在java.util.regex包下,提供了正则表达式对字符串进行约束规范匹配
正则表达式必须依靠Pattern类和Matcher类。
Pattern
Pattern类的主要作用是编写正则规范。常用方法如下:
| 方法 | 类型 | 描述 |
|---|---|---|
| public static Pattern compile(String regex) | 静态方法 | 传入正则表达式规则,并返回Pattern实例 |
| public Matcher matcher(CharSequence input) | 普通方法 | 传入待验证字符串,并返回Matcher实例 |
Matcher
Matcher类的主要作用是执行规范,验证一个字符串是否符合其规范。常用方法如下:
| 方法 | 类型 | 描述 |
|---|---|---|
| public boolean find() | 普通方法 | 是否有符合规范的子字符串 |
| public String group() | 普通方法 | 返回符合规范的子字符串 |
| public boolean matches() | 普通方法 | 整个字符串是否符合规则 |
(子字符串:原有字符串中解析出的字符串)
正则表达式规范
常用正则表达式如下:
| 规范 | 描述 | 规范 | 描述 |
|---|---|---|---|
| \\ | 表示反斜杠( \ )字符 | \w | 字母、数字、下划线 |
| [abc] | a或b或c | \W | 非字母、数字、下划线 |
| [^abc] | 除abc | \s | 所有空白字符(换行符,空格) |
| [0-9a-zA-z] | 0到9的数字,小写的a到z,大写的A-Z | \S | 所有非空白字符 |
| \d | 数字 | . | 除换行符之外的任意字符 |
| \D | 非数字 |
多个规范也可以称之为一组规范
上述规范中大写字母一般就是小写字母的取反。
在Java中一个\用\\表示
\\
对于\\来说,第一个\是转义符。
栗子:利用正则表达式规范一个3位的纯数字。
栗子:
public static void main(String[] args) {
String txt = "asdas11121456481qwe889788978asd1asd156";//待验证字符串
Pattern compile = Pattern.compile("\\d\\d\\d");//想要实例化Pattern类,必须调用compile()方法
//Pattern compile = Pattern.compile("[0-9][0-9][0-9]");等价于上行代码
Matcher matcher = compile.matcher(txt);
while (matcher.find()){
System.out.println(matcher.group());
}
System.out.println("验证整个字符串是否符合正则规范"+matcher.matches());
}
程序运行结果:
111
214
564
//81只有两位,并不匹配
889
788
978
156
验证整个字符串是否符合正则规范false
对于整个字符串来说,肯定是不符合题目要求的三个纯数字规范的。
(书写规范会导致PatternSyntaxException异常)
正则规范限定符
用于指定限定符自身之前的规范出现的次数。
(X,Y表示一个或一组规范,,一组规范用小括号()包括)
| 规范限定符 | 限定符描述 | 实例 | 实例的描述 |
|---|---|---|---|
| X | 必须出现一个 | a | a必须出现一次 |
| X? | 可以出现0次或1次 | abc? | c可以出现0次或1次 |
| X+ | 可以出现1次或多次(至少出现一次) | (abc)+ | abc至少出现一次 |
| X* | 可以出现0次、1次或多次(可以出现任意次) | m* | m可以出现任意次 |
| X{n} | 必须出现n次 | m{3} | 必须出现3个m |
| X{n,} | 必须出现n次以上 | m{3,} | 必须出现3个m以上 |
| X{n,m} | 必须出现n到m次 | m{3,4} | 必须出现3个m到4个m |
| X|Y | 或 | a|b | a或b必须出现一次 |
Java默认是贪婪匹配,对于a{2,3}。总是会匹配3个m,也就是会匹配尽可能多的字符。
(贪婪匹配也叫贪心匹配)
当?字符紧跟其他限定符之后,就是非贪婪匹配。总是会匹配尽可能短的字符。
a{2,3}?,会尽可能匹配2个a
栗子:使用非贪婪匹配解析字符串"aaaa"
栗子:
public static void main(String[] args) {
String txt = "aaaa";
Pattern compile = Pattern.compile("a{2,3}?");//尽可能匹配2个a
Matcher matcher = compile.matcher(txt);
while (matcher.find()){
System.out.println(matcher.group());
}
}
程序运行结果:
aa
aa
//非贪婪匹配会尽可能匹配2个a。所以aaaa会被解析成两个aa
正则规范定位符
用于规范字符出现的位置。
规范定位符 定位符描述 实例 实例的描述
^ 开头 ^[0-9]+ 必须以数字开头并至少有一个数字
$ 结尾 ^\d+a$ 必须以数字开头并至少有一个数字,且必须是a结尾
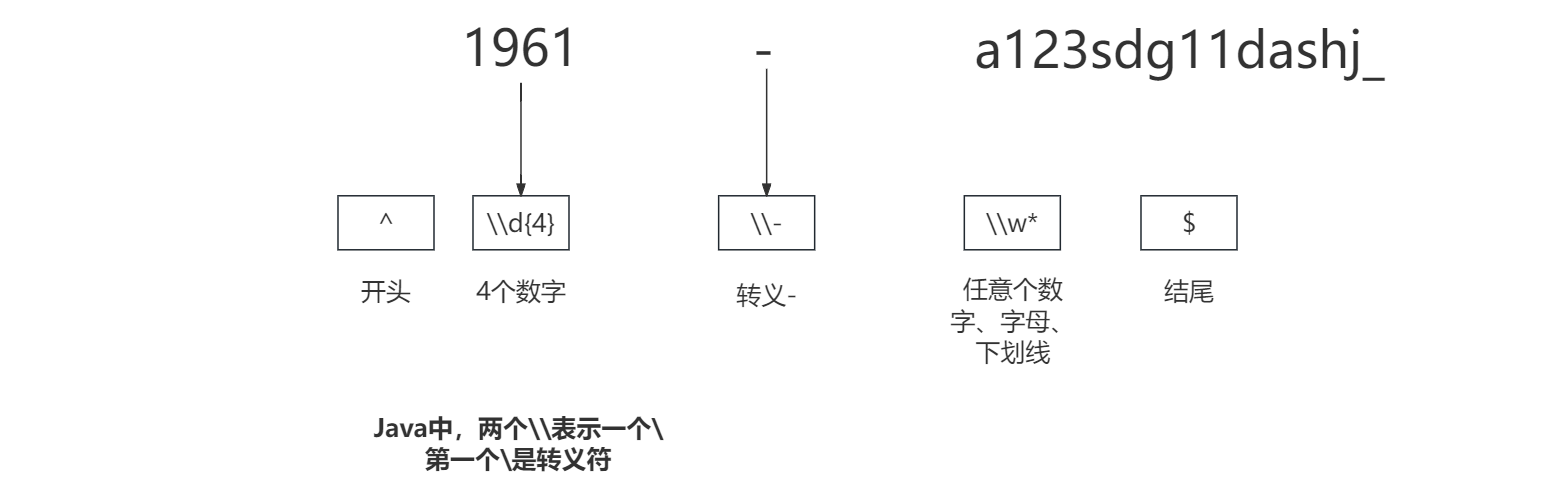
栗子:利用定位符与限定符解析字符串"1961-a123sdg11dashj_"。
栗子:
public static void main(String[] args) {
String txt = "1961-a123sdg11dashj_";
Pattern compile = Pattern.compile("^\\d{4}\\-\\w*$");
Matcher matcher = compile.matcher(txt);
if (matcher.find()){
System.out.println("匹配");
}else {
System.out.println("不匹配");
}
}
程序运行结果:
匹配
解析:
注意!!正则表达式一种题目,肯定拥有多种不同的写法,切忌吊死在一棵树上!!
注意!!正则表达式一种题目,肯定拥有多种不同的写法,切忌吊死在一棵树上!!
注意!!正则表达式一种题目,肯定拥有多种不同的写法,切忌吊死在一棵树上!!
分组规范
在一组规范中,可以再次细分组,使用小括号包括。称之为分组规范
"^[0-9]+194-[abcdf]" 这种可以称之为一组规范
在上述一组规范基础上,可以再次细分。
"^[0-9]+(194-)([abcdf])"
194- 称之为第一组
[abcdf] 称之为第二组
栗子:利用分组规范解析字符串"15as4das6d86asfas54d6sad65sa556as4d5sad4a6s5"
解析出 (\d\d)(\w\d)这种的模式的字符
并依次打印第一组,第二组字符
栗子:
public static void main(String[] args) {
String txt = "15as4das6d86asfas54d6sad65sa556as4d5sad4a6s5";
Pattern compile = Pattern.compile("(\\d\\d)(\\w\\d)");
Matcher matcher = compile.matcher(txt);
while (matcher.find()) {
System.out.println(matcher.group(0));//得到整体符合规范的字符串
System.out.println(matcher.group(1));//得到整体符合规范的字符串的第一组规范
System.out.println(matcher.group(2));//得到整体符合规范的字符串的第二组规范
System.out.println(matcher.group(3));//得到整体符合规范的字符串的第三组规范,没有 报错
}
}
程序运行结果:
54d6
54
d6
Exception in thread "main" java.lang.IndexOutOfBoundsException: No group 3
at java.util.regex.Matcher.group(Matcher.java:538)
at module3.Test26.main(Test26.java:16)
注意,正则并没有书写错误,所以并没有出现PatternSyntaxException异常。
反向引用
在规范中引用规范。称之为反向引用。
(X)\\1
X是一个或一组规范,\\1表示引用第一组规范。
栗子:利用反向引用解析出字符串"asd1221a4s8d7asd199144878844568455222"
中 nmmn这种模式的数字。
栗子:
public static void main(String[] args) {
String txt = "asd1221a4s8d7asd199144878844568455222";
Pattern compile = Pattern.compile("(\\d)(\\d)\\2\\1");
Matcher matcher = compile.matcher(txt);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
程序运行结果:
1221
1991
利用正则结巴去重案例,非常精彩,有兴趣可以看看韩顺平-正则结巴去重