1.凝聚聚类 Agglomerative Clustering
在不同层次上对数据集进行划分,形成树状的聚类结构。AggregativeClustering是一种常用的层次聚类算法。
最初将每个样本点看成一个簇,然后将这些簇根据某种规则被一步步合并,就这样不断合并直到达到预设的簇类个数。
1 Ward:俩个簇的样本放到一起计算方差,合并方差最小的 (方差最小 相似度越高)
2 Maximum or complete linkage:合并d max 最小的
3 Average linkage:合并d avg 最小的
4 Single linkage:合并d min 最小的

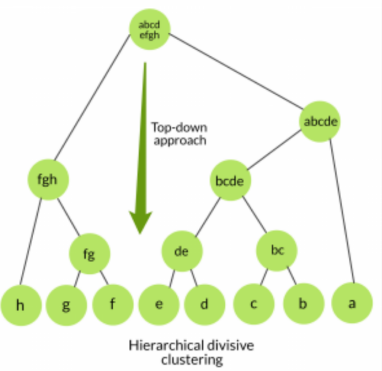
2. 分裂聚类
自上而下的方法,二分KMeans本质上是层次聚类中的分裂聚类,它通过不断分裂直到达到预设的簇类个数。
3. BIRCH
Balanced Iterative Reducing and Clustering using Hierarchies
利用了一个树结构来帮助我们快速的聚类,一般将它称之为聚类特征树(Clustering Feature Tree,简称CF Tree)
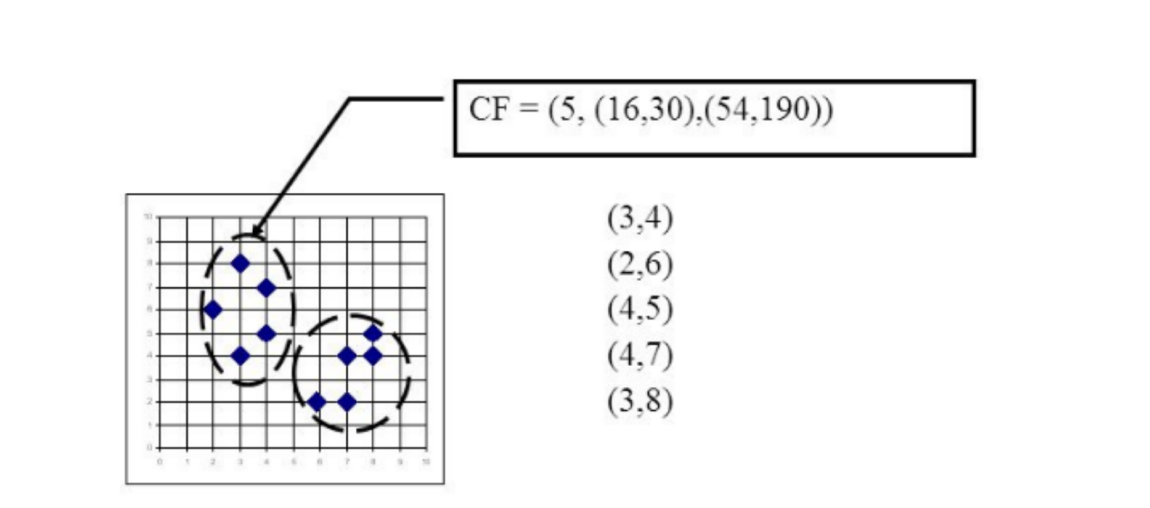
一个聚类特征项被定义为一个有序的三元组,(N, LS, SS) 这里 ‘N’ 是簇中数据点数量,‘LS’ 是簇中数据点的线性加和,‘SS’ 是簇中数据点的平方和。对于一个聚类特征项是有可能由其它多个聚类
特征项组成的。
CF有一个很好的性质,就是满足线性关系:
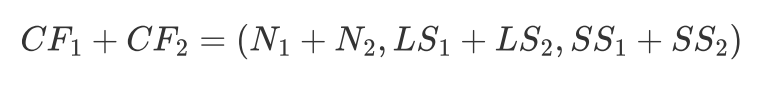
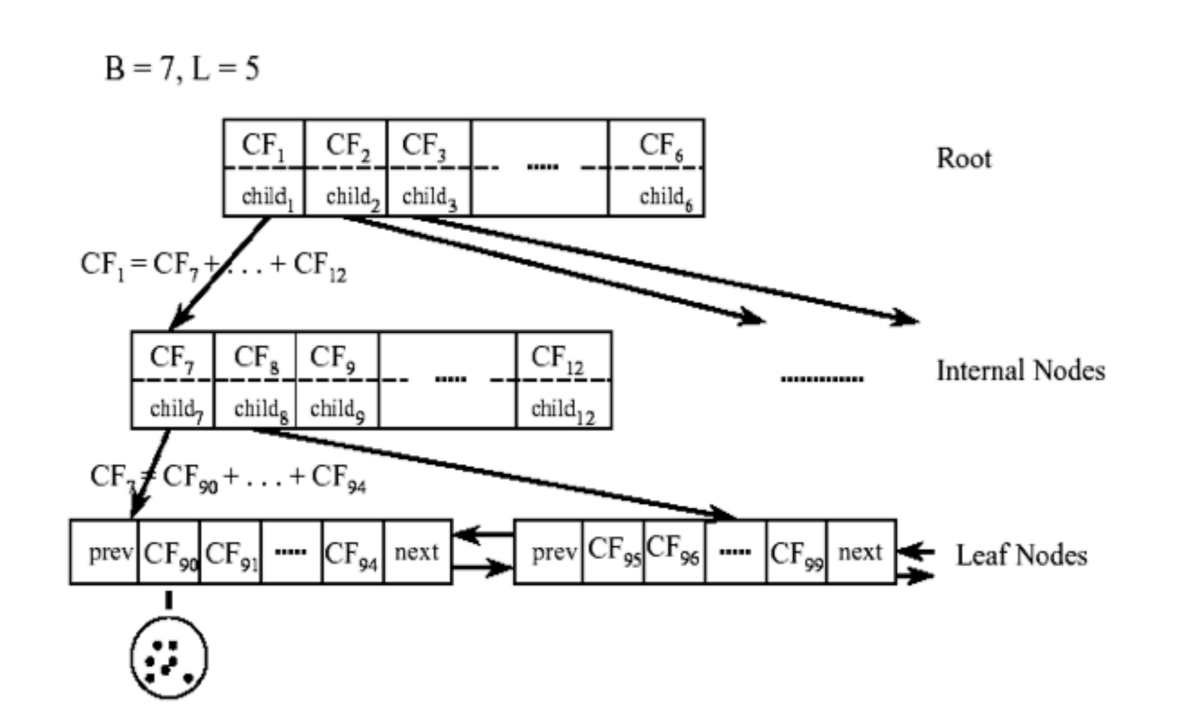
CF Tree的重要参数:
第一个参数是:每个内部节点的最大CF数B,branch
第二个参数是:每个叶子节点的最大CF数L,leaf
第三个参数是: 空间阈值 τ,表示叶节点每个CF的最大样本半径或直径,所有类簇的半径不得大于 τ,决定分类的粒度,更细小的类没必要再分
注释:不能再继续往下分的节点--叶子节点-没有child的节点
这个Tree是如何生成的:
在最开始的时候,CF Tree是空的,没有任何样本,我们从训练集读入第一个样本点,将它放入一个新的CF三元组A,这个三元组的N=1,将这个新的CF放入根节点,此时的CF Tree如下图:
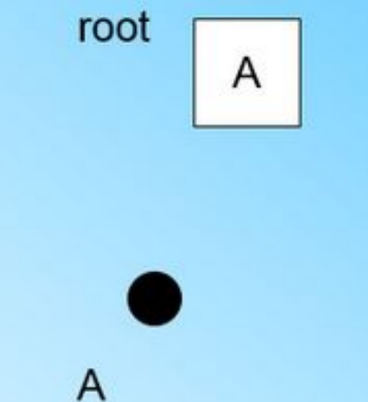
继续读入第二个样本点,我们发现这个样本点和第一个样本点A,在半径为T的超球体范围内,也就是说,他们属于一个CF,我们将第二个点也加入CF A,此时需要更新A的三元组的值。此时A的三元组中N=2:
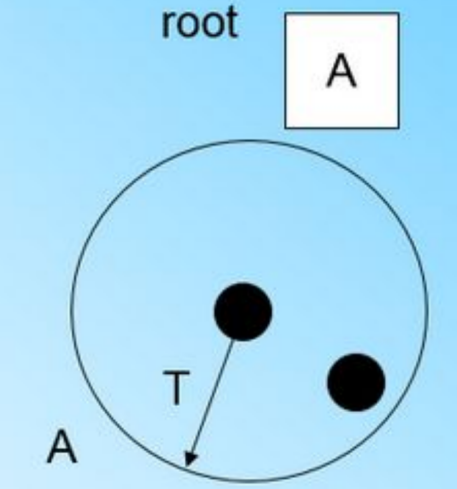
第三个样本,结果我们发现这个样本不能融入刚才前面的节点形成的超球体内,也就是说,我们需要一个新的CF三元组B,来容纳这个新的值。此时根节点有两个CF三元组A和B,此时的CFTree如下图:
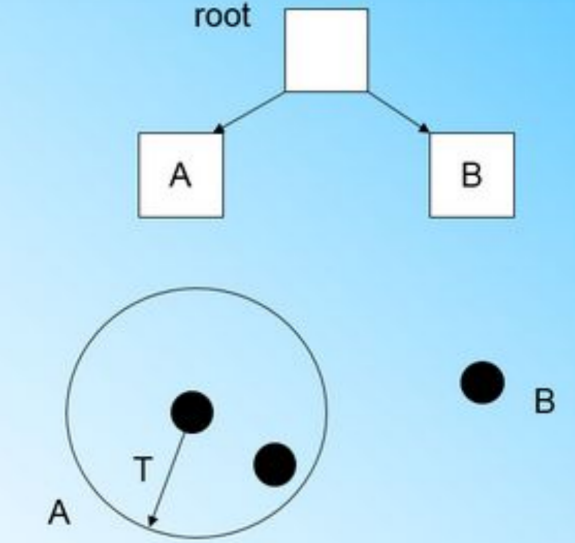
来到第四个样本点的时候,我们发现和B在半径小于T的超球体,这样更新后的CF Tree如下图:
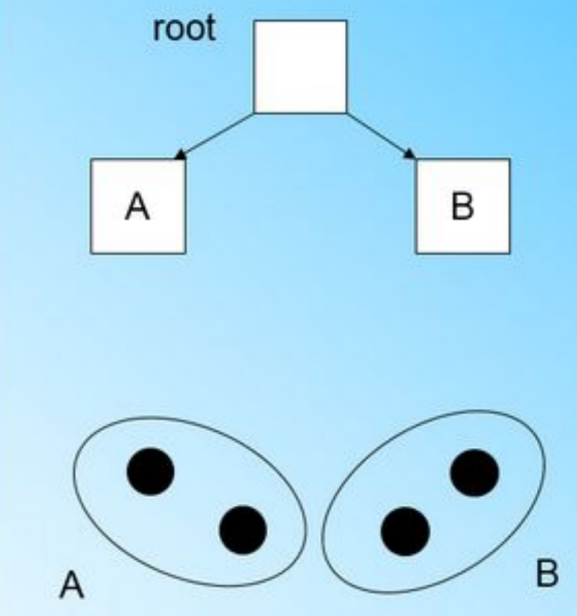
一个新的
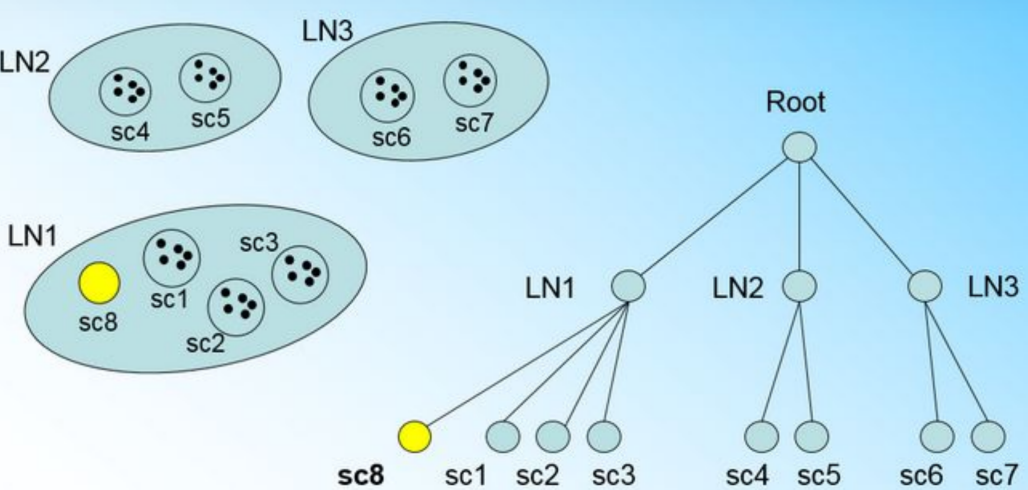
样本点来了,我们发现它离LN1节点最近,因此开始判断它是否在sc1,sc2,sc3这3个CF对应的超球体之内,但是很不幸,它不在,
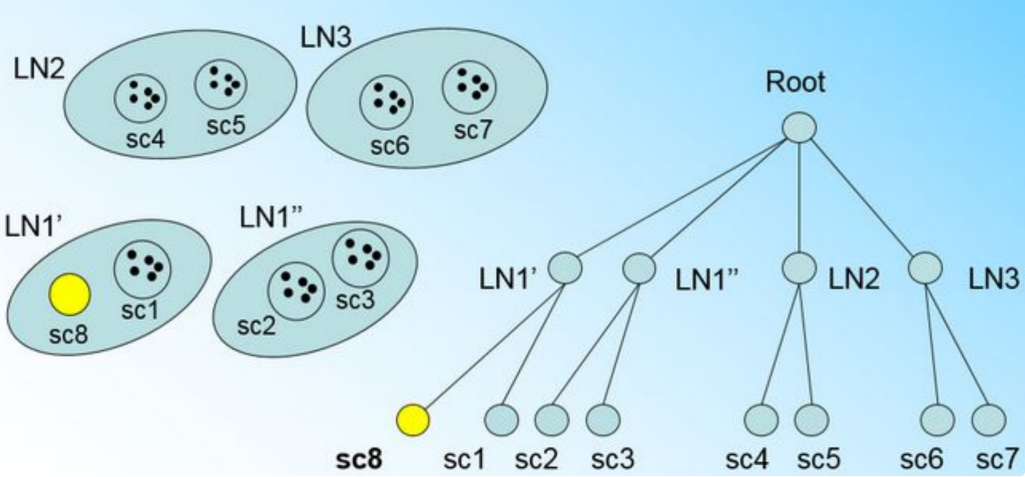
因此它需要建立一个新的CF,即sc8来容纳它。问题是我们的L=3,也就是说LN1的CF个数已经达到最大值了,不能再创建新的CF了,怎么办?此时就要将LN1叶子节点一分为二了。
转换成:
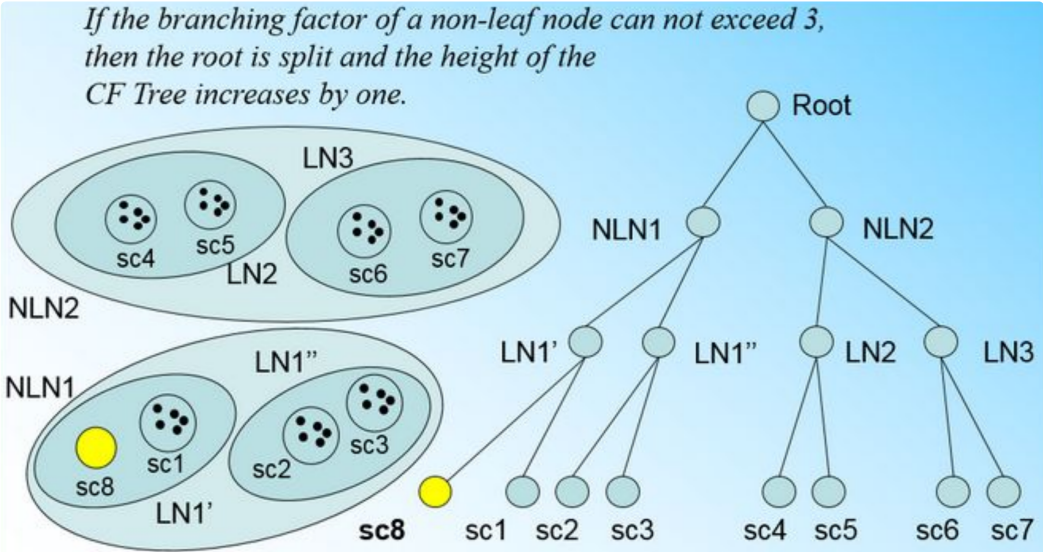
如果我们的内部节点的最大CF数B=3,则此时叶子节点一分为二会导致根节点的最大CF数超了,也就是说,我们的根节点现在也要分裂,分裂的方法和叶子节点分裂一样,分裂后的CF Tree如下图:
将所有的训练集样本建立了CF Tree,一个基本的BIRCH算法就完成了
有了 CF 这三个统计量,我们可以知道哪些簇的信息呢?
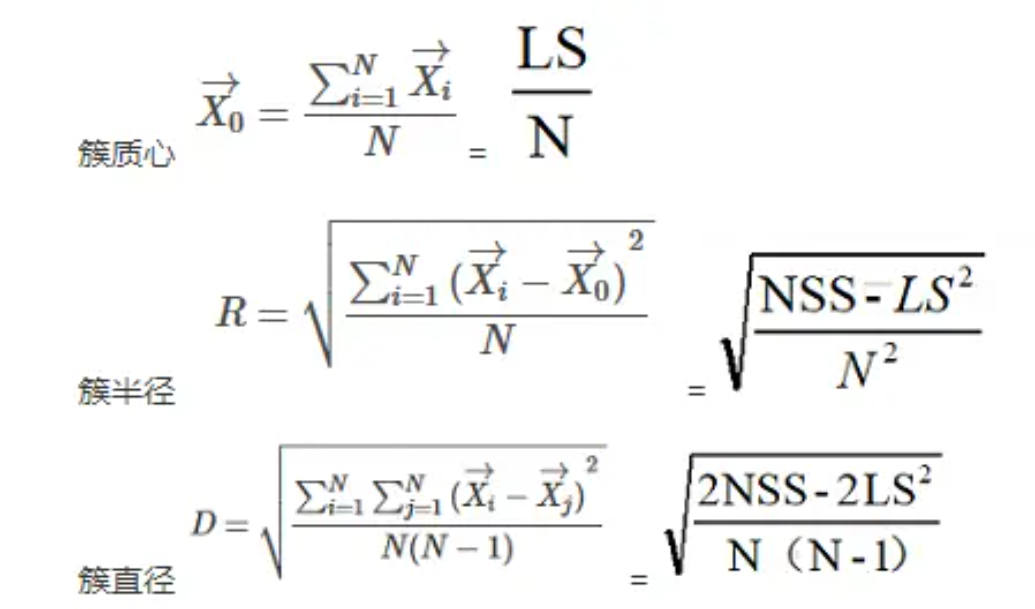
利用 CF 的三个统计量,我们还可以度量不同簇间的距离。例如:中心点欧基里得距离(centroid Euclidian distance)
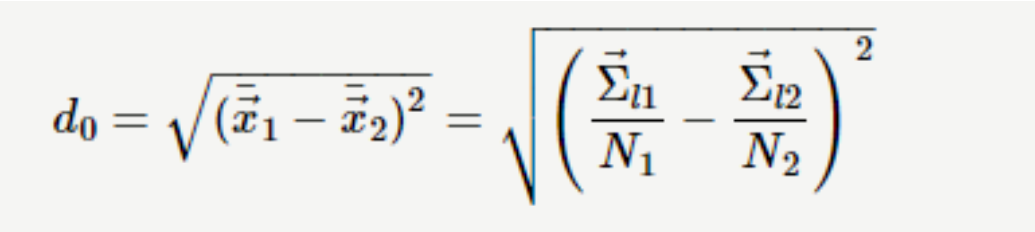
算法步骤:
1.将所有的样本依次读入,在内存中建立一颗CF Tree。
(可选)将第一步建立的CF Tree进行筛选,去除一些异常CF节点,这些节点一般里面的样本点很
少。对于一些超球体距离非常近的元组进行合并。
(可选)利用其它的一些聚类算法比如K-Means对所有的CF元组进行聚类,得到一颗比较好的CF
Tree.这一步的主要目的是消除由于样本读入顺序导致的不合理的树结构,以及一些由于节点CF个
数限制导致的树结构分裂。
(可选)利用第三步生成的CF Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距
离远近进行聚类。这样进一步减少了由于CF Tree的一些限制导致的聚类不合理的情况。