的任务。
有研究者提出一种的新的方法来识别函数边界,通过识别可区分的函数调用指令,如X86的Call指令来复原函数边界。然而,正如2.2节所述,ARM架构下的Thumb指令集一般使用BL指令跳转和函数调用,这种具备多用途的指令让这种方法的准确率大大下降。
三 评估结果
评估对象
非商业工具:angr , BAP , Objdump , Ghidra , Radare2
商业工具:Binary Ninja , Hopper, IDA Pro
评估尝试回答以下几个问题
• RQ1:反汇编工具对整个数据集的准确性如何?
• RQ2:影响反汇编工具结果的因素是什么,原因是什么?
• RQ3:不同类型和选项的工具是否会产生不同的结果?
• RQ4:这些反汇编工具的效率如何?
3.1 哪个工具效果好?

![]()
还得是你IDA
3.2 影响精确率的因素
3.2.1 指令集
影响很大
(1)有些工具无法在ARM和thumb指令集之间转换;
(2)有些工具对thumb指令不支持更支持ARM指令;
(3)指令边界和函数边界的相关性很大,很多工具对指令边界都识别的不精确,会极大影响函数边界识别。
核心原因:
这是因为Thumb指令集的二进制文件中,BL标签指令既用作函数调用,又用作直接跳转分支。
具体来说,BL标签(BLX标签)指令用于直接调用函数。对于ARM指令集,编译器使用
B tag
等指令来进行直接跳转分支。
然而,对于Thumb指令集,B标签的范围受限(16位Thumb为±2KB)[4]。编译器倾向于将BL标签用作直接跳转分支(16位Thumb的范围为±4MB),这与函数调用相同。
这让反汇编工具混淆了,错误地将直接跳转分支解释为函数调用。这会导致在识别函数边界时产生很高的错误正例,从而导致低精度。
3.2.2 CPU架构
有影响,比如在ARMv7 CPU架构中,编译器在直接分支时使用B标签指令,而不是重新使用BL标签指令。这有助于反汇编工具区分直接分支指令和函数调用指令,从而提高了识别函数边界的精确度值。
3.2.3 文件混淆
混淆给反汇编工具在定位函数边界方面引入了挑战,特别是在控制流扁平化方面。根本原因是由于混淆工具插入的直接分支所重用的BL标签指令。
四 怎样改进?
(1)针对ARM指令集制定特定的反汇编策略
如逐渐流行的thumb指令集,目前并没有很多工具支持识别,这就需要进行完善;
使用混合反汇编技术(《Control Flow Integrity for COTS Binaries》. In Proceedings of the 22nd USENIX Security Symposium)定位、识别内联数据,比如radare2,该工具如果识别出一个无效指令,那么就会尝试切换指令模式,或者通过数据引用分析来验证这个无效code是否是内联数据。
(2)提高函数边界的识别技术
现阶段的工具常用函数签名的方式来识别函数边界,效果比较差。
作者建议:开发人员可以使用基于机器学习的机制首先检测函数,然后通过考虑不同基本块之间的内部逻辑进行静态分析,以减少误报和漏报。此外,反汇编工具还可以进一步分析BL标签指令,以了解它是否是一个函数调用。作者认为对BL标签指令的使用进行进一步分析可以极大地提高函数边界的结果。