前言
本问阐述 Redis 主从同步、哨兵监控和故障迁移的过程,并通过各个服务日志加以验证。
准备工作
- 主从和哨兵安装见 安装过程。
- 为了方便通过日志观察同步过程,你可以在每个 Redis 和 Sentinel 配置文件中修改下面参数,实现前台运行并将日志输出到控制台。
# 这两个配置是为了实现前台运行和输出日志
# 关掉后台运行
daemonize no
# 注释掉日志输出
# logfile /var/log/redis_6380.log
- 为了方便查看,Redis 服务还需要关闭 AOF。
# 关闭 AOF 持久化方便查看同步产生的 RDB 持久化文件
appendonly no
- 为了方便查看,如果数据目录下已经有文件可以执行这个指令清除掉。
rm -f /var/lib/redis/6380/*
主从同步
原理
从节点跟随主节点时,会发送自己的 Replication ID 和偏移量给主节点对比,这个 ID 在 dump.rdb 文件开头也可以看到。用来判断从节点的 RDB 快照是不是最新的。是最新的,进行增量同步,否则进行全量同步+增量同步。
全量同步时,主节点调用系统调用fork() 创建子进程 通过写时拷贝技术(copy-on-write)生成 RDB 数据快照保存到磁盘上,然后发送给从节点。从节点接收也保存到磁盘,接收完成后清除内存中的旧数据,再将磁盘上的 RDB 加载到内存。如果多个从节点进行全量同步,需要队列顺序发送和接收。
以上是默认方式,还有不需要磁盘参与的全量同步,RDB 数据通过套接字直接发送给从节点,这种方式会更加高效。
增量同步时,主节点会有一个缓冲队列,只需要对比偏移量同步这个队列中的数据就行了。
如果从节点开启了 AOF 那从节点每次重启追随都会进行全量同步。4.0版本开始 AOF 是混合模式,.aof 文件前面是 RDB,后面是追加的写指令,而这里的 RDB 并没有 Replication ID,从而无法对比是否最新数据只能全量同步。没有ID的原因还不知道为什么。
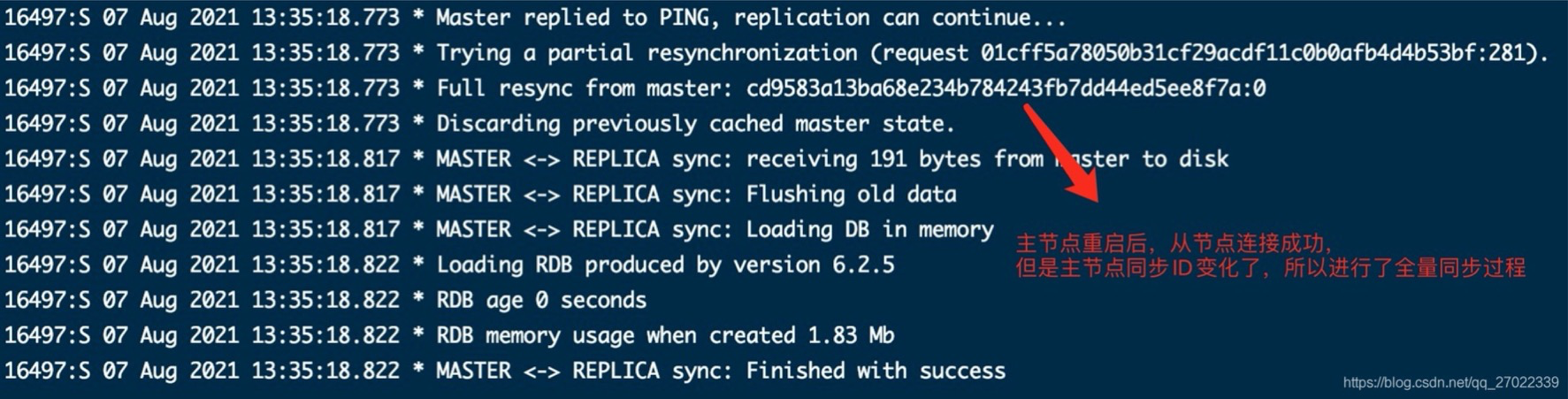
主节点关机,从节点会一直尝试重连。主节点重启后会产生新的 Replication ID,从节点连上后主节点对比发现 ID 不一致,从而进行全量同步。
从节点宕机,对主节点没有太多影响
主节点宕机恢复
- 直接恢复主节点
- 手动将从切换为主,通过 redis-cli 连接从节点执行以下命令,将从节点改成主节点
REPLICAOF no one
相关配置项
这里只列出了部分,其他相关配置参考 Redis 配置文件,注释解释得很清楚。
- 主节点
# no 代表 RDB 先存储到磁盘,再经过套接字传输
# yes 代表 RDB 不存储到磁盘,直接经过套接字传输
repl-diskless-sync no
# 增量同步队列缓冲区大小
# 如果缓冲区太小,从节点宕机过程中缓冲区写满了,重启会导致触发全量同步
# 如果缓冲区足够大,从节点宕机重启则只需要进行增量同步
repl-backlog-size 1mb
- 从节点
# 全量同步时,传输过程中是否允许访问旧数据
# 同步完成前内存里面都是旧数据,如果数据量太大同步时间非常长,这个空档期可以考虑允许访问内存中旧的数据
replica-serve-stale-data yes
# 作为从节点的时候是否只读不允许写入
replica-read-only yes
日志观察同步过程
- 初次跟随时的主从 Replication ID 不一致,进行全量同步
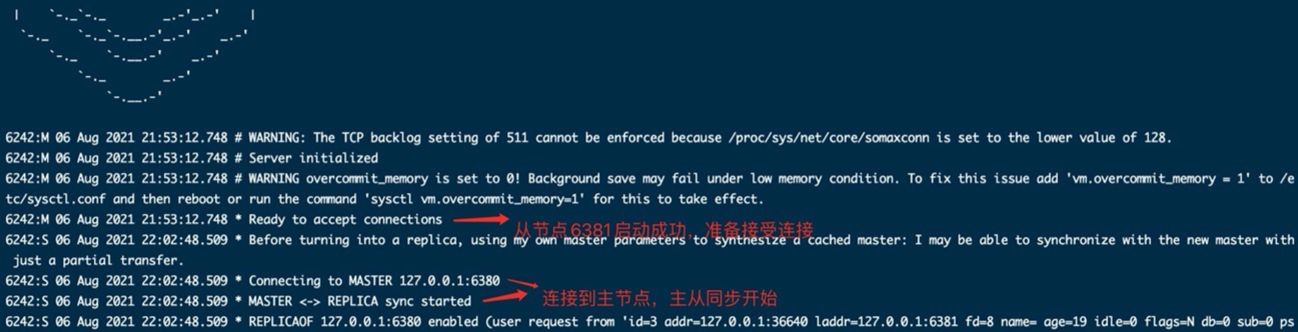
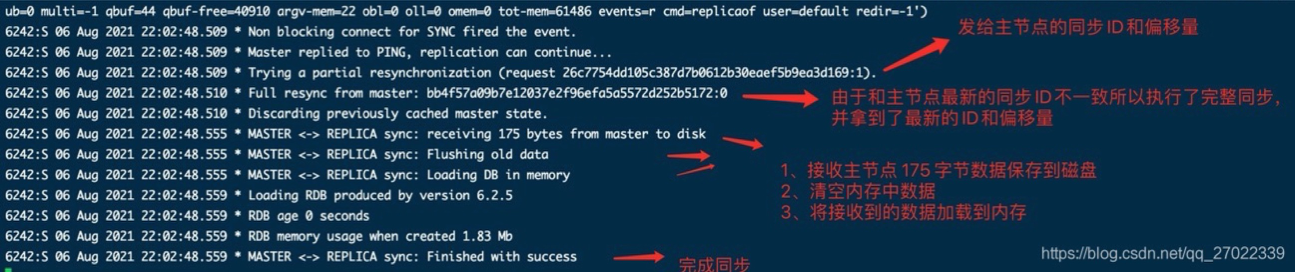
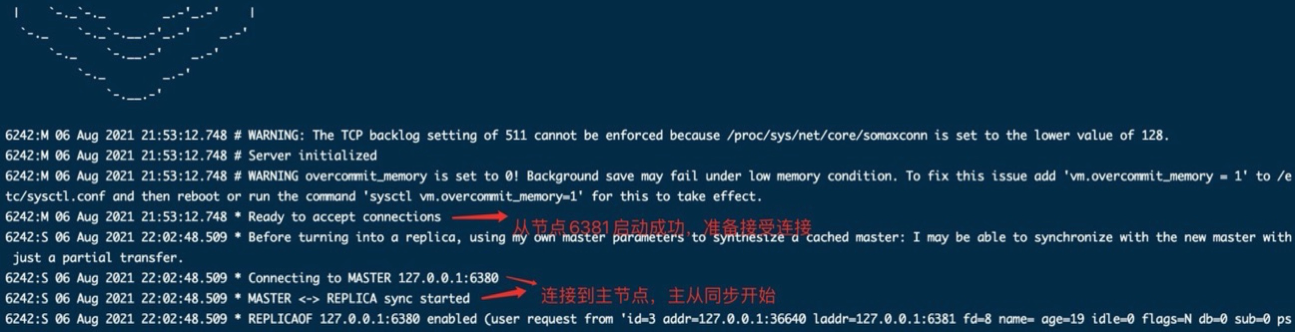
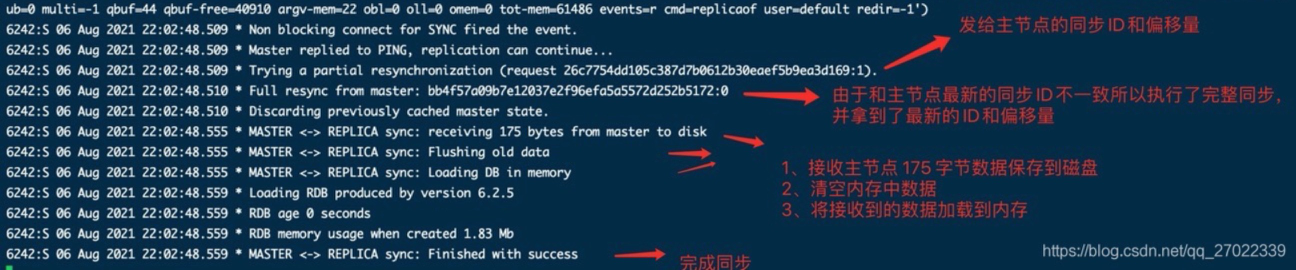
- 找到主和从数据目录下的 RDB 文件也可以看到上面的 Replication ID 保持了一致。

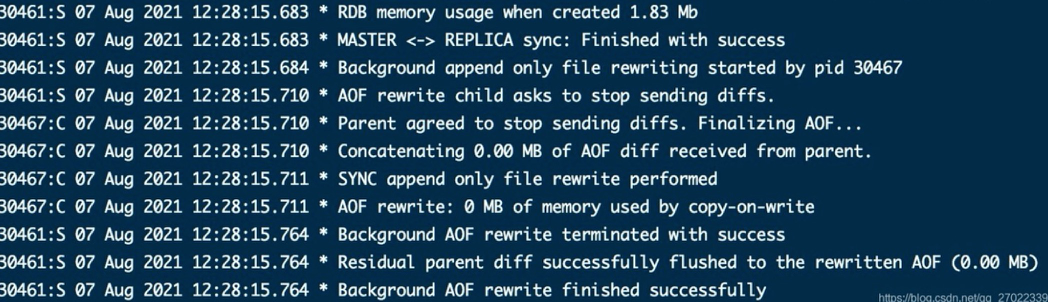
- 从节点停机重启再次追随时,主节点发现 Replication ID 一致,所以只用偏移量判断进行了增量同步。(这一步图里ID跟上面不一致是因为过了一天我清除重启过了)


- 从节点开启 AOF 重启,从节点追随日志可以看到 Replication ID 和之前一样,也就是跟主节点是一致的,但是还是执行了全量同步。

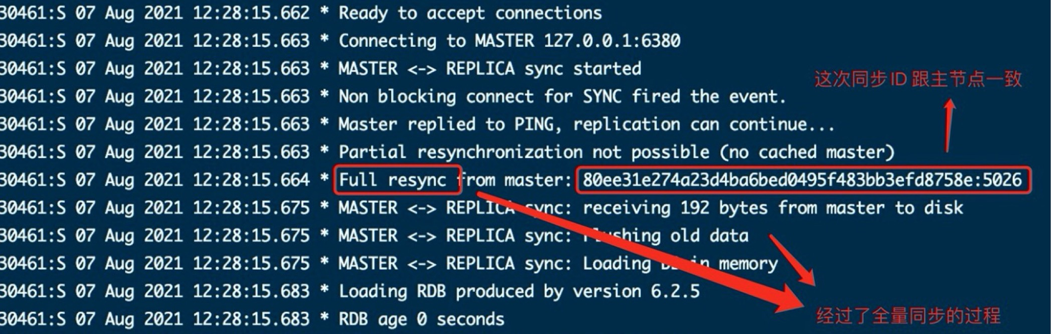
- 主节点关机后,从节点不断尝试重连。主节点重启后 Replication ID 变化 从而进行全量同步。

- 通过主节点是可以知道从节点是否在线的,因为主需要向从同步数据,通过下面主节点日志可以看到从节点下线上线信息。

哨兵(Sentinel)
原理
- 哨兵是独立、不同于 Redis 的服务,它主要作用是
【监控】检查主从节点是否正常运行;
【提醒】Redis 出现故障时,通过 API 向其他应用程序发送通知;
【故障迁移】在主不能正常工作时,将主的其中一个从升级成新主,并让所有从跟追新主包括旧主(修改其配置),当客户端访问旧主时,向客户端返回新主地址。
- 自动发现
一般情况下哨兵通过发布订阅与主、从和其他哨兵进行通信。哨兵通过主节点来获得其从节点的信息,每个哨兵都订阅了被它监视的所有主服务器和从服务器的 sentinel:hello 频道。
- 监控存活状态
哨兵以每秒钟一次的频率向它所知的主、从以及其他哨兵发送一个 PING 命令。距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值,那么哨兵自己会标记它为主观下线。
标记为主观下线的哨兵会询问其他哨兵主存活状态,而至少需要 quorum 个 哨兵同意才会将这个主服务器判断为失效,之后再尝试发起故障迁移。
哨兵需要获得系统中过半的支持, 才能发起一次故障迁移,不过半是不能执行的。
- 配置纪元
哨兵的配置文件有代表纪元从 0 开始的自增版本号,每次选举出新主代表进入一个新的纪元,哨兵互相交换信息的同时会对这个版本号进行对比,低版本的哨兵会向高版本的哨兵同步配置。
- 领头选举
故障迁移前需要先对比版本号选举出唯一选举领头(leader),其他哨兵来支持领头的选择;当选失败,在设定的故障迁移超时时间的两倍之后,重新尝试当选;再按 新主选择规则 选出新主。
- 新主选择规则
【淘汰】被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从节点。
【淘汰】失效主连接断开时长超过 down-after 选项指定时长十倍的从节点。
【选择】出复制偏移量最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用/相同,选择运行 ID 最小的。
- 迁移过程
被选中的从 SLAVEOF NO ONE 命令,让它转变为主服务器。
通过发布与订阅将更新后的配置传播给所有其他哨兵进行更新。
向其他从服务器发送 SLAVEOF 命令,让它们去复制新的主服务器。
当所有从服务器都已经开始复制新的主服务器时, 领头结束这次故障迁移操作。
- 配置持久化
哨兵自动发现会将主、从、其他哨兵的信息追加到自己的配置文件中;故障迁移结果也会修改哨兵和所有主从的配置文件,包括旧的主节点。这意味着停止和重启都是最新的选举结果。
- 一个哨兵可以监控多个主节点,那就意味着可以监控多个主从集群,按下面格式配置多行就行了。
# sentinel monitor <主节点名称> <主节点ip> <主节点端口号> <quorum 个哨兵主观认为主节点下线了,才会将主节点判定为客观下线,从而开始故障迁移选新主>
sentinel monitor <master-name> <ip> <redis-port> <quorum>
日志解读
大致流程:三个 Redis 6380(主)、6381(从)、6382(从),三个哨兵 6383、6384、6385。
这个是第一个哨兵 6383 启动的日志,通过日志可以观察到这个哨兵的 ID;监控 mymaster 主从集群,并且有 2 个哨兵主观认为主节点下线才会判定主节点为客观下线,从而尝试进行故障迁移选举出新的主节点;还通过主节点发现了两个从节点。

并且现在查看 6383 的配置文件,我们可以发现哨兵将以上信息追加到了文件末尾 # Generated by CONFIG REWRITE 之后的代表哨兵追加的内容。
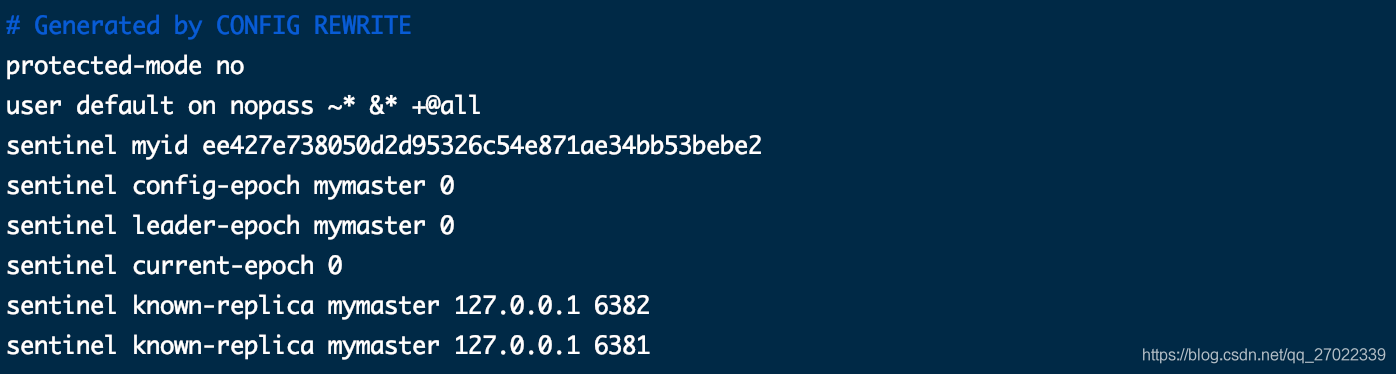
启动哨兵 6384 和 6385 后我们通过 6383 的日志输出了刚启动的哨兵信息。

刚起动的两个哨兵的信息同样写到了配置文件中。
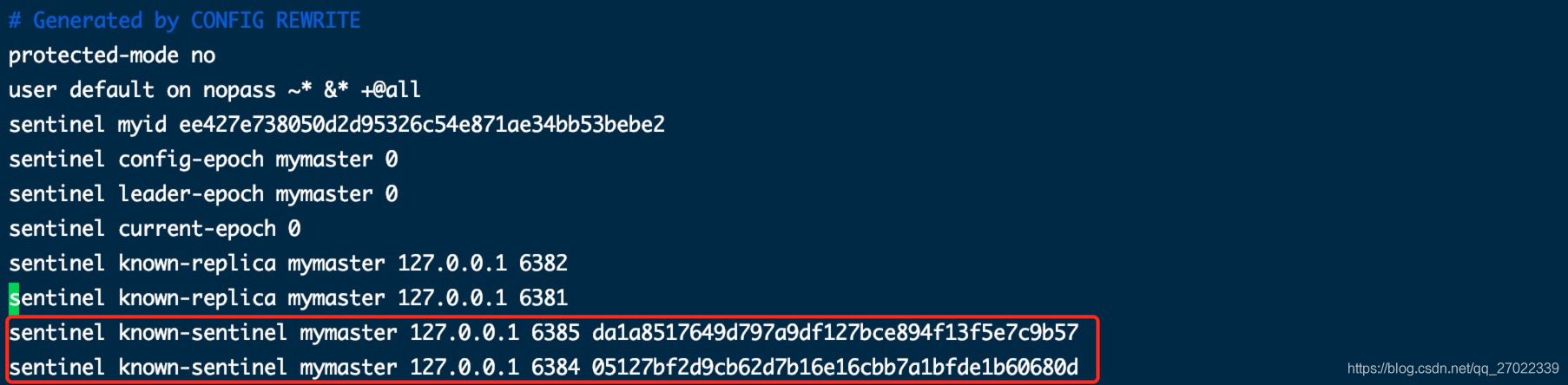
使用 redis-cli 6380 连接主节点,使用订阅命令可以观察到哨兵通过主节点发布/订阅功能进行通讯,通过从节点也可以看到。
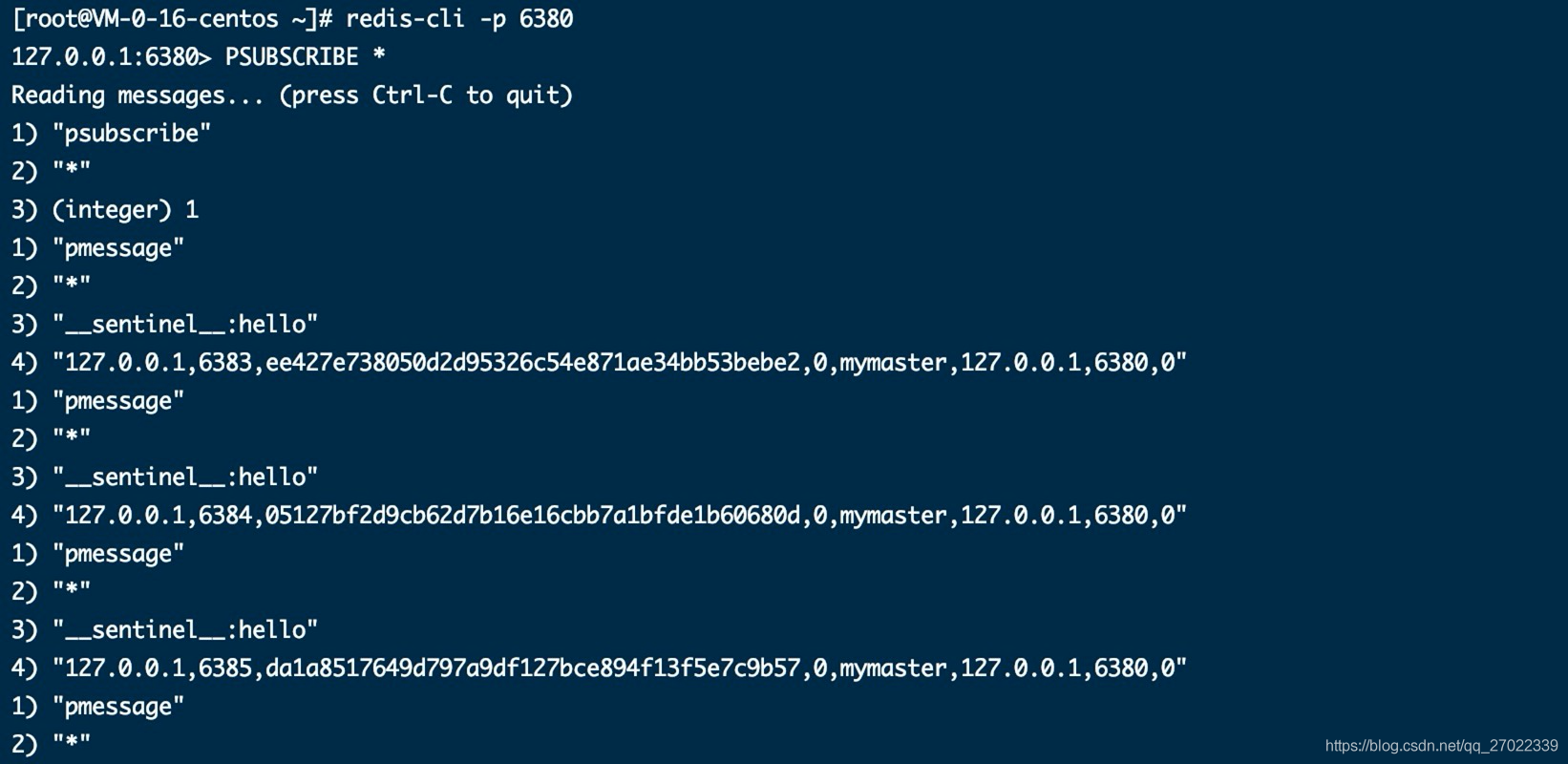
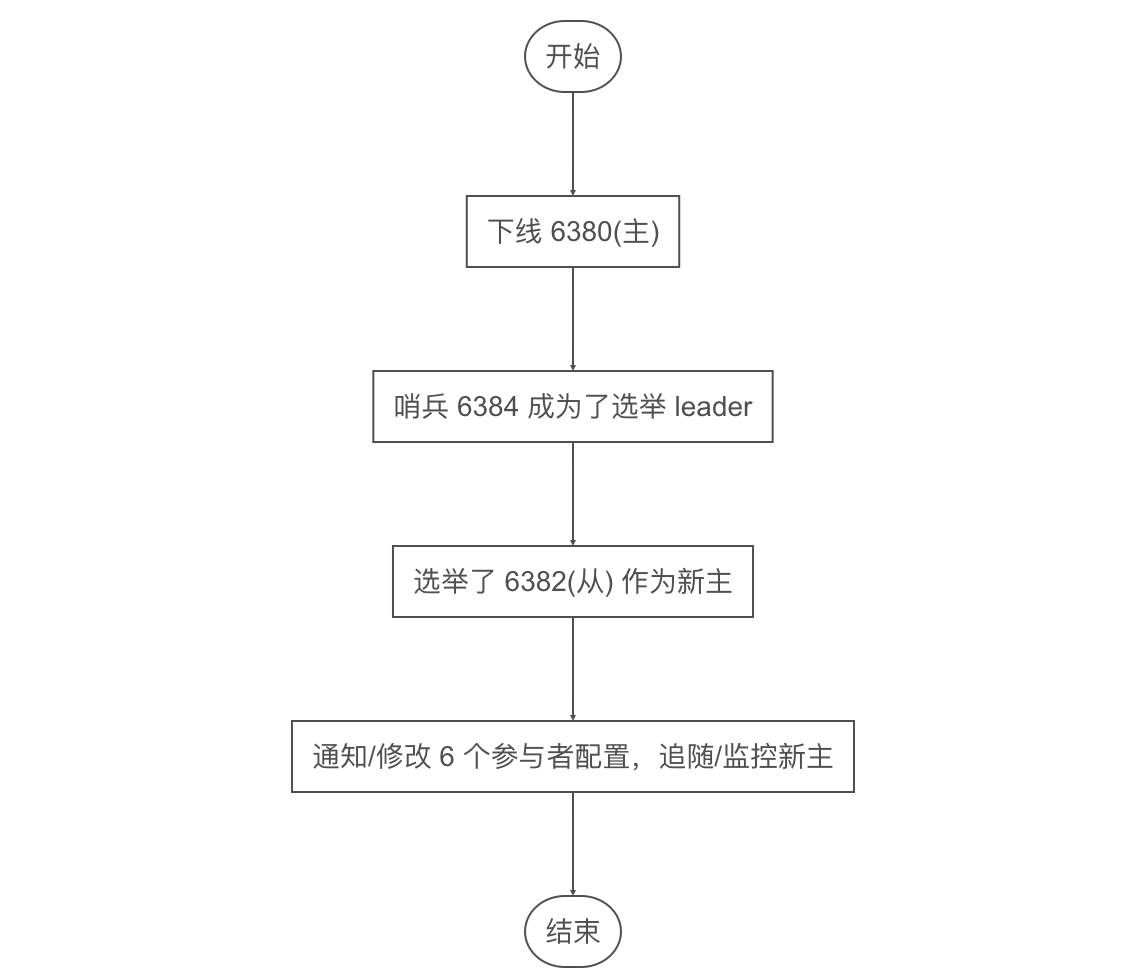
将主节点 6380 下线,经过保护时间后查看日志最多的哨兵 6384 输出的信息
[1]-自己主观认为主节点下线;有其他哨兵主观认为主节点下线达到了客观下线的票数
[2]-进入新纪元 1,开始故障迁移
[3]-选举了 6384 作为选举投票的主,其他两个哨兵跟投
[4]-选举了从节点 6382 为新主,f+failover-state-send-slaveof-noone slave 127.0.0.1:6382 相当于告诉 6382 执行 REPLICAOF no one
[5]-后面就是通知/修改所有相关服务的配置,三个哨兵和三个 Redis(包括了已经下线的主)
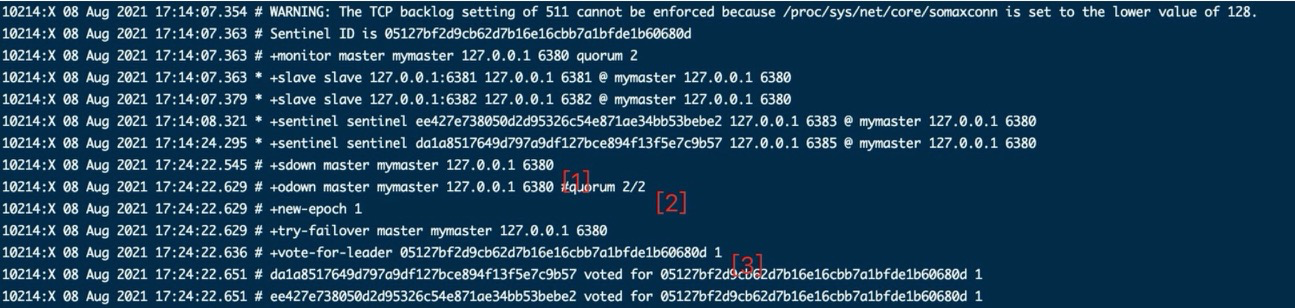
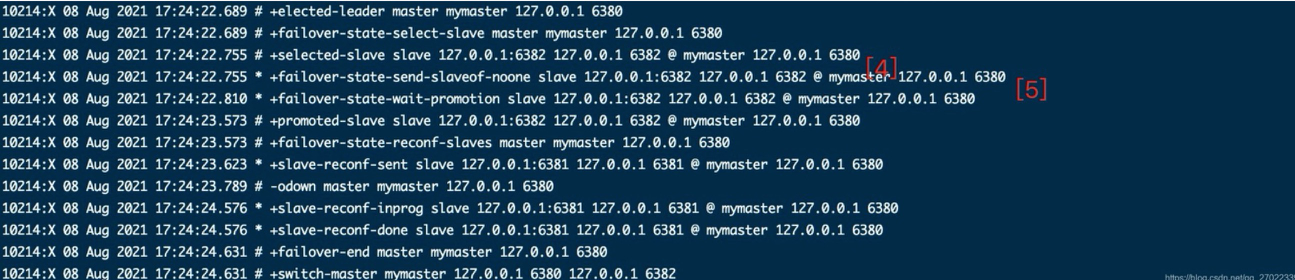
从 6381 的日志可以看到向新主 6832 进行了一次新的同步流程。

其他问题
- 跟随指令旧版本是 SLAVEOF,新版本是 REPLICAOF。