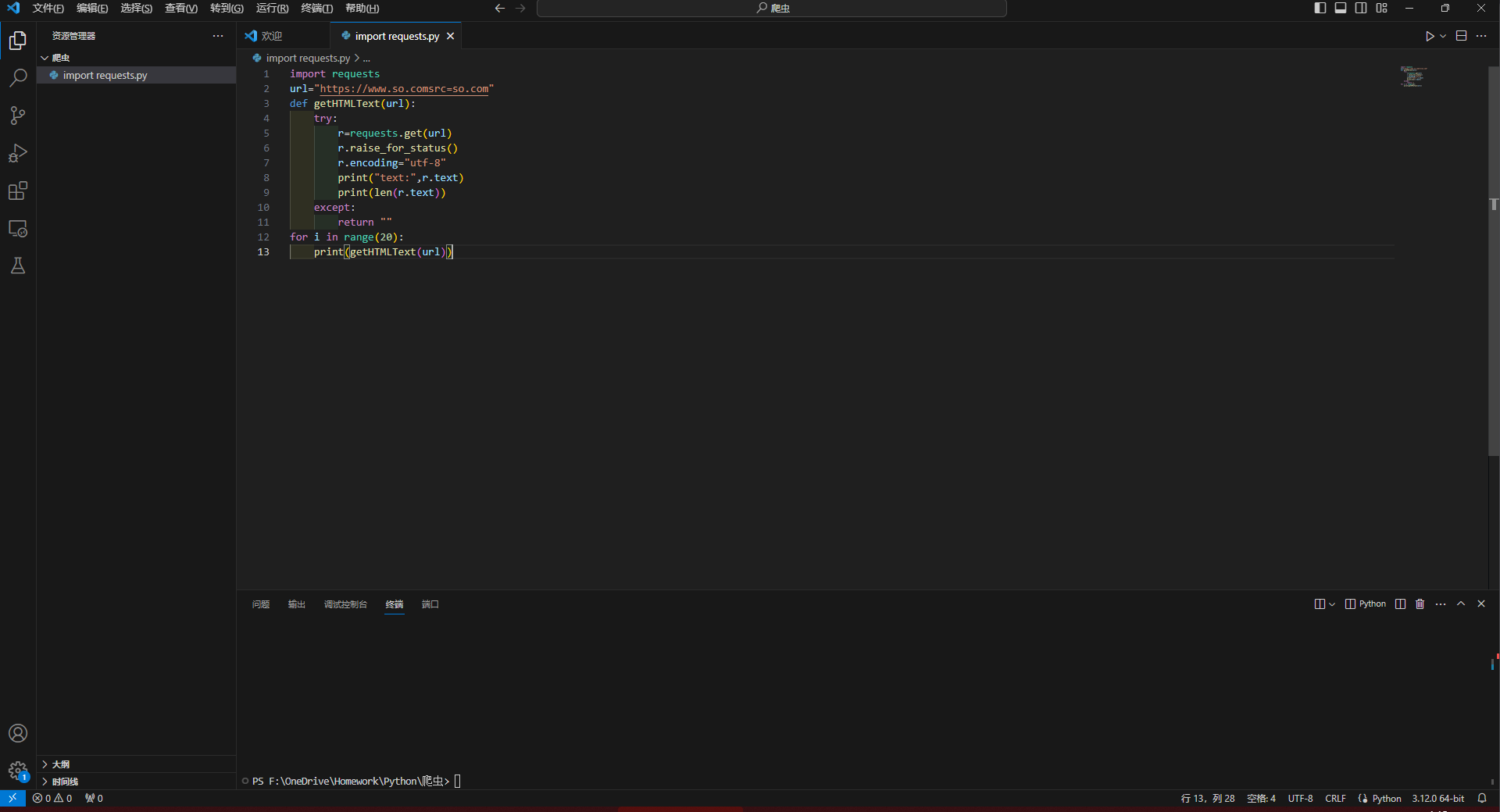
爬虫作业
import requests
url="https://www.so.comsrc=so.com"
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding="utf-8"
print("text:",r.text)
print(len(r.text))
except:
return ""
for i in range(20):
print(getHTMLText(url))