1 什么是无监督学习

- 一家广告平台需要根据相似的人口学特征和购买习惯将美国人口分成不同的小组,以便广告客户可以通过有关联的广告接触到他们的目标客户。
- Airbnb 需要将自己的房屋清单分组成不同的社区,以便用户能更轻松地查阅这些清单。
- 一个数据科学团队需要降低一个大型数据集的维度的数量,以便简化建模和降低文件大小。
我们可以怎样最有用地对其进行归纳和分组?我们可以怎样以一种压缩格式有效地表征数据?这都是无监督学习的目标,之所以称之为无监督,是因为这是从无标签的数据开始学习的。
无监督学习就是没有目标的学习
2 无监督学习包含算法
- 聚类
K-means(K均值聚类) - 降维
PCA
3 K-means原理
我们先来看一下一个K-means的聚类效果图
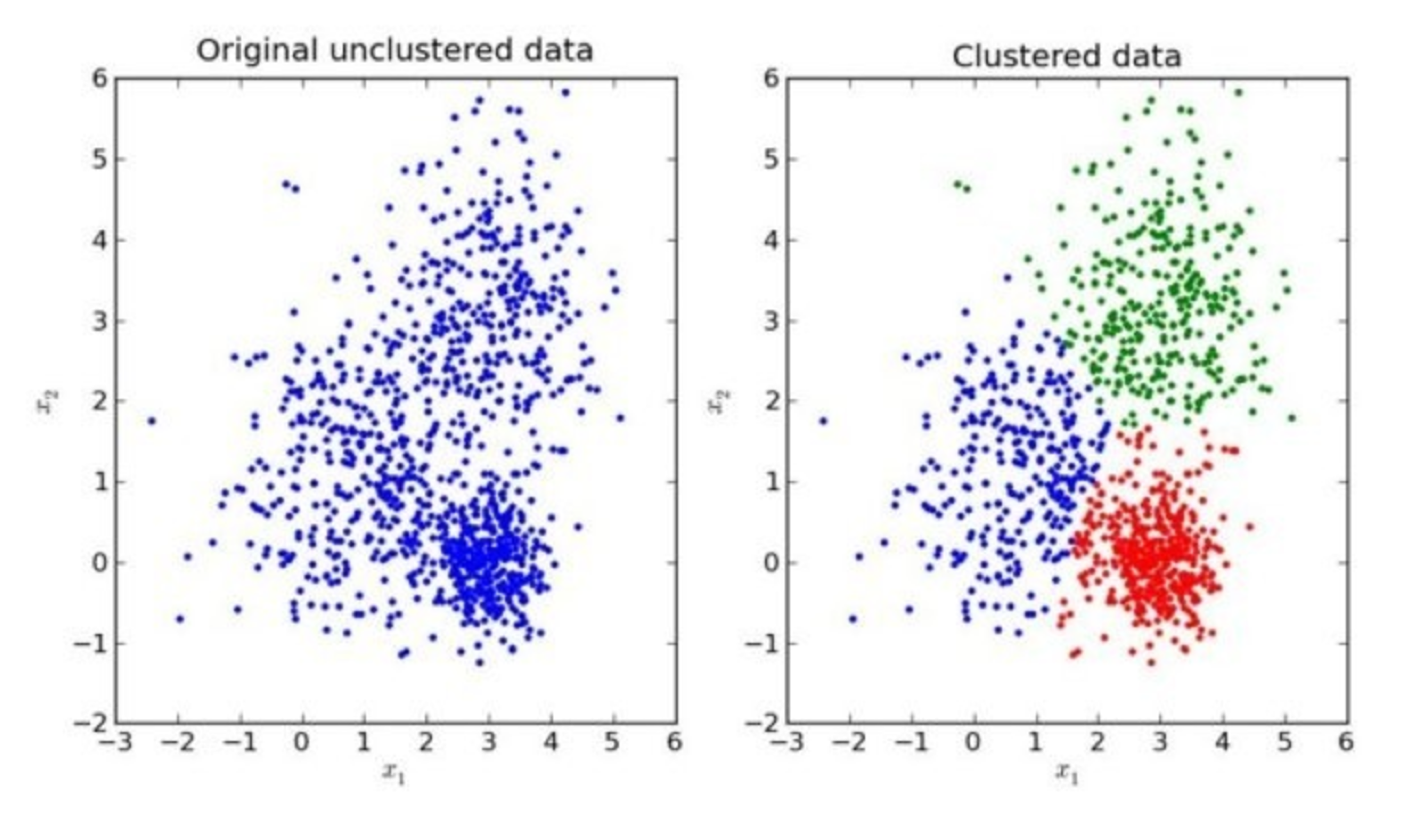
首先拿到了一堆数据,就是想给他分成三个堆,但是没有目标
3.1 K-means聚类步骤
- 1、随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
k值就是分成几类
我们以一张图来解释效果
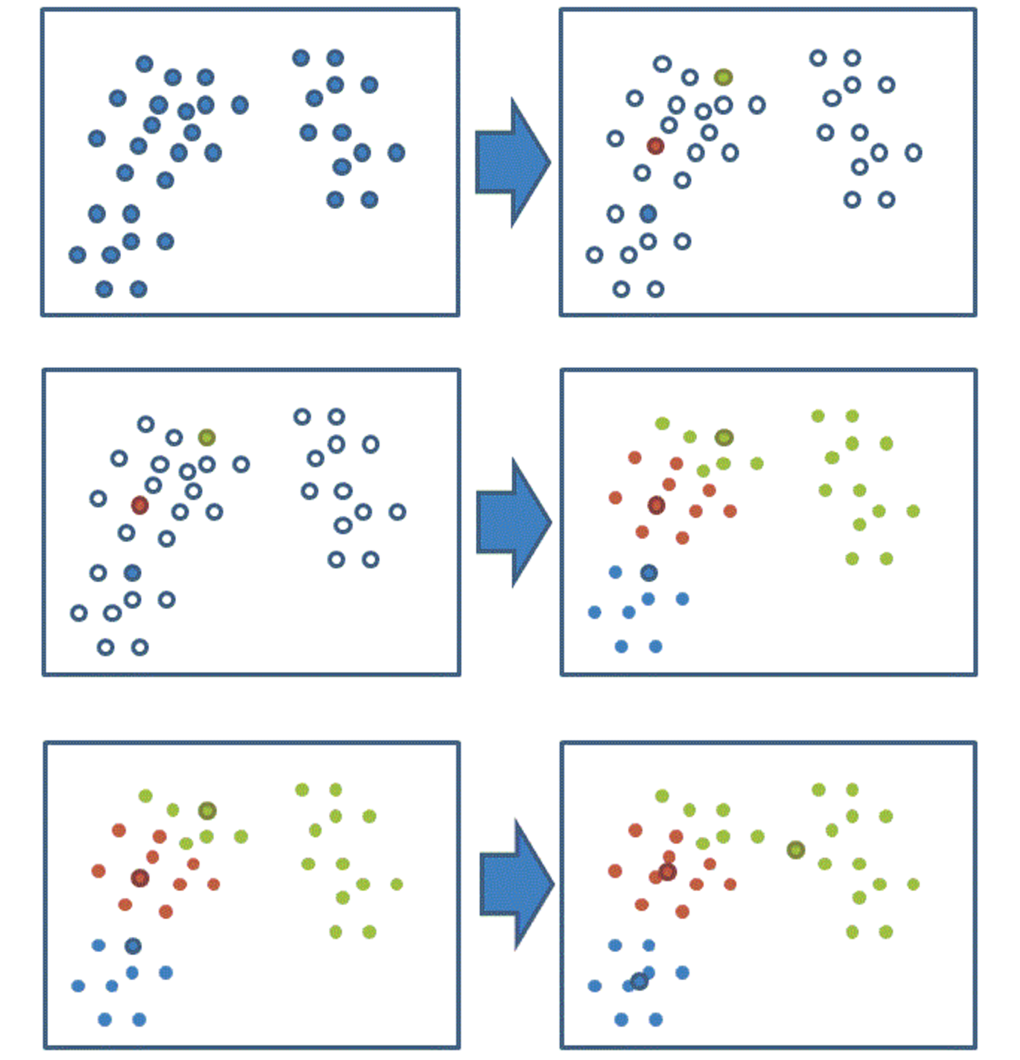
就是先找三个点(a1,b1,c1),然后对于每个点xi,都相对这三个点求一个距离,然后看看这个点xi离这三个点那个点近,然后就标记成和它相同的点,这样就分成了三堆了,之后再求这三堆的每个的中心点(a2,b2,c2),之后重复这个过程
A(a1,b1,c1)
B(a2,b2,c2)
C(a3,b3,c3)
..........
z(a26,b26,c26)
中心点(a平均,b平均,c平均)
4 K-meansAPI
sklearn.cluster.KMeans(n_clusters=8,init='k-means++')
- k-means聚类
- n_clusters:开始的聚类中心数量
- init:初始化方法,默认为'k-means ++’
- labels_:默认标记的类型,可以和真实值比较(不是值比较)
5 案例:k-means对Instacart Market用户聚类
5.1 分析
- 1、降维之后的数据
- 2、k-means聚类
- 3、聚类结果显示
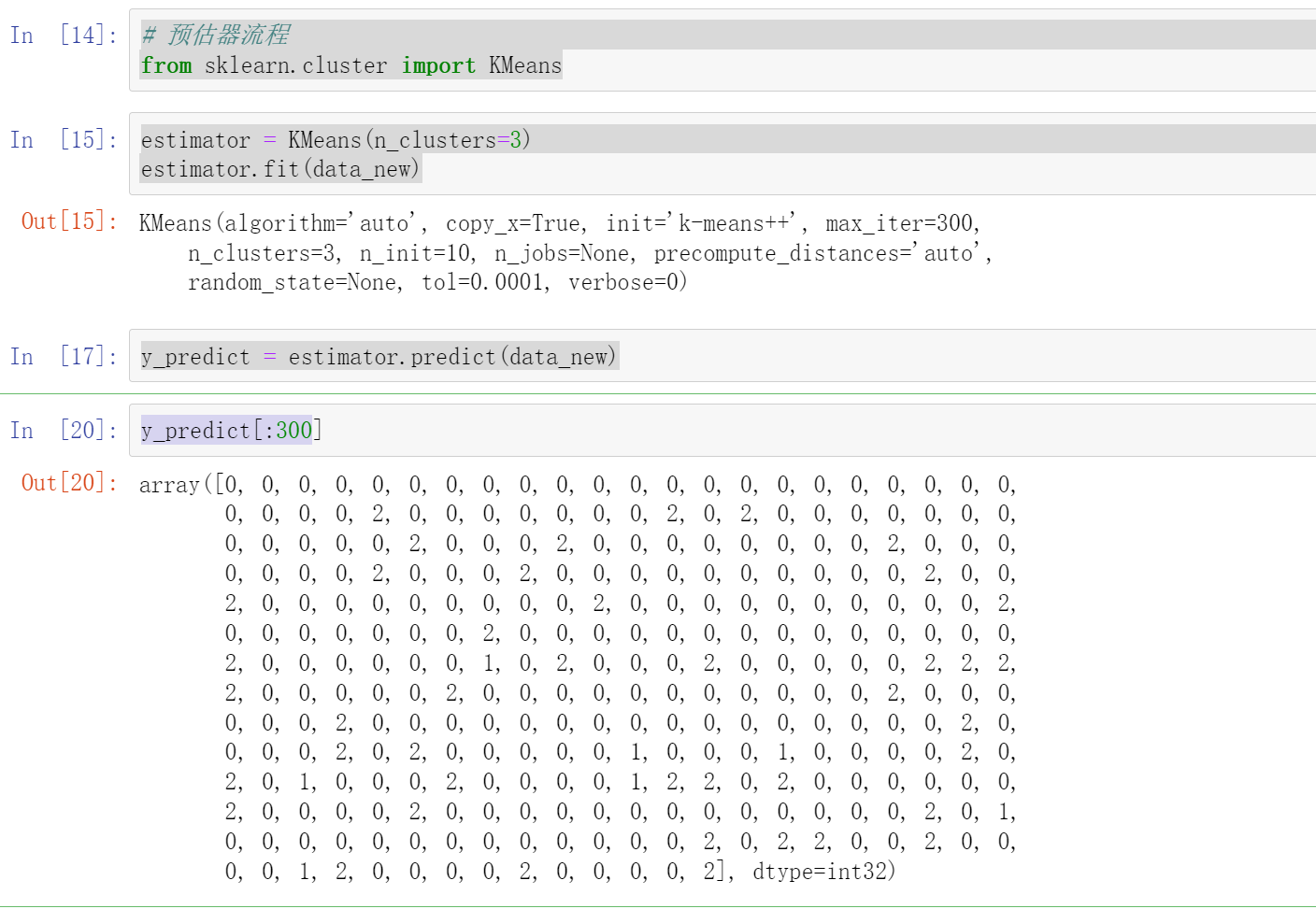
5.2 代码
# 预估器流程
from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=3)#分成三类
estimator.fit(data_new)
y_predict = estimator.predict(data_new)
y_predict[:300]
5.3 Kmeans性能评估指标
5.3.1 轮廓系数
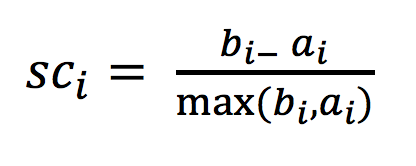
注:对于每个点i为已聚类数据中的样本 ,b_i为i这个点到其它族群所有样本的距离最小值,a_i为i到本族群的距离平均值。最终计算出所有的样本点的轮廓系数平均值
5.3.2 轮廓系数值分析
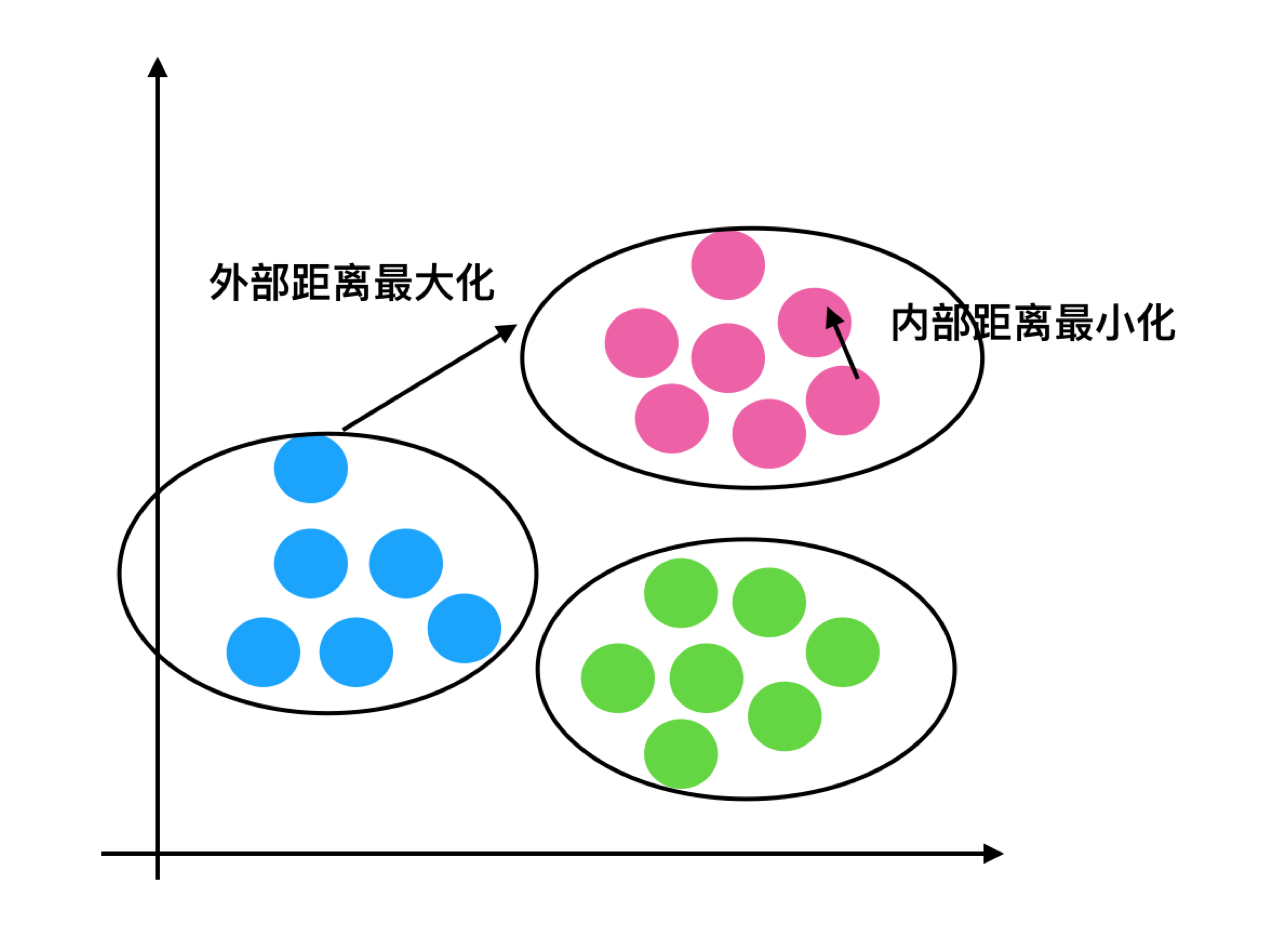
怎么算好呢?就是三个组外部距离最大化,内组距离最小化
分析过程(我们以一个蓝1点为例)
- 1、计算出蓝1离本身族群所有点的距离的平均值a_i
- 2、蓝1到其它两个族群的距离计算出平均值红平均,绿平均,取最小的那个距离作为b_i
- 根据公式:极端值考虑:如果b_i >>a_i: 那么公式结果趋近于1,聚类效果最好的,如果a_i>>>b_i: 那么公式结果趋近于-1
就是高内聚、低耦合
我们就是用轮廓系数来量化这个距离
结论
如果b_i>>a_i:趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。
5.3.3 轮廓系数API
sklearn.metrics.silhouette_score(X, labels)
计算所有样本的平均轮廓系数
X:特征值
labels:被聚类标记的目标值
用户聚类结果评估
silhouette_score(cust, pre)
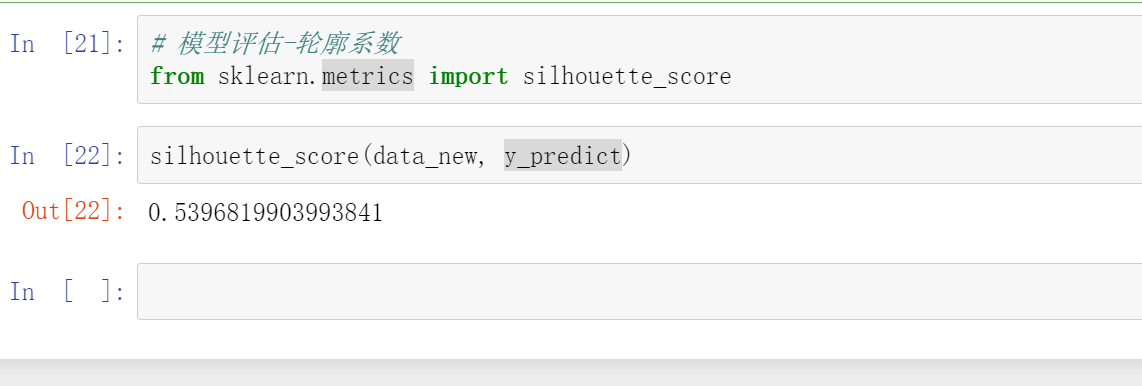
# 模型评估-轮廓系数
from sklearn.metrics import silhouette_score
silhouette_score(data_new, y_predict)
6 K-means总结
特点分析:采用迭代式算法,直观易懂并且非常实用
缺点:容易收敛到局部最优解(多次聚类)
注意:聚类一般做在分类之前