Flink消费kafka数据同步问题排查 https://mp.weixin.qq.com/s/EZbCKHBI_JrsF0yJndhe8Q
Flink消费kafka数据同步问题排查
我们有一个flink任务,消费的kafka的数据,写入到es,非常简单的逻辑,但是出现了数据丢失的情况,之前没遇到过,初步猜想是转换逻辑或脏数据的影响,排查了一圈,未发现Exception等相关信息。猜想是写入频率太快,es写入的时候,出现了version conflict,也没找到相关证据。
从埋点日志来看,这个消息根本没进入到flink内部,因此也就排除了是转换逻辑出错或者是es写入失败导致。
按照猜想,业务能感知到数据同步出现了问题,大概率是丢失了大量的数据,而且根本没进入到flink内部,因此怀疑是单分区不消费的情况,之前因为线程hang死也发生过类似的情况。
去统计了一下消费分区,还真发现了问题,我们kafka有5个分区,统计出来的只有3个分区在消费。
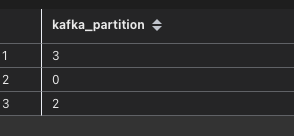
同时我们用同一个程序,起了另外一个任务,发现了消费分区是0-4正常的5个,问题具有随机性,时好时坏?
发给更多人一起排查,被同事一眼看到bootstrap.server里不仅配置了pro集群,还混入了pre集群地址,bootstrap.servers=[business-s2-002-kafka1.xxxx.com.cn:9092,business-s2-002-kafka2.xxxx.com.cn:9092,business-s2-002-kafka3.xxxx.com.cn:9092,pre-kafka1.xxxx.com.cn:9092,pre-kafka2.xxxx.com.cn:9092,pre-kafka3.xxxx.com.cn:9092],不知道是不是这个问题导致的,因此要从源代码层面寻找一些证据和支持。
按照网上谷歌出来的理论讲解,kafka的消费者在连接kafka server的时候,先选bootstrap.server的第一个地址,如果第一个连不上,再连第二个,实际上看起来并非如此...
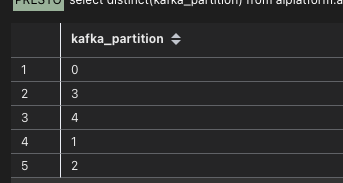
消费组是sp2_group_name_G_2023_10_08_16_58_03,topic是test_topic_A,在pro的kafka集群里有0-4共计5个分区,而在pre集群里有一个同样的topic,他有0-2共3个分区。
关键性的日志如下:

对应到FlinkKafkaConsumerBase.java的源代码,查找线索,主要看open和run两个函数,大概搞清楚了整个流程。
程序的第一步,根据时间戳到kafka的server读取到每个分区的offset,作为初始的offset传给kafka,调用的是如下方法。

在open方法里,因为我们的场景是指定了offset,并且第一次启动的时候,没有状态,因此打日志的地方是这段代码 : (因为这里的TIMESTAMP模式有bug,因此没有直接用这个)。
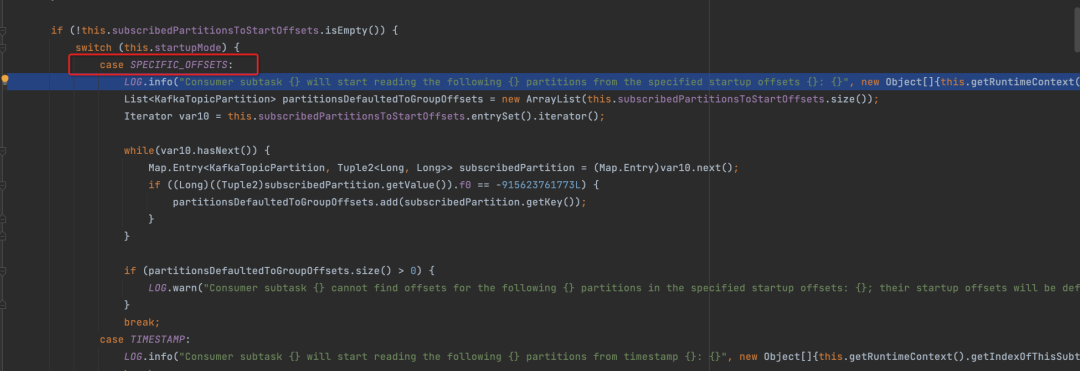
LOG.info("Consumer subtask {} will start reading the following {} partitions from the specified startup offsets {}: {}", new Object[]{this.getRuntimeContext().getIndexOfThisSubtask(), this.subscribedPartitionsToStartOffsets.size(), this.specificStartupOffsets, this.subscribedPartitionsToStartOffsets.keySet()});这里面有几个关键变量subscribedPartitionsToStartOffsets和specificStartupOffsets,因此追寻这2个变量,specificStartupOffsets这个是我们上面的方法传入并且设置的指定offset逻辑,而subscribedPartitionsToStartOffsets则非常关键,他来源于this.partitionDiscoverer.discoverPartitions(),分区发现。
List<KafkaTopicPartition> allPartitions = this.partitionDiscoverer.discoverPartitions();
现在我们把整个逻辑串一下。
第一步,根据时间戳读取offset,我们从日志里看到,他读到了0-4个分区,并且也读到了他们的offset。
第二步,每一个消费线程(subtask 0-3),通过discoverPartitions去读取自己分配到的分区(服务端的协调节点负责分配,有RR等多种算法,网上讲解很多)。
我们发现,最后分配到的情况如下:
subtask0 => partition3,
subtask1 => partition0,
subtask2 => partition1,
subtask3 => partition2
4分区不见了?是为什么呢?由于去kafka server拿分配分区的时候,每个subtask发送1次请求,连接的server则是从bootstrap.server里随机选取的,因此可能连上pro的kafka集群(因此分配到了分区3),也可能连到了pre集群,因此可能被分配分区0-2(当然也不排除是pro的),这里就非常混乱,你搞不清楚这次subtask请求的到底是pro集群的还是pre集群的,因此领的分区,也不知道是来自哪里,不过可以肯定的是3分区是来自pro,至于4分区没有的原因,可能剩下的subtask都连的是pre集群?(猜想)
还有个疑问,这里连上了0-3分内,为什么日志里统计出来,只有0,2,3,其中的1分区一条数据也没有?
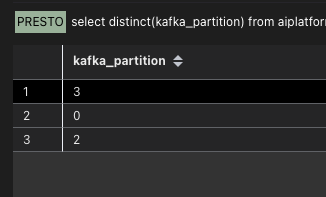
这就涉及第三步。
第三步,去拿数据。flink是在内部建了一个createFetcher,直接连接server去做数据拉取。这里也涉及到建立连接,如果这个时候你用的是pro的offset,连接的是pre集群去拉取数据,由于这个offset很大(在pre里根本不存在),是不是就拉不到数据了呢?毕竟pre集群的数据少offset很小,而pro的offset很大。
由于没有去看拿时间戳、discoverPartitions和createFetcher建立连接的代码,因此对于bootstrap.server的随机选择只是猜想,因此用另外一个任务去证明他。
我们新建了第二个任务,相同的bootstrap.server的配置,日志如下:

从日志中,我们看到拿offset的地方,只拿到了0-2三个分区,也就是拿offset连接的是pre(具有随机性,并且确认bootstrap.server里的机器都是活的),因此第一步请求的server肯定是随机选择的。
而在discoverPartitions的时候第二步的结果是:
subtask0 => [partition1,partition4]
subtask1 => [partition2]
subtask2 => [partition3,partition0]
subtask3 => 日志里没出现???
所以这里的discoverPartitions又连接的是pro集群的kakfa。
整个代码、日志和现象都对上了,因此也就确认了就是server的配置问题,由于有些源码没有细看,因此可能会有一些错误,供参考。
把bootstrap.server配置正确之后,分配的分区再也没有混乱了。
