LAVA: Large-scale Automated Vulnerability
Addition
I. 引言
自动化漏洞发现工作的进展一直受到缺乏可用于评估工具和技术的真实语料库的限制。缺乏这样的语料库导致工具的作者和用户都不能够衡量诸如漏报和误报率等基本量。
LAVA是一种基于动态污染分析的崭新技术,可以快速并自动地向程序源代码中注入大量真实的漏洞。LAVA的每个漏洞都伴随着一个可以触发它的输入,而正常的输入极不可能做到这一点。
II. 方法论
1、LAVA的技术基础
动态污染分析和源代码注入技术。
动态污染分析:是一种在运行时检测程序中数据流动的技术。它通过跟踪程序执行过程中数据的流动,来识别潜在的安全问题。在LAVA中,动态污染分析用于确定哪些数据可能被恶意利用,从而识别出潜在的攻击向量。
源代码注入技术:是将修改后的源代码插入到程序中,以达到改变程序行为或引入安全漏洞的目的。在LAVA中,源代码注入技术被用于在程序的特定位置引入新的代码,这些代码可以用于触发已知的安全漏洞或引入新的漏洞。
2、LAVA的运作流程
①在给定程序的一些特定输入上,我们通过程序的执行轨迹来确定哪些地方有可用的输入字节,这些字节不会确定控制流并且没有做太多的修改。我们称这些输入字节为DUAs,即Dead (死亡的)、Uncomplicated(不复杂的)和Available(可用的)数据。
这里的意思是在程序的执行过程中,有些输入的字节可能并未影响到程序的执行流程(也就是说它们并没有触发任何跳转或者改变控制流的动作),或者这些字节并未被显著地修改。这些字节被称为“死亡的、未复杂的和可用的数据”(DUA)。
②在程序轨迹中,找到在DUA之后的可能的攻击点。攻击点是源代码的位置,其中DUA可能被使用,如果它也可以在那里可用的话,来使程序变得脆弱。
这里的“攻击点”指的是在程序执行过程中,那些可能在DUA可用之后进行攻击的位置。这些攻击点可能会利用DUA来让程序出现漏洞。
③向程序添加代码,使DUA的值在攻击点可用,并使用它来触发漏洞。
这是说,为了使DUA在攻击点可用,我们需要在程序中添加一些代码。然后,利用这个可用的DUA,我们可以在攻击点触发程序的漏洞。
如:

3、选择注入目标的标准和考虑的因素
LAVA会选择重要的、可达性高、可利用性强、稳定性好且可控制性高的函数或系统调用作为注入目标,以实现更准确、可靠的安全漏洞发现和评估。
III. 实现细节
LAVA 分四个阶段对 Linux C 源代码中的缓冲区溢出漏洞进行注入和验证。
1、LAVA工具的设计
- 动态污染分析模块:该模块使用PANDA和Clang来执行动态污染分析,以识别潜在的漏洞注入点。
PANDA是一个轻量级的动态二进制插桩框架,用于收集程序的执行轨迹数据。
Clang是一个C/C++编译器,用于将源代码编译成可执行文件。在LAVA中,使用Clang进行动态污染分析,以识别潜在的漏洞注入点。
- 源代码注入模块:该模块负责将修改后的源代码插入到程序中,以引入新的漏洞注入点。在LAVA中,使用Clang进行源代码注入,通过修改程序的二进制文件来引入新的代码。
- 漏洞验证模块:该模块负责测试经过源代码注入后的程序,以确定是否引入了新的安全漏洞。在LAVA中,使用目标输入变化来测试每个潜在的有漏洞的二进制文件,以确定是否发生了缓冲区溢出等安全漏洞。
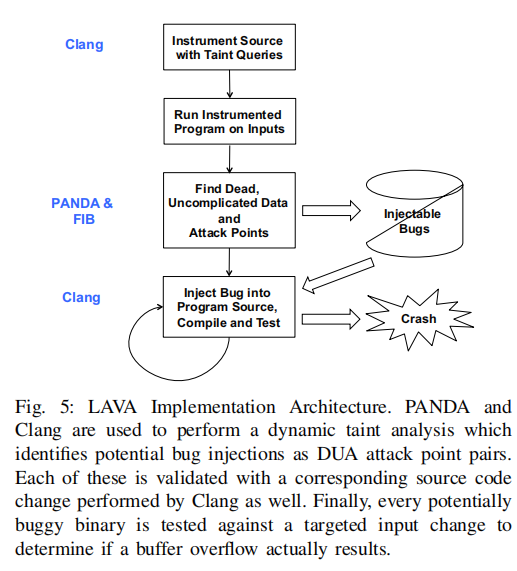
2、LAVA工具的实现
A. Taint queries
LAVA的污染查询依赖于PANDA动态分析平台,它是基于QEMU全系统仿真器。通过跟踪程序中的数据流,确定哪些数据可能被恶意利用,并在这些数据上应用标记或“污染”技术。在实现taint queries时,需要将标记指令插入到目标程序的源代码中,以便在程序执行期间收集数据流信息。
B. Running the program
在PANDA平台上运行目标程序时,需要将目标程序加载到PANDA平台上,并监控其执行过程。PANDA平台具有插件架构和动态污染分析能力,可以支持taint queries等分析功能。使用PANDA平台可以方便地进行迭代和分析。
C. Mining the Pandalog
从PANDA平台生成的事件日志(Pandalog)中挖掘信息是关键步骤之一。解析和分析Pandalog可以提取有关程序执行过程的有用信息,如函数调用关系、参数传递等。这些信息将用于发现潜在的漏洞注入点。通过挖掘Pandalog可以提高对目标程序的深入理解,从而发现更多的漏洞。
D. Inject and test bugs
将漏洞注入到目标程序中进行测试验证是整个过程的最后一步。首先需要使用PANDA平台的插件架构开发用于漏洞注入的插件。然后,将漏洞注入到目标程序的特定位置,如函数调用处。接下来,对经过漏洞注入的程序进行测试验证,以确定是否引入了安全漏洞。最后,对发现的漏洞进行修复和验证。

IV. 结果分析与评估
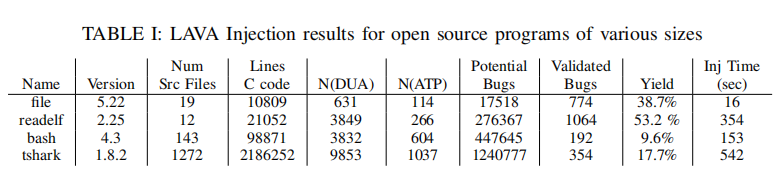
- 使用模糊测试和其他自动化工具对注入的漏洞进行检测。
- 比较各种工具的效能,包括已知漏洞的检测率和误报率。
- 分析各种因素对工具效能的影响。
V. 结论和未来工作
- LAVA的优点和局限性。
- 对其他自动化漏洞发现工具的启示和影响。
- 对未来工作的建议和展望。
- Vulnerability Large-scale Automated Addition 笔记vulnerability large-scale automated addition vulnerability frameworks cdeepfuzz automated large-scale automated addition with multiobjective optimization large-scale conversational automated program reading vulnerability recognition-vgg convolutional large-scale recognition large-scale tensorflow cdeepfuzz learning