现在attention的热度已经过去了,基本上所有的attention都是transformer的kqv形式的,甚至只要说道attention,默认就是transformer的attention。
为避免遗忘历史,我这里做一个小总结。繁杂的att我就不去了解了,只了解下经典的。
以下以\(h_i\)代表想要att聚合的各个向量,以\(s_0\)表示当前向量。
鼻祖Bahdanau Attention
2015,Bengio组。文章https://arxiv.org/pdf/1409.0473.pdf。
att的获得
\(\alpha_i=func(h_i,s_0)\).
\(alpha\)是att权重(加权平均的weight系数)。
att的使用
即加权平均:
\[h_{before}
\]
\[h_{after}=\sum_{i\in N} \alpha_i*h_i
\]
其中\(N\)为\(h\)的(包括自己的)邻域(邻居)。
func的形式
也就是att系数的获得方式。
形式1
\(\alpha\)的计算方式:
\(\alpha=V*tanh(W*(h_i||s_0))\),其中\(V\)、\(W\)都是可学习参数.
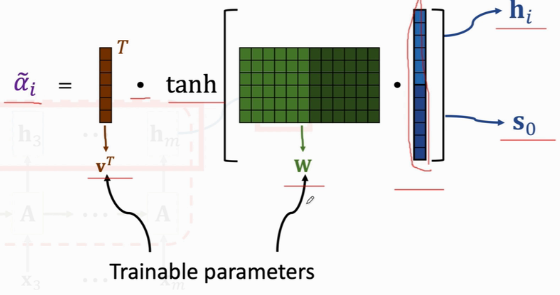
然后对各个\(\alpha\) softamx即可。
形式2
\(k=W_K*h_i\)
\(q=W_Q*s_0\)
\(\alpha=k^Tq\)
然后softmax。
其中\(W_K\), \(W_Q\)是学习参数。
注:此Transformer模式本质上与此方式一致。
不同的是,Transformer直接把\(h_i\)和\(s_0\)直接变成了一个训练参数\(V\),组成了\(K,Q,V\)三者。