1. 单个循环延迟优化
1.1 循环展开(Unroll)
- 将一个循环展开成多个循环,复制多个循环电路,并行执行;消耗更多的资源换取加速效果。
- 例子如下
for (int i = 0; i < 4; i++)
{
#pragma HLS unroll factor=2
a[i] = b[i] + c[i];
}
\\等效于
for (int i = 0; i < 4; i=i+2)
{
a[i] = b[i] + c[i];
}
for (int i = 1; i < 4; i=i+2)
{
a[i] = b[i] + c[i];
}
- 这个优化要求循环边界为常数,才可以确定unroll factor设置为多少。
- 对于循环次数较大的,展开后可能资源不足,导致unroll 失败;此时需要根据芯片实际资源数量,以及报错信息对factor进行调整。
1.2 循环展平(Flatten)
- 相当于将内层循环合并到外层循环上,节省从内层循环过渡到外层循环时条件判断的延迟。
for (int i = 0; i < M; i++)
for (int j = 0; j < N; j++)
{
#pragma HLS loop_flatten
// Loop body
}
}
//等效于
for (int i = 0; i < M*N; i++)
// Loop body
- Flatten要求循环是完美循环/半完美循环。
- 完美循环:循环的边界是常数,且循环体只出现在最内层循环。
- 半完美循环:外循环的边界可以是变量,但内循环边界必须是常数;且循环体只能出现在最内层循环。
2. 多个循环的并行优化
2.1 循环合并
- 即使多个循环之间完全独立,在RTL中默认是顺序执行,共要消耗A+B个周期。但是若将两种循环合并,那么只需要消耗max(A,B)个周期。
void func (...) {
#pragma HLS loop_merge
L1: for (int i = 0; i < 8; i++) {
// Loop body of L1
L2: for (int i = 0; i < 4; i++)
L3: for (int j = 0; j < 5; j++)
// Loop body of L3
L4: for (int i = 0; i < 13; i++)
// Loop body of L4
}
//等效于
void func (...) {
MERGED: for (int i = 0; i < 20; i++) {
if (/* condition1 */)
// Loop body of L1
// Flattened loop body of L3
if (/* condition4 */)
// Loop body of L4
}
}
- 合并时应注意
- 如果合并前,所有循环边界为常数,那么合并后的循环边界应该为常数间最大值。
- 如果合并前,所有循环边界为变量,则循环边界必须相同。
- 如果合并前,部分循环边界为变量,部分为常数,那么不能合并。
2.2 循环函数化
- 如果两个循环的边界不同,则不能合并。但是可以将循环封装成子函数,实现并行。
- 注意需要使用#pragma HLS inline off来防止内联。
- HLS inline:去除子函数层次结构,使用内联操作使自身逻辑融入调用函数中。内联后的函数不能共享或重用。
2.3 数据流 Dataflow
- 对于2个循环存在数据依赖关系时,不管循环合并或是循环函数化,都没有办法实现循环之间的并行;但是可以通过数据流实现。
- 举例如下
- 如果是非数据流执行方式,那么LOOP_2需要等待LOOP_1执行完成之后才能执行。
void func (int A[N], int C[N], int num) {
#pragma HLS dataflow
int acc = 0;
int B[N];
LOOP_1: for (int i = 0; i < N; i++) {
#pragma HLS PIPELINE II=1
acc += A[i];
B[i] = acc;
}
LOOP_2: for (int i = 0; i < N; i++)
#pragma HLS PIPELINE II=1
C[i] = B[i] * num;
}
- Dataflow一般会在循环之间插入缓存,如果循环之间依靠变量传递数据,那么HLS会插入FIFO缓存;如果循环间依靠数组传数据,那么HLS会插入Ping-Pong RAM。
- 由于存在循环到循环之间的缓存通路,所以只要LOOP_1中的数据输出就可以用于LOOP_2中的运算。多个任务间可以有交叠,降低延迟,提高数据吞吐率。
- 注意
- 循环之间数据只能顺序流动,不能有反馈回路。、
- 数据流只能从一个循环流出到另一个循环,single-producer,single-consumer.
- 循环不能在条件语句内。
3. 吞吐量优化:循环 - pipeline
#pragma HLS pipeline II=<int>
- 对于下面左图中,RD距离下次RD间隔3个周期,即II=3;而右图II=1.若不指定,则默认为1.
- 很明显,II = 1时,性能最好。但是代码中可能会因为数据依赖关系/存储器读写出现的冒险情况(具体可看流水线相关知识),而导致不满足设定的II;此时需要进行相应的优化,如消除依赖关系,数组划分等;后面有介绍。
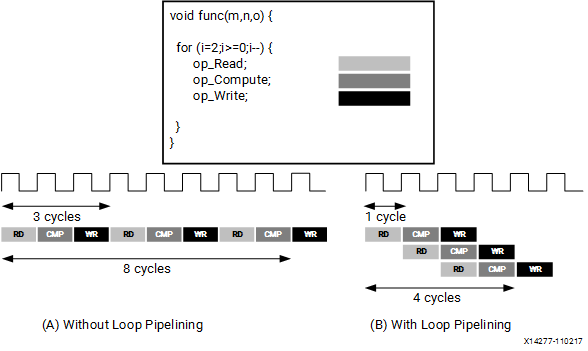
- 如果#pragma HLS pipeline 语句作用于嵌套循环的外层循环,那么需要将pragma下面所有的内层循环完全unroll。此时,如果循环边界为变量或展开后资源不够,那么展开会失败。
- 若作用于函数,那么函数内所有循环都会被展开,同样存在导致展开失败的情况。
4. 吞吐量优化:循环 - DataFlow
- "3"中介绍的是细粒度的流水线架构,而数据流可以实现粗粒度的流水线,具体实现与"2.3"相同。