作业一
实验内容
- 要求:熟练掌握Selenium查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股” 3个板块的股票数据信息。(东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board) - 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
- Gitee文件夹链接:https://gitee.com/codeshu111/project/blob/master/作业4/stock_selenium.py
实现
- 用
find_element+click进入相应的板块,再用getMes获取相应板块的信息
def mySpider(url):
driver = webdriver.Chrome()
driver.get(url)
getMes(driver)#获取第一个”沪深A股“股票信息
#再加个循环可以翻页
for i in range(2,4):#”上证A股“和”深证A股“在导航栏第二、第三个
next=driver.find_element(By.XPATH,"//div[@id='tab']/ul/li["+str(i)+"]")
next.click()#next不能用find_elements,因为是列表
print('now in '+str(i)+'个')
time.sleep(3)
getMes(driver)
driver.quit()
getMes()部分:因为页面结构比较简单,是表单,直接把一整个表单都爬下来,在存入数据库时再通过索引做区分
def getMes(driver):
#获取信息
stock_list=[]#临时存一个板块
mes=driver.find_elements(By.XPATH,'//tbody/tr')#该板块所有20条信息,一条信息为一整个以字符分割的字符串
for i in range(len(mes)):#遍历每个tr,把每行字符串分割,存为一个列表
stock=list(str(mes[i].text).split(' '))
for j in range(len(stock)):#遍历每个tr下的列
print(stock[j],end=' ')
print('\n')
stock_list.append(stock)
insertDB(stock_list)
- 插入数据库:
def createDB():
con = sqlite3.connect("stocks_selenium.db")
cursor = con.cursor()
try: # 创建表
cursor.execute(
"create table stocks_selenium (ID varchar, stock_code varchar,stock_name varchar,latest_price varchar,change_percent varchar,change_amount varchar,volume varchar ,turnover varchar,amplitude varchar,highest varchar,lowest varchar,open_price varchar,close_price varchar)")
except:
cursor.execute("delete from stocks_selenium")
def insertDB(stock_list):
try:
con = sqlite3.connect("stocks_selenium.db")
cursor = con.cursor()
for i in range(len(stock_list)):
cursor.execute(
"insert into stocks_selenium (ID,stock_code,stock_name,latest_price,change_percent,change_amount,volume,turnover,amplitude,highest,lowest,open_price,close_price) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(stock_list[i][0],stock_list[i][1],stock_list[i][2],stock_list[i][6],stock_list[i][7],stock_list[i][8],stock_list[i][9],stock_list[i][10],stock_list[i][11],stock_list[i][12],stock_list[i][13],stock_list[i][14],stock_list[i][15]))
con.commit()
except Exception as err:
print(err)
print('completed')
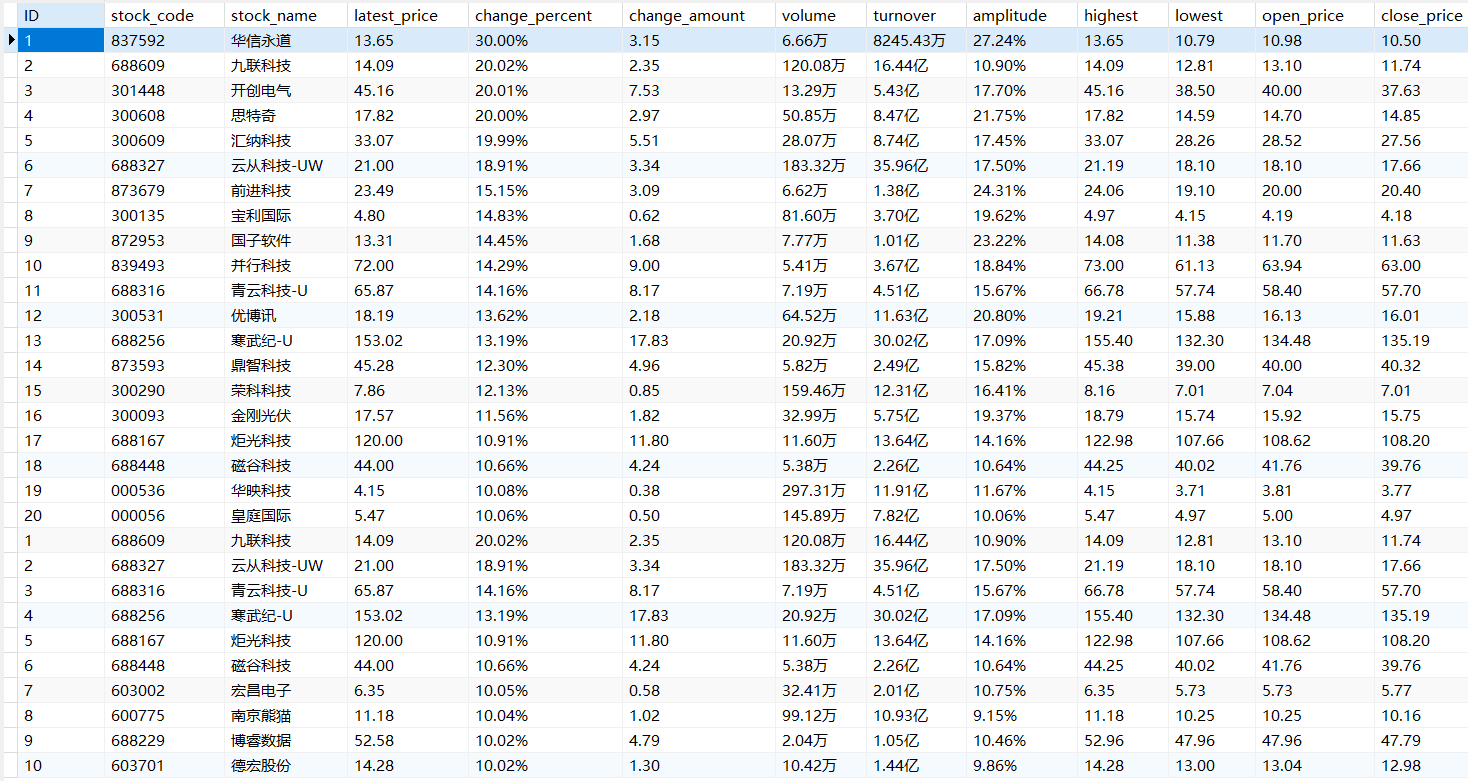
- 运行结果:
控制台输出:

数据库stocks_selenium.db内容:
心得
- 页面本身比较简单,利用selenium爬取不用像之前一样找json文件了,只需要掌握如何利用selenium进入相应板块。爬取的时候还要考虑怎么样获取信息最方便,一开始是想把13个属性的内容分开爬下来,但是数据在传递的过程中会产生大量的重复性操作,后面发现只需要把一整个表单直接爬下来保存为一个二维列表,再遍历列表保存到数据库中就行了。
作业二
实验内容
- 要求:熟练掌握Selenium查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)候选网站:中国 mooc 网:https://www.icourse163.org
- **输出信息: **MYSQL 数据库存储和输出格式
- Gitee文件夹链接:https://gitee.com/codeshu111/project/blob/master/作业4/mooc_selenium.py
实现
利用selenium实现用户模拟登录,并在搜索框中搜索“爬虫”
打开登录页面后,利用loginid=driver.find_element(By.XPATH,"//input[@type='tel']")会找不到element

问题在于登录界面新加载了一个frame
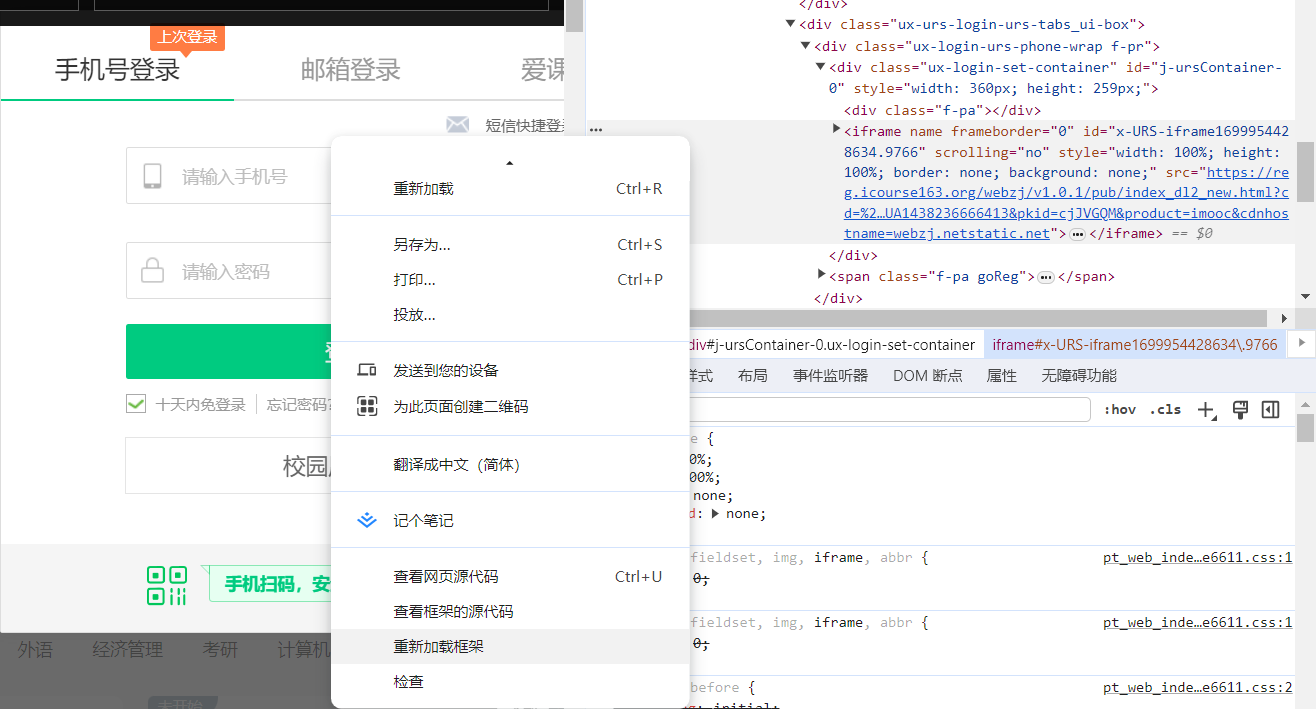
这里点击一下重新加载框架就会找到这个框架的起始部分,利用driver.switch_to.frame(frame)进入这个框架,再用前面的代码找到input元素,用send_keys输入账号和密码就可以成功登录了。
登录后不可以马上进行搜索框操作,否则会出现下面的问题:

等待五秒,并switch到新打开的窗口,再进行操作就没有问题了
time.sleep(5)
# 切换到最新打开的窗口
driver.switch_to.window(driver.window_handles[-1])
- 完整代码如下:
def mySpider(self,url):
driver=webdriver.Chrome()
driver.get(url)
time.sleep(1)
#登录部分
login=driver.find_element(By.XPATH,'//a[@class="f-f0 navLoginBtn"]')
login.click()
frame=driver.find_element(By.XPATH,"//div[@class='ux-login-set-container']/iframe")#登录页面重新加载了一个框架,所以要跳到这个框架
driver.switch_to.frame(frame)
#账号
loginid=driver.find_element(By.XPATH,"//input[@type='tel']")
loginid.send_keys('18250388603')
time.sleep(2)
#密码
password=driver.find_element(By.XPATH,'//input[@class="j-inputtext dlemail"]')
password.send_keys('raowenjie2003..')
time.sleep(2)
#登录按钮
loginbut=driver.find_element(By.XPATH,"//a[@id='submitBtn']")
loginbut.click()
time.sleep(5)
# 切换到最新打开的窗口
driver.switch_to.window(driver.window_handles[-1])
#会跳出一个东西,同意一下
agree = driver.find_element(By.XPATH,'//button[@class="btn ok"]')
agree.click()
#右上角搜索框
search=driver.find_element(By.XPATH,'//input[@name="search"]')
search.send_keys('爬虫')#在右上角搜索框搜什么
time.sleep(1)
#点击搜索按钮
findcourse=driver.find_element(By.XPATH,'//div[@class="u-search-icon"]')
findcourse.click()
time.sleep(2)
#获取信息
self.getMes(driver)
- getMes部分:没找到courseid,所以用序号代替。有一些课程会缺少一些属性,要进行特殊处理,保存为null,否则进程会因为找不到元素而终止
def getMes(self,driver):
#没有courseid
global id
courses=driver.find_elements(By.XPATH,"//div[@class='u-clist f-bgw f-cb f-pr j-href ga-click']")#先找到每个课程所属的div
for course in courses:#在每一个div下再查找
id=id+1
coursename=course.find_element(By.XPATH,".//span[@class=' u-course-name f-thide']").text#课程名称
print(coursename)
try:
uniname = course.find_element(By.XPATH, ".//a[@class='t21 f-fc9']").text#学校名称
except :
uniname='null'
print(uniname)
try:
professor=course.find_element(By.XPATH,"(.//a[@class='f-fc9'])[1]").text#主讲教师
except:
professor=course.find_element(By.XPATH,".//div[@class='t2 f-fc3 f-nowrp f-f0']/p").text
print(professor)
teammate=''#团队成员
for i in range(2,len(course.find_elements(By.XPATH,".//a[@class='f-fc9']"))):
mate=course.find_element(By.XPATH,"(.//a[@class='f-fc9'])["+str(i)+"]").text#好多老师,取第一个后面的
if i==2:
teammate=mate
else:
teammate=teammate+'、'+mate#除第一个老师外的人拼接起来
if teammate=="":
teammate='null'
print(teammate)
number=course.find_element(By.XPATH,".//span[@class='hot']").text#参加人数
print(number)
try:
progress=course.find_element(By.XPATH,".//span[@class='txt']").text#课程进度
except:
progress='null'
print(progress)
brief=course.find_element(By.XPATH,'.//span[@class="p5 brief f-ib f-f0 f-cb"]').text#课程简介
print(brief)
#插入数据库
self.insertDB(id,coursename,uniname,professor,teammate,number,progress,brief)
- 数据库部分:
def __init__(self):
self.con = sqlite3.connect("moocDB.db")
self.cursor = self.con.cursor()
try: # 创建数据库
self.cursor.execute(
"create table moocDB (id int, coursename varchar, uniname varchar, professor varchar, teammate varchar, number varchar, progress varchar, brief varchar)")
except:
self.cursor.execute("delete from moocDB")
def insertDB(self, id, coursename, uniname, professor, teammate, number, progress, brief):
try:
self.con = sqlite3.connect("moocDB.db")
self.cursor = self.con.cursor()
self.cursor.execute("insert into moocDB (id, coursename, uniname, professor, teammate, number, progress, brief) values (?,?,?,?,?,?,?,?)",
(id, coursename, uniname, professor, teammate, number, progress, brief))
self.con.commit()
self.con.close()
print('hhhhhhhhhhhhhhhhhhh')
except Exception as err:
print(err)
-
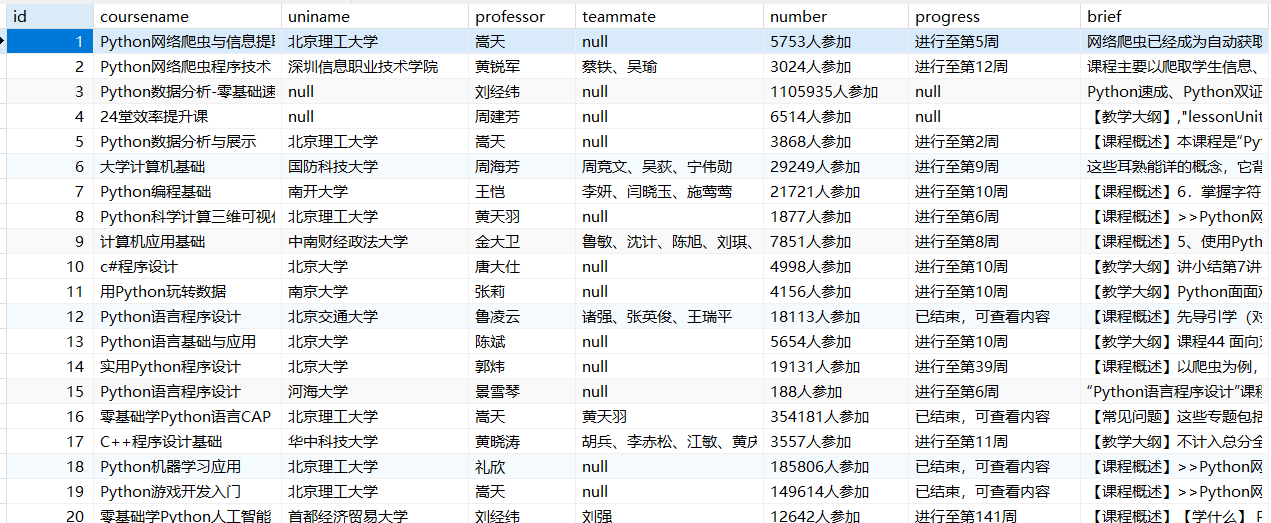
运行结果:
-
控制台输出结果:

-
moocDB.db内容:
心得
- 难点还是在于登录的实现上,登录会加载出一个新的frame,以及登录之后要等待一段时间并switch到新打开的页面,再进行下一步操作,剩下的步骤与上一题差不多,多了一些对空值的处理。
作业三
- 要求:掌握大数据相关服务,熟悉 Xshell 的使用,完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
- 任务一:开通 MapReduce 服务
申请集群:
配置安全组:
实时分析开发实战:
- 任务一:Python 脚本生成测试数据
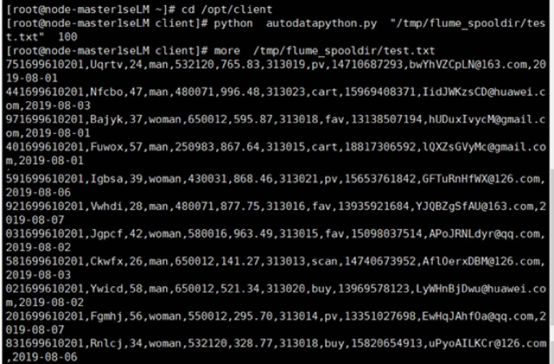
- 任务二:配置 Kafka


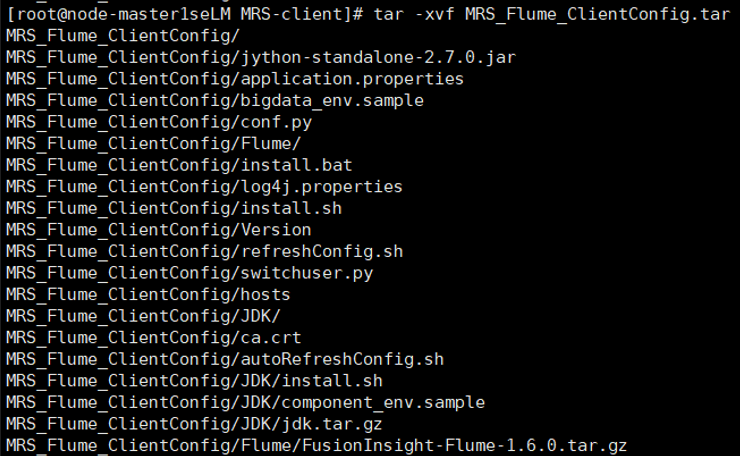
- 任务三: 安装 Flume 客户端
解压下载的flume客户端文件,校验文件包


安装客户端

重启

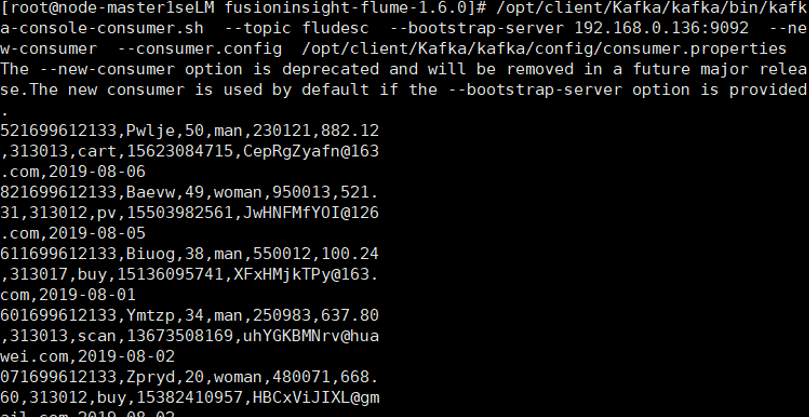
- 任务四:配置 Flume 采集数据
心得
- 每一秒都是钱,人民币在背后追着我的感觉,紧张。但是又怕哪里搞错,很仔细的对照着文档做。初步了解了实时分析开发的流程。