SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
* Authors: [[Meng-Hao Guo]], [[Cheng-Ze Lu]], [[Qibin Hou]], [[Zhengning Liu]], [[Ming-Ming Cheng]], [[Shi-Min Hu]]
·······
初读印象
comment:: 发现了导致分割模型性能提高的几个关键要素,促使设计出一种使用轻量卷积操作的新型卷积注意力网络。
Why
一个成功的语义分割模型应该具有的特点
(i) 强大的骨干网络作为编码器。与以往基于 CNN 的模型相比,基于ViT的模型的性能提升主要来自于更强大的骨干网络。
(ii) 多尺度信息交互。图像分类任务主要是识别单个物体,而语义分割则不同,它是一项密集预测任务,因此需要处理单幅图像中不同大小的物体。
(iii) 空间注意力。空间注意力允许模型通过对语义区域内的区域进行优先排序来执行分割。
(iv) 计算复杂度低。这一点在处理来自遥感和城市场景的高分辨率图像时尤为重要。
相似工作
- LKM:将\(k\times k\)卷积分解为\(1\times k\)和\(k \times 1\)卷积,显示了大核卷积的重要性,但是忽略了多尺度感受野的重要性,也没有考虑如何利用大卷积核提取的这些多尺度特征,以注意力的形式进行分割。
- GoogleNet和HRNet用多尺度的方法进行分割,SegNeXt多了关注机制。
- VAN用大核注意力(LKA)来建立通道和空间注意力,但是忽略了多尺度特征聚合。
What
Multi-scale Convolutional Attention(MSCA)
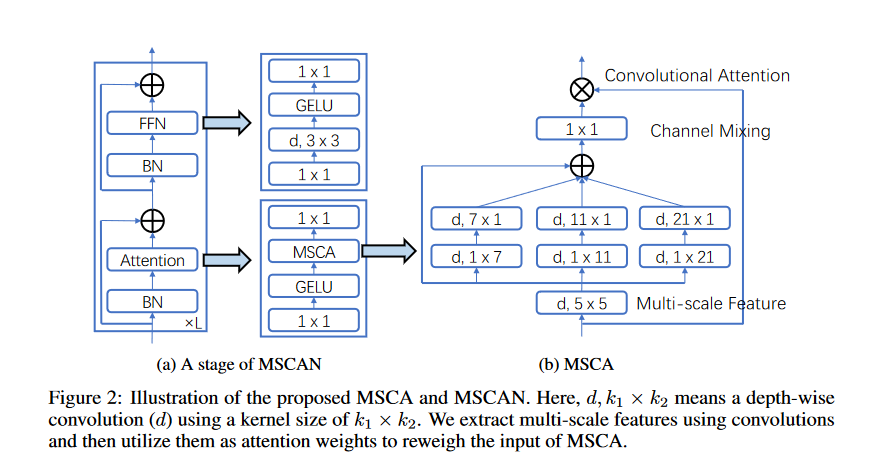 MSCA包含三个部分:一个深度卷积以聚合局部信息,一个多分支深度带状卷积以捕捉多尺度上下文,以及一个 1 × 1 卷积以模拟不同通道之间的关系。1 × 1 卷积的输出直接用作注意力权重,以重新权衡 MSCA 的输入。
MSCA包含三个部分:一个深度卷积以聚合局部信息,一个多分支深度带状卷积以捕捉多尺度上下文,以及一个 1 × 1 卷积以模拟不同通道之间的关系。1 × 1 卷积的输出直接用作注意力权重,以重新权衡 MSCA 的输入。
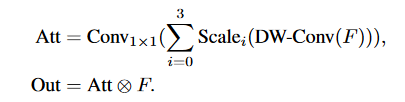
采用了条状卷积->轻量,且可以识别条状物体。
Encoder: MSCAN
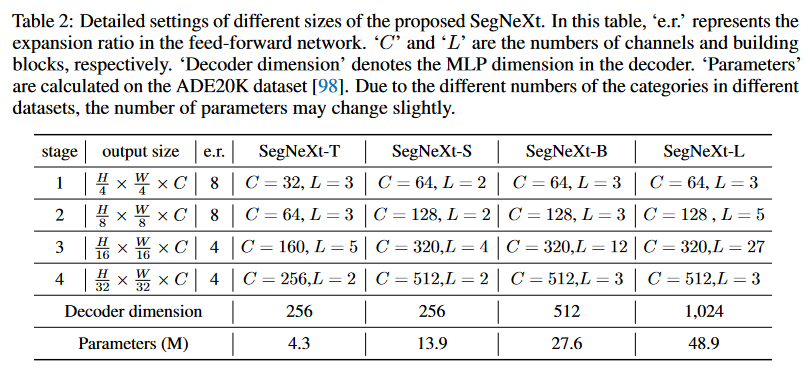 采用逐层降分辨率的设计,每层有一个步长为2的3×3卷积来下采样。#### Decoder
采用逐层降分辨率的设计,每层有一个步长为2的3×3卷积来下采样。#### Decoder
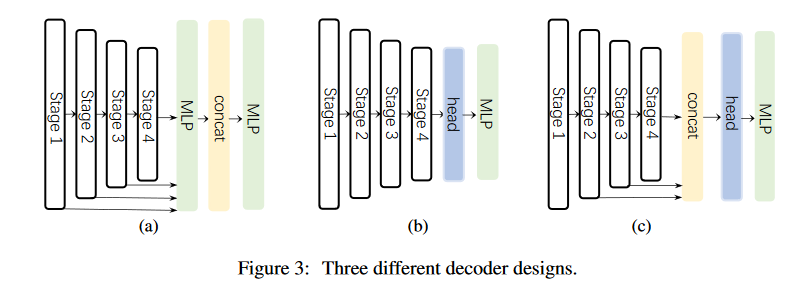
实验了三种解码器:
- 用于SegFormer中,采用简单的MLP;
- 用于CNN方法中,如PSP等;
- 最终采用的方法,汇聚后三层的特征,且采用一个轻量级的hambuger来聚合全局信息。
Hambuger
是另外一篇论文里的东西,作者发现在编码长距离依赖性能和计算成本方面,self-attention并不比20年前的矩阵分解(Matrix decomposition)效果好。作者建模全局信息问题转化为一个低秩补全问题(low-rank completion problem),使用优化算法帮助设计全局信息块。论文提出了一系列的Hamburger结构,作者利用优化方法来求解矩阵分解问题,将输入表示分解为子矩阵,并重构低秩嵌入。
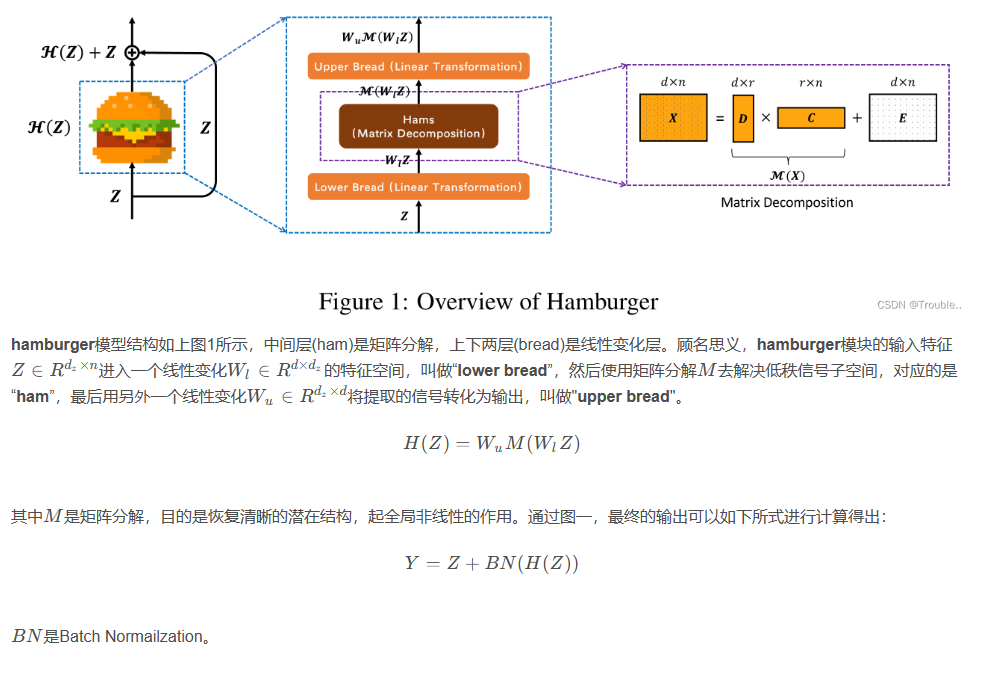 ###How
###How
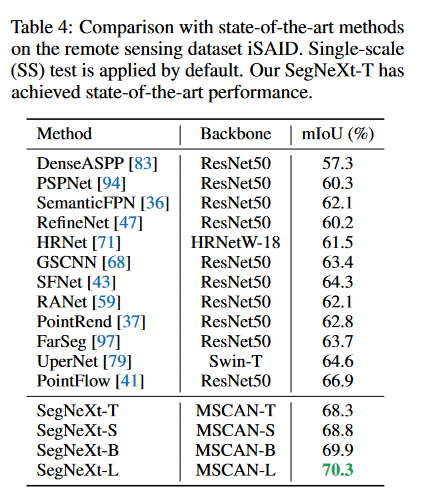
- Convolutional Segmentation Rethinking Attention Semanticconvolutional segmentation rethinking attention convolutional segmentation networks semantic segmentation criss-cross attention semantic convolutional segmentation biomedical networks convolutional segmentation multi-stage temporal segmentation generative gaussian semantic segmentation attentional semantic network segmentation transformers semantic segvit convolutional attention module block segmentation注意力attention network