第十章
4.Bash shell操作环境
终端环境设置:stty set
登录终端时,自动获取的一些终端的输入环境的设置。
stty [-a]
set [-uvCHhmBx]
echo $- 可以显示目前所有的set设置值

通配符与特殊符号
符号 意义
* 代表0到无穷多任意字符
? 代表一定有一个任意字符
[] 同样代表一定有一个再括号内的字符(非任意字符)。例如[abcd]代表一定有一个字符,可能是a、b、c、d中的一个
[-] 若有减号在中括号内时,代表在编码顺序内的所有字符。例如[0-9]代表0到9之间的所有数字,因为数字的语系编码是连续的
[^] 表示[反向选择],例如[^abc]代表一定有一个字符不是a、b、c的其他字符就接受的意思
特殊符号
符号 内容
# 注释符号
|将[特殊字符或通配符]还原成一般字符
竖号 管道(pipe):分隔两个管道命令的符号
; 连续命令执行分隔符:连续性命令的界定
$ 使用变量前导符:亦即是变量之前需要加的变量替换符
& 任务管理job control:将命令变成后台任务
! 逻辑运算意义上的的[非]not的意思
>、>> 数据流重定向:输出定向,分别是[替换]与[累加]
<、<< 数据流重定向:输入定向
‘’ 单引号,不具有变量替换的功能($ 变为)
“” 具有变量替换的功能,($ 可保留相关功能)
`` 两个[`]中间为可以先执行的命令,亦可使用$()
() 在中间为子shell的起始与结束
{} 在中间为命令区块的组合
数据流重导向
标准输入stdin:代码为0,使用< 或 <<;
标准输出stdout:代码为1,使用 > 或 >>;
标准错误输出stderr:代码为2,使用 2> 或 2>>
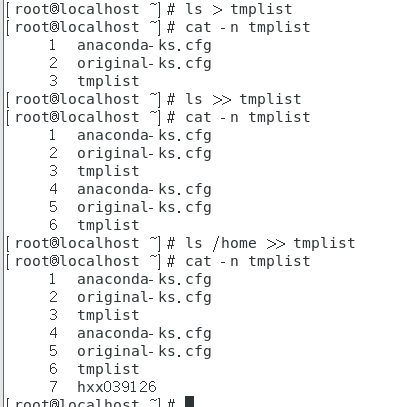
重定向操作会新建或覆盖原有文件。
如果想将数据累加而不想要将旧的数据删除,利用两个大于的符号(>>)就好。
将stdout与stderr分别存到不同的文档中
find /home -name .bashrc >list_right 2>list_error

双向重导向tee
tee:将数据流同时输出到屏幕和文件
5.管道命令pipe
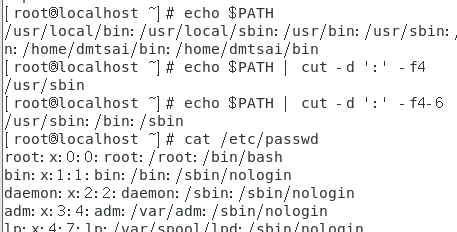
cut -d’分隔字符’ -f fields 用于有特定分隔字符
cut -d字符区间 用于排列整齐的信息
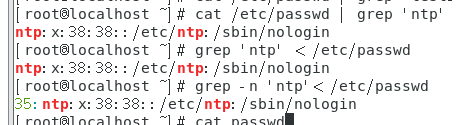
grep则是分析一行信息,不是处理,若当中有我们所需要的信息,就将该行拿出来。
grep [-acinv] [–color=auto] ‘查找字符’ filename
排序命令:sort,wc,uniq
sort可以根据不同的数据形式在排序,排序的字符与语系的编码有关,因此,如果需要排序时,建议使用LANG=C来让语系统一
uniq可以将列出的数据中重复的数据仅列出一个显示
wc可以知道文件里面有多少字,多少行,多少字符
cat /etc/man_db.conf | wc
字符转换命令tr,col,join,paste.expand
tr可以用来删除一段信息当中的文件,或是进行文字信息的替换。
tr [-ds]
-d:删除信息当中的SET1字符
-s:替换掉重复的字符
join是再两个文件当中,有相同数据的那一行,才将它加在一起
paste直接将两行贴在一起,且中间以[Tab]键隔开
-d:后面可以接分隔字符,默认使用Tab
-:如果file部分写成-,表示来自标准输入的数据的意思。
expand将Tab按键转成空格键
unexpand将空格转成Tab命令。
划分命令:split可以将一个大文件,依据文件大小或行数来划分
-b:后面可接欲划分成的文件大小,可加单位,例如b、K、M等
-l:以行数来进行划分
参数代换:xargs就是在产生某个命令的参数的意思
xargs可以读入stdin的数据,并且以空格符或换行符作为识别符,将stdin的数据分隔成参数
第十一章 正则表达式与文件格式化处理 \\掌握可提高对文本文件的处理效率和灵活性
1.基础正则表达式
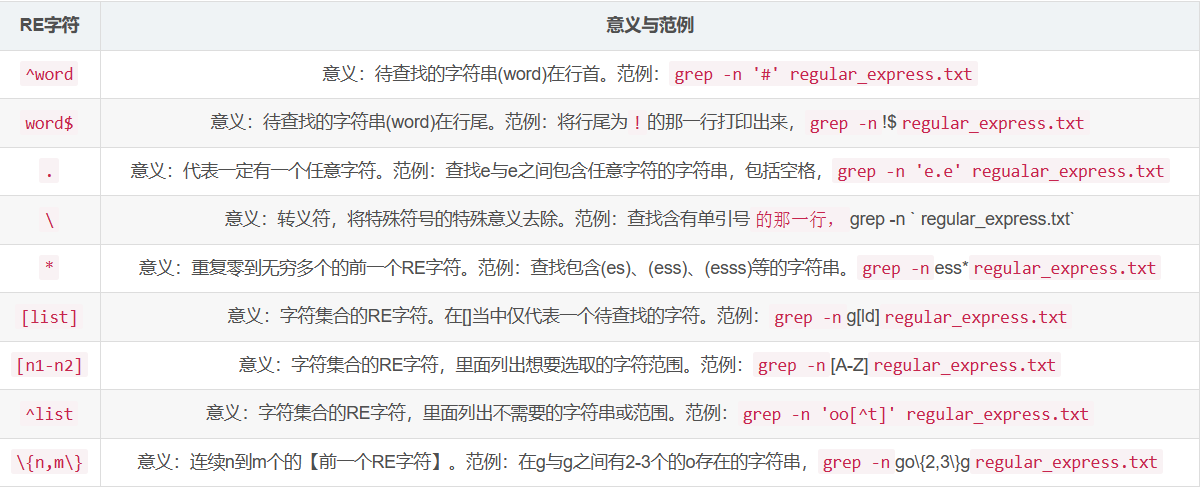
grep [-A] [-B] [--color=auto] '查找字符' filename
[]查找集合字符
行首与行尾字符^$
任意一个字符.与重复字符*
限定连续RE字符范围 {}
由于{与}的符号在shell中有特殊意义,因此必须使用转义字符\使其失去特殊意义
例如,使用grep 'pattern' file可以查找文件中包含指定模式的行
sed工具
sed `s/要被替换的字符/新的字符/g`
sed [-nefr] [操作]
-n:使用安静(silent)模式
-e:直接在命令行模式上进行`sed`的操作编辑
-f:直接将`sed`的操作写在一个文件内,-f filename则可以执行filename的sed操作
-r:`sed`的操作使用的是扩展型正则表达式语法(默认的是基础正则表达式语法)
-i:直接修改读取的文件内容,不是由屏幕输出
操作说明:[n1[,n2]] function
n1,n2:代表[选择进行操作的行数],例如:操作是需要在10到20行之间进行的内容,则[10,20[操作行为]]
function 中字母的含义:
`a`:新增,a后面可以接字符,这些字符会在新的一行出现(目前的下一行)
`c`:替换,c后面可以接字符,这些字符可以替换n1,n2之间的行
`d`:删除,d后面不接任何字符
`i`:插入,i的后面可以接字符,这些字符会在新的一行出现(目前的上一行)
`p`:打印
`s`:替换
使用sed 's/pattern/replacement/' file可以将文件中匹配指定模式的文本替换为指定的内容
2.扩展正则表达式

3.文件格式化与相关处理
格式化打印:printf
`\a`:
`\b`:退格键
`\f`:清楚屏幕
`\n`:输出新的一行
`\r`:回车
`\t`:等同于水平的tab按键
`\v`:等同于垂直的tab按键
`\xNN`:NN为两位数的数字,可以转换数字成为字符
awk
awk命令是一种强大的文本处理工具,支持正则表达式和字段处理。它可以用于从文件中提取指定字段、计算和处理数据等
awk '条件类型1{操作1} 条件类型2{操作2} ...' filename
| 变量名称 | 代表意义 |
|---|---|
NF |
每一行($0) 拥有的字段总数 |
NR |
目前awk所处理的是第几行数据 |
FS |
目前的分割字符,默认为空格键 |
文件对比工具
diff以行为单位来比对两个文件之间的差异
cmp利用字节单位去比对,用处不是很广泛
path将升级之后的文件与旧文件制成补丁文件,扩展名为.patch
patch命令可以对旧文件进行升级,或者将新文件进行还原。