AbstractApplicatContext【refresh】
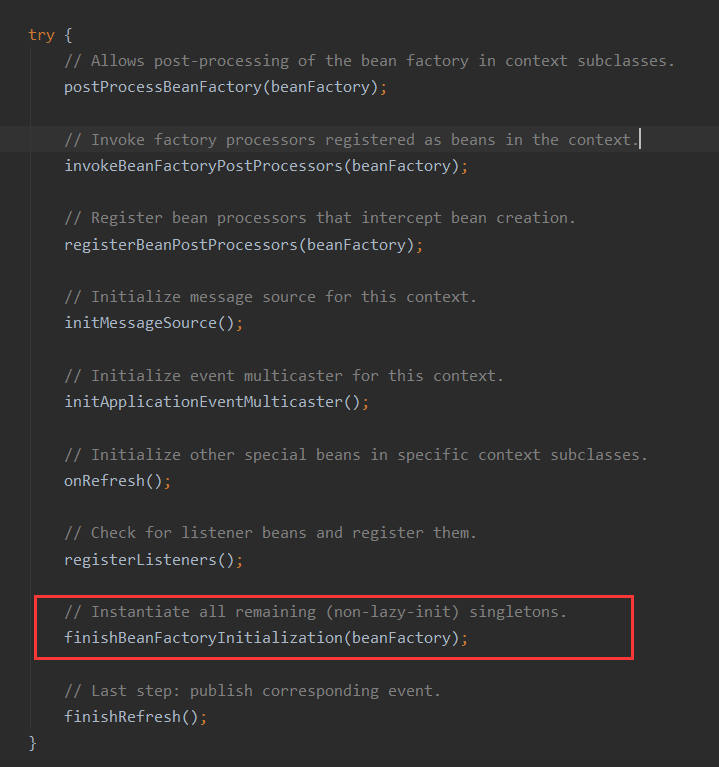
点击到该方法中,直接看到方法最后的 beanFactory.preInstantiateSingletons() 方法:

DefaultListableBeanFactory【preInstantiateSingletons】
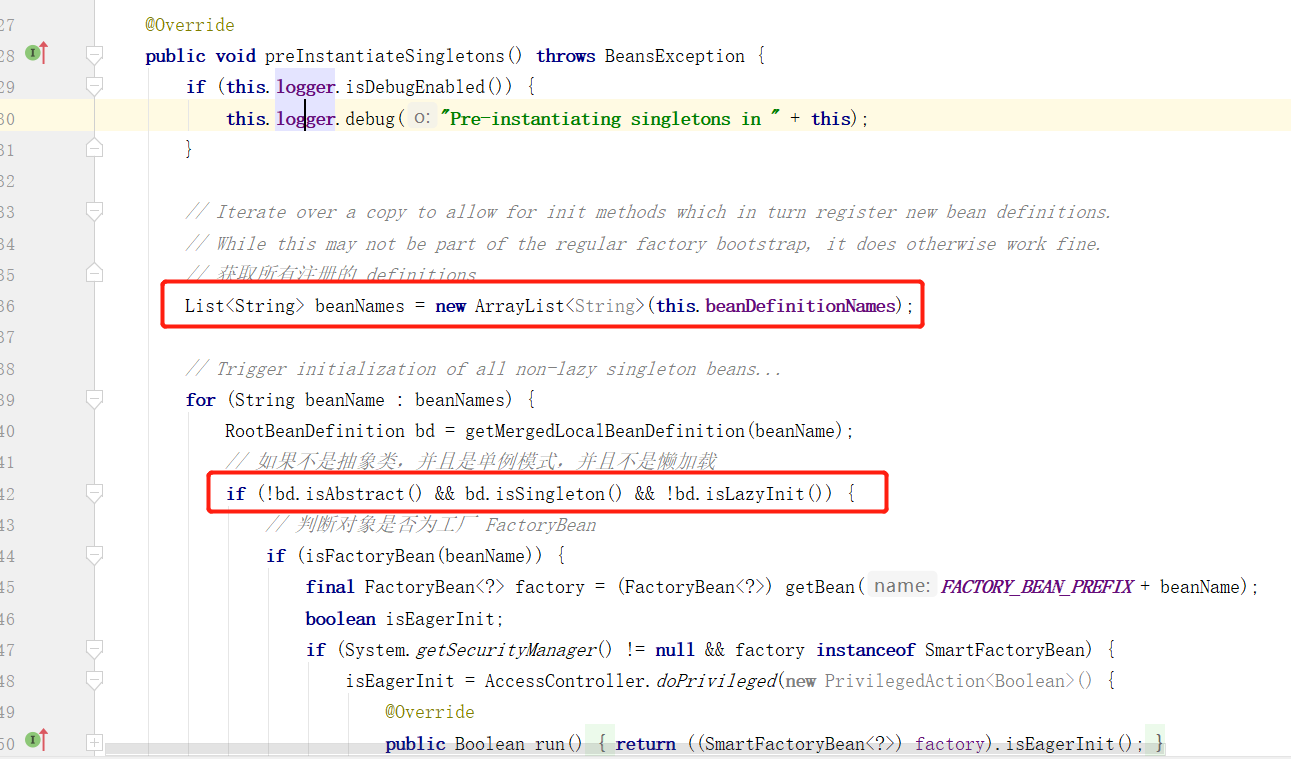
在 preInstantiateSingletons() 方法中,可以明显看到拿到了 beanDefinitionNames 列表,而这个列表则是存储所有注册的 beanDefinition 定义信息。
单例且非懒加载的bean定义才需要进行实例化。
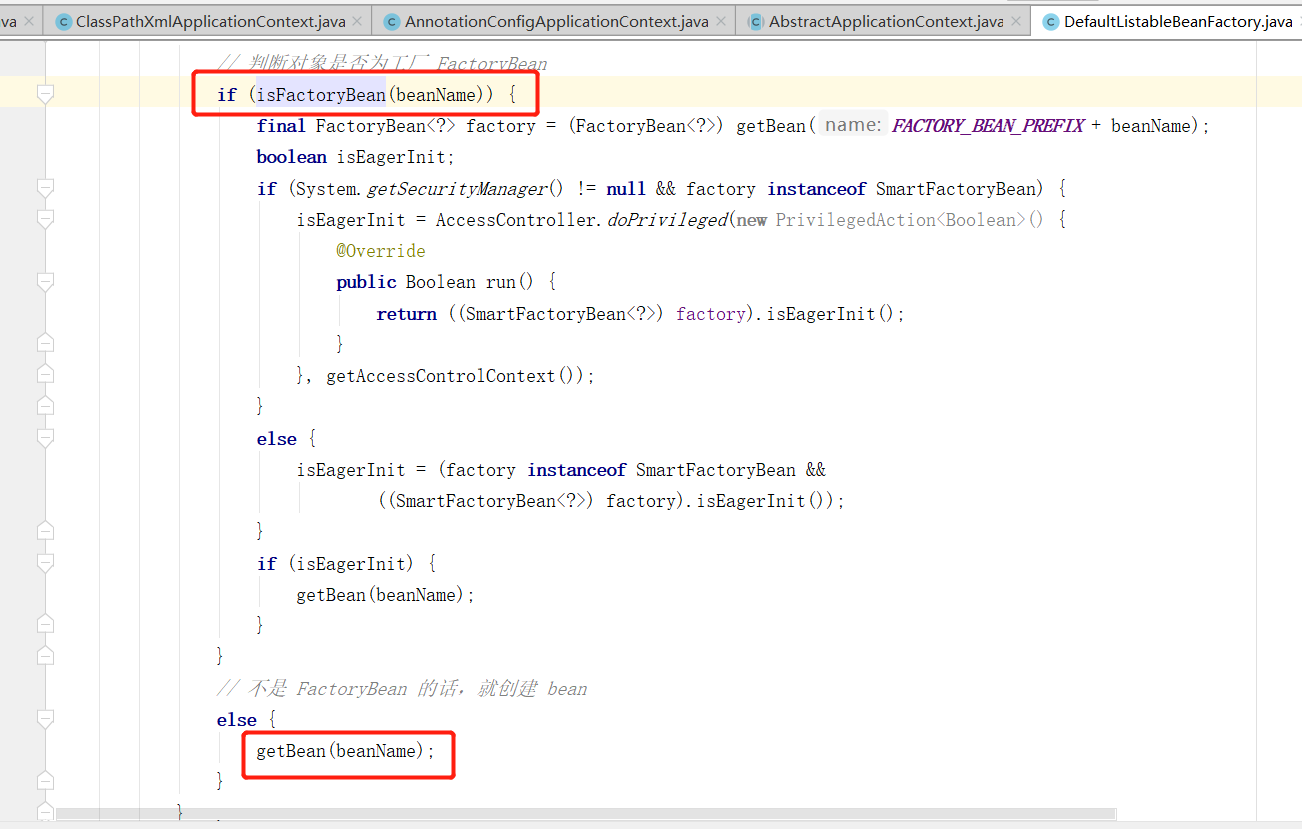
判断当前的 beanName 是否为 FactoryBean ,如果不是的话则使用 getBean(beanName) ,该方法调用的是AbstractBeanFactory 下的 getBean(beanName) 。

这里又调用了当前类的 doGetBean 方法。
ApplicationContext 的 getBean(String name)
当我们在使用 Spring 时,需要使用 bean 时,则一般都是通过 ApplicationContext 的 getBean(String name) 方法获取一个指定的对象。
那这个 getBean(String name) 方法和上面我们分析得到的 getBean(beanName) 是否为一个呢?
在 ApplicationContext 中并没有重写 getBean(String name) 方法,实际的 getBean(String name) 其实是调用的 AbstractApplicationContext下的 getBean(String name)。

在该方法中又使用了当前的 BeanFactory 中的 getBean(String name, Class<T> requiredType) 方法,那此时的 BeanFactory 是具体哪个子类呢?
其中 BeanFactory 默认是使用 DefaultListableBeanFactory,而 DefaultListableBeanFactory 并没有对 getBean(String name) 方法进行重写,那继续去父类 AbstractAutowireCapableBeanFactory 中找,也没有对 getBean(String name) 方法重写,继续向父类 AbstractBeanFactory 找,发现有 getBean(String name) 的重写。

看到这里是不是很有印象,和前面单例分析时调用了相同的方法进行初始化 bean , 那此时我们就可以得出结论不管是单例还是原型或者其他,最终都是使用的 AbstractBeanFactory 中的 getBean(String name) 方法初始并获取 bean 。
AbstractBeanFactory【doGetBean】

在 doGetBean 方法中,首先对传入的 name 进行转换,因为 name 可能是别名,需要转为 beanName 。
接着使用 getSingleton(String beanName) 方法获取该 beanName 的实例,如果实例不为空的话则使用该 bean 。
这里的 getSingleton(String beanName) 其实是在 DefaultSingletonBeanRegistry 类下,主要是从单例缓存中获取已经创建的对象,这里就使用到了经典的三级缓存。
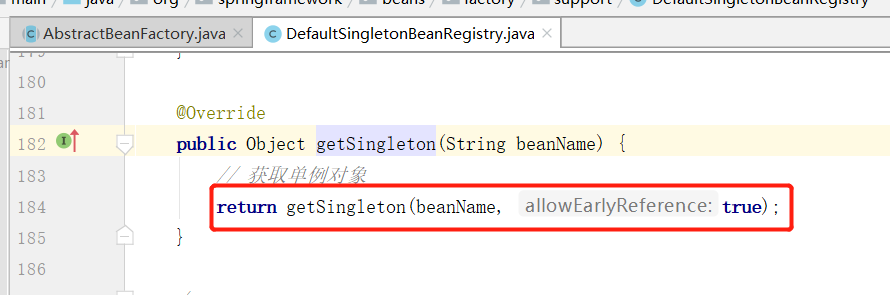
在该方法中又调用了当前类的 getSingleton(String beanName, boolean allowEarlyReference) 方法:
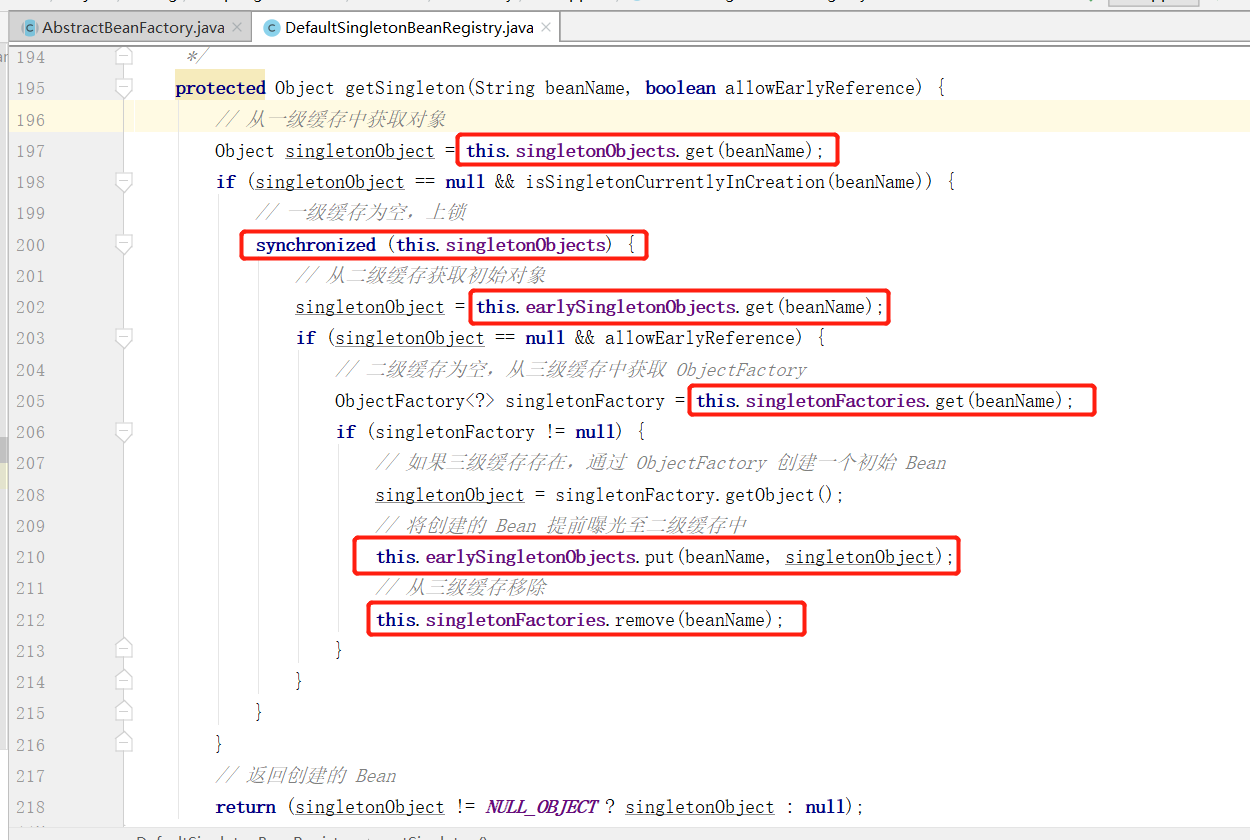
从该方法中可以明显看出,首先去 singletonObjects 容器获取对象,如果不存在的话再去 earlySingletonObjects 容器中获取对象,如果还不存在的话,则从 singletonFactories 容器中获取一个 ObjectFactory ,如果存在则可以通过 ObjectFactory 创建对象,最后将对象存放至 earlySingletonObjects 容器中,然后从singletonFactories 容器中移除。
这就是Spring解决循环依赖的方式,那什么是循环依赖呢?
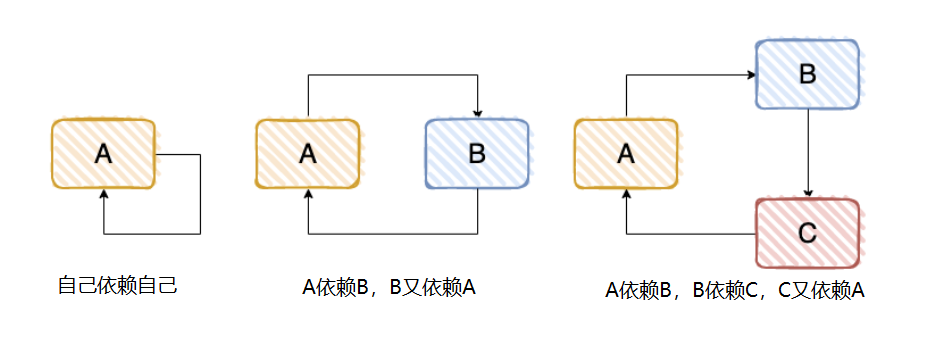
由于 Spring 在实例化对象时,会先去尝试创建其依赖的对象,这样就会出现 A 在创建中,发现依赖于 B,此时再去创建 B,而 B 又依赖于 A 再去尝试创建 A ,这种情况下不就陷入了死循环中,因此为了解决这种场景增加了多级缓存的概念。
多级缓存是哪几级呢,其实就是上面的 singletonObjects、earlySingletonObjects、singletonFactories 三个容器,分别对应着缓存的一二三级,这三个容器在 DefaultSingletonBeanRegistry 类中:
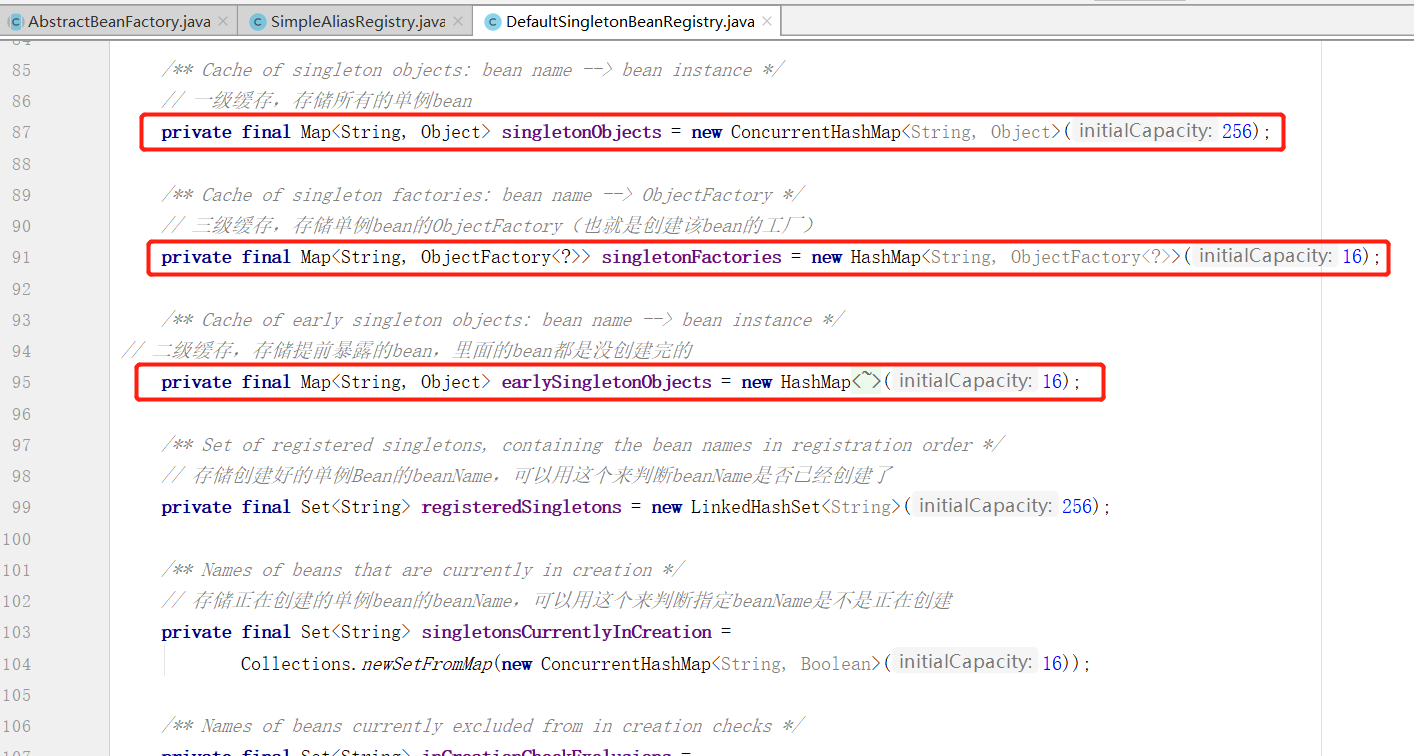
三级缓存具体是怎么使用的呢:
- 一级缓存:singletonObjects,存储所有的单例bean
- 二级缓存:earlySingletonObjects,存储提前暴露的bean,里面的bean都是没创建完的
- 三级缓存:singletonFactories,存储单例 bean的ObjectFactory(也就是创建该bean的工厂)
创建对象时首先会将创建 bean 的 ObjectFactory 暴露至三级缓存中,后面如果有依赖于该 bean 的则会先从一二三级缓存中挨个尝试取数据,直到拿到。如果是在三级缓存中存在,则通过 ObjectFactory获取一个早期的 bean 对象,并且放入二级缓存中,三级缓存中的移除,后面使用该早期的bean对象进行依赖注入。再到后面当该早期 bean 的依赖也被注入完成后,此时就是一个完整的对象了,需要从二级缓存中移除,放入一级缓存中,供上层使用。

如果从 getSingleton(String beanName) 中获取的实例为空,则缓存中不存在,那就要看如何进行实例化的了。
这里首先会判断是否原型模式下形成了循环依赖,如果是则抛出异常,因此这里可以得出 Spring 原型模式下不允许出现循环依赖。
AbstractBeanFactory【doGetBean】继续往下看:
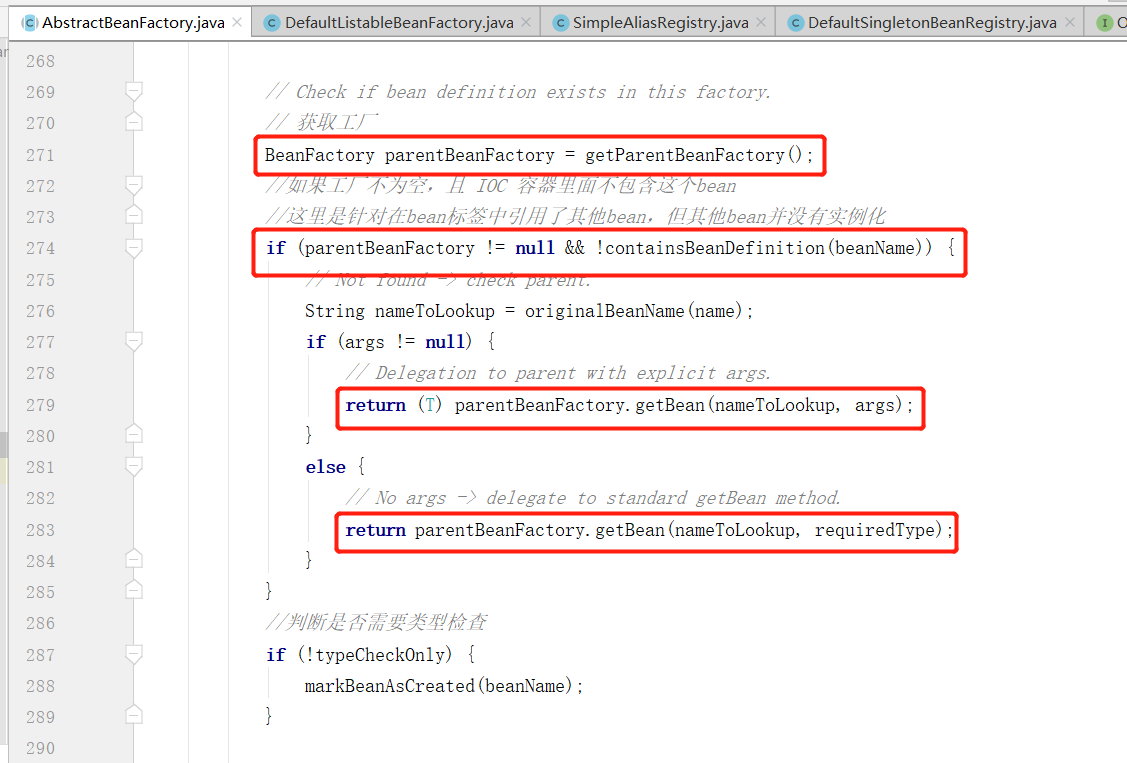
接着会获取到上级的 BeanFactory ,并且如果当前的 beanName 不在 beanDefinitionMap 容器中,则尝试用上级的 BeanFactory 进行获取 bean ,一般对于我们声明好的 bean 肯定都会存在于 beanDefinitionMap 容器中。
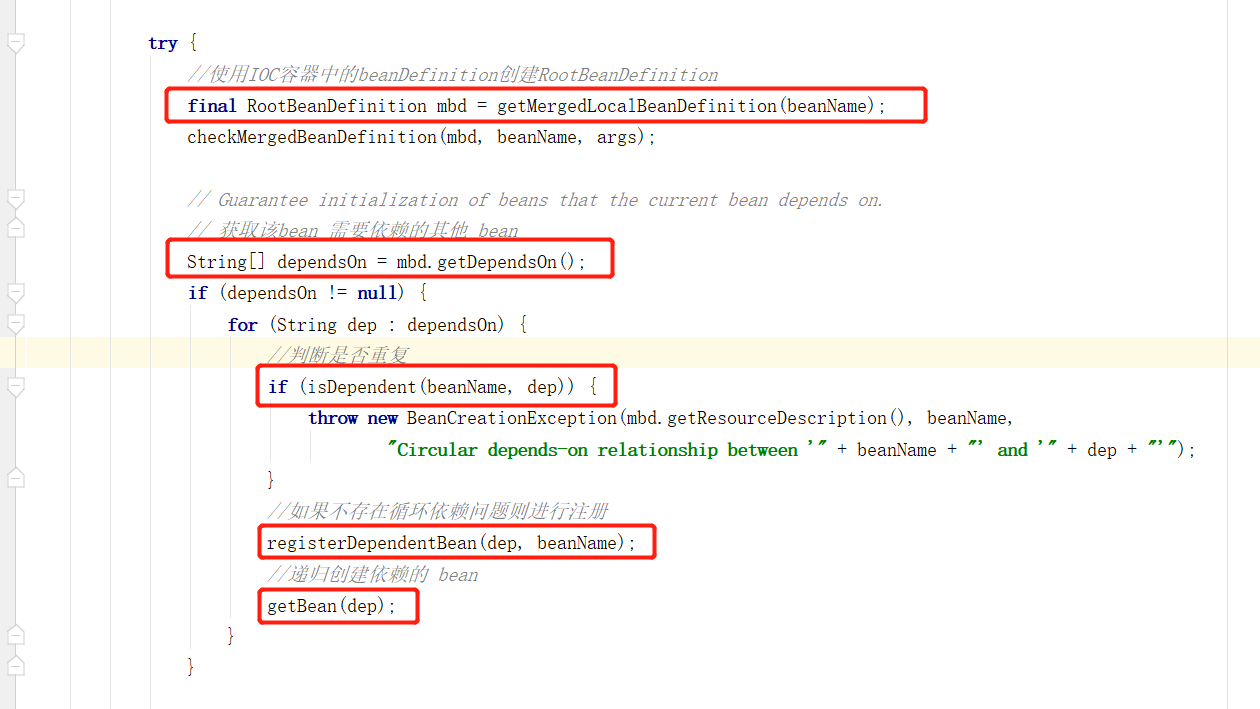
接着会根据 beanDefinitionMap 容器中的 BeanDefinition 创建一个 RootBeanDefinition ,然后会遍历全部的依赖,首先判断是否已经注册依赖了,主要判断 dependentBeanMap 容器中是否存在,如果不存在的话,则进行注册将该依赖加入到dependentBeanMap 中,最后递归的方式调用 getBean(String name) 创建依赖的对象。
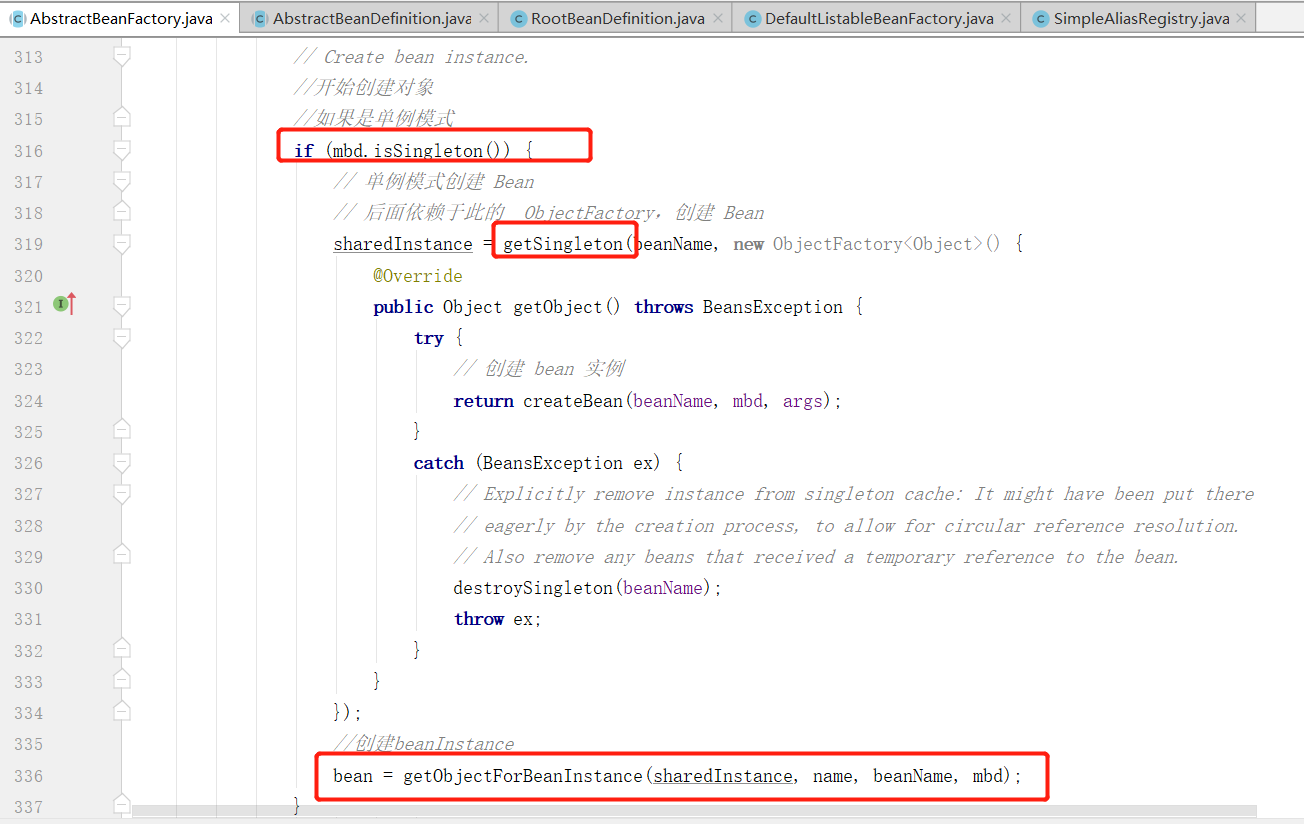
接着就要进行当前 bean 的创建工作了,首先如果是单例模式下,则使用 getSingleton(String beanName, ObjectFactory<?> singletonFactory) 方法获取实例对象,并传入一个 ObjectFactory 函数,其中 getSingleton 方法其实在 DefaultSingletonBeanRegistry下,进入到该方法中:
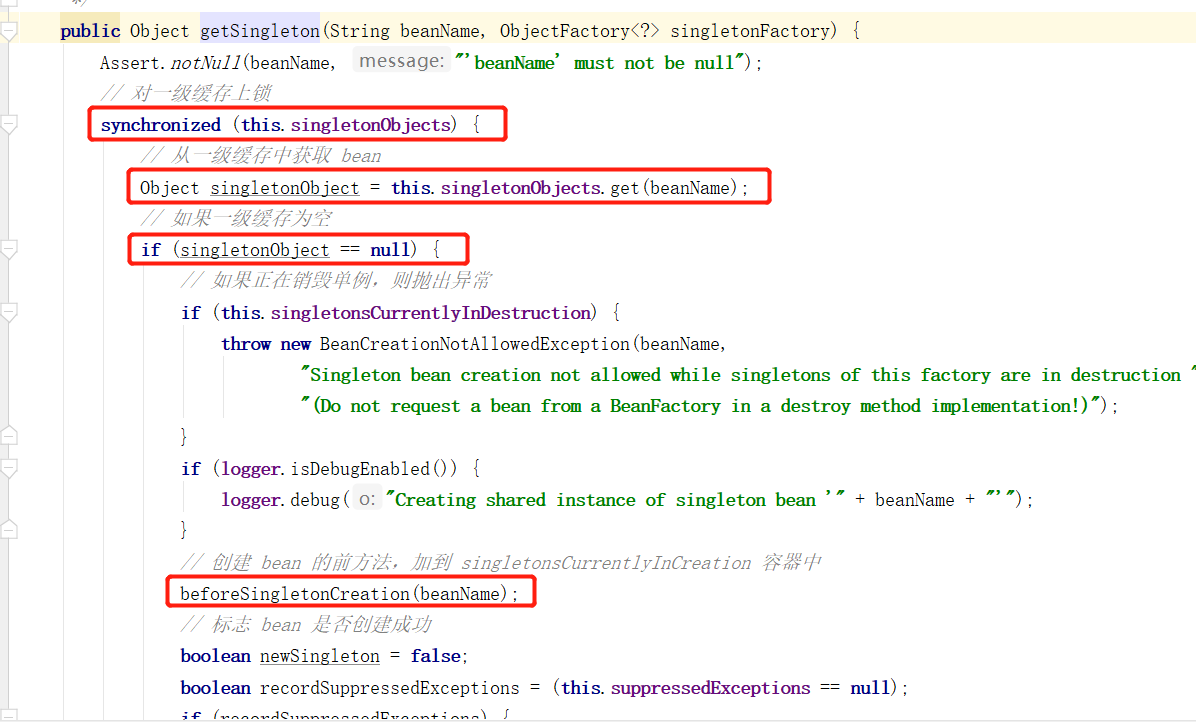
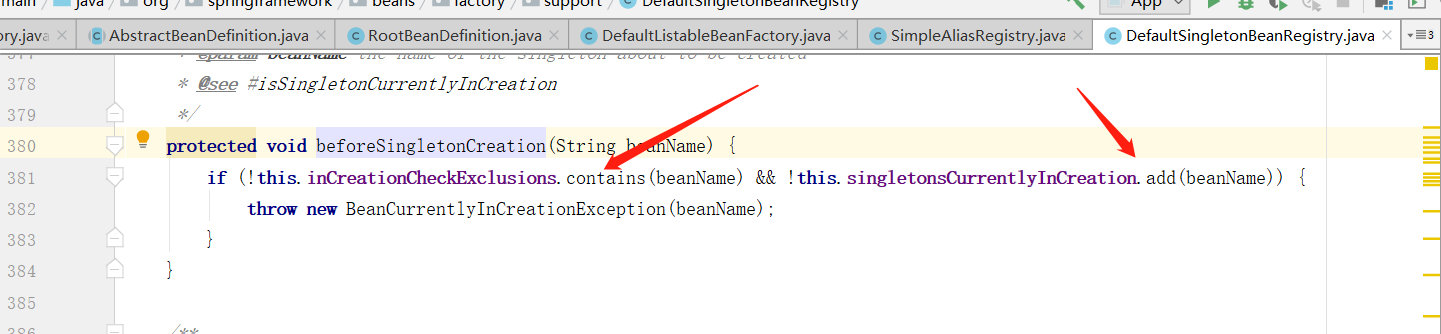
在该方法中首先对一级缓存进行上锁,然后再次尝试从一级缓存中获取对象,如果不存在的话,并且单例对象正在销毁的话则抛出异常,否则的话则执行创建 bean 的前方法,主要写入 singletonsCurrentlyInCreation 容器中,表示当前 bean 正在创建中。这个容器名称可以记一下,会在后面进行判断是否是创建中的 bean 。
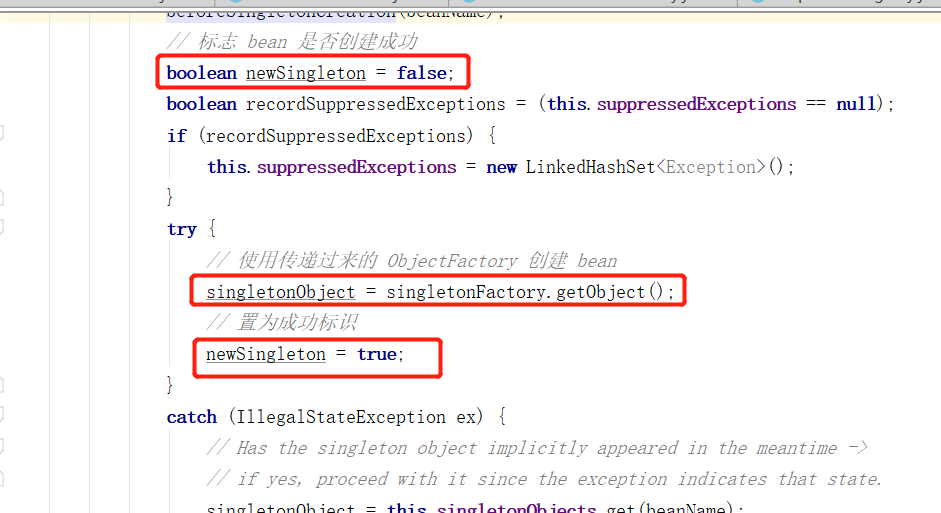
下面接着使用 newSingleton 作为创建对象的标记,可以看到当调用 singletonFactory.getObject() 成功后,则置为成功的标志,而 singletonFactory 则就是前面传递进来的 ObjectFactory,这里的 getObject() ,其实就是执行的 AbstractAutowireCapableBeanFactory 下的 createBean 方法,该方法可以放在后面分析,因为原型模式也是使用的 createBean 方法创建实例对象,后面可以一起分析,现在我们知道它是创建实例对象的就可以。
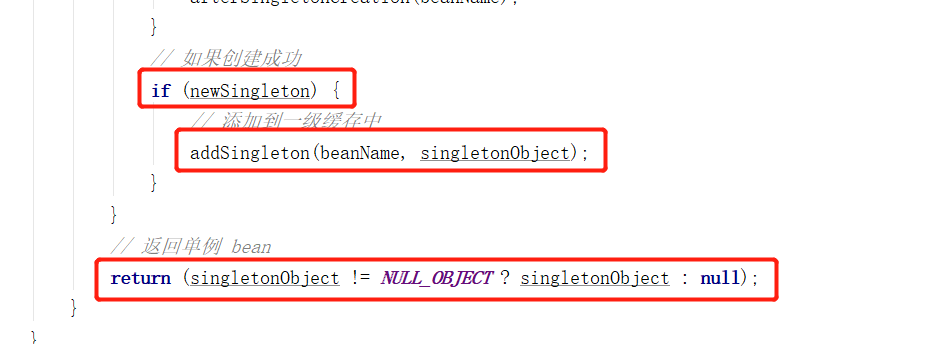
如果 newSingleton标记创建成功,则此时对象属于一个完整的对象,其中依赖注入已经在 createBean 方法中实现过了,这个时候需要写入到一级缓存中曝光出来。

在写入一级缓存时,首先对一级缓存加锁,然后写入一级缓存,并从二三级缓存移除,同时记录到已注册的单例列表中。
到此 getSingleton(String beanName, ObjectFactory<?> singletonFactory) 方法就走完了。
AbstractBeanFactory【doGetBean】继续往下看:

上面如果不是单例模式,再继续判断否为原型模式,如果是原型的,则先调用 beforePrototypeCreation(String beanName) 将 beanName 加入到 prototypesCurrentlyInCreation ThreadLocal 中,进入到该类中逻辑如下:
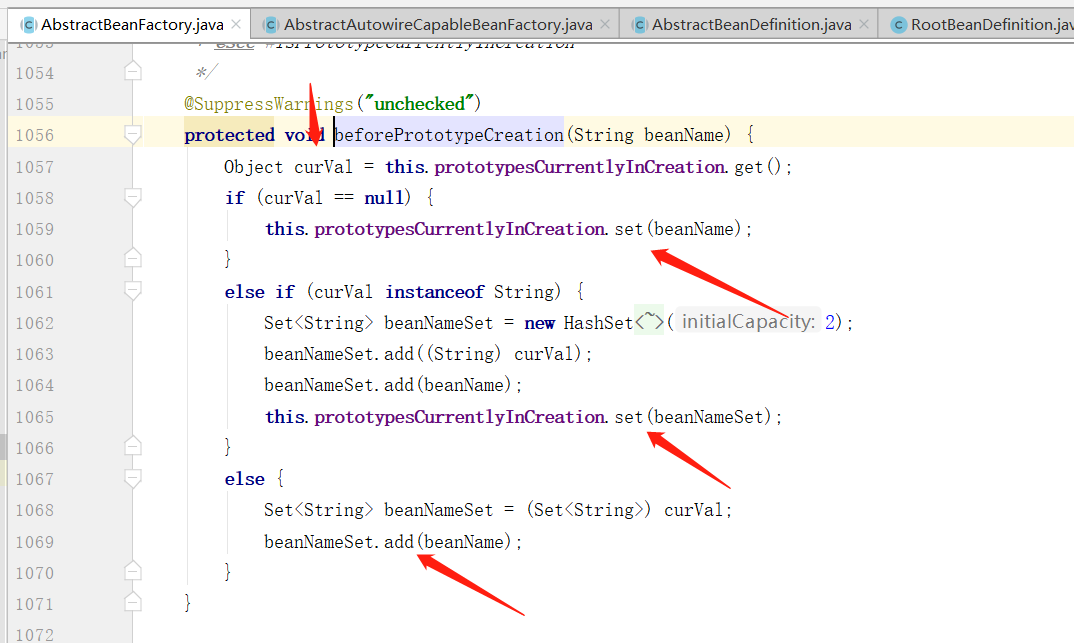
这里 prototypesCurrentlyInCreation ThreadLocal 正对应上前面原型模式下判断循环依赖。
原型模型和单例模式一样使用了 AbstractAutowireCapableBeanFactory 下的 createBean 方法创建实例,我们后面再分析。
创建完后,调用afterPrototypeCreation(String beanName) 方法,此时当前 bean 已经实例化好了,依赖注入同样在createBean 方法中已经完成了,下面就可以将 ThreadLoad 中记录的 beanName 移除了,逻辑如下:
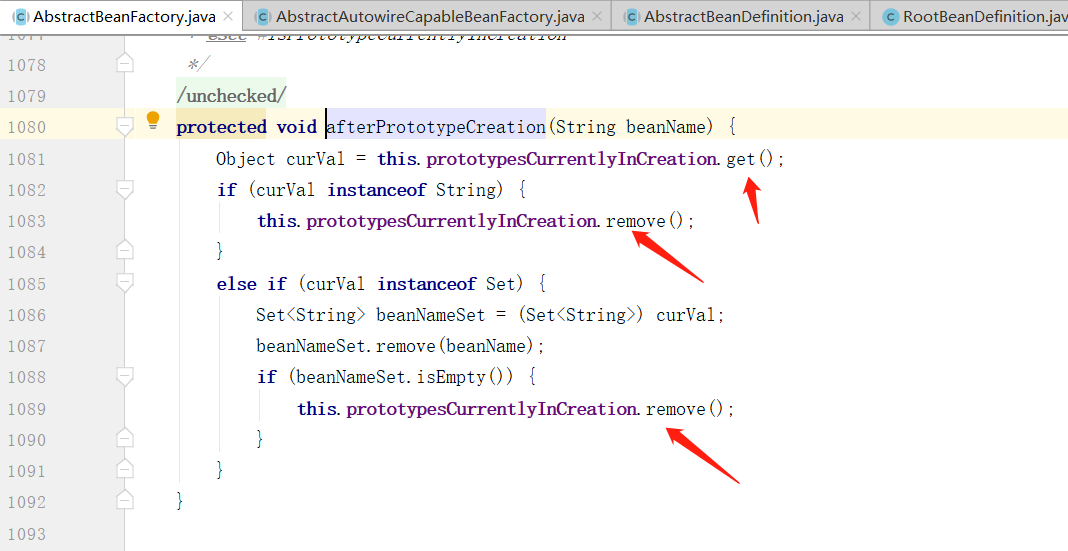
AbstractBeanFactory【doGetBean】继续往下看:
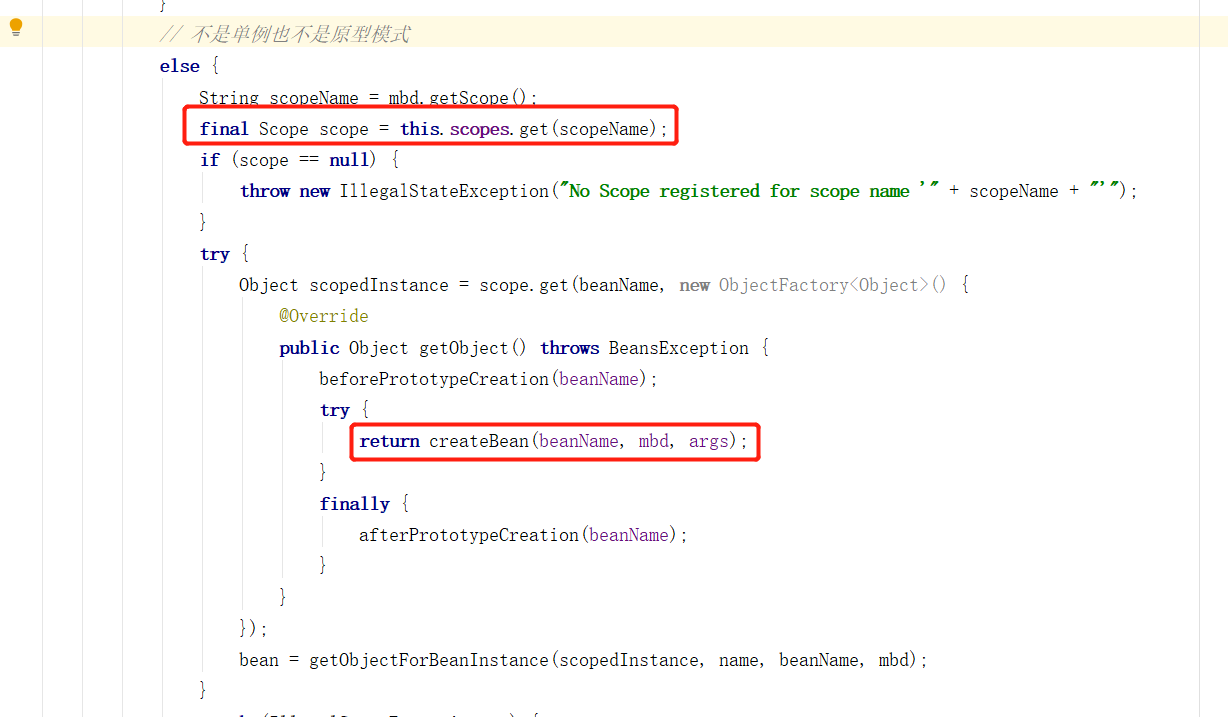
在 else 中则表示,既不是单例模式也不是原型模式下,这里就不做过多的介绍了,但明显的可以看到也是使用 createBean 方法创建实例对象的。
三种情况下创建的 bean 不为空的话,则直接返回给上层,也就是给到业务层可以正常使用该 bean 了。
AbstractAutowireCapableBeanFactory【createBean】
从上面的分析中发现,实际创建对象都使用的 AbstractAutowireCapableBeanFactory 下的 createBean 方法

这里首先拿到前面创建的 RootBeanDefinition,根据 RootBeanDefinition 获取到当前 bean 的 Class,主要判断需要创建的bean 是否可以被实例化,是否可以通过当前的类加载器加载。 如果 resolvedClass 不为空,并且 mbd 的 beanClass 不是 resolvedClass 话,则创建一个新的 RootBeanDefinition。
AbstractAutowireCapableBeanFactory【createBean】继续往下看:
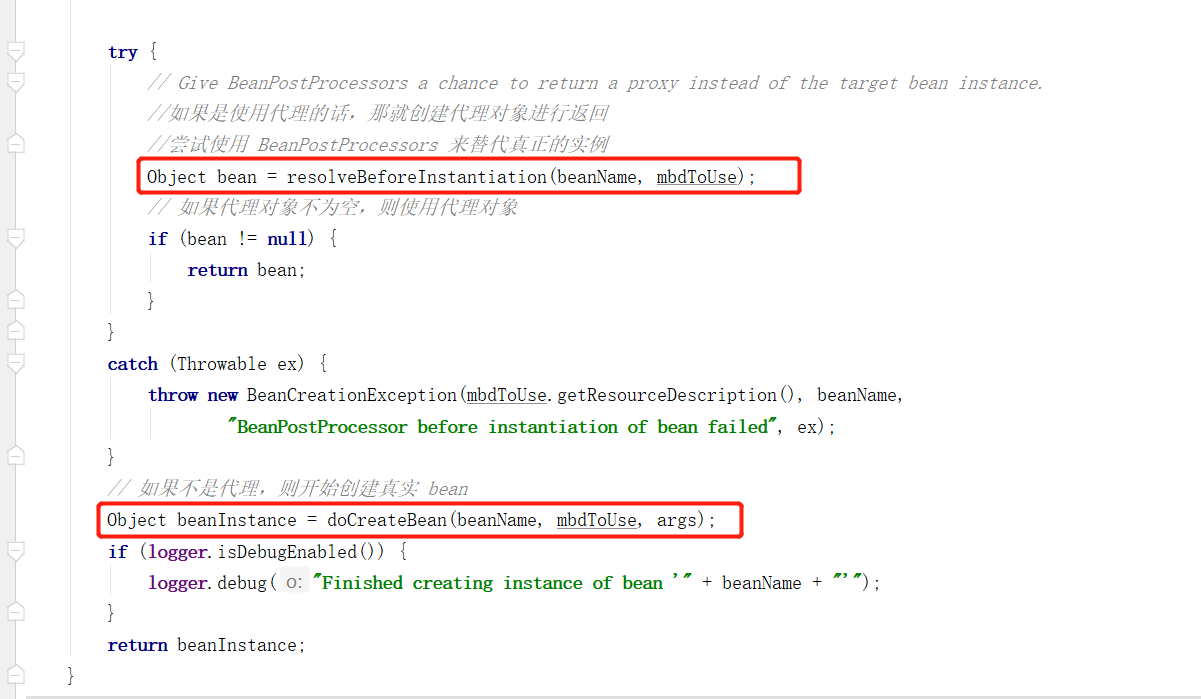
这里会尝试创建代理对象,如果是 AOP 的话则尝试使用 BeanPostProcessors 来替代真正的实例,对于 AOP 的分析这里不做过多的介绍了,这里主要关注下最后的 doCreateBean 方法。
AbstractAutowireCapableBeanFactory【doCreateBean】
该方法主要代码:
doCreateBean{
// 实例化bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 执行MergedBeanDefinitionPostProcessor实现类的postProcessMergedBeanDefinition方法
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
// 提前暴露bean,将ObjectFactory添加到三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
//设置bean属性
populateBean(beanName, mbd, instanceWrapper);
//初始化bean
exposedObject = initializeBean(beanName, exposedObject, mbd);
//从一二三缓存中再获取一遍bean
Object earlySingletonReference = getSingleton(beanName, false);
}AbstractAutowireCapableBeanFactory#createBeanInstance
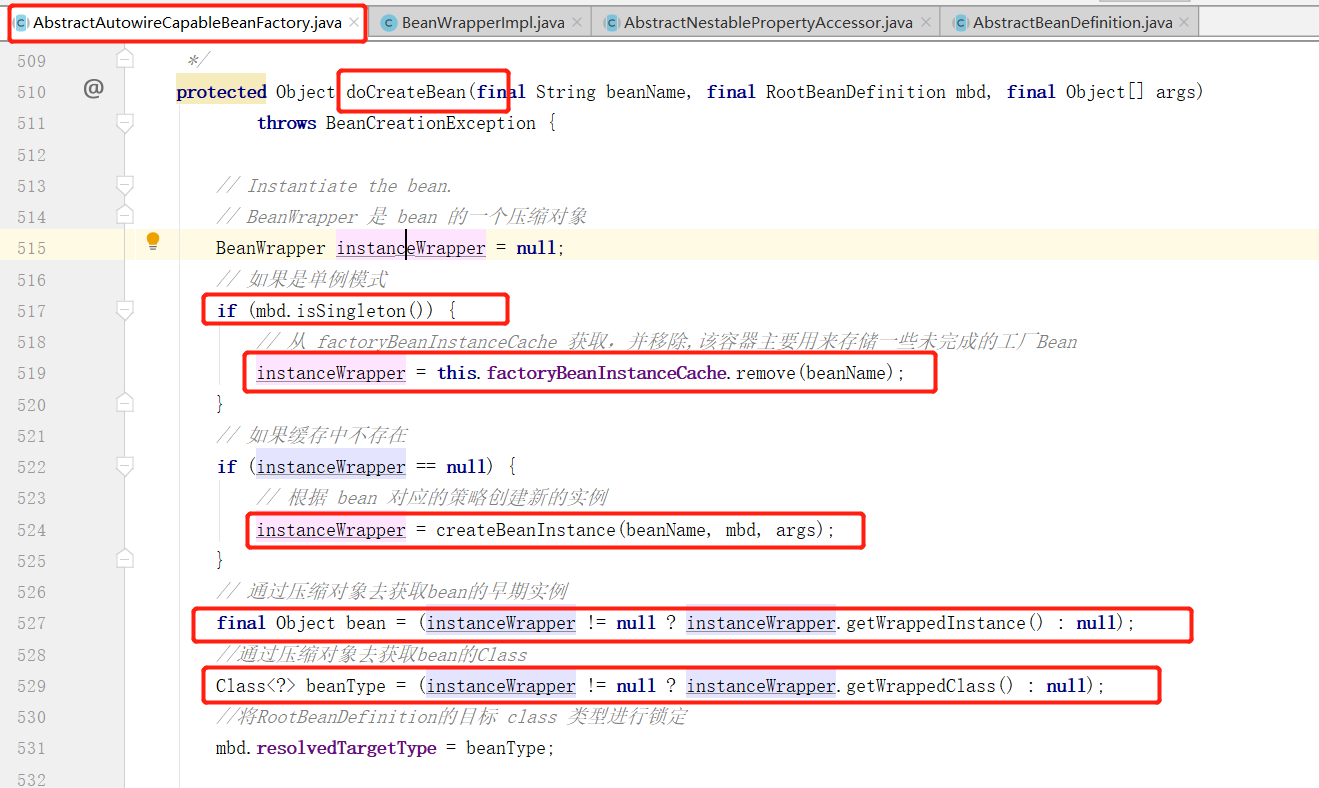
在 doCreateBean 方法中,如果是单例模式的话,会尝试从 factoryBeanInstanceCache 缓存中获取一个 BeanWrapper 对象,如果不存在的话则通过 createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) 方法创建一个新的 BeanWrapper 对象。
这里的BeanWrappe 对象是对bean的包装,可以使用统一的方式来访问bean的属性,从下面的操作可以看出,通过BeanWrapper 对象获取到了当前 bean 的实例对象,因此在 createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) 方法中肯定对当前 bean 进行了实例化操作,下面进入到该方法中:
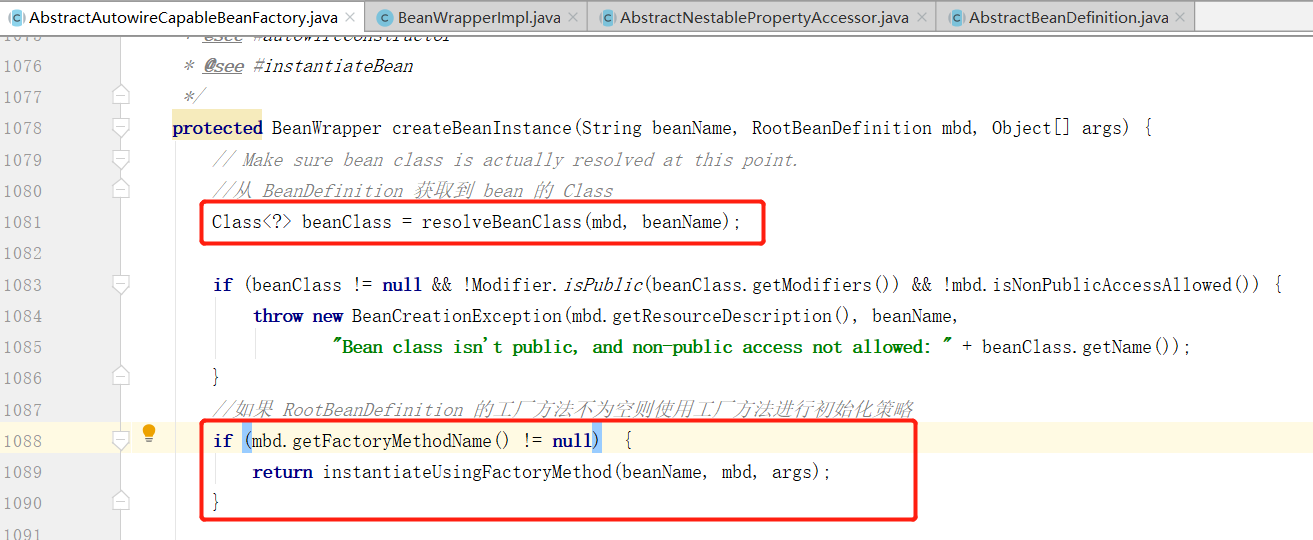
在 createBeanInstance 方法中,首先通过 BeanDefinition 获得 bean 的 Class ,如果 RootBeanDefinition 的工厂方法不为空则使用工厂方法进行初始化策略。
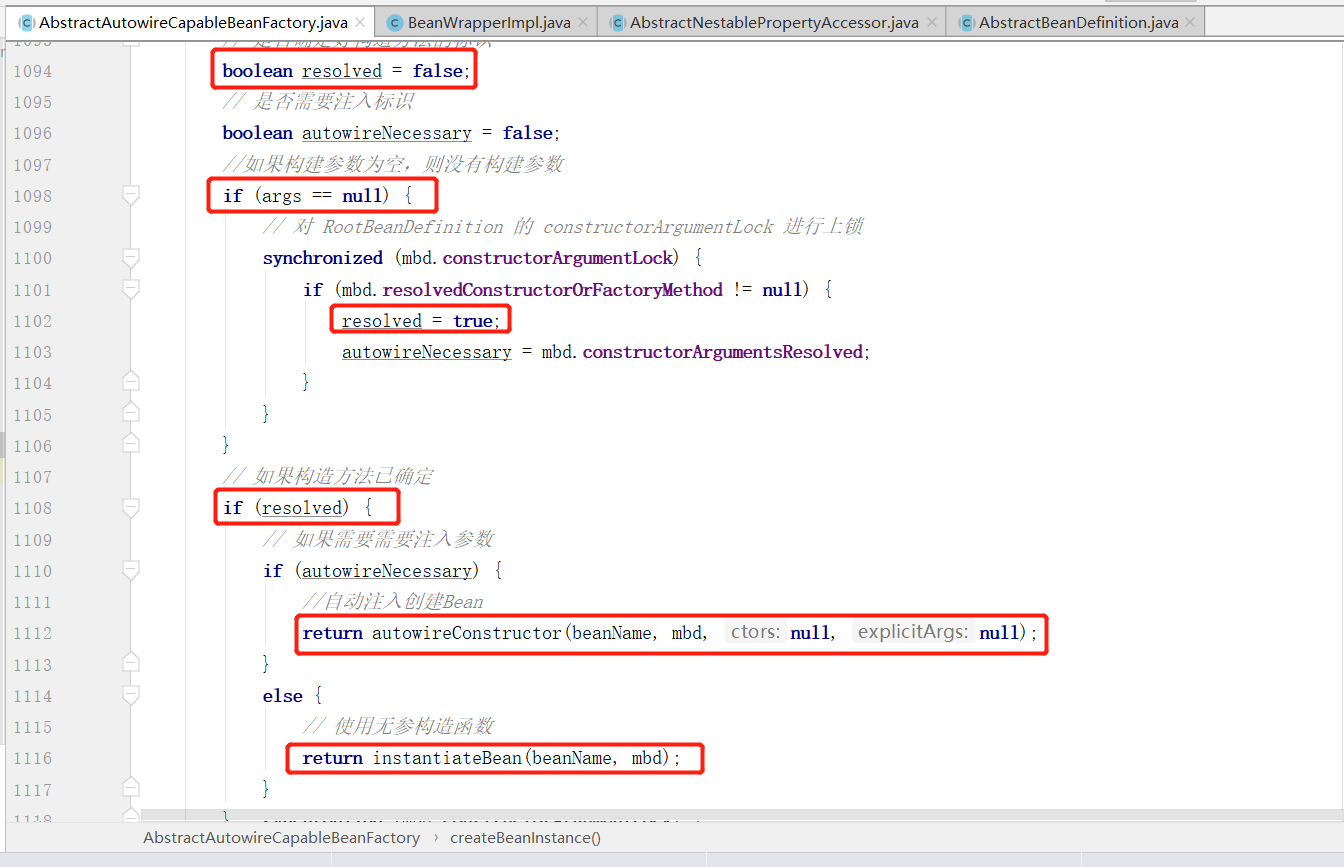
其中resolved 表示是否已经确定好构造方法,autowireNecessary 表示构造方式是否需要自动注入,如果传递过来的参数为空的话,那这个时候就对RootBeanDefinition 的 constructorArgumentLock 进行上锁,接着会判断 RootBeanDefiniton 的 resolverConstructorOrFactoryMethod 是否为空,这里其实是一个缓存,后面在实例对象时会对其进行赋值,这里如果存在缓存,则直接使用。

如果构造方法已经确定的话,那就是 mbd.resolvedConstructorOrFactoryMethod 缓存存在,则根据 mbd 中的构造类型选择用有参的构造函数创建 bean,还是使用无参的构造函数创建 bean。
这里我们假设缓存为空的话,则程序继续向下执行。

如果没有缓存的话,则就要找beanName 对应的 beanClass 的所有的有参构造器,如果找到了则尝试进行创建 bean ,否则的话直接使用无参的构造函数进行初始化。
进入 instantiateBean 方法中。

在该方法中判断是否开启了安全管理,如果是则使用 AccessController.doPrivileged 生成 bean 实例,可以看到最终都是由 getInstantiationStrategy().instantiate 方法生成实例,该方法其实在 SimpleInstantiationStrategy 类中,下面进入到该方法中:

在该方法中,首先如果没有覆盖方法的话,同样对 RootBeanDefinition 的 constructorArgumentLock 进行上锁,接着也还是获取 RootBeanDefiniton 的 resolverConstructorOrFactoryMethod 是否为空,就是判断是否存在缓存,如果不存在的话则获取到 bean 的 Class ,如果 Class 是接口类型的话则抛出异常。

这一步的处理比较明了,如果是安全模式下,则使用 AccessController.doPrivileged ,同时这里使用 clazz.getDeclaredConstructor 反射获取 class 的构造方法,并且将反射得到的结果存入到resolvedConstructorOrFactoryMethod 中进行缓存,对应了前面取缓存的动作,最后直接通过 BeanUtils 工具类反射实例化出 bean 对象。
下面如果有覆盖方法的话,则使用 cglib 进行实例化对象:

看到这里,我们应该了解到了 bean 在哪里被创建的了。
DefaultSingletonBeanRegistry#addSingletonFactory
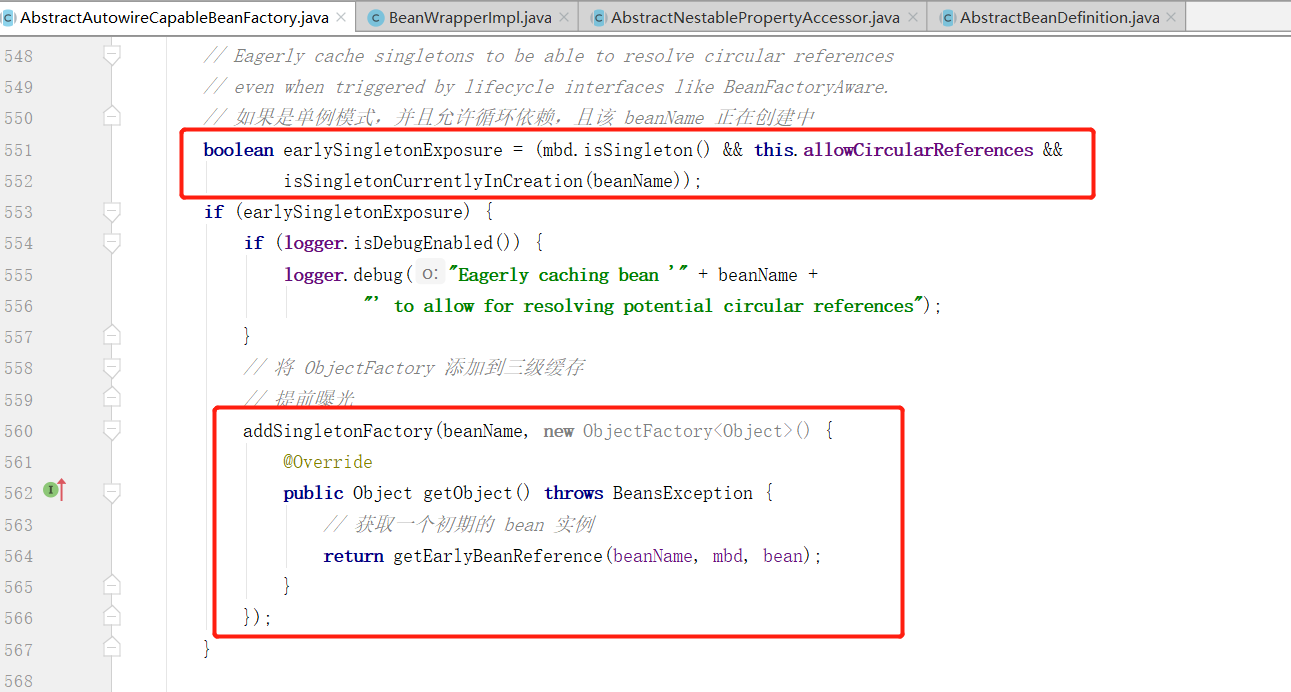
这里判断是否为单例模式,并且允许循环依赖,并且该 beanName 正在创建中的话,判断是否正在创建中就是去 singletonsCurrentlyInCreation 容器中判断有无。
如果条件都符合的话,则首先曝光至三级缓存中,可以看下 addSingletonFactory 方法的过程:
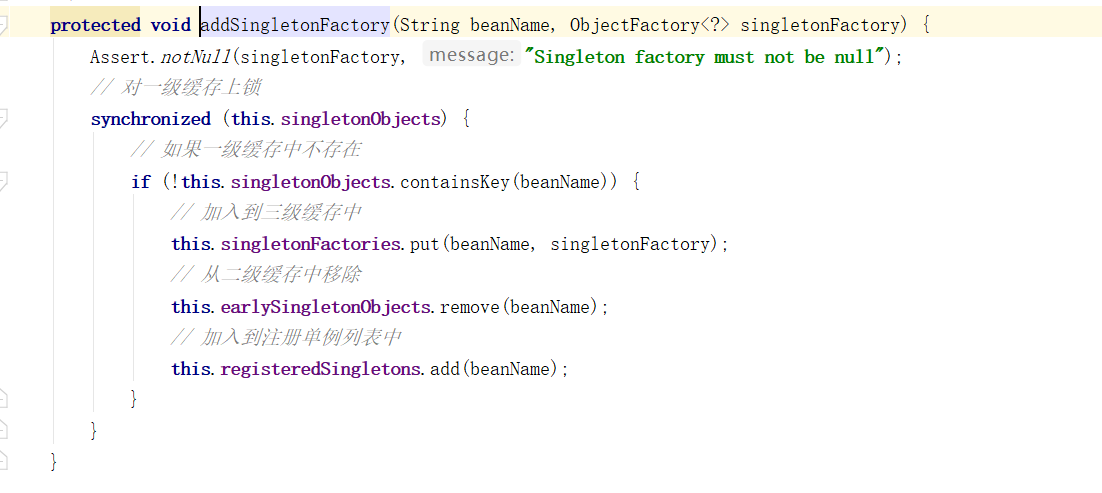
这里首先对一级缓存进行上锁,并且一级缓存中不存在,则写入到三级缓存中,并从二级缓存中移除,最后加入到注册单例列表中。
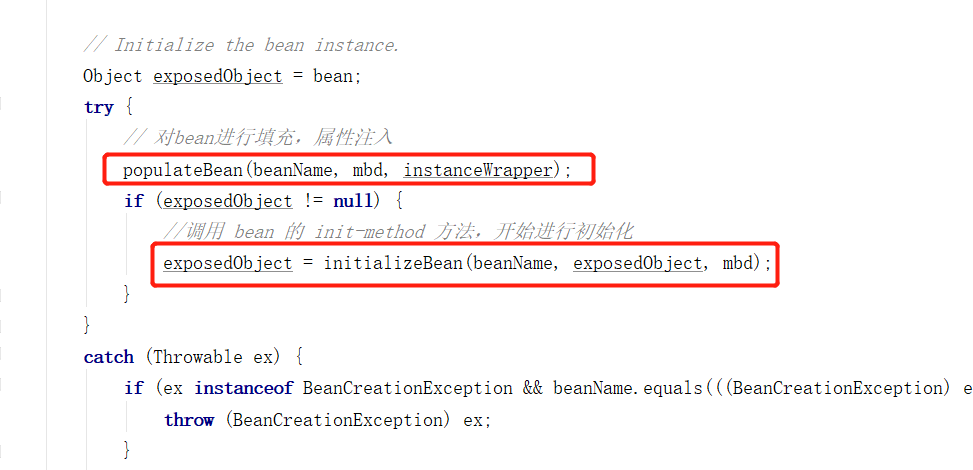
AbstractAutowireCapableBeanFactory#populateBean
populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) 方法,主要进行了依赖的注入。
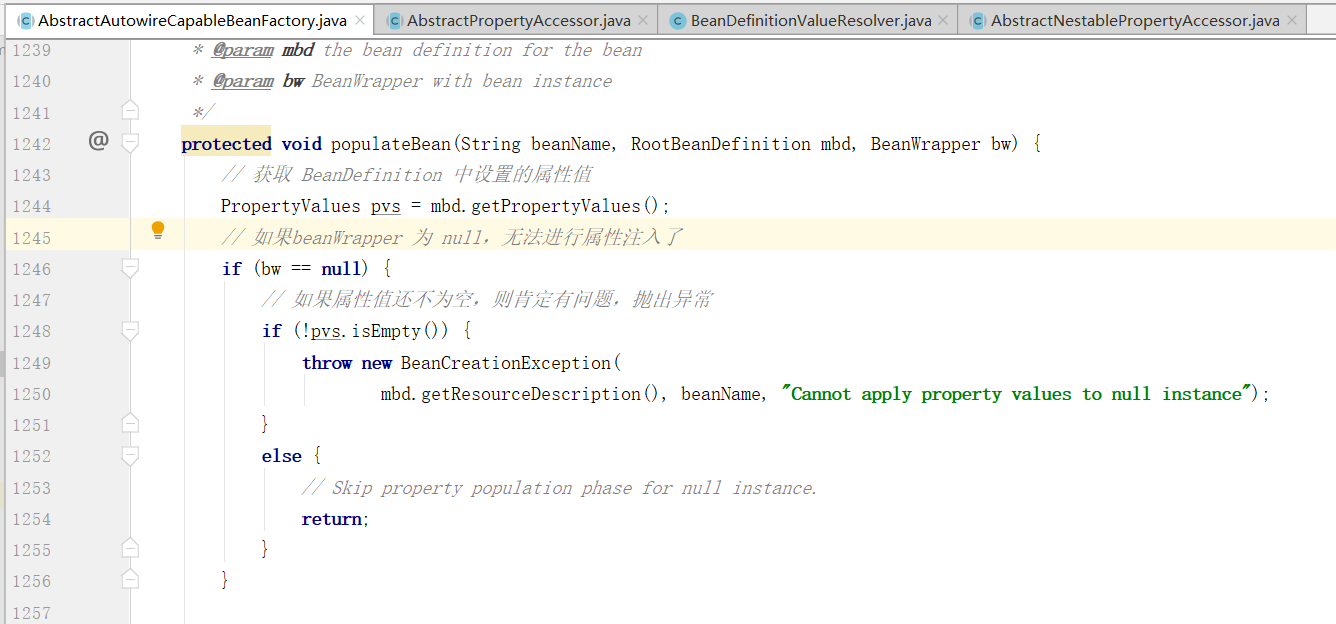
在 populateBean 方法中,先校验是否需要进行依赖注入,接着向下看,可以看到两个非常显眼的标识:

这里进行了两种类型的解析 byName 和 byType 就是配置的 autowire 属性 ,选择依赖注入的方式是根据名称还是根据类型,这里我们主要看下 autowireByName 的逻辑:
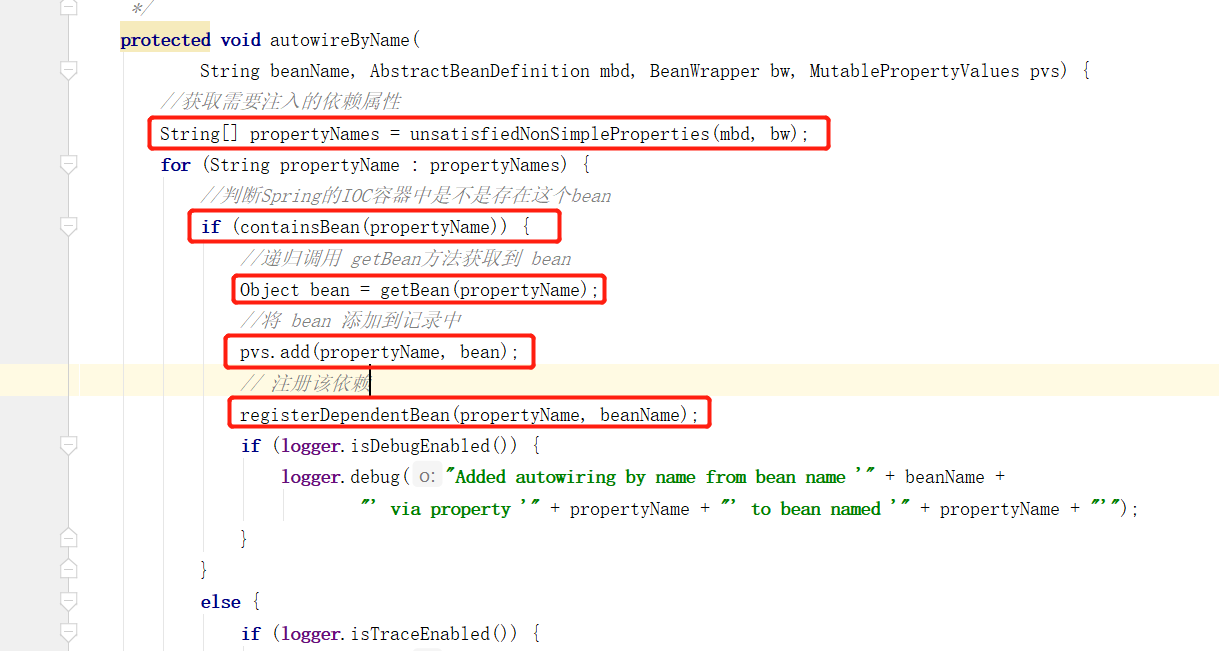
这里首先获取到所有依赖的 beanName ,然后如果存在容器中的话,则递归的方式获取到该 bean 。
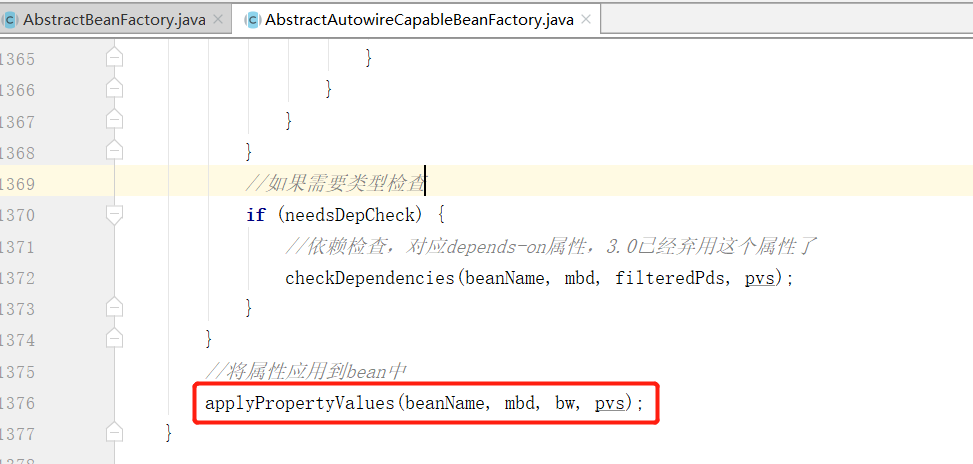
最后是使用 applyPropertyValues 方法进行属性的赋值,下面来看下该方法的逻辑:
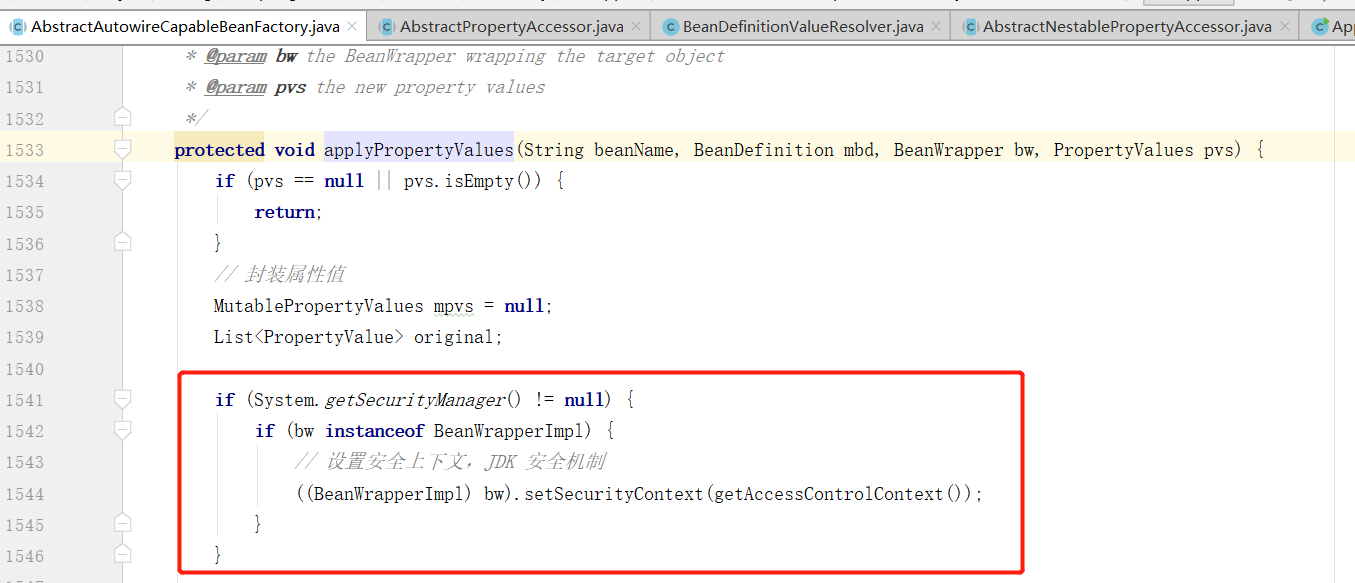

这里首先判断了下属性是否被转化,如果转化了就直接设置属性值,否则的话就记录下,在后面的逻辑中对其进行转化后再进行设置属性值。
这个转换其实就是依赖的类型有可能多种多样,比如可能是引用类型、集合类型、字符串、Properties属性等等,对于不同的依赖需要由不同的操作方式,因此在下面的逻辑中生成了一个 BeanDefinitionValueResolver 这个是 bean 定义属性值解析器,主要就是将 bean 定义中的属性值解析为 bean 实例对象的实际值:
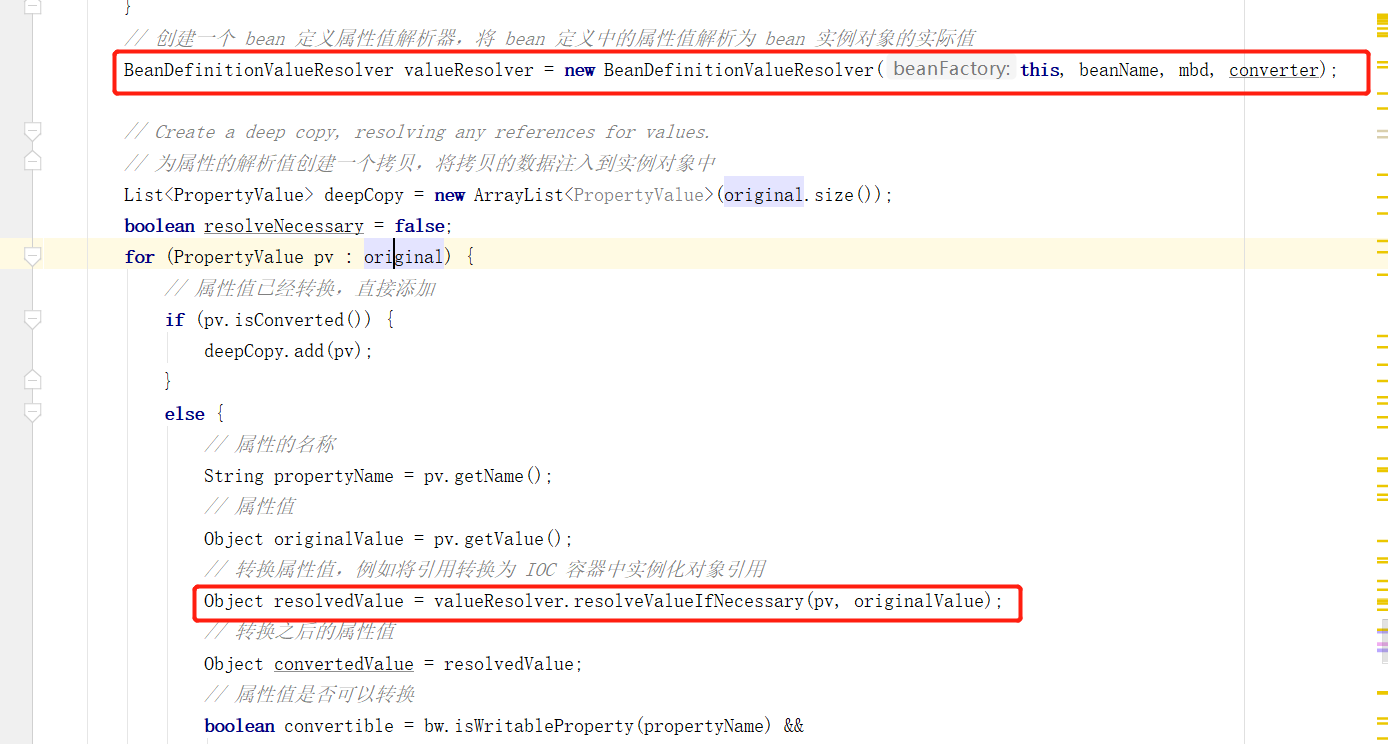
下面主要看是如何进行转化的,进入到 resolveValueIfNecessary 方法中:
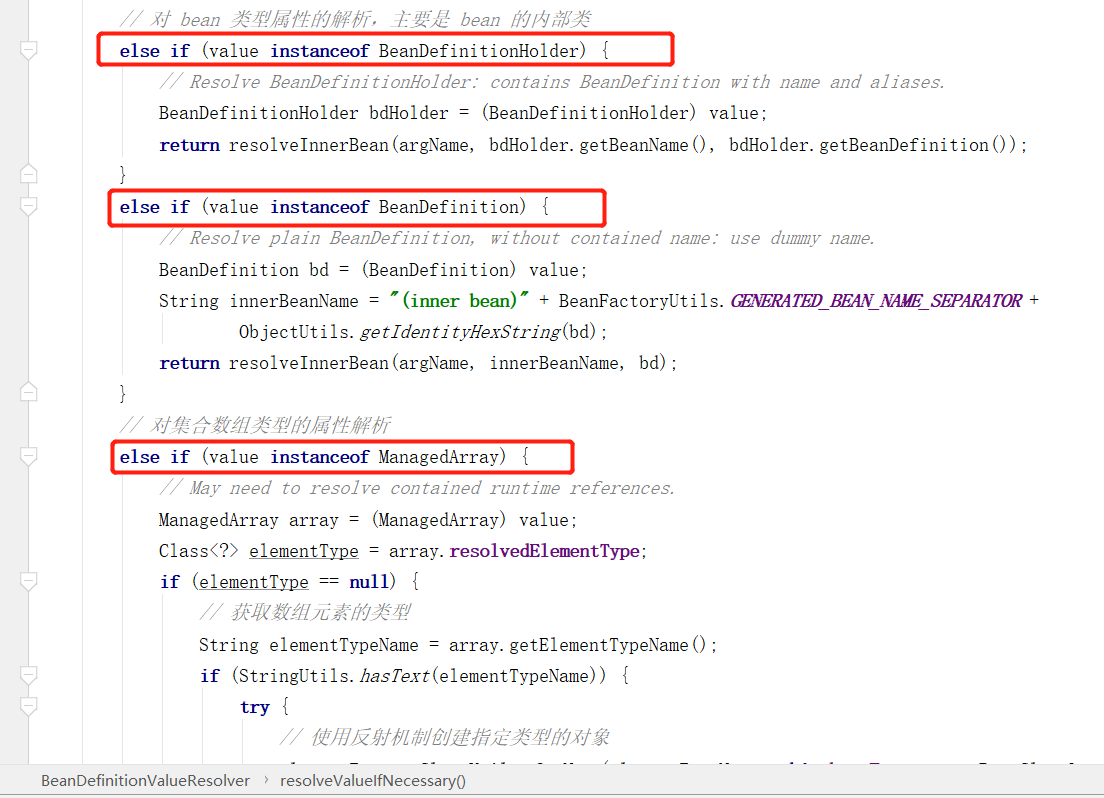
可以明显看出针对不同的类型进行了不同的解析方式,这里以引用类型为例看下resolveReference(Object argName, RuntimeBeanReference ref) 方法是如何处理的:
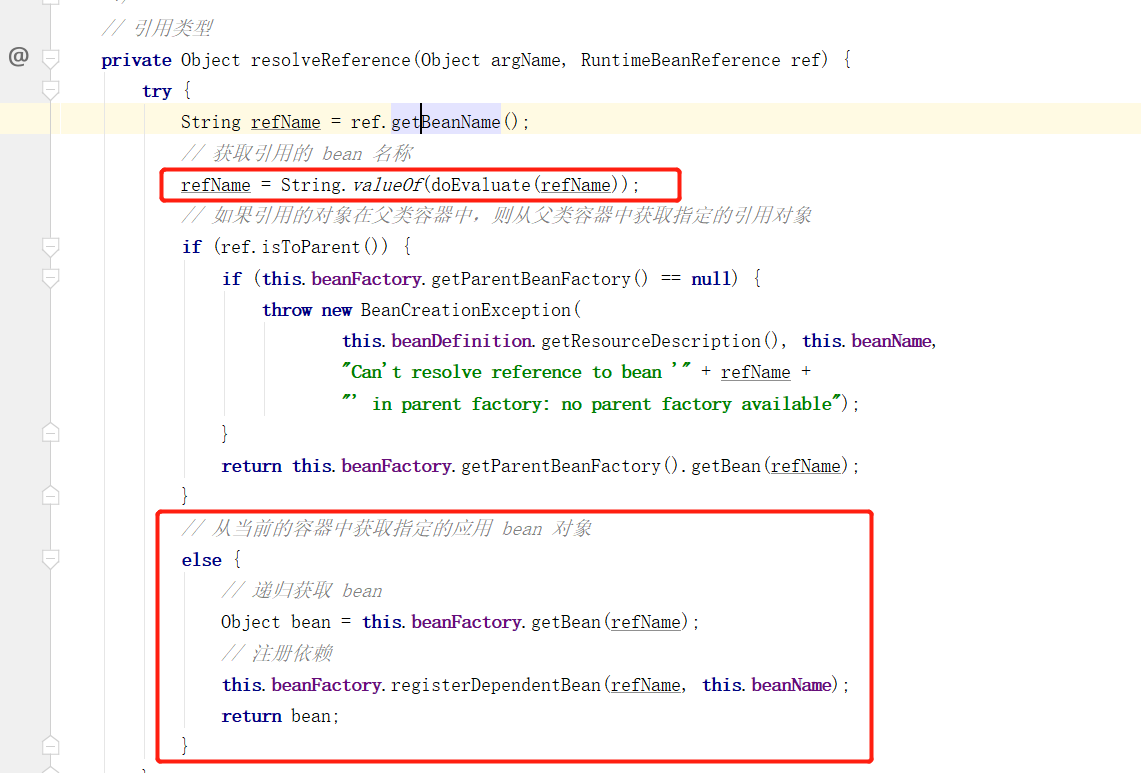
这里的逻辑也非常直观,首先获取到 beanName ,如果不是引用父类容器中的 bean 的话,则使用 getBean 递归获取依赖的对象,最后对其注册,并返回给上层。
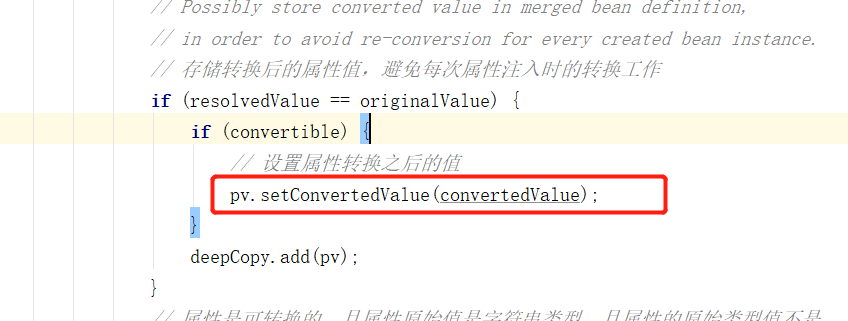
下面再回到 applyPropertyValues 方法中就好理解了,最后将转化后的值通过 PropertyValue 中的 setConvertedValue 方法注入到 bean 的属性字段中。
到这里就大概看完 bean 的依赖注入。
AbstractAutowireCapableBeanFactory#initializeBean
initializeBean是个bean初始化比较重要的方法,主要代码:
initializeBean{
// beanFactory相关aware接口调用
invokeAwareMethods(beanName, bean);
// BeanPostProcessor前置处理调用
Object wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
// 调用初始化方法,如InitializingBean的afterPropertiesSet以及自定义的init-method
invokeInitMethods(beanName, wrappedBean, mbd);
// BeanPostProcessor后置处理调用
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}