从 TCP 聊起
作为一个程序员,假设我们需要在A电脑的进程发一段数据到B电脑的进程,我们一般会在代码里使用 socket 进行编程。
此时我们可选项一般也就 TCP 和 UDP 二选一。TCP 可靠,UDP 不可靠。除非是马总这种神级程序员(早期 QQ 大量使用UDP),否则,只要稍微对可靠性有些要求,普通人一般无脑选 TCP 就对了。
类似下面这样。
fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
其中SOCK_STREAM,是指使用字节流传输数据,说白了就是 TCP 协议。
通过该方法得到的 fd 是 socket 文件的句柄,是个数字,相当于 socket 的身份证号。
- 对于服务端,得到
fd后,就可以依次执行bind()绑定 IP 端口,listen(),accept()方法,然后坐等客户端的连接请求。 - 对于客户端,得到
fd后,就可以执行connect()方法向服务端发起建立连接的请求,此时就会发生 TCP 三次握手。 - 连接建立完成后,客户端可以执行
send()方法发送消息,服务端可以执行recv()方法接收消息,反过来,服务器也可以执行send(),客户端执行recv()方法。
光这样一个纯裸的 TCP 链接能收发数据,但它是个无边界的数据流,会有粘包问题,上层需要定义消息格式用于定义消息边界。于是就有了各种协议,如 HTTP 和各类基于 RPC 的协议 (gRPC. thrift),这些都是定义了不同消息格式的应用层协议。
RPC 是一种普适性的思想,有很多种实现方式,不一定非得基于 TCP 协议,也可基于 UDP, HTTP。(gRPC底层直接采用 HTTP2)
粘包问题
TCP 的特点:面向连接、可靠、基于字节流。
字节流可理解为一个双向的通道里流淌的数据,这个数据其实就是二进制数据,简单来说就是一大堆 01 串。纯裸 TCP 收发的这些 01 串之间是没有任何边界的,你根本不知道到哪个地方才算一条完整消息。
正因为这个没有任何边界的特点,所以当我们选择使用TCP发送 "夏洛"和"特烦恼" 的时候,接收端收到的就是 "夏洛特烦恼",这时候接收端没发区分你是想要表达 "夏洛"+"特烦恼" 还是 "夏洛特"+"烦恼"。
—— 这就是所谓的粘包问题。
因此为解决纯裸 TCP 的粘包问题,要在这个基础上加入一些自定义的规则,用于区分消息边界。
于是我们会把每条要发送的数据都包装一下,比如加入消息头,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的消息体。
消息头还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认就可以了,这就是所谓的协议。
每个使用 TCP 的项目都可能会定义一套类似这样的协议解析标准,他们可能有区别,但原理都类似。
于是基于 TCP,就衍生了非常多的协议,比如 HTTP 和各类基于 RPC 的协议。
RPC 理论基础
BRUCE JAY NELSON 在其1984年的论文《Implementing Remote Procedure Calls》中描述到,当我们在程序中发起 RPC 调用时,会涉及5个模块:
- user:发起调用的应用模块,发起rpc调用 会和发起本地调用一样,不感知rpc底层逻辑。
- user-stub:负责调用请求的打包以及结果的解包。
- RPCRuntime:RPC 运行时,负责处理远程网络交互,如网络包重传、加密等。
- server-stub:负责请求的解包以及结果的打包。
- server:真正提供服务处理的应用模块。

下面展示一个「麻雀虽小五脏俱全」的RPC框架,去除了管控平台等辅助功能。通过对核心功能进行设计和实现,理解整个RPC框架的设计原理。
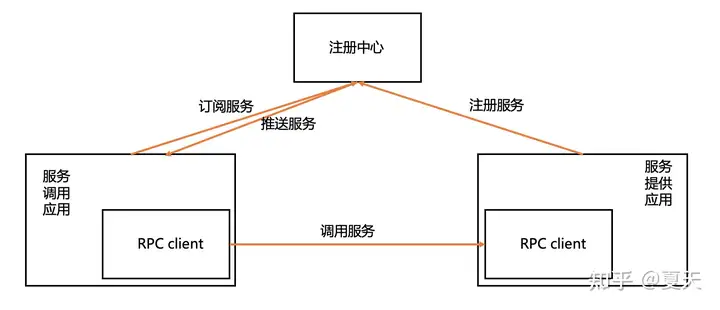
涉及核心技术:
- 注册中心:服务端将发布的服务注册到注册中心,调用端从注册中心订阅服务,获得服务的地址,才能发起调用。
- 分布式环境不同服务器之间需要通过网络通信(RPC client)。
- 网络通信必然涉及到编解码。
- 避免每次寻址都需要调用注册中心,服务调用端还需要对服务信息进行缓存。
- 动态代理:方便对客户端调用透明化。
HTTP 和 RPC
TCP是传输层的协议,而HTTP 和各类 RPC 的协议,都只是定义了不同消息格式的应用层协议。
HTTP协议 (Hyper Text Transfer Protocol):超文本传输协议,底层采用 TCP 协议。浏览器使用的就是 HTTP 协议。
RPC (Remote Procedure Call):远程过程调用,即通过网络向远程计算机请求服务。它本身并不是一个具体的协议,而是一种调用方式。希望像调用本地方法那样调用远端方法,屏蔽掉一些网络细节,更便于使用。

基于 RPC 思想,大佬们造出了多种协议,如 gRPC. thrift。
❗️虽然大部分 RPC 协议底层使用 TCP,但实际上不是非得使用 TCP,改用 UDP 或 HTTP,其实也能做到类似的功能。
HTTP ? RPC
TCP是70年代出来的协议。
RPC 概念于 1974 年提出,并在 1984 年就被实现用于分布式系统的通信,Java 在 1.1 版本提供了 Java 版本的 RPC 框架 (RMI)。
而 HTTP 协议在 1990 年才开始作为主流协议出现。
所以 PRC 是先出现的,那为啥有了 RPC 还要 HTTP?
现在电脑端的软件,作为客户端(client)需要跟服务端(server)建立连接收发消息,此时都会用到应用层协议,在这种 client/server (c/s) 架构下,它们可以使用自家造的 RPC 协议,因为它只管连自己公司的服务器就ok了。
但有个软件不同,浏览器(browser)不仅要能访问自家公司的服务器(server),还要访问其他公司的网站服务器,因此它们需要有个统一的标准,不然大家没法交流。于是,HTTP 就是那个时代用于统一 browser/server (b/s) 的协议。
也就是说在多年以前,HTTP主要用于 b/s 架构,而 RPC 更多用于 c/s 架构。但现在其实已经没分那么清了,b/s 和 c/s 在慢慢融合。很多软件同时支持多端,比如某度云盘,既要支持网页版,还要支持手机端和 pc 端,如果通信协议都用 HTTP 的话,那服务器只用同一套就行。而 RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
那这么说的话,都改用 HTTP 得了,还用什么 RPC?
我们对比下 RPC 和 HTTP 区别较明显的几个点。
服务发现
要向某个服务器发起请求,得先建立连接,而建立连接的前提是知道 IP 地址和端口。这个找到服务对应的 IP 端口的过程,就是服务发现。
在 HTTP 中,知道服务的域名,就可以通过 DNS服务 去解析得到它背后的 IP 地址,默认 80 端口。
而 RPC 的话,就有些区别,一般会有专门的 中间服务 去保存服务名和 IP 信息,比如 consul 或 etcd,甚至是 redis。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如 CoreDNS。
可以看出服务发现这一块,两者是有些区别,但不太能分高低。
底层连接形式
以主流的 HTTP1.1 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接 (keep alive),之后的请求和响应都会复用这条连接。
而 RPC 的协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 的协议一般还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。
由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 go 就是这么干的。
可以看出这一块两者也没太大区别,所以也不是关键。
传输内容
基于 TCP 传输的消息,说到底,无非都是消息头 header 和消息体 body。
header 是用于标记一些特殊信息,其中最重要的是消息体长度。
body 则存放真正需要传输的内容,而这些内容只能是二进制01串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成01串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制01串,这样的方案现在也有很多现成的,比如 json,protobuf。
这个将结构体转为二进制数组的过程就叫 序列化,反过来将二进制数组复原成结构体的过程叫 反序列化。
对于主流的 HTTP1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计初是用于做网页文本展示的,所以它传的内容以字符串为主。header 和 body 都是如此。在 body 这块,它使用 json 来序列化结构体数据。
可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像header里的那些信息,其实如果我们约定好头部的第几位是 content-type,就不需要每次都真的把 "content-type" 这个字段都传过来,类似的情况其实在body的 json 结构里也特别明显。
而 RPC,因为它定制化程度更高,可以采用体积更小的 protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如302重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用RPC的最主要原因。

当然上面说的HTTP,其实特指的是现在主流使用的HTTP1.1,
HTTP2在前者的基础上做了很多改进,所以性能可能比很多 RPC 协议还要好,甚至连gRPC底层都直接用的HTTP2。那为啥有了 HTTP2,还要有 RPC?
这个是由于 HTTP2 是 2015 年出来的。那时很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。
小结
- 纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义消息边界。于是就有了各种协议,HTTP 和各类基于 RPC 的协议就是在 TCP 之上定义的应用层协议。
- RPC本质上不是协议,而是一种调用方式,而像 gRPC和 thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。同时RPC有很多种实现方式,不一定非得基于 TCP 协议,也可基于 UDP, HTTP。(gRPC底层直接采用 HTTP2)
- 从发展历史来说,HTTP主要用于 b/s 架构,而 RPC 更多用于 c/s 架构。但现在其实已经没分那么清了,b/s 和 c/s 在慢慢融合。很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
- RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
- HTTP2.0 在 HTTP1.1 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
参考链接
关于 socket
- socket 中文套接字,我理解为一套用于连接的数字。socket 本质是一个代码库 or 接口层,它介于内核和应用程序之间,提供了一些高度封装过的接口,让我们去使用内核网络传输功能。
- sock在内核,socket_fd 在用户空间,socket 层介于内核和用户空间之间。
- 在操作系统内核空间里,实现网络传输功能的结构是 sock,基于不同的协议和应用场景,会被泛化为各种类型的 xx_sock,它们结合硬件,共同实现了网络传输功能。为了将这部分功能暴露给用户空间的应用程序使用,于是引入了 socket 层,同时将 sock 嵌入到文件系统的框架里,sock 就变成了一个特殊的文件,用户就可以在用户空间使用文件句柄,也就 是socket_fd 来操作内核 sock 的网络传输能力。
- 服务端可以通过四元组来区分多个客户端。
- 内核通过c语言"结构体里的内存是连续的"这一特点实现了类似继承的效果。