Faster R-CNN的发展史
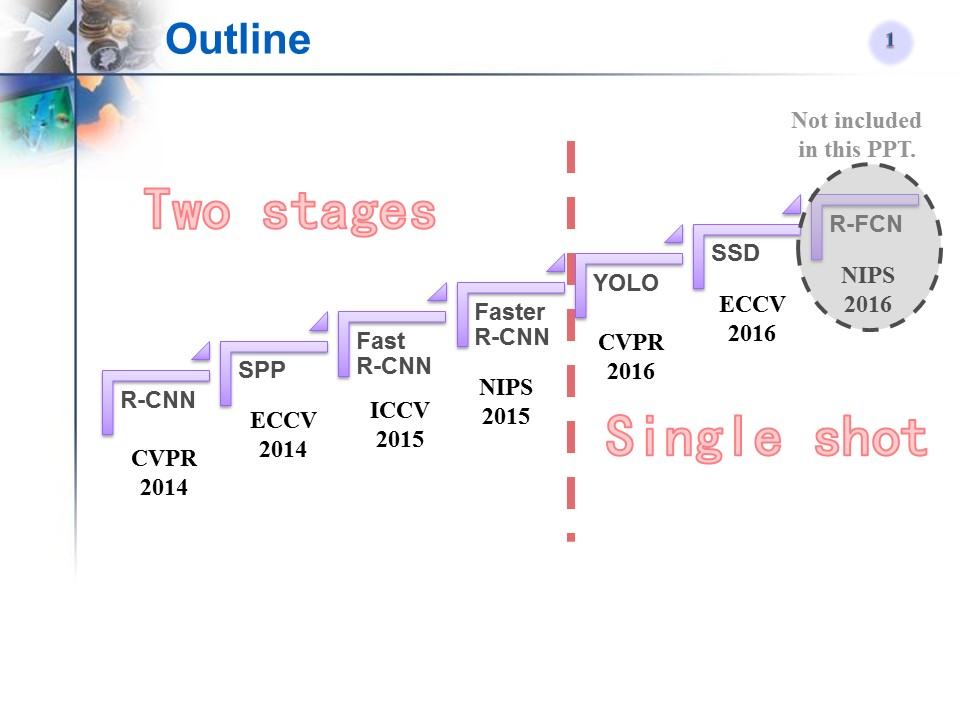

- Selective Search(2012)
- RCNN(2014)
- SPPNet(2014)
- Fast R-CNN(2015)
- Faster R-CNN(2015)
- 总结
- 补充:Mask RCNN
- 7.1、FPN
- 7.2、RPN
- 7.3、ProposalLayer层
- 7.4、DetectionTarget层(预测框匹配groundTrue)
- 7.5、ROIAlign
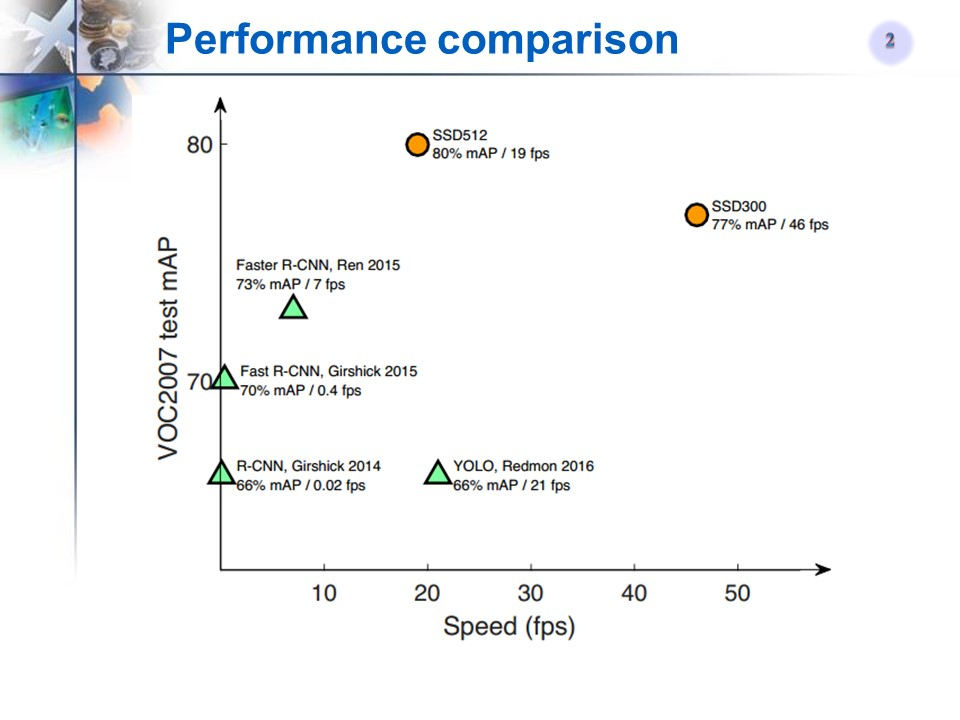
8.补充:历年主流网络型对比、常用数据集
上面的目标检测网络上是按照顺序写的,Faster R-CNN之后是YOLOV1、SSD、YOLOV2、3、4、5,可以看到one-stage才能战未来。只要认真学习Faster R-CNN,后续学习其他网络,你都会看到Faster-RCNN的影子。
1.Selective Search(2012)
网络最终输出层,对齐进行回归、分类
初代目标检测算法:Selective Search:依据图像颜色、纹理、大小等指标,给定多个候选框,然后再去筛查。

2.RCNN(2014)
RCNN的全称是:Region-CNN。下图中,Bbox reg表示位置的回归,SVMs表示分类。
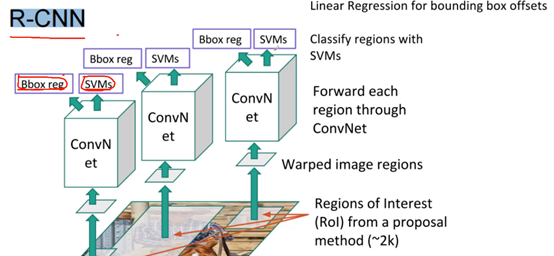
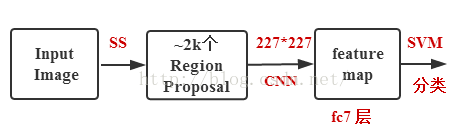
如上图,2014年的RCNN思想:训练的时候,基于Selective Search给定2000个候选框,通过卷积得到最终特征图,然后依据最终特征图分别进行分类和回归(一张图需要2000次前向传播)。效果比较好(2000多个候选框,对小物体也比较友好),但是速度慢(一张图27s)、没有共享卷积。

补充:SPPNet也是需要selective search来选择候选框,离线训练;其最大贡献在于:解除由于FC层导致网络输入图像大小必须固定的问题。
参考:https://zhuanlan.zhihu.com/p/27485018
3.SPPNet
针对RCNN卷积不能共享的缺陷,如下图,先用pooling将不同size的特征图下采样到相同size,接着展开、并链接FC层;通过以上方法,可实现卷积共享。

SPPNet优点:实现了卷积共享,加快了训练速度。缺点:多尺度maxpooling,计算量较大。
4.Fast R-CNN(2015)
Fast R-CNN不再是原图应用Selective Search上找候选框了,而是在卷积层中找,这能够避免对原图每个候选区域分别卷积,极大地提升了速度,如下图:
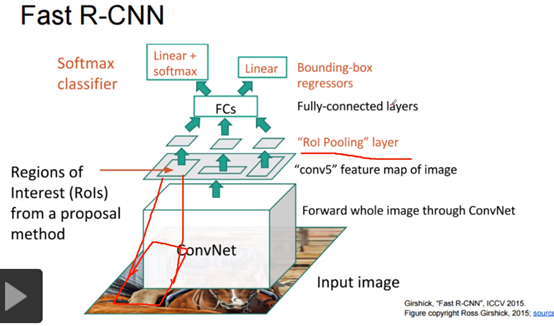
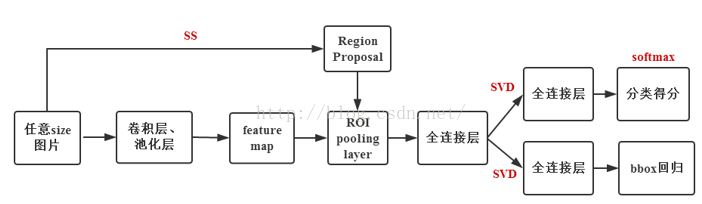
另外,上图中的ROI Pooling layer类似于SPP层,后续MaskRCNN中采用了精度更高的ROI Align进行改进。ROI pooling相当于单层的SPPNet,后面还是要接FC层!因为ROI Pooling都应ROI特征统一尺寸了。话说,注意YOLOV5中的SPP和SPPNet网络的区别是不一样的,YOLOV5中的,指示设定pooling的size不同,输出的特征图宽高还是一样的。
小结:R-CNN是在原图找到2000个候选区域,然后分别对候选区域卷积;Fast R-CNN 先对原图卷积,然后在卷积中找到2000个候选区域,然后再卷积,也就是上图的ConvNet处改进了计算量,但是也到2s一帧。
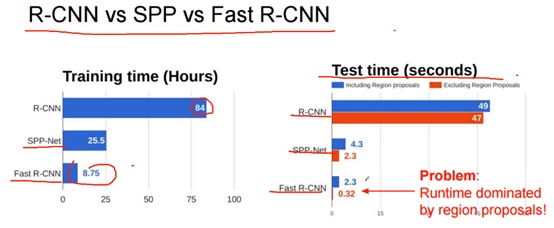
可以看到,FastRCNN已经是很快了,但是还有优化空间,其中Selective Search占据了大量时间。‘
优点:使用了简化版SPP(ROI Pooling,参考:https://zhuanlan.zhihu.com/p/24780395),单尺度Maxpooling,加快了速度。。。。。
训练的时候是一个two-stage的模型,还是要ss提供proposals。
缺点:
5.Faster R-CNN(2015):
Faster R-CNN = Fast R-CNN + RPN
如下图,有一个RPN(Region Proposal Network)网络(此时,Faster RCNN已经去除了Selective Search的方案), 在特征图上,找到候选区域后,先进行二分类和回归;如果是正例,进一步地,然后在网络末端进行20分类和回归(还是two-stage)。训练的时候,loss有四项,如下图。
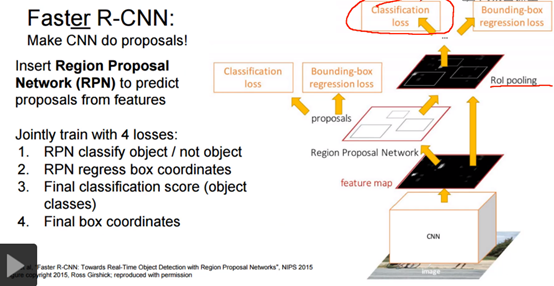
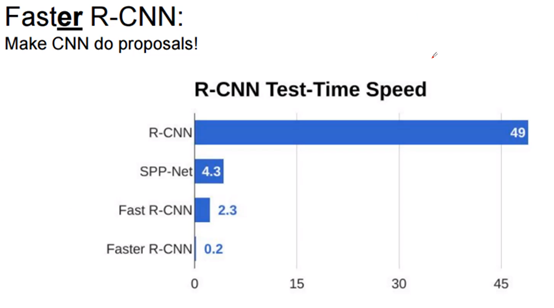
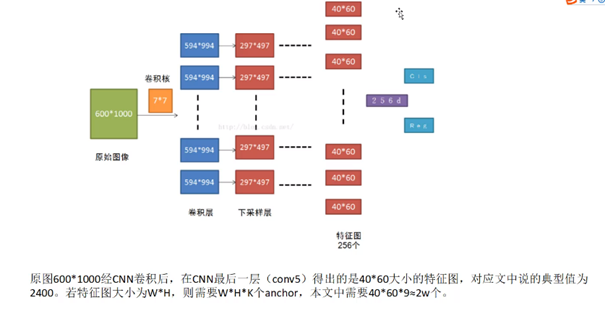
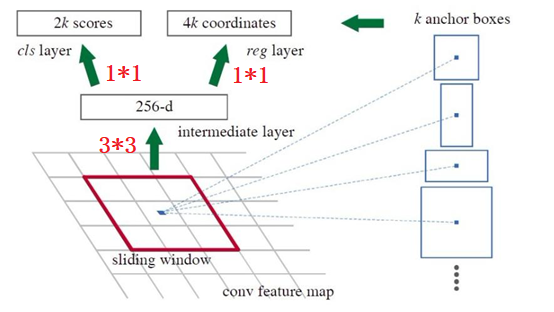
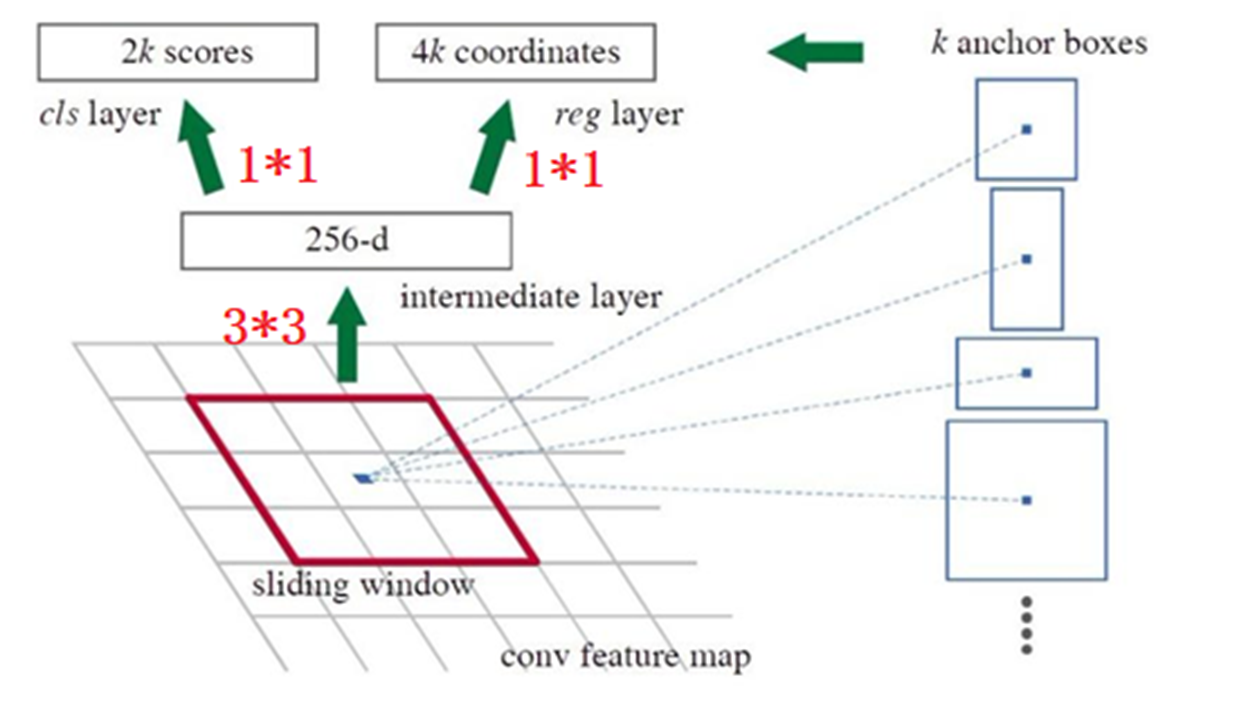
网络中的RPN层,如下图,卷积过程中,k取值为9(表示3个scale中,3个比例的候选框,在YOLO系列中,我已经说过),2k中的2表示候选框的二分类(如果候选框和任何一个GT的IOU大于0.7,那就是正例),表示是否有目标。4k中的4表示候选框的位置信息。RPN区域建议网络用来提取检测区域,它能和整个检测网络共享全图的卷积特征,使得区域建议几乎不花时间。

RPN层之后,有一个二分类和框位置的回归:下面是目标函数,候选框的分类和置信度的回归。其中pi=1 or 0,表示候选框是否为目标。简单了解:只有当候选框是正例的时候,才会对框进行微调。
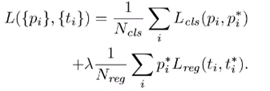
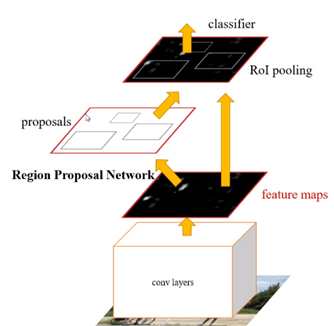
以上就是RPN的过程,如下图,RPN之后,得到一堆是正例且微调过的候选框(经过了NMS筛选),最后经过classifier分类器进行具体分类;这就是two-stage。
最后,有关RPN,补一张图:
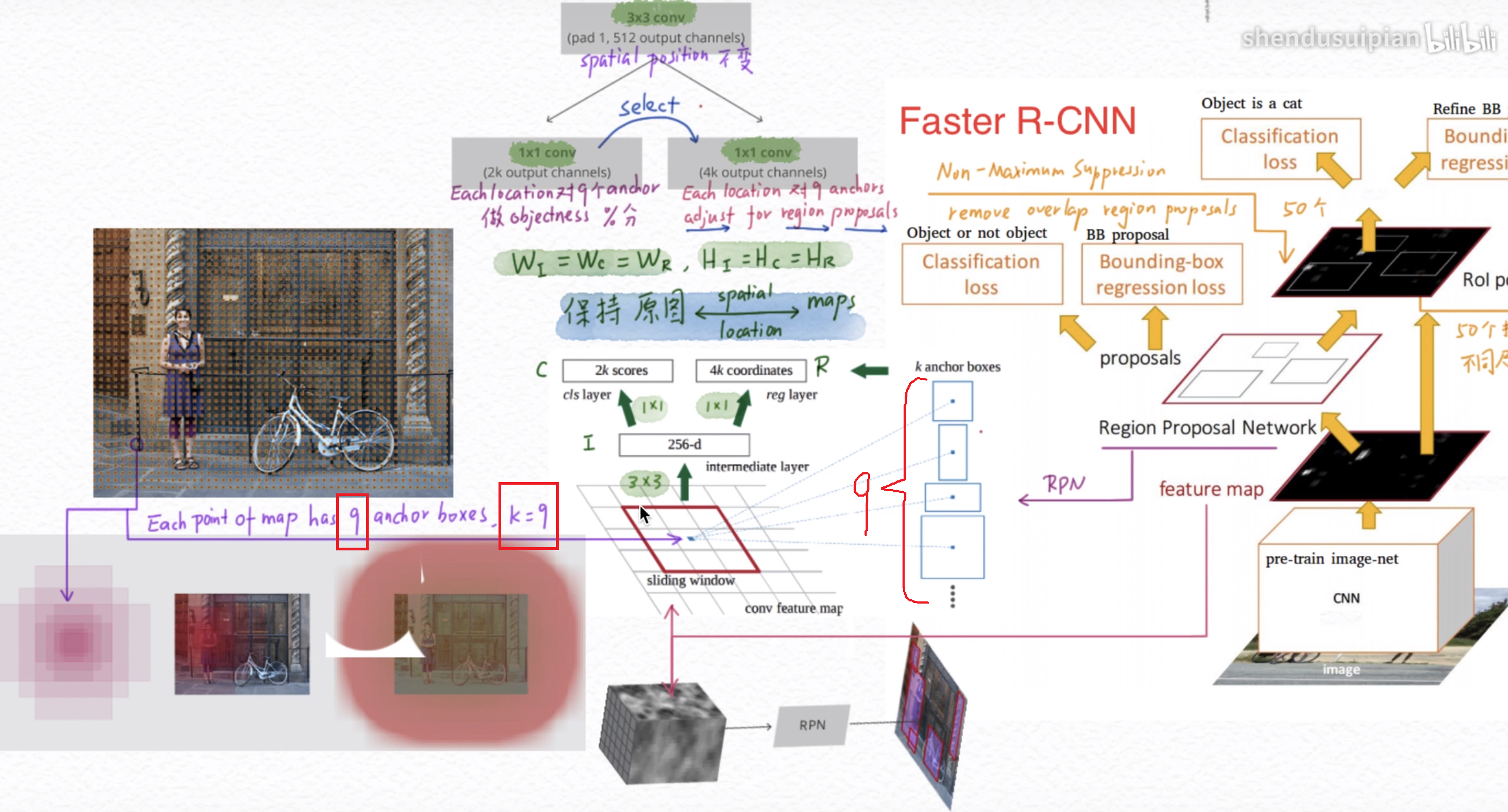
RPN过程:
1、将vgg中输出的特征图输入到RPN,每个元素对应k=9个框(3种尺度,假定其中一种尺度特征图H、W为:60、40,那么候选框就有60*40*9约20000)
2、利用3×3卷积得到256-d的特征图
3、利用1×1卷积分别得到2k个二分类得分,4k个位置信息(4:x y h w)
4、NMS去除冗余框(例如:2000个框筛选后,只剩下50个)
Faster RCNN是two-stage,但是end-end从头可以直接优化到尾的网络。
6. 总结

| 优点(改进 | 缺点 | 单帧推理速度 | VOC(mAp) | 网络结构 | 网络类型 | |
| RCNN | 没有共享卷积,计算量大 | 49s | 66% | 原图SS->conv->框回归+分类 | two-stage | |
| Fast-RCNN | selective search计算量大 | 2.3s | 70% | 原图conv->特征图SS->框回归+分类 | two-stage | |
| Faster-RCNN | 0.2s | 73% | 原图conv->RPN->conv->框回归+分类 | two-stage(端到端) |
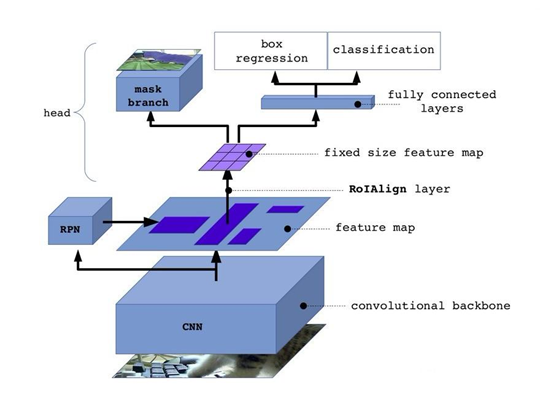
 7、补充:Mask RCNN
7、补充:Mask RCNN
是faster rcnn基础上改进,增加了一个分支。Fps:5。它的识别,先目标检测到roi,再到roi上进行分割。

7.1、FPN(Feature Pyramid Networks):
(顺便PANet:Path Aggregation Network for Instance Segmentation)

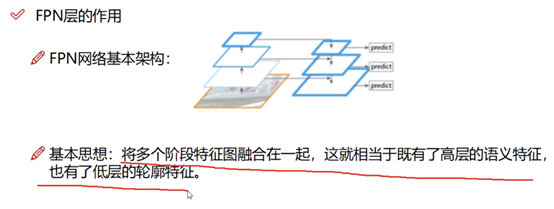
基于3*3卷积(stride设置2等,fpn是插值)调整W、H,基于1*1卷积调整C,这样就能将不同大小特征图进行叠加(resnet的sortcut处就是这样处理的)。
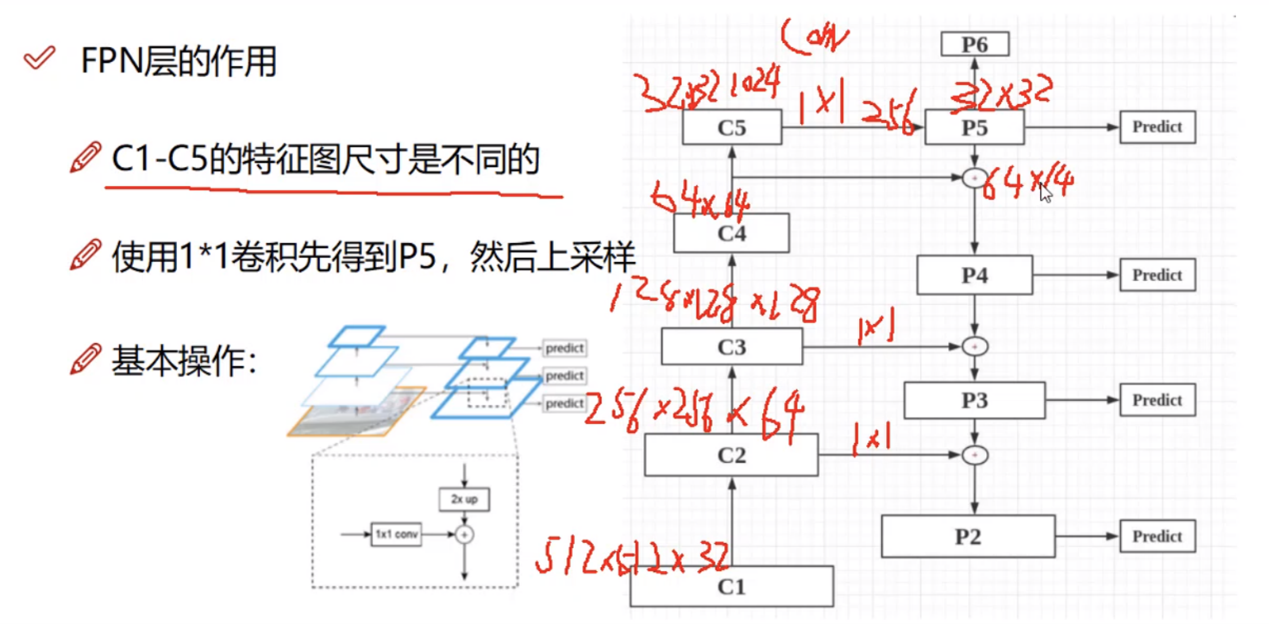
FPN是自上而下进行特征图相加(对应元素相加)。
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE, stage5=True)
- _: 256*256*64
- C2: 256*256*256
- C3: 128*128*512
- C4: 64*64*1024
- C5: 32*32*2048
下面是开始执行FPN操作代码,可以看到,基于1*1卷积,输出的都是C=256的特征图:
1 # P5:32*32*2048 -> 32*32*256 2 P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5) 3 # P4:64*64*256 4 P4 = KL.Add(name="fpn_p4add")([ 5 # 这里P5上采样:32*32*256 -> 64*64*256 6 KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5), 7 # 这里C4降维:64*64*1024 -> 64*64*256 8 KL.Conv2D(256, (1, 1), name='fpn_c4p4')(C4)]) 9 P3 = KL.Add(name="fpn_p3add")([ 10 KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4), 11 KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)]) 12 P2 = KL.Add(name="fpn_p2add")([ 13 KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3), 14 KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])
以上得到:
- P2:256*256*256
- P3: 128*128*256
- P4: 64*64*256
- P5: 32*32*256
如上图,P2-5连接到predict之前,又再次进行3*3卷积:
1 # Attach 3x3 conv to all P layers to get the final feature maps. 2 P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2) 3 P3 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p3")(P3) 4 P4 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p4")(P4) 5 P5 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p5")(P5) 6 # P6 is used for the 5th anchor scale in RPN. Generated by 7 # subsampling from P5 with stride of 2. 8 P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
以上得到:
- P2:256*256*256
- P3: 128*128*256
- P4: 64*64*256
- P5: 32*32*256
- P6: 16*16*256
这里P2-6经过3*3卷积,channel维度都是256;后面又是两拨1*1卷积得到得分、boudingBox如下图:
7.2、RPN
generate_pyramid_anchors,根据特征图生成所有候选框(anchors)

在FPN中,我们得到特征图P2-6,对P2-5提取候选框,
- P2:256*256*256
- P3: 128*128*256
- P4: 64*64*256
- P5: 32*32*256
- P6: 16*16*256
下面是候选框生成方式:
1 scales: 1D array of anchor sizes in pixels. Example: [32, 64, 128] 2 ratios: 1D array of anchor ratios of width/height. Example: [0.5, 1, 2] 3 shape: [height, width] spatial shape of the feature map over which to generate anchors.
Scales表示基础框大小,三个尺度[32 64 128],ratios表示长宽的三个比例[0.5 1 2]。每个像素点,候选框的计算方式如下:
# Enumerate heights and widths from scales and ratios
- heights = scales / np.sqrt(ratios)
- widths = scales * np.sqrt(ratios)
如上图,例如:已经在P2:256*256上计算出候选框的宽高(假定原图分辨率:1024*1024),需要将候选框位置信息缩放映射为原图(256*4 = 1024)。对于P2产生的候选框数量为:256*256*9。其实,一共获取大概26W个候选框,代码如下:
# Generate Anchors self.anchors = utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES, # config.RPN_ANCHOR_SCALES (32, 64, 128, 256, 512),具体可手动设置几个尺度 config.RPN_ANCHOR_RATIOS, # [0.5, 1, 2] config.BACKBONE_SHAPES, config.BACKBONE_STRIDES, config.RPN_ANCHOR_STRIDE)
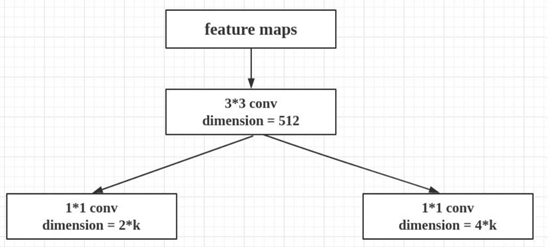
下面将候选框对应特征图(P2-6)区域放进RPN中,k=9,就是上面一个点对应9个候选框,2k=18,表示二分类的概率值,4k=36表示初步优化候选框的位置信息。
如图,对特征图P2-6中每一个特征图进行3*3卷积(这里就是共享卷积了,如上图conv feature map),得到W*H*256特征图(不同特征图经过3*3卷积之后,WH不一致,不详细说明)。
# Shared convolutional base of the RPN shared = KL.Conv2D(512, (3, 3), padding='same', activation='relu',strides=anchor_stride,name='rpn_conv_shared')(feature_map)
利用1*1卷积,得到前景背景得分rpn_class_logits (cls layer,得到特征图:anchors*2):
# Anchor Score. [batch, height, width, anchors per location * 2]. x = KL.Conv2D(2 * anchors_per_location, (1, 1), padding='valid',activation='linear', name='rpn_class_raw')(shared) # Reshape to [batch, anchors, 2] rpn_class_logits = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 2]))(x)
将得分rpn_class_logits进行softmax,得到概率值rpn_probs(anchors*2):
1 # Softmax on last dimension of BG/FG. 2 rpn_probs = KL.Activation( "softmax", name="rpn_class_xxx")(rpn_class_logits)
利用1*1卷积,得到框的初步优化位置信息rpn_box(anchors*4):
1 # Bounding box refinement. [batch, H, W, anchors per location, depth] 2 # where depth is [x, y, log(w), log(h)] 3 x = KL.Conv2D(anchors_per_location * 4, (1, 1), padding="valid", activation='linear', name='rpn_bbox_pred')(shared) 6 # Reshape to [batch, anchors, 4] 7 rpn_bbox = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 4]))(x)
最后将上述几个操作小结下,就如下图:
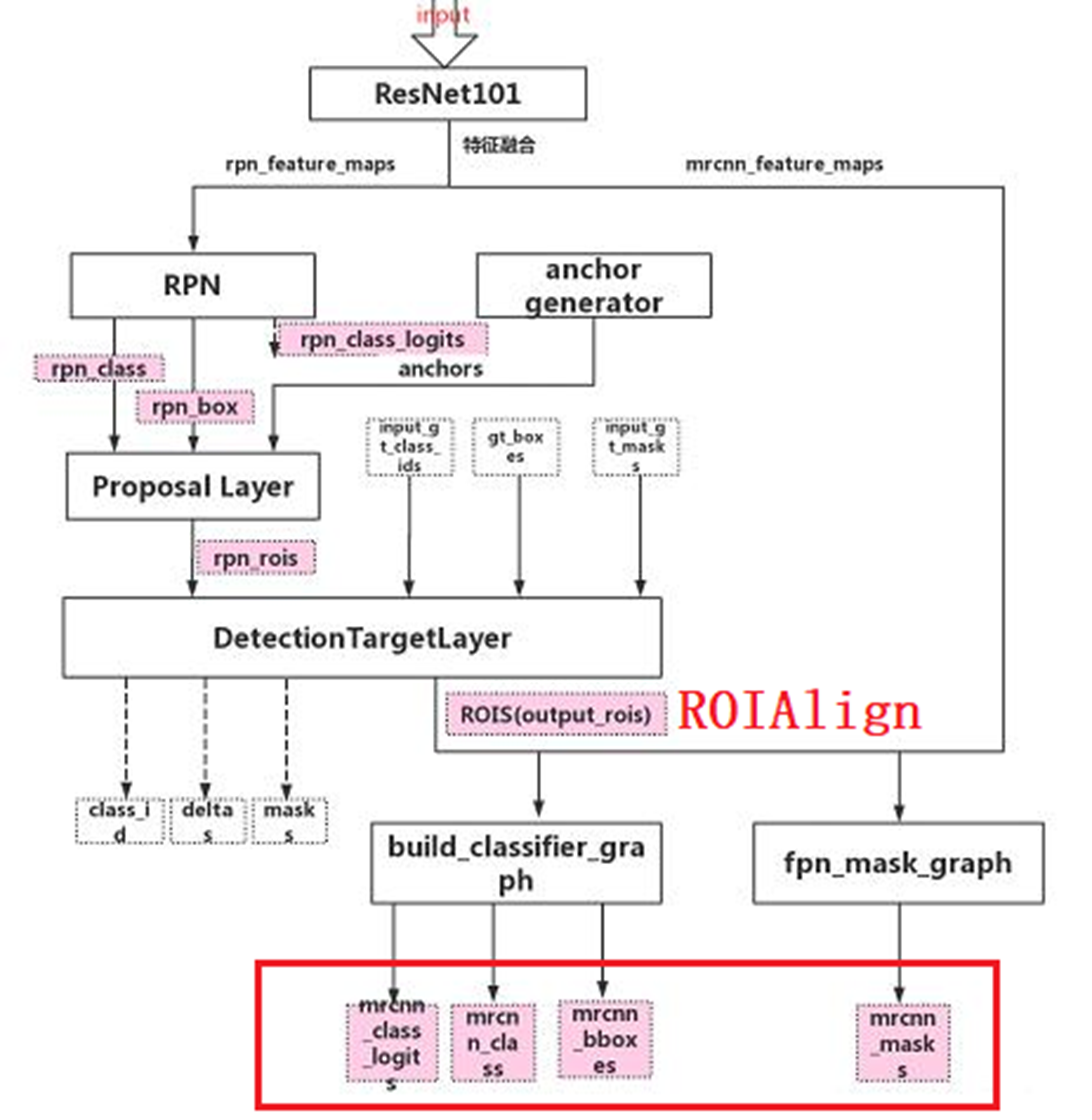
7.3、ProposalLayer层
ProposalLayer层的作用(筛选框)
- 对20W+候选框进行过滤,先按照前景得分排序
- l取6000个得分高的,把之前得到的每个框回归值都利用上
NMS再过滤:
7.4、DetectionTarget层(预测框匹配groundTrue)
1.之前得到了2000个ROI,可能有pad进来的(0充数的)这些去掉
2.有的数据集一个框会包括多个物体,这样情况剔除掉
3.判断正负样本,基于ROI和GT,通过IOU与默认阈值0.5判断
4.设置负样本数量是正样本的3倍,总数默认400个
MaskRCNN既可以目标检测、还可以做分割:
5.[目标检测-类别]每一个正样本(ROI),需要得到其类别,用IOU最大的那个GT
6.[目标检测-框]每一个正样本(ROI),需要得到其与GT-BOX的偏移量
7.[mask]每一个正样本(ROI),需要得到其最接近的GT-BOX对应的MASK
8.返回所有结果,其中负样本偏移量和MASK都用0填充
7.5、ROIAlign
现在已经得到最后筛选得到的候选框,以及对应GT。下图是Mask RCNN网路结构图:
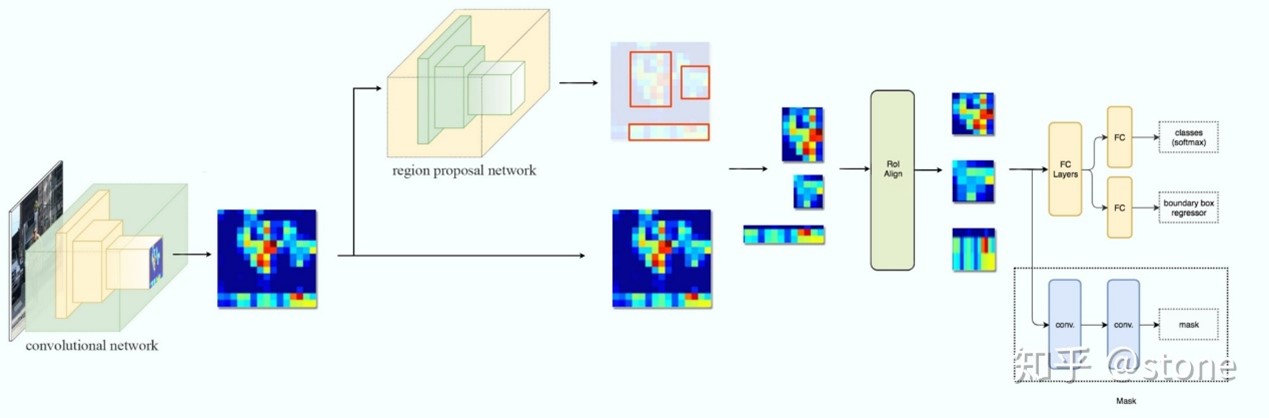
放大ROIAlign以及后续处理:
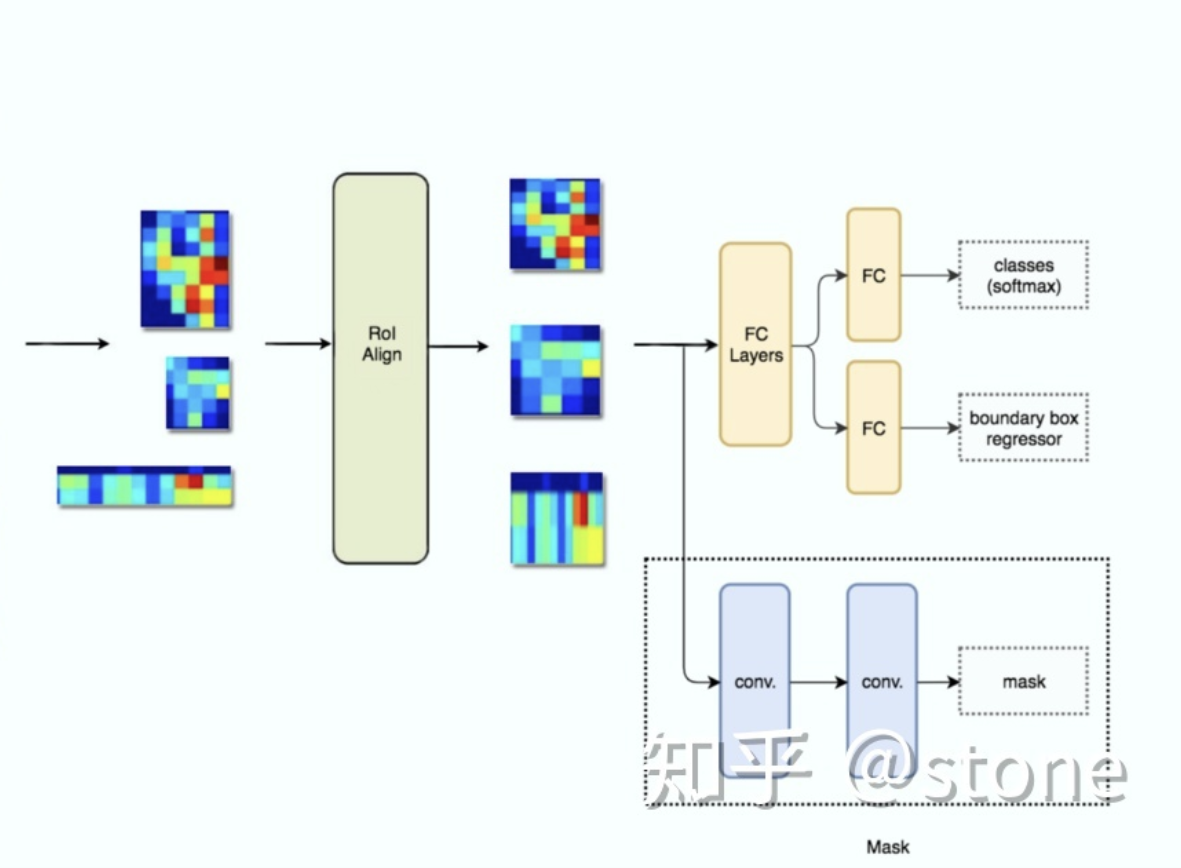
ROIAlign的作用:将特征图P2-6中对应ROI的部分取出来,各层ROI尺寸不同,利用插值+maxpooling将其大小统一,得到对齐的特征图。
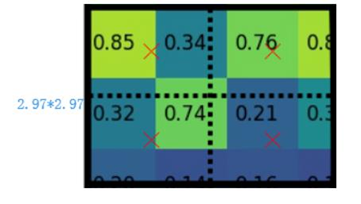
如下图,假定是2*2的pooling,但由于ROI的宽高对应是浮点数,2*2区域对应原特征图大小是2.97*2.97区域,可以利用双线性插值算出该区域的四个值,然后执行2*2maxpooling。(如果将2.97取整为2,假定ROI特征图对应原图缩放了32倍;那么将会给原图带来0.97*32个像素的定位误差,对于大物体检测没多大影响,对于小物体检测影响很大)
紧接着,对于目标检测:分别连接FC层进行分类、回归。
分类(mrcnn_probs:1000*2):
1 # Classifier head 2 mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),name='mrcnn_class_logits')(shared) 4 mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),name="mrcnn_class")(mrcnn_class_logits)
回归定位(x:1000*8,8 = 2*4,包含负例):
1 # BBox head 2 # [batch, boxes, num_classes * (dy, dx, log(dh), log(dw))] 3 x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),name='mrcnn_bbox_fc')(shared)
对于实例分割:进行卷积、池化、sigmoid最终得到28*28*2的mask特征图,最后和GT作二值交叉熵。
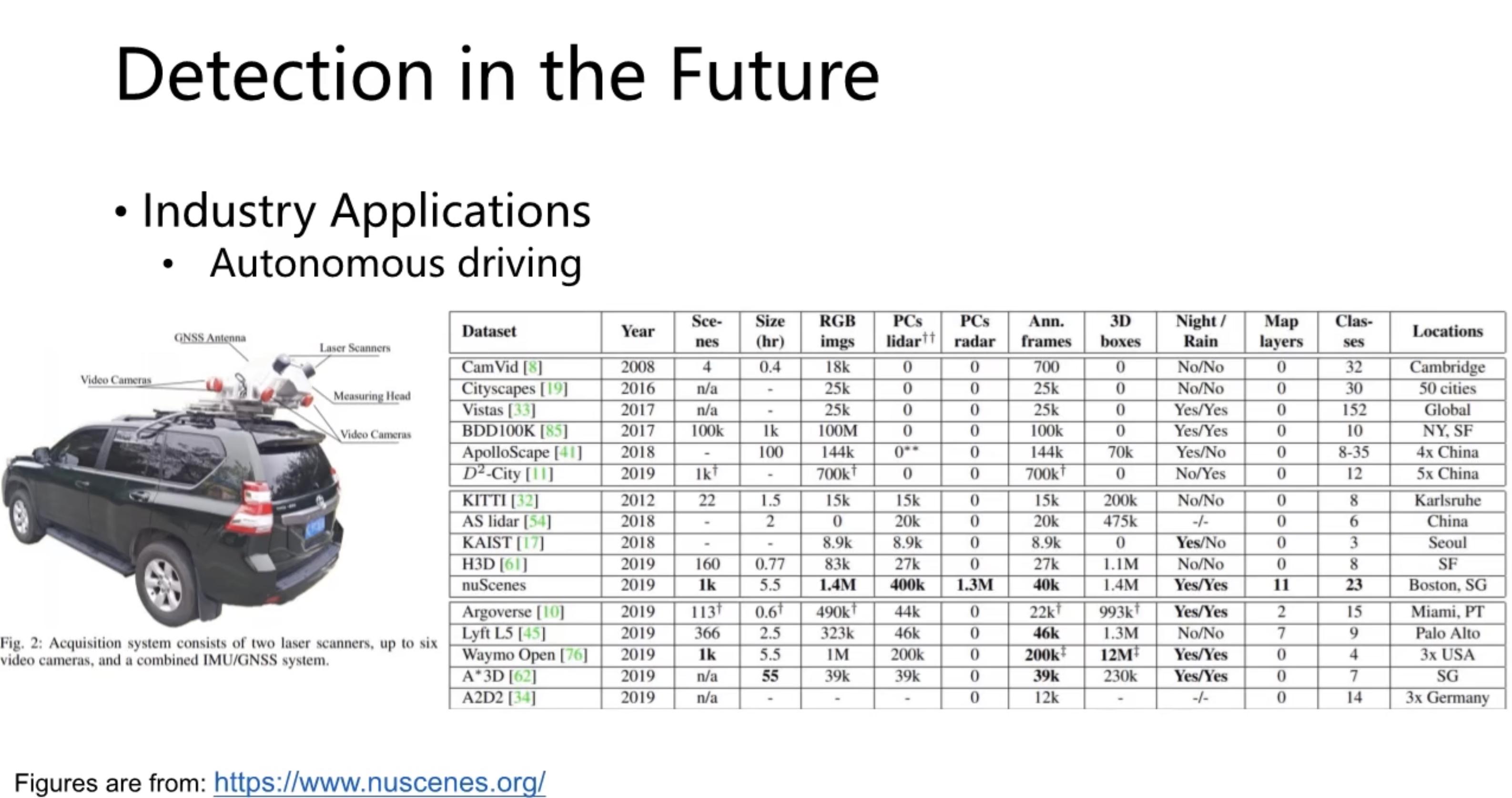
8.补充:历年主流网络型对比、常用数据集
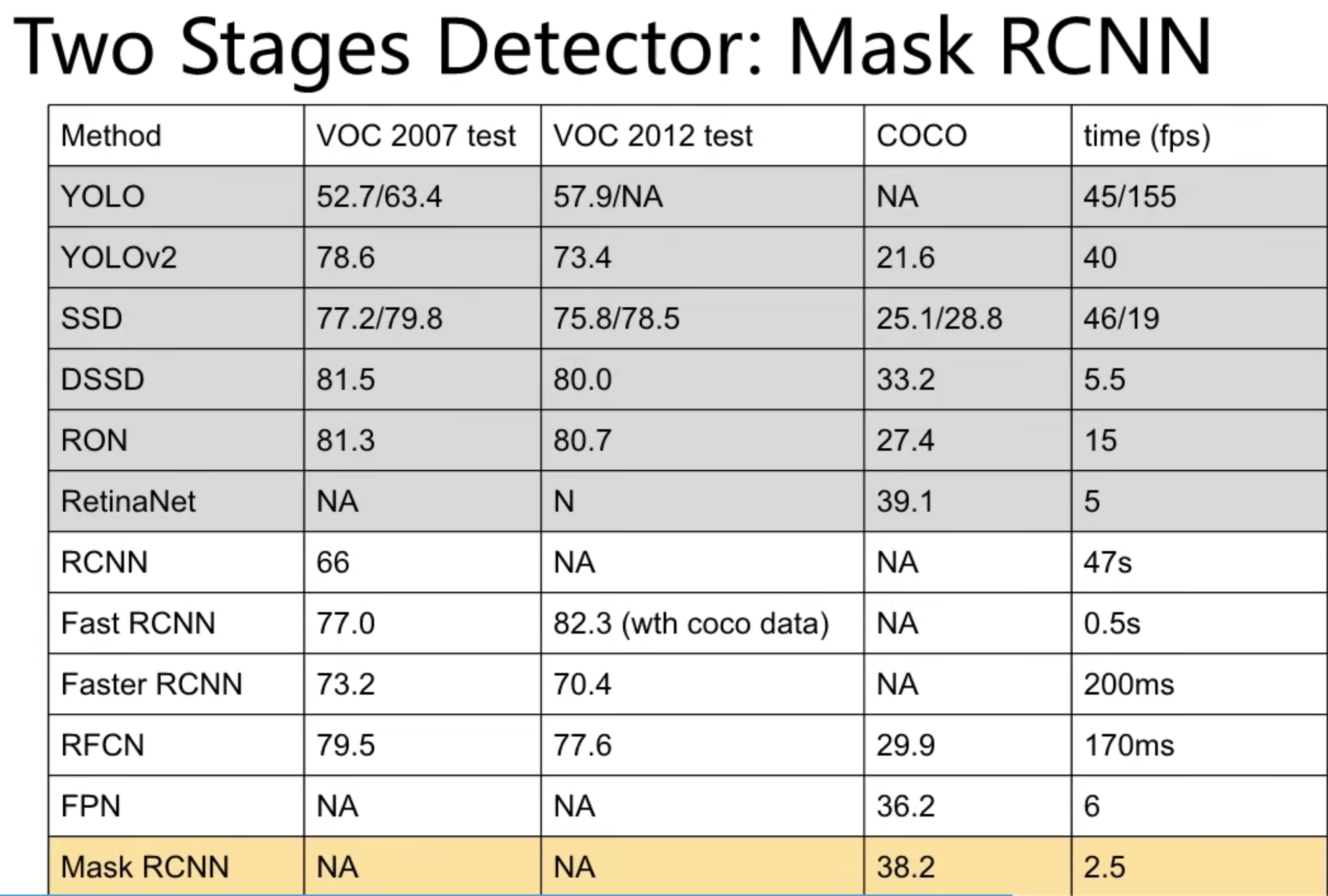
常用数据集:
Reference:https://blog.csdn.net/majinlei121/article/details/53870433
ROI Pooling:https://zhuanlan.zhihu.com/p/37998710