一、简介

scrapy的优势:
1、为了更利于我们将精力集中在请求与解析上
2、企业级的要求,效率高
二、模块安装
scrapy支持Python2.7和python3.4以上版本
1.在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件
2. 在命令行进入到Twisted的目录 执行pip install 加Twisted文件名 pip install Twisted
3.执行pip install scrapy
三、运行流程
只要是框架就要掌握其运行流程
1.找到目标数据==》2.分析请求流程==》3.构造http请求==》4.提取数据==》5.数据持久化
A:新生报到的例子

宿舍 床号 班级 卡号
移动办卡 床单
可能有新的需求会交给管理员,然后重新排队(如换床号,不住宿等),然后再到报到处报道拿资料,然后到新生等待处,当 需求满足0时退出
B:
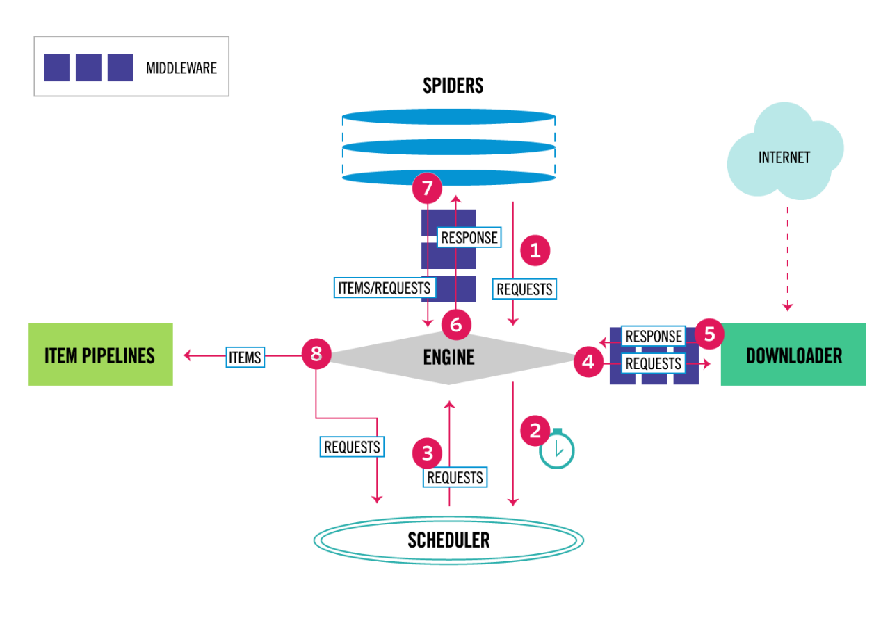
上图显示了Scrapy框架的体系结构及其组件,以及系统内部发生的数据流(由红色的箭头显示) Scrapy中的数据流由执行引擎控制,流程如下:
首先从爬虫获取初始的请求 将请求放入调度模块,然后获取下一个需要爬取的请求 调度模块返回下一个需要爬取的请求给引擎 引擎将请求发送给下载器,依次穿过所有的下载中间件 一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。 引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件 爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎 引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求 该过程重复,直到调度程序不再有请求为止。