1.算法仿真效果
matlab2013b仿真结果如下:



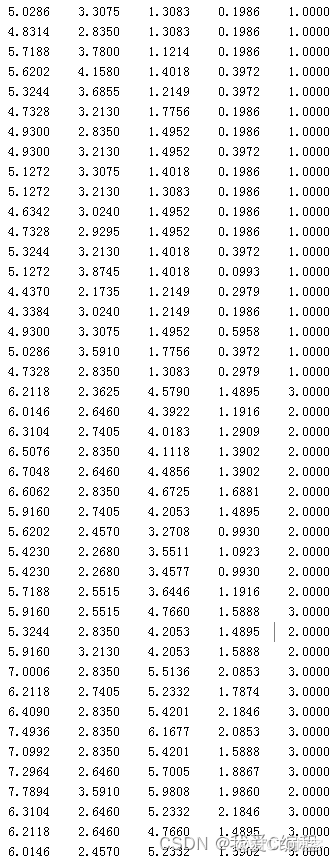
运行结果如下所示:


测试集的分类结果及分类正确率。
2.算法涉及理论知识概要
首先“K均值算法”和“基于局部和全局一致性算法”的整合,并不是两个算法的简单拼凑,这里,实际上结合了“K均值算法”和“基于局部和全局一致性算法”两者算法的思想。根据你提供的算法思想,算法的基本步骤是:
-----------------------------------------------------------------------------------------------------
输入:数据集(其中训练样本和测试样本分别占一定的比例)和图像其中有少量样本已被标记类别,而且每一类至少标记一个训练样本。
-----------------------------------------------------------------------------------------------------
Step1:计算少量有标记样本的均值,得到c(类别数目)个初始聚类中心点;
Step2:使用欧式距离计算未标记数据到c个初始中心点的距离,将未标记样本分配到距离中心点最近的那类中,划分出c个簇;
Step3:使用测地距离的相似性度量方法,选择各个簇中相似度大于等于0.9的()个(各个簇中的数目不一样)样本,求它们的均值,作为c个新中心点以及得到c个平均半径;
Step4:循环(2)(3),直到c个中心点固定;
Step5:对()个样本以及距离各个中心点半径内的样本进行标记;
Step6:用基于局部和全局一致性算法对剩下的未标记的样本进行标记,其中已标记数据只使用c个中心点;
Step7:在全部样本标记完后,再计算出各个类的c个中心点。
Step8:对于新的测试数据,通过计算测试数据与各个中心点的相似度,选择可信度最高的进行标记。
-----------------------------------------------------------------------------------------------------
输出:分别将数据集分成已标记和未标记以及测试数据集三部分,其中测试数据集占30%的比例,已标记和未标记的共占70%。用10折交叉验证法进行测试,输出F1-measure各个指标的结果,输出分类后的图像及指标结果。以已标记数据作为训练集,保证每个类别有一个已标记的训练集,然后按照不同的比例扩展训练集,一个数据集的precision和recall测试结果都是未标记数据和测试数据结果的均值。对数据集按已标记数据占得不同比例进行测试。
半监督学习(Semi-supervised learning)发挥作用的场合是:你的数据有一些有label,一些没有。而且一般是绝大部分都没有,只有少许几个有label。半监督学习算法会充分的利用unlabeled数据来捕捉我们整个数据的潜在分布。它基于三大假设:
1)Smoothness平滑假设:相似的数据具有相同的label。
2)Cluster聚类假设:处于同一个聚类下的数据具有相同label。
3)Manifold流形假设:处于同一流形结构下的数据具有相同label。
标签传播算法(label propagation)的核心思想非常简单:相似的数据应该具有相同的label。LP算法包括两大步骤:1)构造相似矩阵(affinity matrix);2)勇敢的传播吧。
label propagation是一种基于图的算法。图是基于顶点和边组成的,每个顶点是一个样本,所有的顶点包括了有标签样本和无标签样本;边代表了顶点i到顶点j的概率,换句话说就是顶点i到顶点j的相似度。
3.MATLAB核心程序
if test_sel == 3
%Step1:计算少量有标记样本的均值,得到c(类别数目)个初始聚类中心点
%Step1:计算少量有标记样本的均值,得到c(类别数目)个初始聚类中心点
[m0,n0,k0] = size(Is);
%如果图片太大,会导致out of memory的错误,这里需要将图片自动变小
I = imresize(Is,[round(m0/2) round(n0/2)]);
[m2,n2,k2] = size(I);
Xr = (reshape((I(:,:,1))',1,m2*n2))';
Xg = (reshape((I(:,:,2))',1,m2*n2))';
Xb = (reshape((I(:,:,3))',1,m2*n2))';
X1 = [Xr,Xg,Xb];
rng(2)
tmp = randperm(length(X1));
%随机产生聚类中心点
[n,d] = size(X1);
Col = d; %测试数据的列数
X = X1(:,1:Col);
nc = X(tmp(1:k),:); %随机C个初始聚类中心点
%Step1:任意进行标记
%Step1:任意进行标记:
nr = zeros(1,k);
Dist = sqdist(nc',X',1); %聚类中心到数据点的距离
[Dwin,Iwin] = min(Dist',[],2);%Dwin 是Dist中每一列的最小值,Iwin是取最小值的行数k,都是n行1列的矩阵
%将数据根据分类结果标号,分成C个簇,表上标记
v = sort(tmp(1:k));
%进行部分标记
X_initial_sort(:,1:Col) = X; %较初步的分类结果给数据标号
X_initial_sort(:,Col+1)=Iwin;
%Step2:用基于局部和全局一致性算法对剩下的未标记的样本进行标记,其中已标记数据只使用c个中心点;(已有现成的程序)
%Step2:用基于局部和全局一致性算法对剩下的未标记的样本进行标记,其中已标记数据只使用c个中心点;(已有现成的程序)
%6.1选择没有被标记的数据集和
Y = produce_labelY2(X_initial_sort(:,Col+1),k);
%进行部分标记
yy = X_initial_sort(:,Col+1);
best_s = 0;
best_a = 0;
sigma = 0.076;
alpha = 0.959;
[F,errors] = LGC(X,Y,yy, sigma, alpha,delta2,k);
%6.2根据计算得到的F值对未标记的数据进行标记
for i=1:size(F,1)
[values(i),indexxx(i)] = max(F(i,:));
end
X_initial_sort3 = X_initial_sort;
X_initial_sort3(find(X_initial_sort(:,Col+1) == 0),Col+1) = indexxx(find(X_initial_sort(:,Col+1) == 0));
%Step7:在全部样本标记完后,再计算出各个类的c个中心点。
%Step7:在全部样本标记完后,再计算出各个类的c个中心点。
%Step7:在全部样本标记完后,再计算出各个类的c个中心点。
for i=1:k
c_final(i,:) = mean(X_initial_sort3(find(X_initial_sort3(:,Col+1) == i),1:Col));
end
%Step3:产生分类后的图像值。
%Step3:产生分类后的图像值。
results = zeros(length(X1),3);
for i = 1:length(X1)
results(i,:) = c_final(X_initial_sort3(i,4),:);
end
I2(:,:,1) = (reshape(results(:,1),n2,m2))';
I2(:,:,2) = (reshape(results(:,2),n2,m2))';
I2(:,:,3) = (reshape(results(:,3),n2,m2))';
figure;
subplot(121);imshow(uint8(I));title('原图');
subplot(122);imshow(uint8(I2)); title('分类结果图');
end
toc