一、选题背景
当今时代智能化发展迅速,各种电子产品层出不穷,人们逐渐从书店购买到网上购买,网上购物使人们更加方便,可以足不出户的购买自己想要的物品,利用爬虫爬取当当网上图书销量排名,然后使用可视化分析,分析人们偏爱的图书价位、风格、出版社等。
二、大数据分析方案:
通过爬取当当网图书销量排行、评分、单价、作者,图书名、推荐值等,分析出最受欢迎的图书是什么。爬取相关数据集,并使用python源代码让大家显明易懂该文章所表述内容
三、数据分析的实现步骤:
数据源:https://category.dangdang.com/cp01.00.00.00.00.00-srsort_sale_amt_desc.html
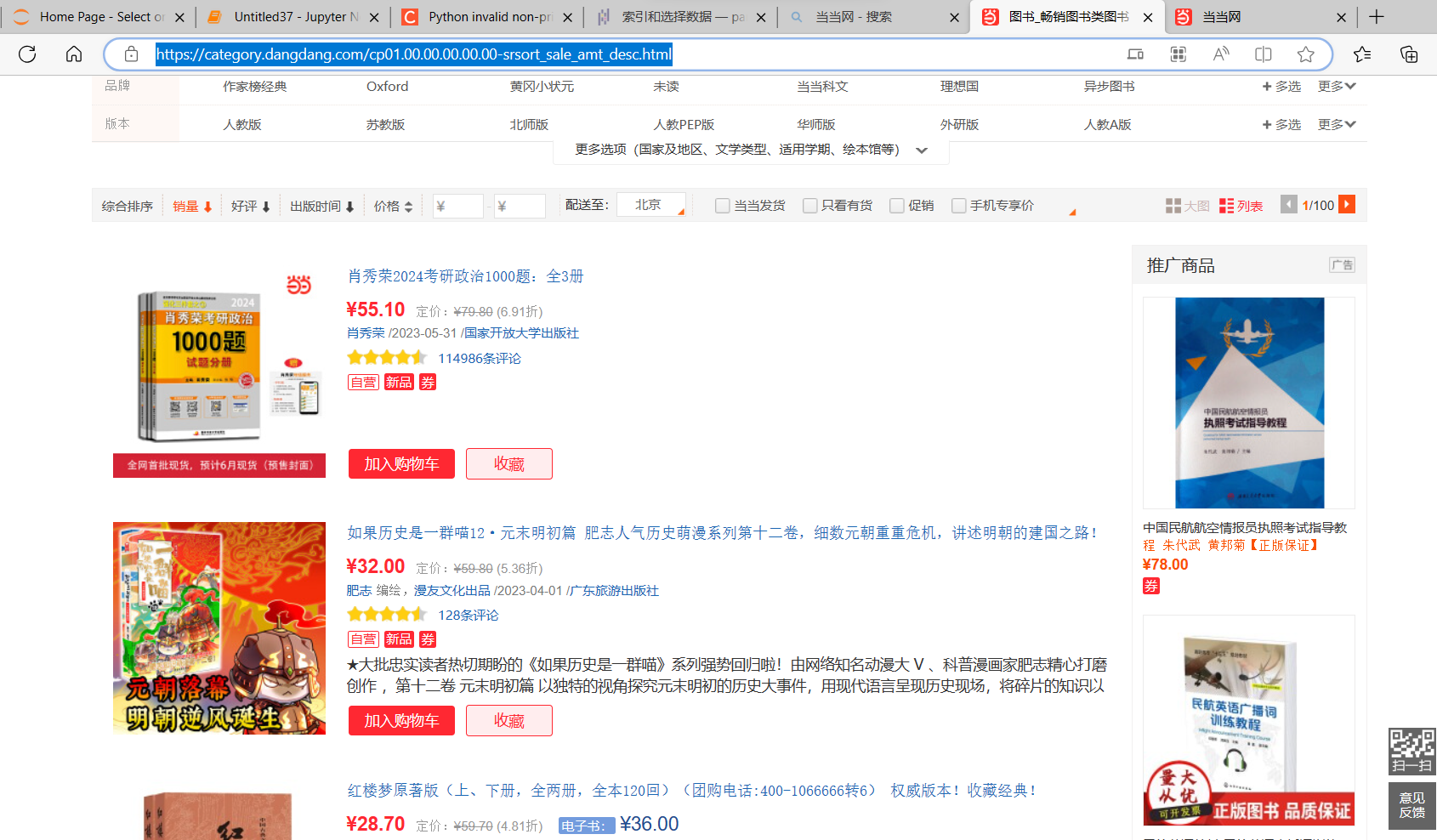
(一)数据爬取
1、导入相关数据模块
import requests # 数据请求模块 第三方模块 需要 pip install requests
import parsel # 数据解析模块 第三方模块 需要 pip install parsel
import csv # 保存csv表格数据模块 内置模块
import time # 时间模块
2、发送请求,使用python代码 headers请求
url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-{page}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
response = requests.get(url=url, headers=headers)

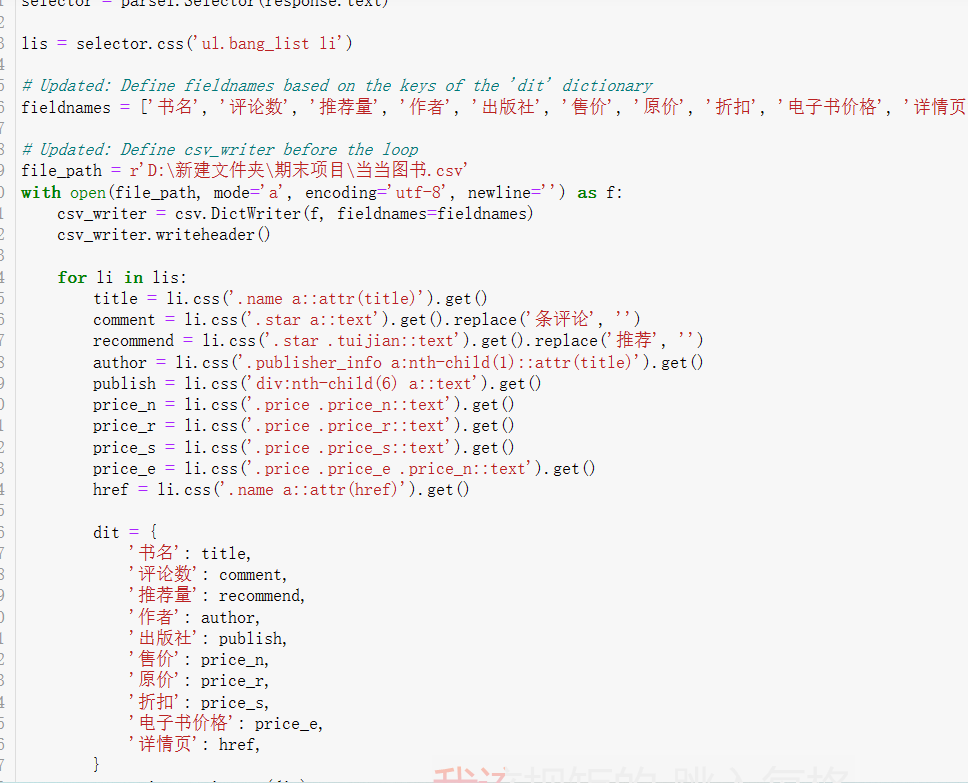
3、解析数据,提取我们想要的数据内容
selector = parsel.Selector(response.text)
lis = selector.css('ul.bang_list li')
# Updated: Define fieldnames based on the keys of the 'dit' dictionary
fieldnames = ['书名', '评论数', '推荐量', '作者', '出版社', '售价', '原价', '折扣', '电子书价格', '详情页']
# Updated: Define csv_writer before the loop
file_path = r'D:\新建文件夹\期末项目\当当图书.csv'
with open(file_path, mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.DictWriter(f, fieldnames=fieldnames)
csv_writer.writeheader()
for li in lis:
title = li.css('.name a::attr(title)').get()
comment = li.css('.star a::text').get().replace('条评论', '')
recommend = li.css('.star .tuijian::text').get().replace('推荐', '')
author = li.css('.publisher_info a:nth-child(1)::attr(title)').get()
publish = li.css('div:nth-child(6) a::text').get()
price_n = li.css('.price .price_n::text').get()
price_r = li.css('.price .price_r::text').get()
price_s = li.css('.price .price_s::text').get()
price_e = li.css('.price .price_e .price_n::text').get()
href = li.css('.name a::attr(href)').get()
dit = {
'书名': title,
'评论数': comment,
'推荐量': recommend,
'作者': author,
'出版社': publish,
'售价': price_n,
'原价': price_r,
'折扣': price_s,
'电子书价格': price_e,
'详情页': href,
}
csv_writer.writerow(dit)
print(title, comment, recommend, author, publish, price_n, price_r, price_s, price_e, href, sep=' | ')
4、多页爬取
for page in range(1, 26):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1.5)url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-{page}'

5、保存数据,并存储为.csv文件
# Updated file path
file_path = r'D:\新建文件夹\期末项目\当当图书.csv'
with open(file_path, mode='a', encoding='utf-8', newline='') as f:
csv_writer=csv.DictWriter(f,fieldnames=dit.keys())
csv_writer.writeheader()

运行结果:

(二)数据可视化
1、引入模块
import pandas as pd
from pyecharts.charts import *
from pyecharts.globals import ThemeType#设定主题
from pyecharts.commons.utils import JsCode
import pyecharts.options as opts
2、导入数据
df = pd.read_csv('当当图书.csv', encoding='utf-8', engine='python')
df.head()

结果:
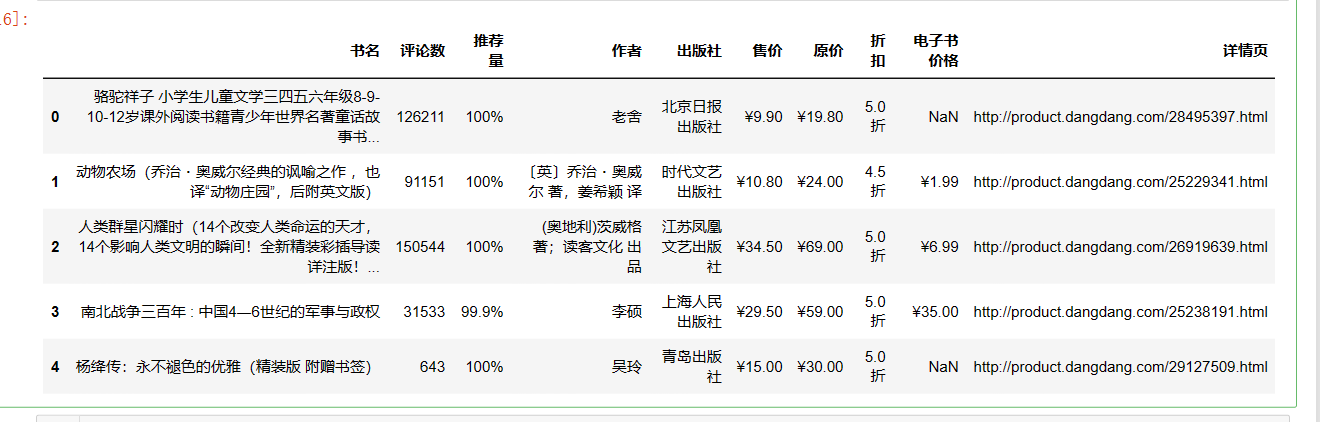
3、数据可视化
from pyecharts.charts import Pie
from pyecharts import options as opts
# Sample data for demonstration
datas_pair_1 = [("0-30", 20), ("30-70", 60), ("70-150", 10),("150-300",10)]
pie1 = (
Pie(init_opts=opts.InitOpts(theme='dark', width='1000px', height='600px'))
.add('', datas_pair_1, radius=['35%', '60%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="当当网书籍\n\n原价价格区间",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#F0F8FF',
font_size=20,
font_weight='bold'
),
)
)
.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook(
结果:
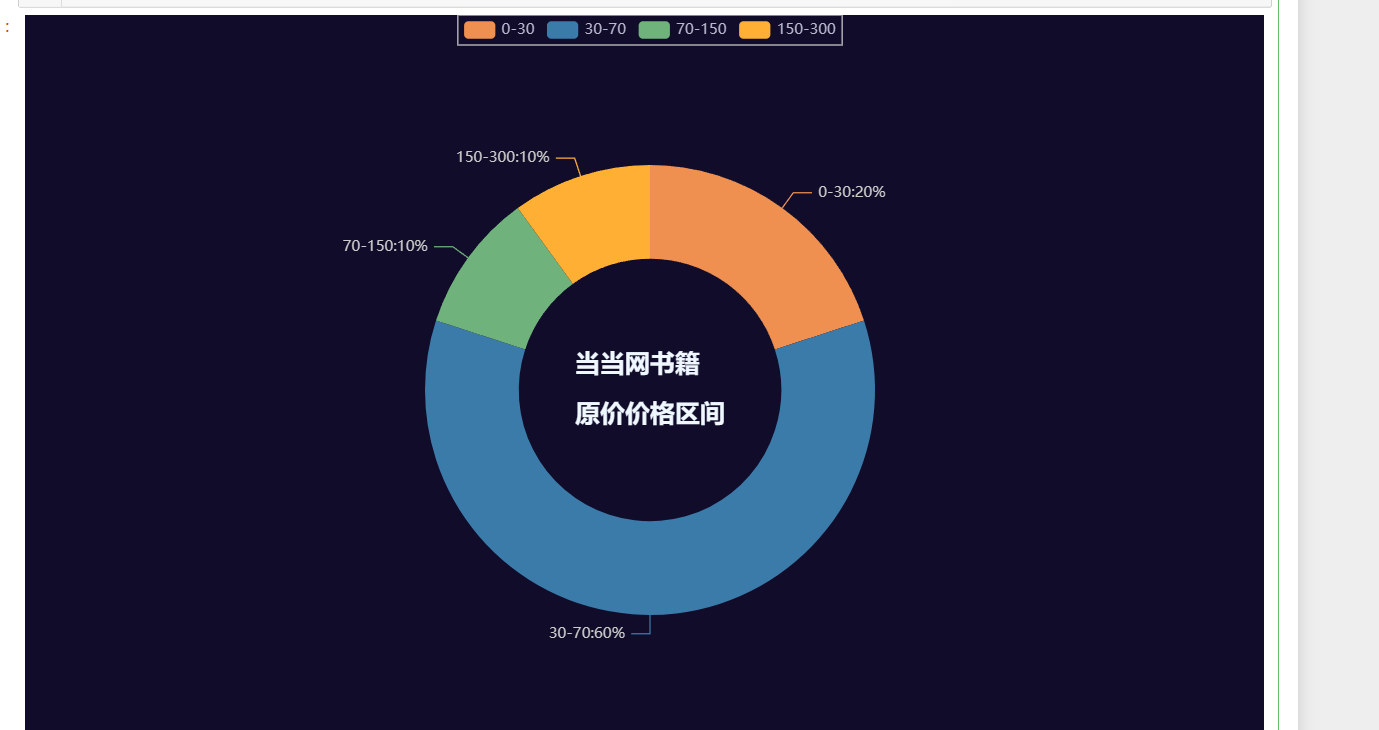
4、分析价格最高的图书
import pandas as pd
# Assuming you have a DataFrame with book data, you can define the 'data' variable like this:
data = pd.DataFrame({
'书名': ['骆驼祥子 小学生儿童文学三四五六年级8-9-10-12岁课外阅读书籍青少年世界名著童话故事书彩图美绘版',
'动物农场(乔治・奥威尔经典的讽喻之作 ,也译“动物庄园”,后附英文版)',
'人类群星闪耀时(14个改变人类命运的天才,14个影响人类文明的瞬间!全新精装彩插导读详注版!)(读客经典文库)',
'南北战争三百年 : 中国4―6世纪的军事与政权',
'杨绛传:永不褪色的优雅(精装版 附赠书签)',
'人生哪能多如意,万事只求半称心(弘一法师人生智慧的精粹,写给每一个在生活中抱有缺憾却依旧前行的人!)',
'原生家庭:如何修补自己的性格缺陷',
'月亮和六便士(又译作月亮与六便士,导读详注完整无删版,央视新闻推荐李继宏译本,精装)【果麦经典】',
'莎士比亚十四行诗(巴别塔诗典系列-精装本)',
'绝叫(罗翔推荐,某瓣年度推理TOP.I现象级真神作,8.9分几十万读者动情好评,女性生存困境样本文学,《一个贫穷的年轻人》同系列好书)',
'小巴掌童话注音版8册百篇张秋生著 小学生课外读本',
'三体(精装纪念版)',
'四五快读 全彩图升级版――幼儿快速识字阅读法(全8册)(让孩子爱上阅读 快乐识字)[精选套装]',
'一个陌生女人的来信(茨威格中短篇小说选,豆瓣9.4高评分译作,德文直译无删节)',
'明朝那些事儿增补版.第1部(2021版)(当当专供)',
'阅读是一座随身携带的避难所(罗翔推荐版本。“阅读应该是愉悦的,怎么思考就有怎么样的人生”。)',
'我妈妈的手提包(点读版)',
'断舍离(2019新版,全新修订50%以上内容)宫崎骏、张德芬、李冰冰的减法哲学',
'张素芳小儿推拿技法图谱(汉竹)',
'秘密(经典身心灵励志读物,为人生带来喜悦转变的能量之书,“吸引力法则”三部曲扛鼎之作。)'],
'单价': [9.9, 10.8,34.5,29.5,15, 35.7, 23.8,24,24.7,29,43.1,193.1,145.8,9.9,32.4,21,57.6,21.6,22.9, 25.9]
})
# Sort the data by price in descending order
data = data.sort_values(by='单价', ascending=False)
# Rest of your code
bar = (
Bar(init_opts=opts.InitOpts(height='500px', width='1000px', theme='dark'))
.add_xaxis(data['书名'].tolist())
.add_yaxis(
'书籍单价',
data['单价'].tolist(),
label_opts=opts.LabelOpts(is_show=True, position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='书籍单价柱状图'
),
xaxis_opts=opts.AxisOpts(
name='书籍名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90)
),
yaxis_opts=opts.AxisOpts(
name='单价/元',
min_=0,
max_=max(data['单价']),
splitline_opts=opts.SplitLineOpts(is_show=True, linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis', axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average', name='均值'),
opts.MarkLineItem(type_='max', name='最大值'),
opts.MarkLineItem(type_='min', name='最小值')
]
)
)
)
bar.render_notebook()
结果:
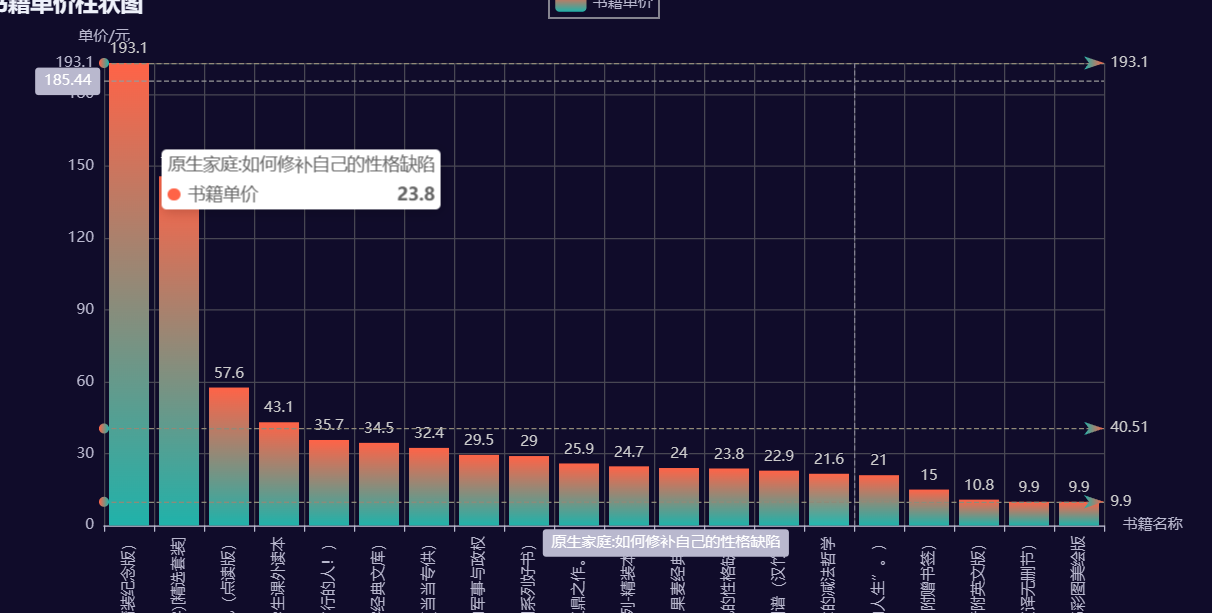
5、通过分析评论最高值,判断最受欢迎的读物
import pandas as pd
# Assuming you have a DataFrame with book data, you can define the 'data' variable like this:
data = pd.DataFrame({
'书名': ['骆驼祥子 小学生儿童文学三四五六年级8-9-10-12岁课外阅读书籍青少年世界名著童话故事书彩图美绘版',
'动物农场(乔治・奥威尔经典的讽喻之作 ,也译“动物庄园”,后附英文版)',
'人类群星闪耀时(14个改变人类命运的天才,14个影响人类文明的瞬间!全新精装彩插导读详注版!)(读客经典文库)',
'南北战争三百年 : 中国4―6世纪的军事与政权',
'杨绛传:永不褪色的优雅(精装版 附赠书签)',
'人生哪能多如意,万事只求半称心(弘一法师人生智慧的精粹,写给每一个在生活中抱有缺憾却依旧前行的人!)',
'原生家庭:如何修补自己的性格缺陷',
'月亮和六便士(又译作月亮与六便士,导读详注完整无删版,央视新闻推荐李继宏译本,精装)【果麦经典】',
'莎士比亚十四行诗(巴别塔诗典系列-精装本)',
'绝叫(罗翔推荐,某瓣年度推理TOP.I现象级真神作,8.9分几十万读者动情好评,女性生存困境样本文学,《一个贫穷的年轻人》同系列好书)',
'小巴掌童话注音版8册百篇张秋生著 小学生课外读本',
'三体(精装纪念版)',
'四五快读 全彩图升级版――幼儿快速识字阅读法(全8册)(让孩子爱上阅读 快乐识字)[精选套装]',
'一个陌生女人的来信(茨威格中短篇小说选,豆瓣9.4高评分译作,德文直译无删节)',
'明朝那些事儿增补版.第1部(2021版)(当当专供)',
'阅读是一座随身携带的避难所(罗翔推荐版本。“阅读应该是愉悦的,怎么思考就有怎么样的人生”。)',
'我妈妈的手提包(点读版)',
'断舍离(2019新版,全新修订50%以上内容)宫崎骏、张德芬、李冰冰的减法哲学',
'张素芳小儿推拿技法图谱(汉竹)',
'秘密(经典身心灵励志读物,为人生带来喜悦转变的能量之书,“吸引力法则”三部曲扛鼎之作。)'],
'评论数': [126211,91151 ,150544,31533,643,19320,165045,168221,2319,101118,343267,96138,521805,213423,17129,88324,46819,388799,35220, 251355]
})
# Sort the data by price in descending order
data = data.sort_values(by='评论数', ascending=False)
# Rest of your code
bar = (
Bar(init_opts=opts.InitOpts(height='500px', width='1000px', theme='dark'))
.add_xaxis(data['书名'].tolist())
.add_yaxis(
'书籍评论数',
data['评论数'].tolist(),
label_opts=opts.LabelOpts(is_show=True, position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='书籍评论数柱状图'
),
xaxis_opts=opts.AxisOpts(
name='书籍名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90)
),
yaxis_opts=opts.AxisOpts(
name='评论数',
min_=0,
max_=max(data['评论数']),
splitline_opts=opts.SplitLineOpts(is_show=True, linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis', axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average', name='均值'),
opts.MarkLineItem(type_='max', name='最大值'),
opts.MarkLineItem(type_='min', name='最小值')
]
)
)
)
bar.render_notebook()
结果:
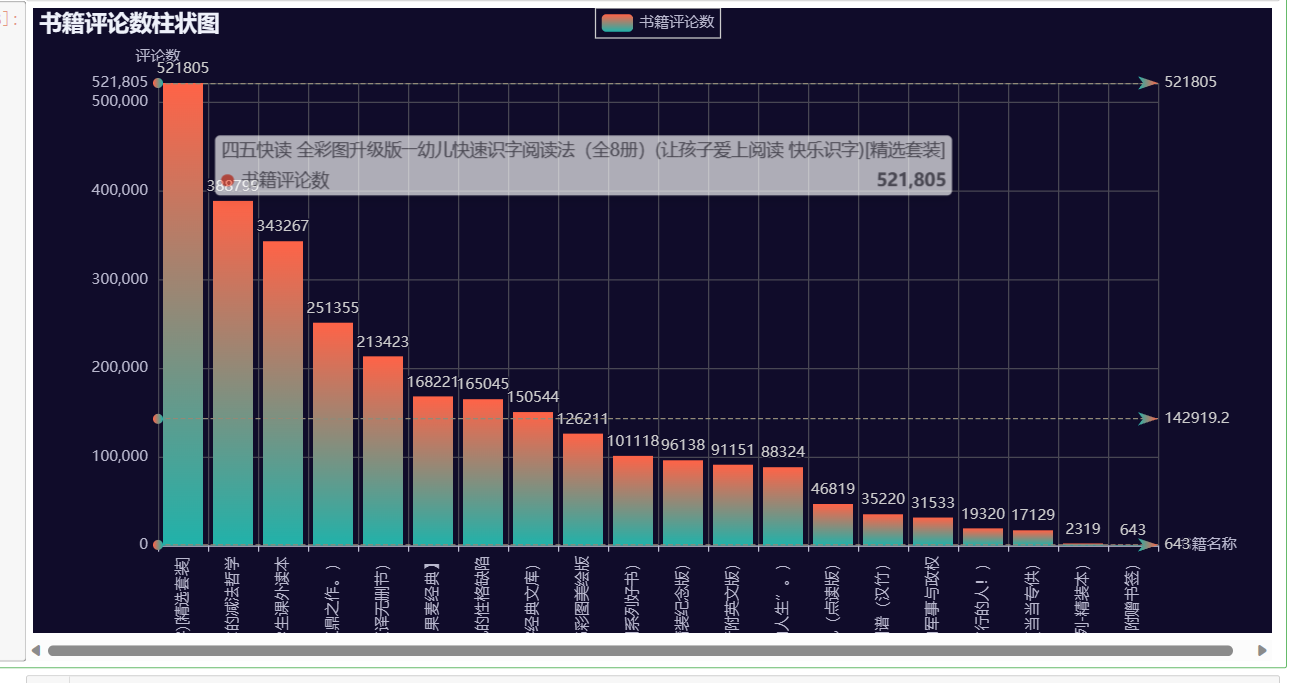
通过分析图可得知,最受欢迎的读物为《四五快读 全彩图升级版――幼儿快速识字阅读法(全8册)(让孩子爱上阅读 快乐识字)[精选套装]》
完整代码:
import requests
import parsel
import csv
import time
url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-{page}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('ul.bang_list li')
# Updated: Define fieldnames based on the keys of the 'dit' dictionary
fieldnames = ['书名', '评论数', '推荐量', '作者', '出版社', '售价', '原价', '折扣', '电子书价格', '详情页']
# Updated: Define csv_writer before the loop
file_path = r'D:\新建文件夹\期末项目\当当图书.csv'
with open(file_path, mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.DictWriter(f, fieldnames=fieldnames)
csv_writer.writeheader()
for li in lis:
title = li.css('.name a::attr(title)').get()
comment = li.css('.star a::text').get().replace('条评论', '')
recommend = li.css('.star .tuijian::text').get().replace('推荐', '')
author = li.css('.publisher_info a:nth-child(1)::attr(title)').get()
publish = li.css('div:nth-child(6) a::text').get()
price_n = li.css('.price .price_n::text').get()
price_r = li.css('.price .price_r::text').get()
price_s = li.css('.price .price_s::text').get()
price_e = li.css('.price .price_e .price_n::text').get()
href = li.css('.name a::attr(href)').get()
dit = {
'书名': title,
'评论数': comment,
'推荐量': recommend,
'作者': author,
'出版社': publish,
'售价': price_n,
'原价': price_r,
'折扣': price_s,
'电子书价格': price_e,
'详情页': href,
}
csv_writer.writerow(dit)
print(title, comment, recommend, author, publish, price_n, price_r, price_s, price_e, href, sep=' | ')
for page in range(1, 26):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1.5)
url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-{page}'
# Updated file path
file_path = r'D:\新建文件夹\期末项目\当当图书.csv'
with open(file_path, mode='a', encoding='utf-8', newline='') as f:
csv_writer=csv.DictWriter(f,fieldnames=dit.keys())
csv_writer.writeheader()
#数据导入
import pandas as pd
from pyecharts.charts import *
from pyecharts.globals import ThemeType#设定主题
from pyecharts.commons.utils import JsCode
import pyecharts.options as opts
df = pd.read_csv('当当图书.csv', encoding='utf-8', engine='python')
df.head()
#数据可视化
from pyecharts.charts import Pie
from pyecharts import options as opts
# Sample data for demonstration
datas_pair_1 = [("0-30", 20), ("30-70", 60), ("70-150", 10),("150-300",10)]
pie1 = (
Pie(init_opts=opts.InitOpts(theme='dark', width='1000px', height='600px'))
.add('', datas_pair_1, radius=['35%', '60%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="当当网书籍\n\n原价价格区间",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#F0F8FF',
font_size=20,
font_weight='bold'
),
)
)
.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()
#分析单价最高
import pandas as pd
# Assuming you have a DataFrame with book data, you can define the 'data' variable like this:
data = pd.DataFrame({
'书名': ['骆驼祥子 小学生儿童文学三四五六年级8-9-10-12岁课外阅读书籍青少年世界名著童话故事书彩图美绘版',
'动物农场(乔治・奥威尔经典的讽喻之作 ,也译“动物庄园”,后附英文版)',
'人类群星闪耀时(14个改变人类命运的天才,14个影响人类文明的瞬间!全新精装彩插导读详注版!)(读客经典文库)',
'南北战争三百年 : 中国4―6世纪的军事与政权',
'杨绛传:永不褪色的优雅(精装版 附赠书签)',
'人生哪能多如意,万事只求半称心(弘一法师人生智慧的精粹,写给每一个在生活中抱有缺憾却依旧前行的人!)',
'原生家庭:如何修补自己的性格缺陷',
'月亮和六便士(又译作月亮与六便士,导读详注完整无删版,央视新闻推荐李继宏译本,精装)【果麦经典】',
'莎士比亚十四行诗(巴别塔诗典系列-精装本)',
'绝叫(罗翔推荐,某瓣年度推理TOP.I现象级真神作,8.9分几十万读者动情好评,女性生存困境样本文学,《一个贫穷的年轻人》同系列好书)',
'小巴掌童话注音版8册百篇张秋生著 小学生课外读本',
'三体(精装纪念版)',
'四五快读 全彩图升级版――幼儿快速识字阅读法(全8册)(让孩子爱上阅读 快乐识字)[精选套装]',
'一个陌生女人的来信(茨威格中短篇小说选,豆瓣9.4高评分译作,德文直译无删节)',
'明朝那些事儿增补版.第1部(2021版)(当当专供)',
'阅读是一座随身携带的避难所(罗翔推荐版本。“阅读应该是愉悦的,怎么思考就有怎么样的人生”。)',
'我妈妈的手提包(点读版)',
'断舍离(2019新版,全新修订50%以上内容)宫崎骏、张德芬、李冰冰的减法哲学',
'张素芳小儿推拿技法图谱(汉竹)',
'秘密(经典身心灵励志读物,为人生带来喜悦转变的能量之书,“吸引力法则”三部曲扛鼎之作。)'],
'单价': [9.9, 10.8,34.5,29.5,15, 35.7, 23.8,24,24.7,29,43.1,193.1,145.8,9.9,32.4,21,57.6,21.6,22.9, 25.9]
})
# Sort the data by price in descending order
data = data.sort_values(by='单价', ascending=False)
# Rest of your code
bar = (
Bar(init_opts=opts.InitOpts(height='500px', width='1000px', theme='dark'))
.add_xaxis(data['书名'].tolist())
.add_yaxis(
'书籍单价',
data['单价'].tolist(),
label_opts=opts.LabelOpts(is_show=True, position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='书籍单价柱状图'
),
xaxis_opts=opts.AxisOpts(
name='书籍名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90)
),
yaxis_opts=opts.AxisOpts(
name='单价/元',
min_=0,
max_=max(data['单价']),
splitline_opts=opts.SplitLineOpts(is_show=True, linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis', axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average', name='均值'),
opts.MarkLineItem(type_='max', name='最大值'),
opts.MarkLineItem(type_='min', name='最小值')
]
)
)
)
bar.render_notebook()
#分析评论数量
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
# Sample data for demonstration
data = pd.DataFrame({
'书名': ['骆驼祥子 小学生儿童文学三四五六年级8-9-10-12岁课外阅读书籍青少年世界名著童话故事书彩图美绘版',
'动物农场(乔治・奥威尔经典的讽喻之作 ,也译“动物庄园”,后附英文版)',
'人类群星闪耀时(14个改变人类命运的天才,14个影响人类文明的瞬间!全新精装彩插导读详注版!)(读客经典文库)',
'南北战争三百年 : 中国4―6世纪的军事与政权',
'杨绛传:永不褪色的优雅(精装版 附赠书签)',
'人生哪能多如意,万事只求半称心(弘一法师人生智慧的精粹,写给每一个在生活中抱有缺憾却依旧前行的人!)',
'原生家庭:如何修补自己的性格缺陷',
'月亮和六便士(又译作月亮与六便士,导读详注完整无删版,央视新闻推荐李继宏译本,精装)【果麦经典】',
'莎士比亚十四行诗(巴别塔诗典系列-精装本)',
'绝叫(罗翔推荐,某瓣年度推理TOP.I现象级真神作,8.9分几十万读者动情好评,女性生存困境样本文学,《一个贫穷的年轻人》同系列好书)',
'小巴掌童话注音版8册百篇张秋生著 小学生课外读本',
'三体(精装纪念版)',
'四五快读 全彩图升级版――幼儿快速识字阅读法(全8册)(让孩子爱上阅读 快乐识字)[精选套装]',
'一个陌生女人的来信(茨威格中短篇小说选,豆瓣9.4高评分译作,德文直译无删节)',
'明朝那些事儿增补版.第1部(2021版)(当当专供)',
'阅读是一座随身携带的避难所(罗翔推荐版本。“阅读应该是愉悦的,怎么思考就有怎么样的人生”。)',
'我妈妈的手提包(点读版)',
'断舍离(2019新版,全新修订50%以上内容)宫崎骏、张德芬、李冰冰的减法哲学',
'张素芳小儿推拿技法图谱(汉竹)',
'秘密(经典身心灵励志读物,为人生带来喜悦转变的能量之书,“吸引力法则”三部曲扛鼎之作。)'],
'评论数': [9.9, 10.8,34.5,29.5,15, 35.7, 23.8,24,24.7,29,43.1,193.1,145.8,9.9,32.4,21,57.6,21.6,22.9, 25.9]
})
counts = dict(zip(categories, values))
bar = (
Bar(init_opts=opts.InitOpts(height='500px', width='1000px', theme='dark'))
.add_xaxis(list(counts.keys()))
.add_yaxis(
'出版社书籍数量',
list(counts.values()),
label_opts=opts.LabelOpts(is_show=True, position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='各个出版社书籍数量柱状图'
),
xaxis_opts=opts.AxisOpts(
name='书籍名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90)
),
yaxis_opts=opts.AxisOpts(
name='数量',
min_=0,
max_=max(values),
splitline_opts=opts.SplitLineOpts(is_show=True, linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis', axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average', name='均值'),
opts.MarkLineItem(type_='max', name='最大值'),
opts.MarkLineItem(type_='min', name='最小值')
]
)
)
)
bar.render_notebook()
四、总结
对本课程设计的整体完成情况做一个总结,通过这次利用python代码爬虫爬取网站数据并分析,让我掌握了最基础的数据分析知识,体验了数据分析的乐趣,包括数据预处理,数据清洗,异常值的查找等,数据的合并和分组及聚合,还有数据可视化来直观的观察.分析数据。虽然学的不是很精通,部分代码还是需要借鉴下课本,网络。但在这次课程设计中还是学到了很多,不止是进一步的复习了课本上的知识内容,还学习了他人的代码思路并加以思考形成自己的思路。虽然作品仍有残缺不是很完美,但希望可以越来越进步