前言
虽然我也很想讲X86_64体系,无奈这样的资料的确不多,因此本文还是本着学习的态度,探究早已经过时的X86体系。
本文转载自此文,该博主对栈的数据结构、栈的作用等进行了阐述,其中涉及了函数栈帧的相关知识,这部分内容我没有转载,我仅仅转载了我感兴趣的进程栈,线程栈等部分,并在其中融入了自己的理解和补充。
原文作者将Linux的栈划分为:
进程栈
线程栈
内核栈
中断栈
显然是缺少了信号栈,有关信号栈,在我翻译的信号相关的linux手册中,曾经多次的提及: linux手册翻译——signal(7) linux手册翻译——sigaction(2) linux手册翻译——sigreturn(2) linux手册翻译——sigaltstack(2)
从实现上说,信号栈其实类似于线程栈,都是可以用用户自己的指定的。
稍微总结一下: 在X86体系中,虚拟内存空间大小为4GB,可以说是非常小了,Linux将其分为了两部分,即高1G字节的内核空间和低3G字节的用户空间,其中内核空间是由所有的进程共享的,在实现上就是所有进程的内核空间的页表是共享使用的。
用户空间,或者说进程的地址空间有自己的标准布局,由各个内存段组成,每个内存段就是一个VMA结构,本质上全部都是用过mmap是实现的,布局如图:
包括了:
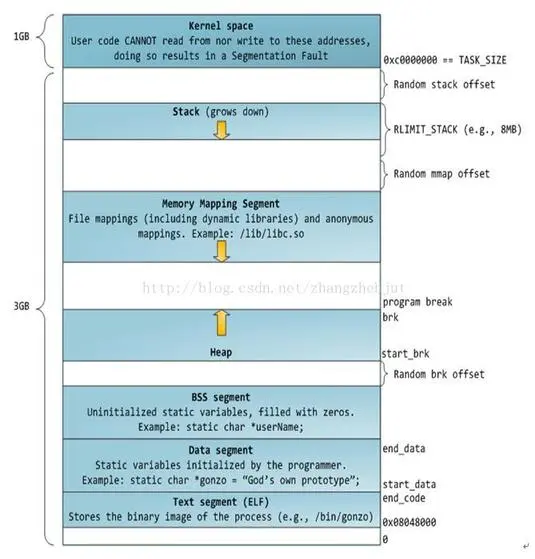
程序段 (Text Segment):可执行文件代码的内存映射
数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
堆区 (Heap) : 存储动态内存分配,匿名的内存映射
栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
映射段(Memory Mapping Segment):任何内存映射文件
一、进程栈
进程栈,就是进程地址空间当中的栈区!
进程栈的初始化大小是由编译器和链接器计算出来的,Linux内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。进程栈是有最大值的,此值由rlimit的值进行限制,可通过shell命令ulimit -s查看,默认是8Mb。关于rlimit,可以查看其linux手册!
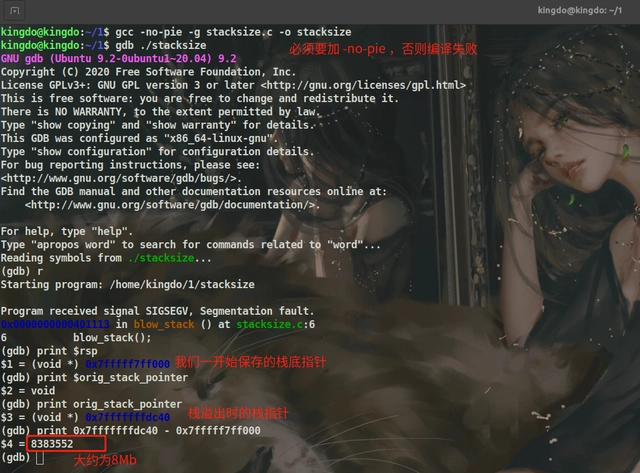
以上结论在X86_64上依然是适用的,如下测试程序:
/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movq %rsp, orig_stack_pointer");
blow_stack();
return 0;
}
编译运行结果如下:
【扩展阅读】:进程栈的动态增长实现 进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
如今的内核是如何处理的需要阅读源码,但是原理应该大差不多
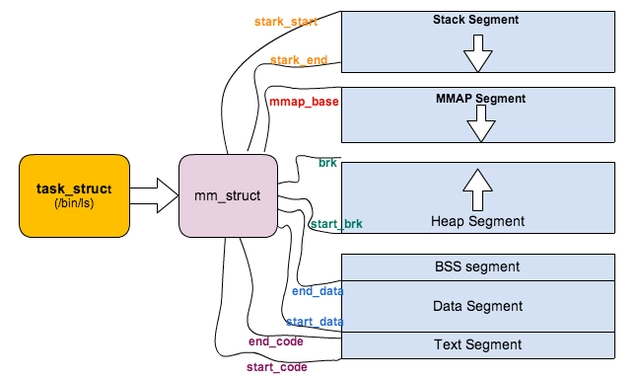
上面对进程的地址空间有个比较全局的介绍,那我们看下 Linux 内核中是怎么体现上面内存布局的。内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的 进程内存段布局 图一起看:
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA 形成的红黑树 */
...
struct list_head mmlist; /* 所有 mm_struct 形成的链表 */
...
unsigned long total_vm; /* 全部页面数目 */
unsigned long locked_vm; /* 上锁的页面数据 */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* 共享页面数目 Shared pages (files) */
unsigned long exec_vm; /* 可执行页面数目 VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* 栈区页面数目 VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数 和 环境变量的 起始地址和结束地址 */
...
/* Architecture-specific MM context */
mm_context_t context; /* 体系结构特殊数据 */
/* Must use atomic bitops to access the bits */
unsigned long flags; /* 状态标志位 */
...
/* Coredumping and NUMA and HugePage 相关结构体 */
};
二、线程栈
Linux可以说很好的贯彻了,线程是任务的调度单位,进程是资源分配单位的理念,在实现上,其实是只有task的概念,并对应了task_struct结构,而进程其实是一个task组,也就是他是一组task的集合,所有的task共享内存资源,即mm_struct,其中task组的第一个task,我们称之为task组的leader,即主线程!
因此在linux中线程对应单个task,每个线程拥有一个task_struct,进程就是一组task,每个进程拥有一个mm_struct,进程中的线程共享mm_struct结构!
我们在创建线程时,会调用clone系统调用,clone系统调用也是fork的底层实现,如果要创建线程,那就需要带上CLONE_VM标志,此时,新创建的task,将会直接共享父亲的mm_struct:
if (clone_flags & CLONE_VM) {
/*
- current 是父进程而 tsk 在 fork() 执行期间是共享子进程
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm = current->mm;
}
从上面的描述可以看出,诸多线程之间是共享栈区的,但是显然他们不可能一起使用栈区,否则就混乱了!因此进程栈其实是线程组leader的栈空间。
因此线程栈是需要我们在创建线程时指定的!翻阅pthread_create()的源码,其调用了: allocate_stack (iattr, &pd, &stackaddr, &stacksize); 函数来申请栈空间,而allocate_stack最终又调用了: mem = __mmap (NULL, size, (guardsize == 0) ? prot : PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0); 因此线程栈,其实是通过mmap在文件映射区申请的匿名页。
此外需要注意的是,线程的栈是不能动态增长的,指定了多大,用完就完了!当然了,默认情况下是和主线程保持一致,都是8Mb
三、内核栈
在一个线程的执行周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先用户空间中的栈,而是一个单独内核空间的栈,这个称作内核栈。每当我们创建新的线程的时候都会一同创建线程的内核栈,实现上是通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
众所周知,我们每个线程除拥有一个task_struct结构之外,还有一个用于找到task_struct的thread_info结构,而thread_info被写入在了线程内核栈的最低地址处,其使用了thread_union的联合体结构来实现:
union thread_union {
struct thread_info ;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
具体关系如图:
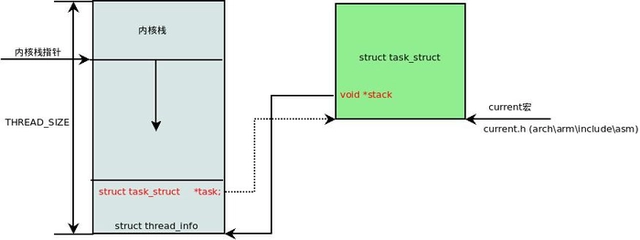
这里有一个小技巧,直接将 esp 的地址与上 ~(THREAD_SIZE - 1) 后即可直接获得 thread_info 的地址。由于 thread_union 结构体是从 thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE 对齐的。因此只需要对栈指针进行 THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_union 的地址。成功获取到 thread_info 后,直接取出它的 task 成员就成功得到了 task_struct。其实上面这段描述,也就是 current 宏的实现方法:
register unsigned long current_stack_pointer asm ("sp");
static inline struct *current_thread_info(void)
{
return (struct *)
( & ~( - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()
根据栈溢出的检测中指出这种方式存在一定的问题:
如果栈的内存使用达到了thread_info的区域,虽然此时"栈溢出"还没有发生,但thread_info的数据结构会受到破坏,可能造成这个线程之后无法正常运行。
从Linux 4.1开始,thread_info就在逐渐被简化,直到4.9版本彻底不再通过thread_info获取task_struct指针,而thread_info本身也被移入了task_struct结构体中,所以这个问题也就不复存在了。
四、中断栈
进程陷入内核态的时候,需要内核栈来支持内核函数调用。中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。
X86 上中断栈就是独立于内核栈的;独立的中断栈所在内存空间的分配发生在 arch/x86/kernel/irq_32.c 的 irq_ctx_init() 函数中(如果是多处理器系统,那么每个处理器都会有一个独立的中断栈),函数使用 __alloc_pages 在低端内存区分配 2个物理页面,也就是8KB大小的空间。有趣的是,这个函数还会为 softirq 分配一个同样大小的独立堆栈。如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。
而 ARM 上中断栈和内核栈则是共享的;中断栈和内核栈共享有一个负面因素,如果中断发生嵌套,可能会造成栈溢出,从而可能会破坏到内核栈的一些重要数据,所以栈空间有时候难免会捉襟见肘。

转载:https://baijiahao.baidu.com/s?id=1712620414089250801&wfr=spider&for=pc