作业①:
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 -
文件夹链接:https://gitee.com/z241842/data-collection-experiment/tree/main/ImgSpider
代码
items.py
class ImgSpiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
# title_ = scrapy.Field()
image_url = scrapy.Field()
pass
pipelines.py
class ImgSpiderPipeline:
count = 0
images_store = "C:\\Users\\zmk\\PycharmProjects\\pythonProject\\ImgSpider"
threads = []
def open_spider(self, spider):
picture_path = self.images_store + '\\images'
if os.path.exists(picture_path): # 判断文件夹是否存在
for root, dirs, files in os.walk(picture_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除文件夹
os.rmdir(picture_path) # 删除文件夹
os.mkdir(picture_path) # 创建文件夹
# 单线程
# def process_item(self, item, spider):
# url = item['img_url']
# print(url)
# img_data = urllib.request.urlopen(url=url).read()
# img_path = self.desktopDir + '\\images\\' + str(self.count)+'.jpg'
# with open(img_path, 'wb') as fp:
# fp.write(img_data)
# self.count = self.count + 1
# return item
# 多线程
def process_item(self, item, spider):
url = item['img_url']
print(url)
T = threading.Thread(target=self.download_img, args=(url,))
T.setDaemon(False)
T.start()
self.threads.append(T)
return item
def download_img(self, url):
img_data = urllib.request.urlopen(url=url).read()
img_path = self.images_store + '\\images\\' + str(self.count) + '.jpg'
with open(img_path, 'wb') as fp:
fp.write(img_data)
self.count = self.count + 1
def close_spider(self, spider):
for t in self.threads:
t.join()
spider.py
class work1_Item(scrapy.Item):
img_url = scrapy.Field()
class imgSpider(scrapy.Spider):
name = 'imgSpider'
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
img_datas = selector.xpath('//a/img/@src')
for img_data in img_datas:
item = work1_Item()
item['img_url'] = img_data.extract()
yield item
运行结果

作业②:
-
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/ -
输出信息:
MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStock -
文件夹链接:https://gitee.com/z241842/data-collection-experiment/tree/main/StockSpider
代码
items.py
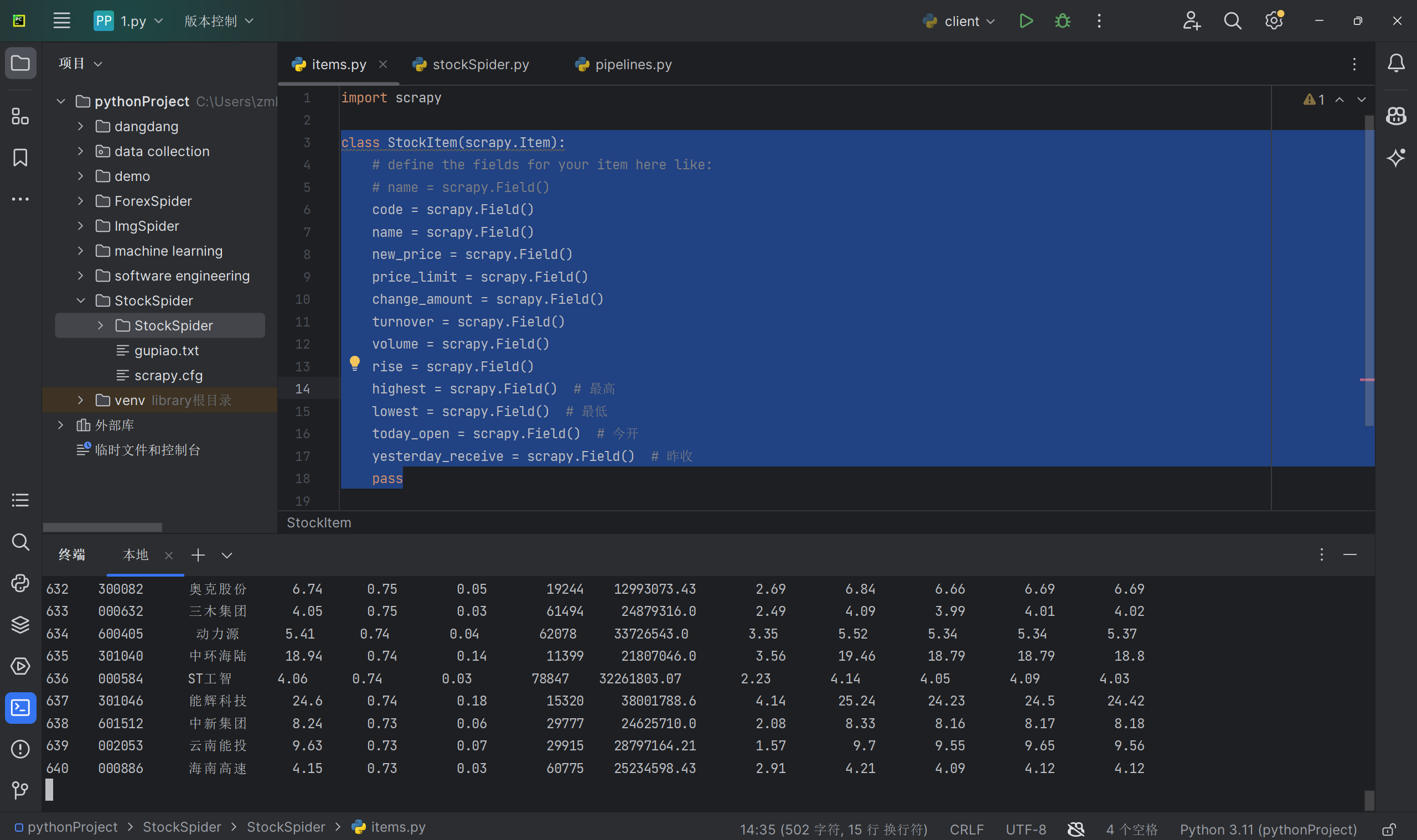
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
price_limit = scrapy.Field()
change_amount = scrapy.Field()
turnover = scrapy.Field()
volume = scrapy.Field()
rise = scrapy.Field()
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
today_open = scrapy.Field() # 今开
yesterday_receive = scrapy.Field() # 昨收
pass
pipelines.py
class StockSpiderPipeline:
count = 0
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "", db = "stock", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条股票信息")
def process_item(self, item, spider):
try:
self.count = self.count + 1
print("{:^2}{:>10}{:>10}{:>10}{:>10}{:>12}{:>13}{:>15}{:>12}{:>12}{:>12}{:>12}{:>12}".format(self.count, item['code'], item['name'],
item['new_price'], item['price_limit'],
item['change_amount'],
item['turnover'],
item['volume'], item['rise'],item['highest'],item['lowest'],item['today_open'],item['yesterday_receive']))
if self.opened:
self.cursor.execute("insert into stocks (id,bStockNo,bName,bNewPrice,bPriceLimit,bChangeAmount,bTurnover,bVolume,bRise,bHighest,bLowest,bTodayOpen,bYesterdayReceive)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(self.count, item['code'], item['name'],item['new_price'], item['price_limit'],item['change_amount'],item['turnover'],item['volume'], item['rise'],item['highest'],item['lowest'],item['today_open'],item['yesterday_receive']))
except Exception as err:
print(err)
return item
spider.py
class stockSpider(scrapy.Spider):
name = 'stockSpider'
page = 1
start_urls = [
'http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240821834413285744_1602921989373&pn=' + str
(page) + '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,'
'm:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,'
'f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602921989374']
def parse(self, response):
try:
data = response.body.decode('utf-8')
data = data[41:-2] # 将获取到的json文件字符串去掉前面的jQuery.....一大串东西,截取为标准的json格式,传入处理
responseJson = json.loads(data)
stocks = responseJson.get('data').get('diff')
for stock in stocks:
item = StockItem()
item['code'] = stock.get('f12')
item['name'] = stock.get('f14')
item['new_price'] = stock.get('f2')
item['price_limit'] = stock.get('f3')
item['change_amount'] = stock.get('f4')
item['turnover'] = stock.get('f5')
item['volume'] = stock.get('f6')
item['rise'] = stock.get('f7')
item['highest'] = stock.get('f15')
item['lowest'] = stock.get('f16')
item['today_open'] = stock.get('f17')
item['yesterday_receive'] = stock.get('f18')
yield item
url = response.url.replace("pn=" + str(self.page), "pn=" + str(self.page + 1)) # 实现翻页
self.page = self.page + 1
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
运行结果
作业③:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/ -
文件夹链接:https://gitee.com/z241842/data-collection-experiment/tree/main/ForexSpider
代码
items.py
class forexItem(scrapy.Item):
name = scrapy.Field()
price1 = scrapy.Field()
price2 = scrapy.Field()
price3 = scrapy.Field()
price4 = scrapy.Field()
price5 = scrapy.Field()
date = scrapy.Field()
pipelines.py
class ForexSpiderPipeline:
count = 0
class ForexSpiderPipeline:
def open_spider(self, spider):
print('%-10s%-10s%-10s%-10s%-10s%-10s%-10s' % (
'货币名称', '现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价', '中行折算价', '发布日期'))
def process_item(self, item, spider):
print('%-10s%-10s%-10s%-10s%-10s%-10s%-10s' % (
item['name'], item['price1'], item['price2'], item['price3'], item['price4'], item['price5'], item['date']))
return item
spider.py
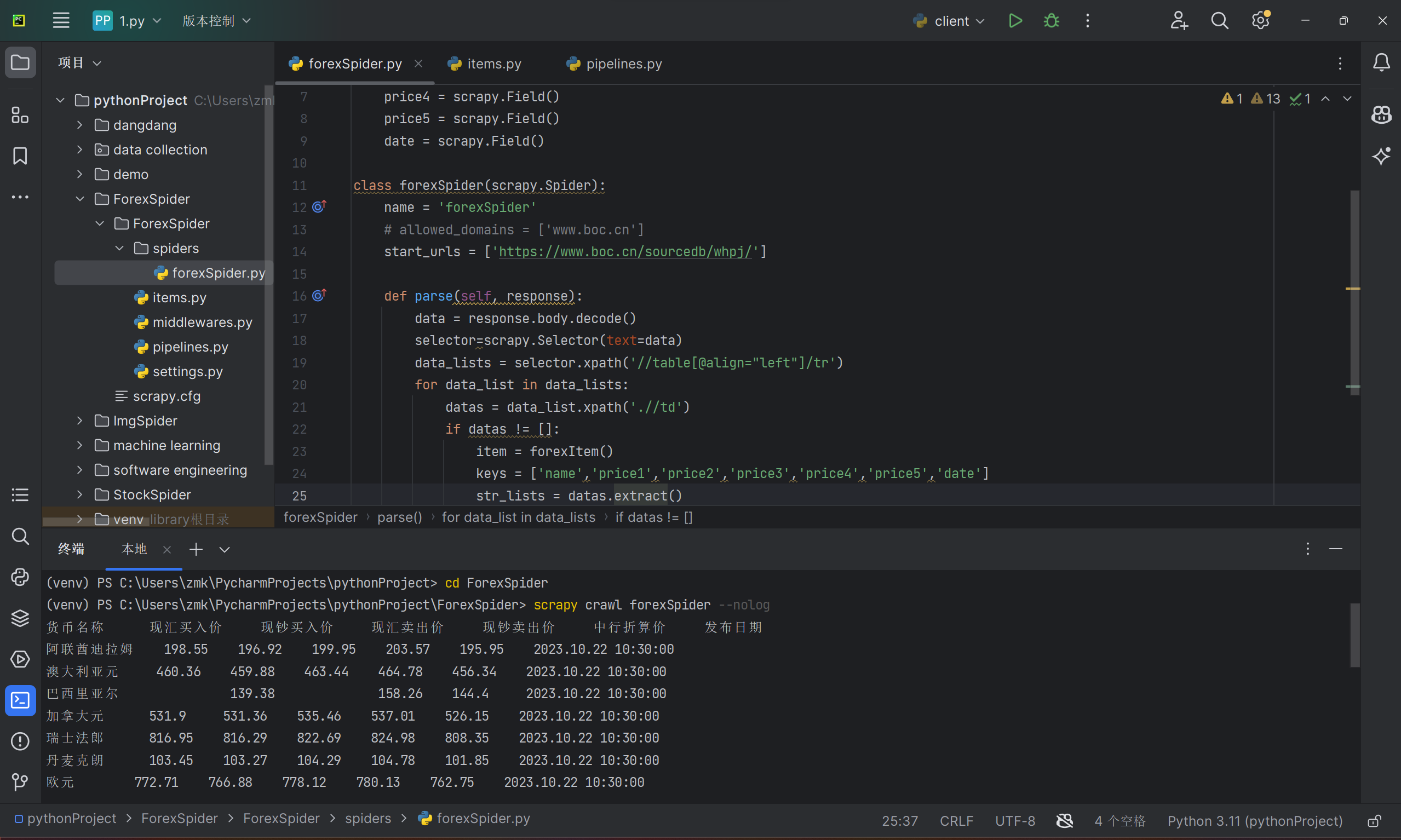
class forexSpider(scrapy.Spider):
name = 'forexSpider'
# allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
data_lists = selector.xpath('//table[@align="left"]/tr')
for data_list in data_lists:
datas = data_list.xpath('.//td')
if datas != []:
item = forexItem()
keys = ['name','price1','price2','price3','price4','price5','date']
str_lists = datas.extract()
for i in range(len(str_lists)-1):
item[keys[i]] = str_lists[i].strip('<td class="pjrq"></td>').strip()
yield item
运行结果