XR(Extended Reality,扩展现实)渲染技术分析(一)
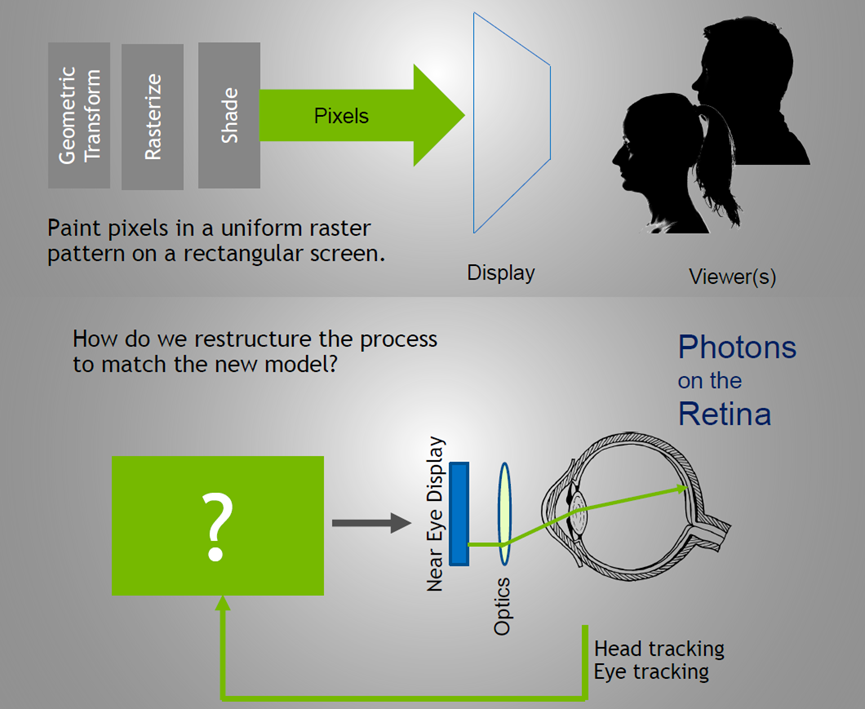
20世纪和21世纪的计算机图形学的模型对比如下图:
人类感知的极限超越了现代VR设备的10万到100万倍:

优化的方法有分区渲染:
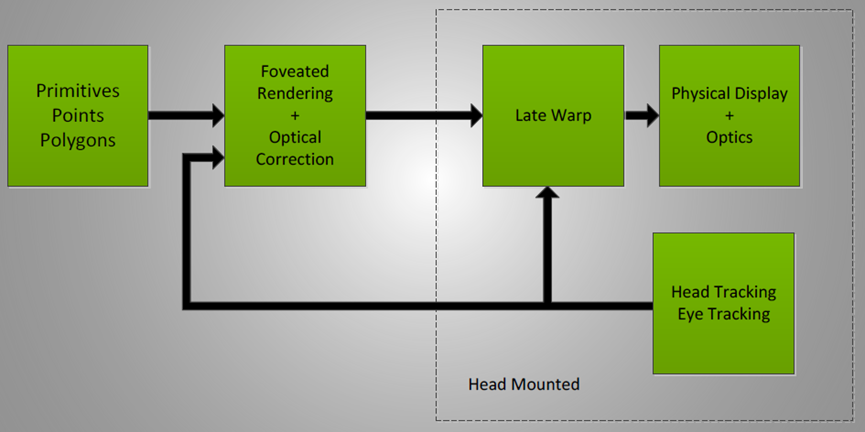
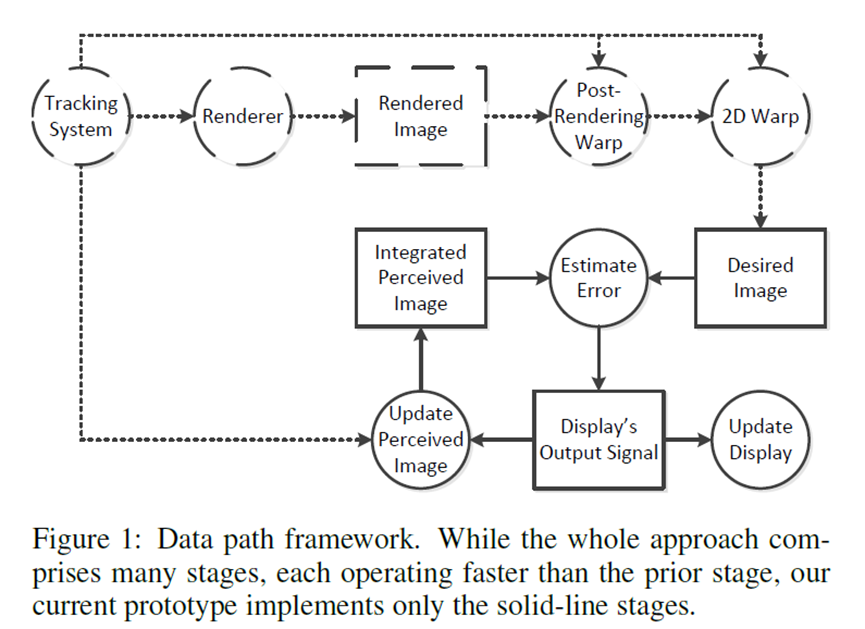
后期跟踪更新——在显示调制过程中插入跟踪,以比帧速率更快地更新位置。
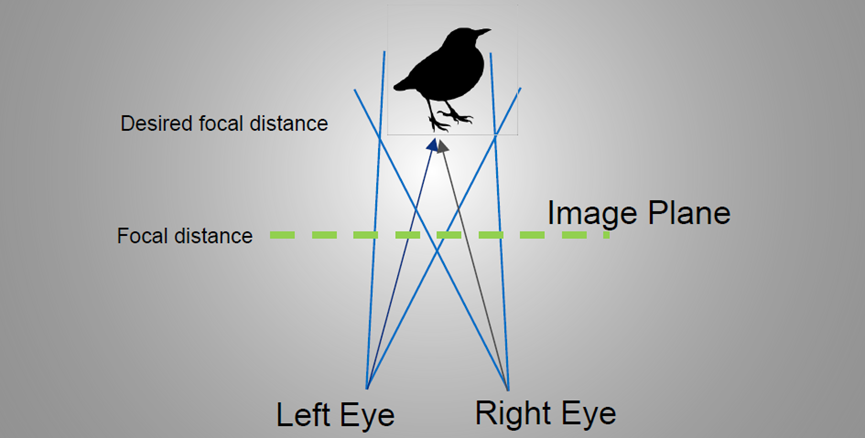
对于XR的双目显示,由于交点和显示平面的不同,存在冲突:
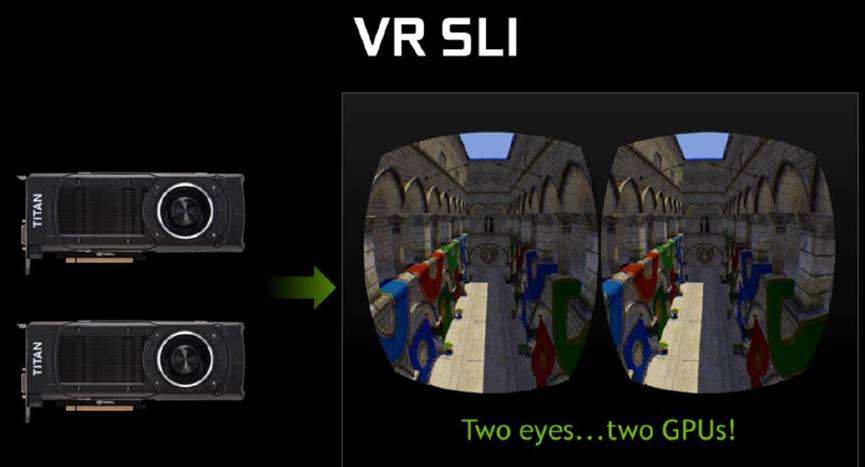
NV的GameWorks VR是用于VR设备和游戏开发的SDK,早在2015年的版本就支持了以下特性:

其中VR SLI是双GPU交火渲染:
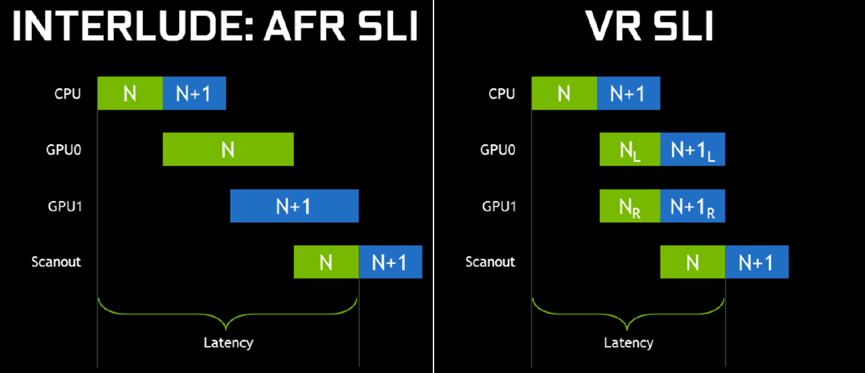
其中交叉帧SLI和VR SLI的延迟对比如下:
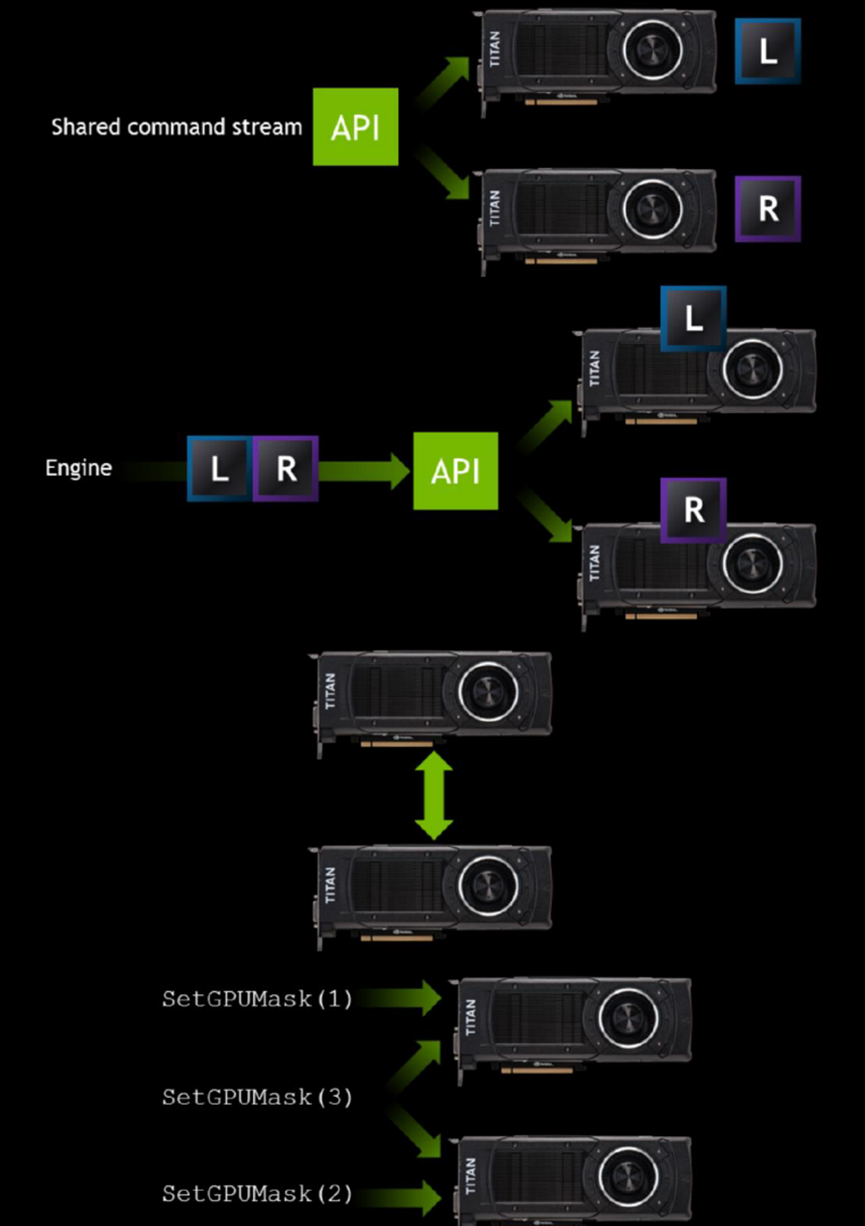
VR SLI实现示意图如下:
对于VR的两个view,渲染代表的改进如下:
// 优化前
for (each view)
find_objects();
for (each object)
update_constants();
render();
// 优化后
find_objects();
for (each object)
for (each view)
update_constants();
render();
1 多分辨率渲染和注视点渲染
如果我们在外围渲染低分辨率,必须小心锯齿/闪烁,如果我们在外围渲染平滑的图像模糊,用户会体验到“隧道视觉”效果,研究表明,我们应该提高外围低频内容的对比度。跟踪用户的视线,在距离注视点较远的地方以越来越低的分辨率渲染。
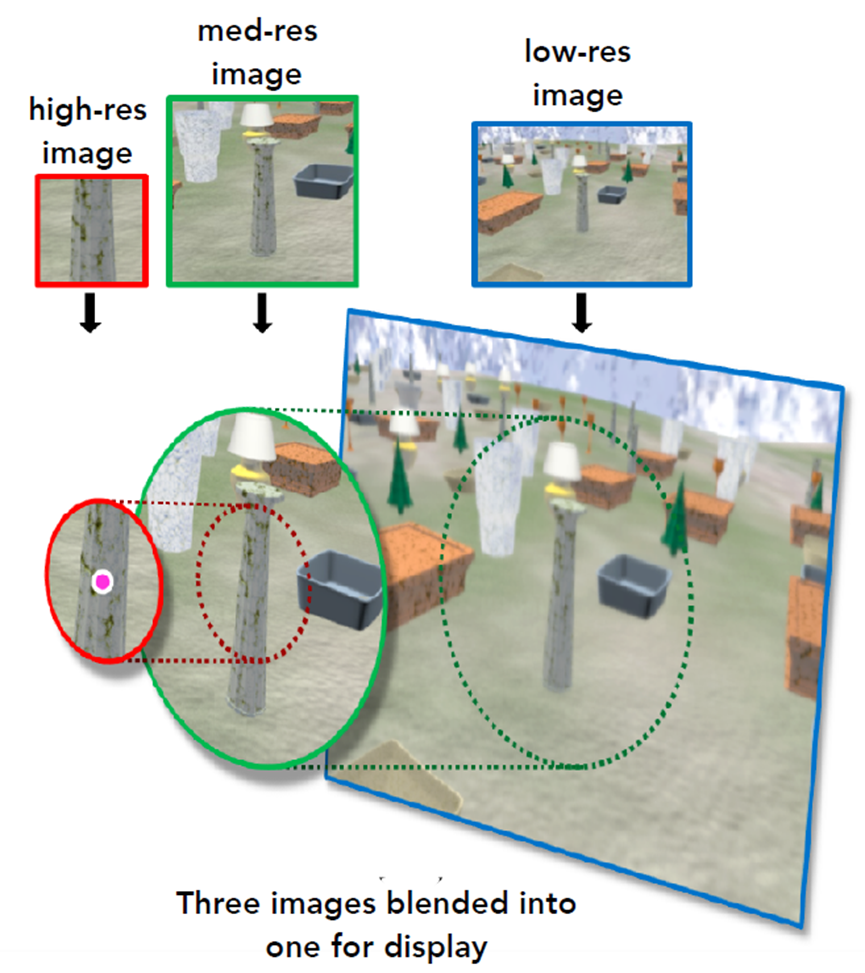
下面是不同的注视点渲染画面对比:

头显为了支持宽FOV,通常用镜头透视来实现,但镜头会引入扰动、枕形畸变和色差(不同波长的光折射量不同)等问题:
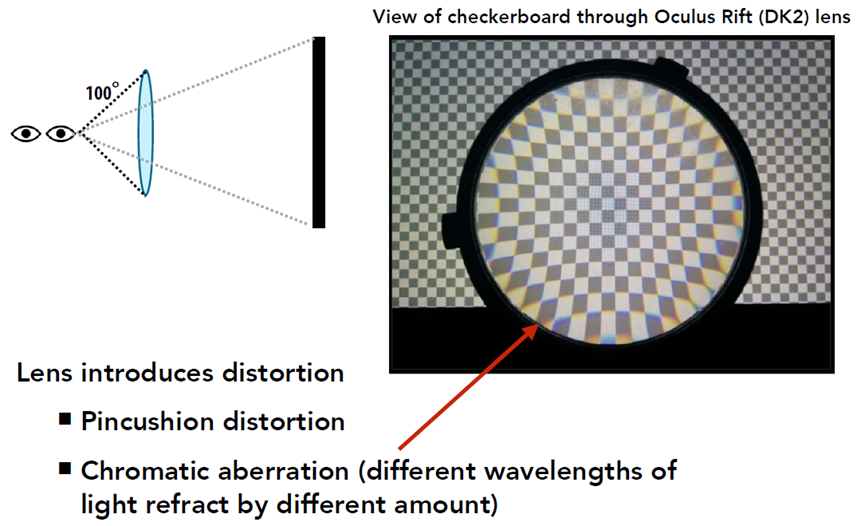
摄影镜头畸变的回调软件校正:

VR渲染中镜头畸变的软件补偿,步骤1:使用传统图形管线以每只眼睛的全分辨率渲染场景,步骤2:扭曲图像,使场景在物理镜头扭曲后看起来正确(可以使用对R、G、B的单独畸变来近似校正色差)。

基于光栅化的图形基于到平面的透视投影,根据VR渲染的需要,在高FOV下扭曲图像,VR渲染跨越宽视场。潜在解决方案空间:扭曲显示、光线投射以实现统一的角度分辨率,使用分段线性投影平面进行渲染(每个屏幕分幅的平面不同)。

由于VR扭曲,图像的四个边缘在渲染期间被压缩,并且在从应用程序内容渲染的大量像素重新采样后无法显示。事实上,可以减少这些像素的渲染开销。业界的GPU供应商提出了多分辨率着色技术,以减少渲染开销。在这项技术中,图像被划分为网格。中心区域保留原始分辨率,四个边和角的分辨率分别压缩1/2和1/4(可根据需要更改)。在渲染应用程序内容的过程中,GPU会立即绘制图像。
在VR设备上呈现的图像必须扭曲,以抵消镜头的光学效果。在下图中,一切看起来都是弯曲和扭曲的,但当通过镜头观看时,观众会感觉到一幅未扭曲的图像。

问题是GPU无法以原生方式渲染成这样的扭曲视图,这将使三角形光栅化变得更加复杂。当前的VR平台都解决了这个问题,首先渲染正常图像(左),然后进行后处理,将图像重新采样到扭曲的视图(右)。

如果你观察在变形过程中发生的情况,你会发现,虽然图像的中心保持不变,但边缘却被挤压得很厉害。意味着我们对图像的边缘进行了过度着色。我们正在生成大量的像素,这些像素永远不会显示在屏幕上——它们只是在扭曲过程中被丢弃了,这些像素是浪费的工作,会降低性能。

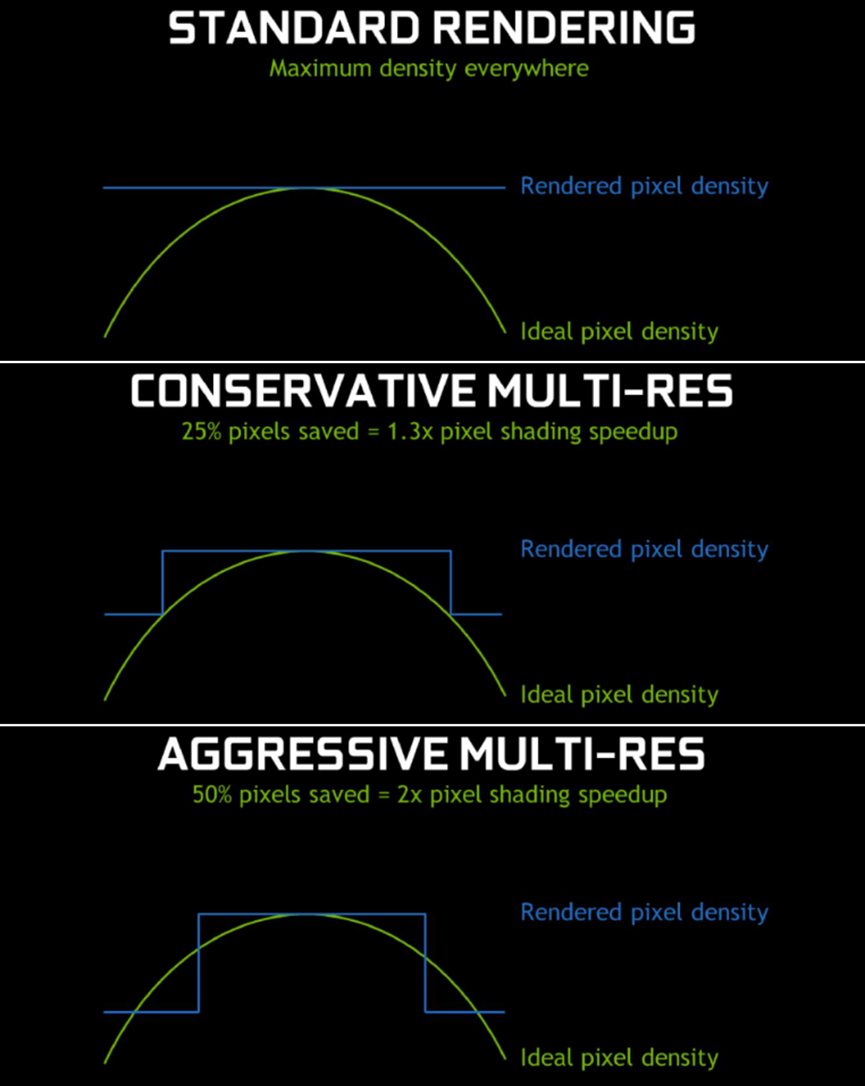
多分辨率着色的想法是将图像分割为多个视口(下图是一个3x3的网格)。我们保持“中心”视口的大小相同,但缩小边缘周围的所有视口。可以更好地近似于我们想要最终生成的扭曲图像,但不会浪费太多像素。而且,由于我们对像素进行着色处理的数量更少,因此渲染速度更快。根据缩小边缘的力度,可以在任何位置保存25%到50%的像素,转化为1.3倍到2倍的像素着色加速。

以下是几种渲染模式的着色像素对比:
2 立体和多视图渲染
视差是投影到两个立体图像中的3D点的相对距离,也是实现立体图像的常用技术,下图是三种不同的视差案例:

视觉系统仅使用水平视差,无垂直视差!粗略的前束法(toe-in)造成垂直视差,引起视觉不适(下图左):

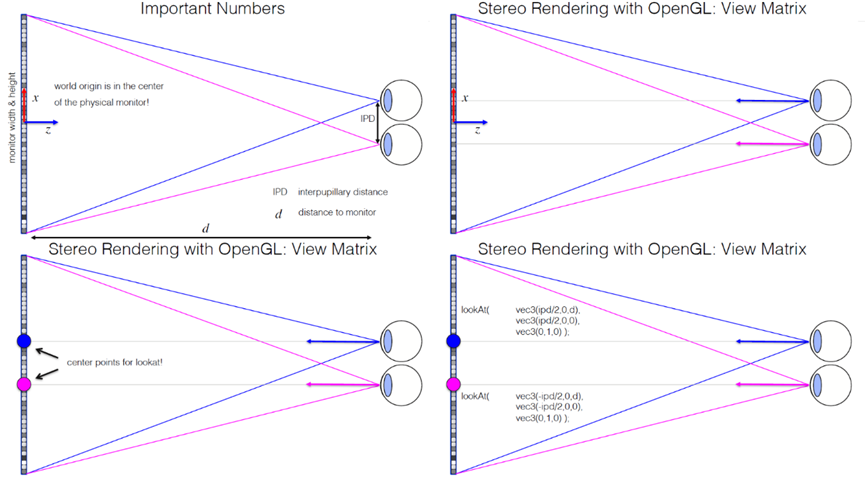
使用OpenGL/WebGL进行立体渲染:视图矩阵。需要修改视图矩阵和投影矩阵,渲染管线不变–仅这两个矩阵,但是需要按顺序渲染两幅图像。首先查看视图矩阵,编写自己的lookAt函数,该函数使用旋转和平移矩阵从eye、center、up参数生成视图矩阵,不要使用THREE.Matrix4().lookAt()函数,它不能正常工作!下面是使用OpenGL构造立体视图矩阵的过程:
上面讨论的透视投影是轴=对称的,我们还需要一种不同的方法来设置非对称离轴平截头体,可以使用THREE.Matrix4().makePerspective(left,right,top,bottom,znear,zfar)。
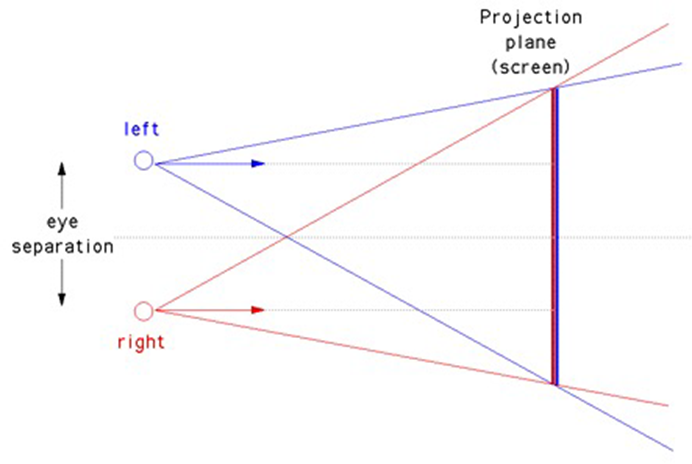
轴上和离轴的视锥体构造示意图如下:


使用OpenGL绘制立体图最有效的方式:
1、清晰的颜色和深度缓冲区。
2、设置左侧模型视图和投影矩阵,仅将场景渲染到红色通道。
3、清除深度缓冲区。
4、设置右侧模型视图和投影矩阵,仅将场景渲染到绿色和蓝色通道中。
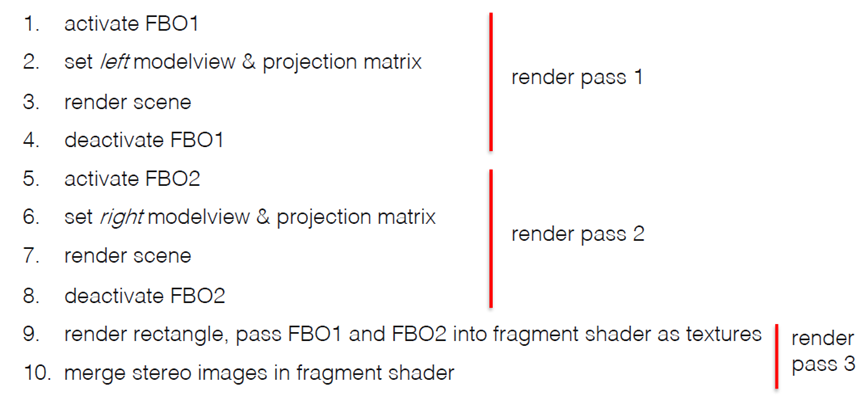
我们将以稍微复杂一点的方式完成(无论如何都需要其他任务):多个渲染过程,渲染到屏幕外(帧)缓冲区。
OpenGL帧缓冲区通常(帧)缓冲区由窗口管理器(即浏览器)提供,对于大多数单通道应用程序,有两个(双)缓冲区:后缓冲区和前缓冲区渲染到后缓冲区;完成后交换缓冲区(WebGL为您完成此操作!)。优点是渲染需要时间,不想让用户看到三角形是如何绘制到屏幕上的;仅显示最终图像,在许多立体声应用中,4个缓冲区:前/后左和右缓冲区,将左右图像渲染到后缓冲区中,然后将两者交换在一起。
更通用的方式是使用离屏缓冲区。OpenGL中最常见的屏幕外缓冲区形式:帧缓冲区对象,采用“渲染到纹理”的概念,但具有颜色、深度和其他重要的每片段信息的多个“附件”,尽可能多的帧缓冲区对象,它们都“活动”在GPU上(无内存传输),每种颜色的位深度:8位、16位、32位用于颜色附件;深度为24位。

FBO对于多个渲染通道至关重要!第1个通道:渲染FBO的颜色和深度,第2个通道:渲染纹理矩形–访问片段着色器中的FBO。
为了模拟人眼视网膜的模糊(失焦)效果,需要DOF(景深)的后处理来达成。方法有很多种,此处忽略。
与常见的应用程序渲染不同,每个帧的VR渲染需要同时渲染左眼和右眼的图像。在每个帧中,分别为左眼和右眼上的图像提交一个渲染任务。因此,VR渲染所占用的CPU/GPU资源是普通应用程序渲染所占用资源的两倍。为了解决这个问题,业界提出了多视图渲染技术,这样在只提交一个任务后,就可以同时渲染左眼和右眼的图像。左眼和右眼的图像的大部分信息是相同的,并且图像的视差仅略有不同。因此,在多视图渲染技术中,CPU只需向GPU提交一个渲染任务和视差信息,然后GPU就可以为左眼和右眼渲染图像,大大减少了CPU资源占用,提高了帧速率。
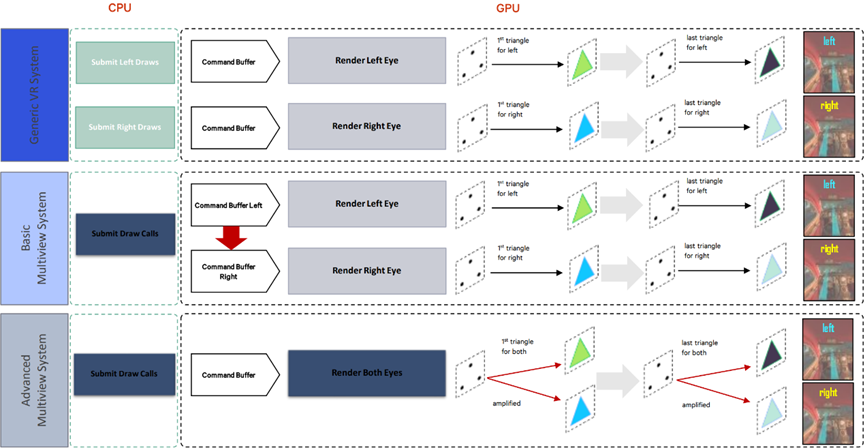
用于优化VR等渲染的MultiView对比图。上:未采用MultiView模式的渲染,两个眼睛各自提交绘制指令;中:基础MultiView模式,复用提交指令,在GPU层复制多一份Command List;下:高级MultiView模式,可以复用DC、Command List、几何信息。
Unity支持以下几种VR渲染模式:
- Multi-Camera。为了为每只眼睛渲染视图,最简单的方法是运行渲染循环两次。每只眼睛将配置并运行自己的渲染循环迭代。最后,将有两个图像可以提交到显示设备。底层实现使用两个Unity摄像头,每只眼睛一个,它们贯穿生成立体图像的过程。这是Unity中支持XR的最初方法,目前仍由第三方HMD插件提供。虽然这种方法确实有效,但多摄像头依赖于暴力,就CPU和GPU而言,效率最低。CPU必须在渲染循环中完全迭代两次,GPU很可能无法利用对眼睛绘制两次的对象的任何缓存。
- Multi-Pass。Multi-Pass是Unity优化XR渲染循环的最初尝试,核心思想是提取与视图无关的渲染循环部分,意味着任何不明确依赖于XR eye viewpoints的工作都不需要针对每只眼睛进行。这种优化最明显的候选者是阴影渲染,阴影并不明确依赖于摄影机查看器的位置。Unity实际上分两步实现阴影:生成级联阴影贴图,然后将阴影映射到屏幕空间。对于多通道,可以生成一组级联阴影贴图,然后生成两个屏幕空间阴影贴图,因为屏幕空间阴影贴图取决于查看器的位置。由于阴影生成的架构,屏幕空间阴影贴图受益于局部性,因为阴影贴图生成循环相对紧密耦合。可以与剩余的渲染工作负载进行比较,剩余的渲染工作负载需要在返回到类似阶段之前在渲染循环上进行完全迭代(例如,眼睛特定的不透明过程由剩余的渲染循环阶段分隔)。另一个可以在两只眼睛之间共享的步骤一开始可能并不明显:可以在两只眼睛之间执行一次剔除。在最初的实现中,使用了截锥剔除来生成两个对象列表,每只眼睛一个。然而,可以创建一个两只眼睛共享的统一剔除截锥。意味着每只眼睛的渲染量都会比使用单眼剔除截头体时稍微多一些,但单次剔除的好处超过了一些额外顶点着色器、剪裁和光栅化的成本。
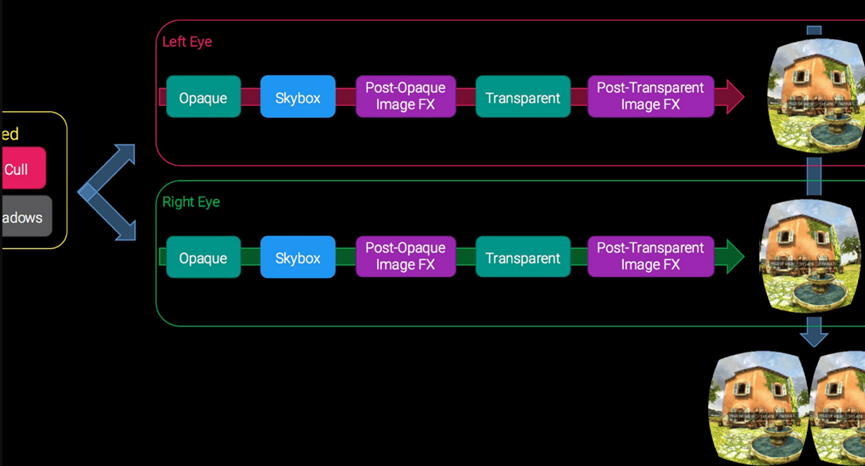
- Single-Pass。单通道立体渲染意味着将对整个renderloop进行一次遍历,而不是两次或某些部分两次。
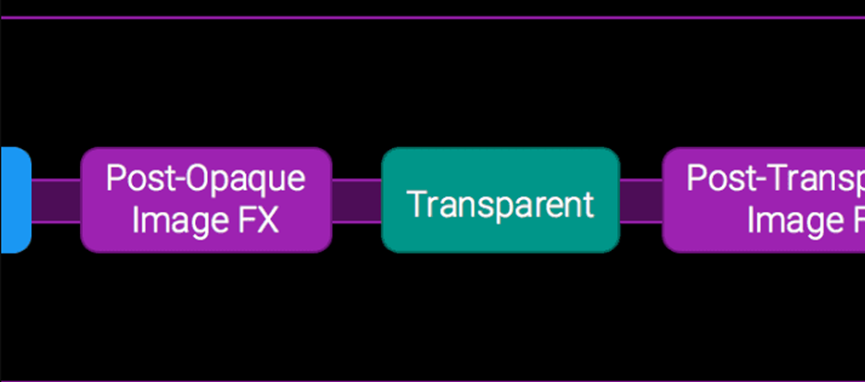
为了执行这两个绘制,需要确保所有常量数据都已绑定,并且还有一个索引。绘制结果如何?如何进行每次绘制调用?在多通道中,两只眼睛都有自己的渲染目标,但不能在单通道中这样做,因为在连续绘制调用中切换渲染目标的成本太高。一个类似的选项是使用渲染目标数组,但需要在大多数平台上从几何体着色器导出切片索引,这种操作在GPU上也可能很昂贵,并且对现有着色器具有侵入性。
确定的解决方案是使用双宽(Double Wide)渲染目标,并在绘制调用之间切换视口,允许每只眼睛渲染到双宽渲染目标的一半。虽然切换视口确实会带来成本,但它比切换渲染目标要少,并且比使用几何体着色器(尽管Double Wide有其自身的一系列挑战,尤其是在后处理方面)。还有使用视口数组的相关选项,但它们与渲染目标数组有相同的问题,因为索引只能从几何体着色器导出。
现在有了一个解决方案,可以开始两次连续绘制以渲染双眼,需要配置支持基础设施。在多通道中,因为它类似于单视图渲染,所以可以使用现有的视图和投影矩阵基础结构,只需将视图和投影矩阵替换为来自当前眼睛的矩阵。然而,对于单通道,不想不必要地切换常量缓冲区绑定。因此,可以将双眼的视图和投影矩阵绑定在一起,并使用unity_StereoEyeIndex对其进行索引,可以在绘图之间进行翻转。这允许着色器基础结构在着色器过程中选择要渲染的视图和投影矩阵集。
另一个细节:为了最小化视口和unity_StereoEyeIndex状态的更改,可以修改眼睛绘制模式,可以使用left、right、right、left、right等节奏,而不是绘制left、right、left、left等。这使我们能够将状态更新的数量减少一半,而不是交替的节奏。比多通道快不了两倍,因为已经针对消隐和阴影进行了优化,同时仍在调度每只眼睛绘制和切换视口,确实会产生一些CPU和GPU成本。
- Stereo Instancing (Single-Pass Instanced)。渲染目标数组是立体渲染的自然解决方案。眼睛纹理共享格式和大小,使其符合在渲染目标阵列中使用的条件,但使用几何体着色器导出数组切片是一个很大的缺点。我们真正想要的是能够从顶点着色器导出渲染目标数组索引,从而实现更简单的集成和更好的性能。从顶点着色器导出渲染目标数组索引的功能实际上存在于某些GPU和API上,并且越来越普遍。在DX11上,此功能作为功能选项VPAndRTArrayIndexFromAnyShaderFeedingRasterizer公开。
现在我们可以指定渲染目标数组的哪个切片,如何选择该切片?我们利用单通道双宽的现有基础架构。我们可以使用unity_StereoEyeIndex在着色器中填充SV_RenderTargetArrayIndex语义。在API方面,我们不再需要切换视口,因为相同的视口可以用于渲染目标数组的两个切片。我们已经将矩阵配置为从顶点着色器索引。
虽然我们可以继续使用现有的技术,即在每次绘制之前发出两次绘制并在常量缓冲区中切换值unity_StereoEyeIndex,但还有一种更有效的技术。我们可以使用GPU实例化来发出单个绘图调用,并允许GPU跨双眼多路复用绘制。我们可以将绘制的现有实例数加倍(如果没有实例使用,我们只需将实例数设置为2)。然后在顶点着色器中,我们可以对实例ID进行解码,以确定渲染到哪只眼睛。
使用此技术的最大影响是,我们实际上将在API端生成的绘制调用数量减少了一半,从而节省了大量CPU时间。此外,GPU本身能够更高效地处理绘图,即使生成的工作量相同,因为它不必处理两个单独的绘制调用。我们还可以通过不必在绘制之间更改视口来最小化状态更新,就像我们在传统的单过程中所做的那样。
请注意:此方法仅适用于在Windows 10或HoloLens上运行桌面VR体验的用户。
- Single-Pass Multi-View。Multi-View是某些OpenGL/OpenGL ES实现中可用的扩展,其中驱动程序本身处理双眼之间的单个绘制调用的多路复用。驱动程序负责复制绘制并在着色器中生成数组索引(通过gl_ViewID),而不是显式实例化绘制调用并将实例解码为着色器中的眼睛索引。有一个与立体实例化不同的底层实现细节:驱动程序本身决定渲染目标,而不是顶点着色器显式选择将被光栅化到的渲染目标数组切片。gl_ViewID用于计算视图相关状态,但不用于选择渲染目标。在使用中,这对开发人员来说并不重要,但却是一个有趣的细节。由于我们如何使用多视图扩展,我们能够使用为单过程实例构建的相同基础结构,开发人员可以使用相同的功能(scaffolding)来支持这两种单通道技术。
以下是Unity不同的VR渲染技术的性能对比:
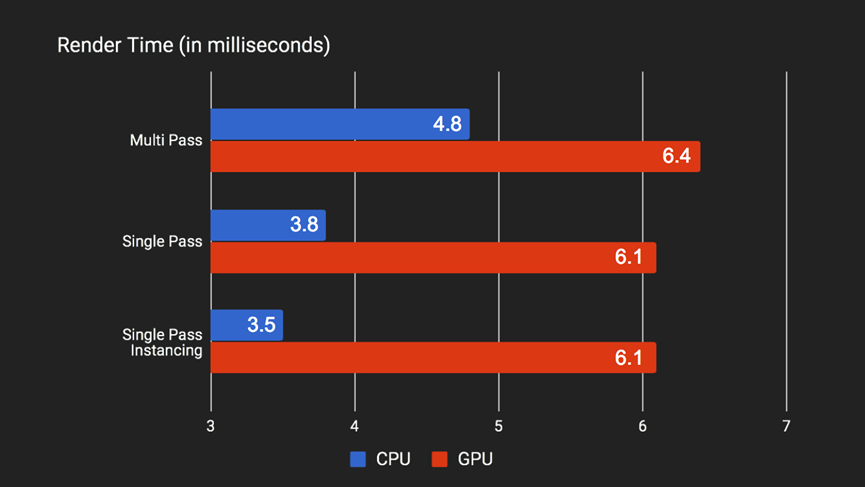
正如上图所示,单通道和单通道实例化代表了与多过程相比的显著CPU优势。但是,单通道和单通道实例化之间的增量相对较小,原因是切换到单通道已经节省了大量CPU开销。单通道实例化确实减少了绘制调用的数量,但与处理场景图相比,这一成本非常低。当考虑到大多数现代图形驱动程序都是多线程的时候,在调度CPU线程上发出draw调用可能会非常快。
3 光场渲染
现有的VR成像方法基本上是具有双目视差的2D成像方法。眼睛的焦点和汇聚点不会长时间保持在同一位置。前者位于屏幕平面上,后者位于双目视差生成的虚拟平面上。因此,会发生边缘调节冲突,导致头晕等生理不适和沉浸感丧失。
恢复现实世界中肉眼可见的内容可以恢复完美的沉浸感。通过改变焦距,眼睛可以在不同距离、不同位置和不同方向上收集物体表面反射的光。这一切的完整集合就是光场。该行业的一家供应商开发了一种光场摄像机,用于收集光场信息。光场渲染技术恢复采集到的光场信息,以满足用户更高的沉浸体验要求。光场信息的采集、存储和传输仍然面临着大量数据等许多基本问题,光场渲染技术仍处于初级阶段。然而,随着用户对VR体验的要求越来越高,它可能成为未来关键的渲染技术。
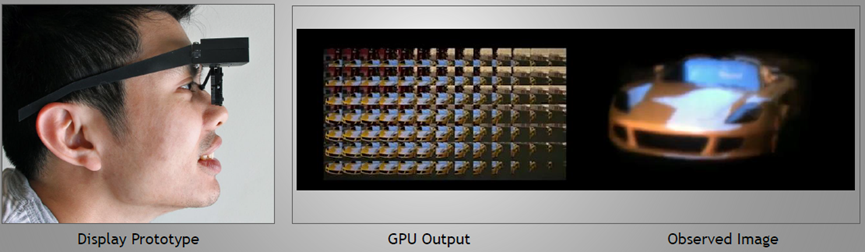
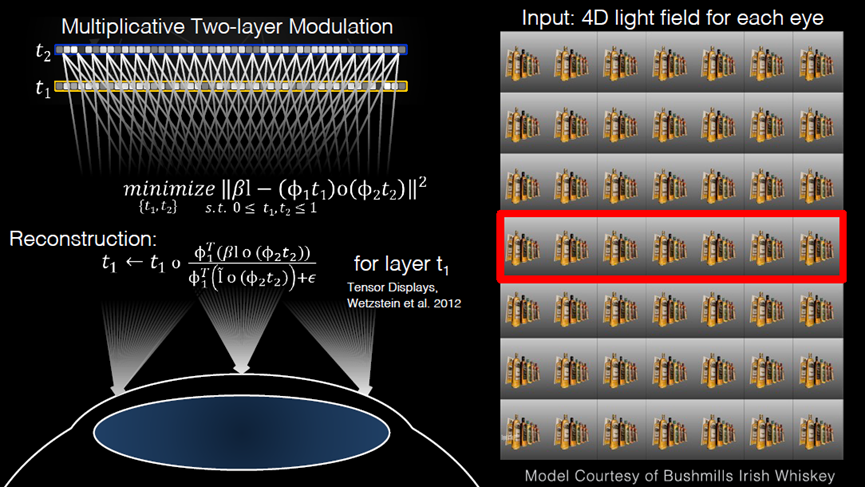
光场显示图示。
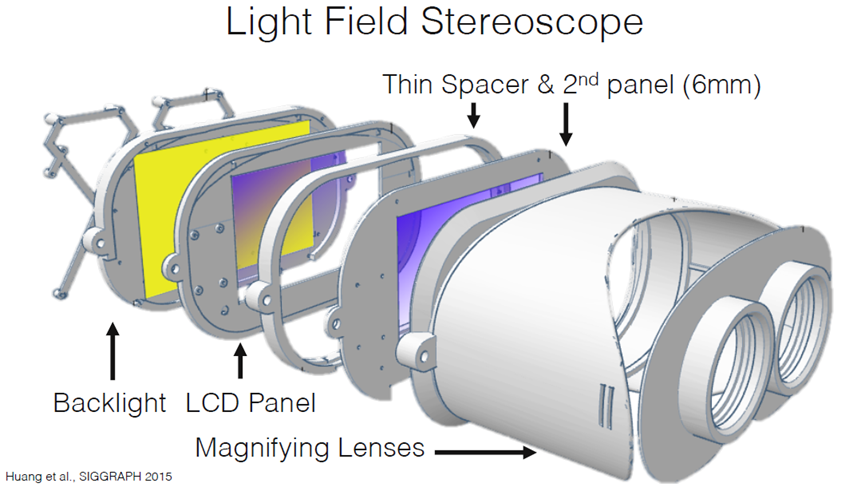
光场显示头显。

注视点光场渲染。
4 光影
对于切线空间轴对齐的各向异性照明,标准各向同性照明沿对角线表示,各向异性与任一相切空间轴对齐,只需要2个附加值与2D切线法线配对=适合RGBA纹理(DXT5>95%的时间)。
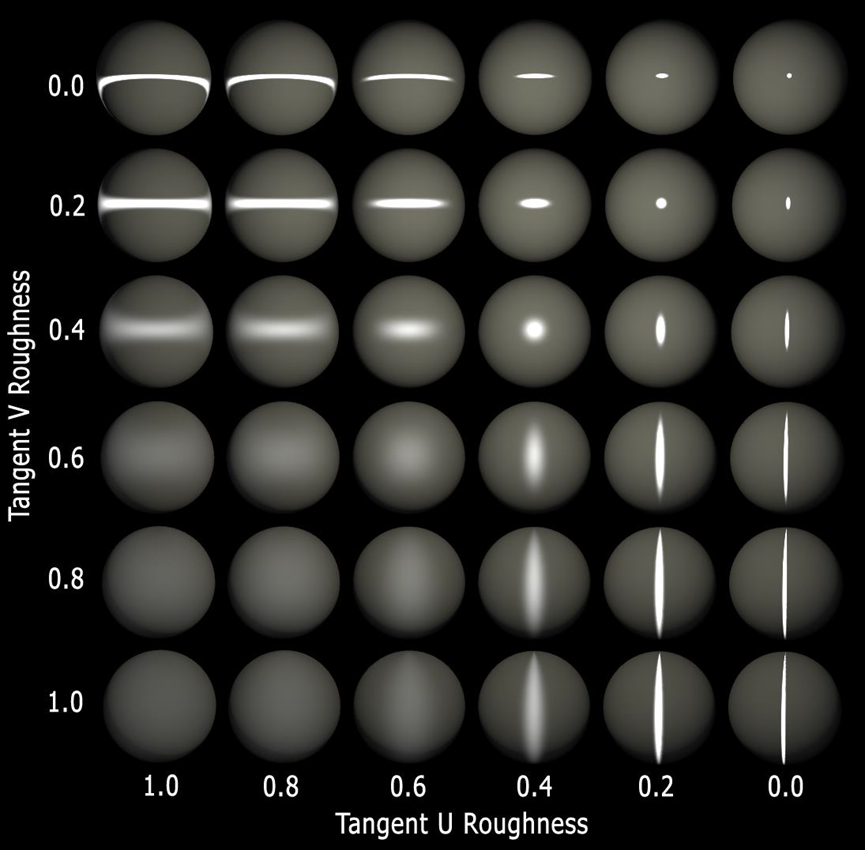
粗糙度到指数的转换:漫反射照明将Lambert提高到指数(N⋅Lk),其中k在0.6-1.4范围内尝,试了各向异性漫反射照明,但不值得这么做,镜面反射指数范围为1-16384,是具有各向异性的修改的Blinn-Phong。
void RoughnessEllipseToScaleAndExp(float2 vRoughness, out float o_flDiffuseExponentOut,out float2 o_vSpecularExponentOut,out float2 o_vSpecularScaleOut)
{
o_flDiffuseExponentOut=((1.0-(vRoughness.x+ vRoughness.y) * 0.5) *0.8)+0.6;// Outputs 0.6-1.4
o_vSpecularExponentOut.xy=exp2(pow(1.0-vRoughness.xy,1.5)*14.0);// Outputs 1-16384
o_vSpecularScaleOut.xy=1.0-saturate(vRoughness.xy*0.5);//This is a pseudo energy conserving scalar for the roughness exponent
}
各向异性的光照计算过程:

几何镜面锯齿:没有法线贴图的密集网格也会产生锯齿,粗糙度mips也无济于事!可以使用插值顶点法线的偏导数来生成近似曲率的几何粗糙度项。
float3 vNormalWsDdx = ddx(vGeometricNormalWs.xyz);
float3 vNormalWsDdy = ddy(vGeometricNormalWs.xyz);
float flGeometricRoughnessFactor = pow(saturate(max(dot(vNormalWsDdx.xyz, vNormalWsDdx.xyz), dot(vNormalWsDdy.xyz, vNormalWsDdy.xyz))), 0.333);
vRoughness.xy=max(vRoughness.xy, flGeometricRoughnessFactor.xx); // Ensure we don’t double-count roughness if normal map encodes geometric roughness

flGeometricRoughnessFactor的可视化。
MSAA中心与质心插值并不完美,因为过度插值顶点法线,法线插值可能会在轮廓处导致镜面反射闪烁。下面是文中使用的一个技巧:
// 插值法线两次:一次带质心,一次不带质心
float3 vNormalWs:TEXCOORD0;
centroid float3 vCentroidNormalWs:TEXCOORD1;
// 在像素着色器中,如果法线长度平方大于1.01,请选择质心法线
if(dot(i.vNormalWs.xyz, i.vNormalWs.xyz) >= 1.01)
{
i.vNormalWs.xyz = i.vCentroidNormalWs.xyz;
}
法线贴图编码:将切线法线投影到Z平面上仅使用2D纹理范围的约78.5%,而半八面体编码使用2D纹理的全部范围:
事实证明,1.4x只是HTC Vive的一个建议(每个HMD设计都有一个基于光学和面板的不同建议标量),在较慢的GPU上,缩小建议的渲染目标标量,在速度更快的GPU上,放大建议的渲染目标标量,尽量利用GPU的周期。
提高了显示器的分辨率(别忘了,VR的每度只有更少的像素),对于颜色和法线贴图,强制启用此选项,默认使用8x。禁用其它所有功能,仅三线性,但需要测量性能。如果在其它地方遇到瓶颈,各向异性过滤可能是“免费的”。
噪点是良师益友,在虚拟现实中,过渡很可怕,带状(banding)比液晶电视更明显,当像素着色器中有浮点精度时,可在帧缓冲区中添加噪点。
float3 ScreenSpaceDither(float2vScreenPos)
{
// Iestyn's RGB dither(7 asm instructions) from Portal 2X360, slightly modified for VR
float3 vDither = dot(float2(171.0, 231.0), vScreenPos.xy + g_flTime).xxx;
vDither.rgb = frac(vDither.rgb / float3(103.0, 71.0, 97.0)) - float3(0.5, 0.5, 0.5);
return (vDither.rgb / 255.0) * 0.375;
}
对于环境图,无穷远处的标准实现 = 仅适用于天空,需要为环境图使用某种类型的距离重新映射:球体很便宜,立方体更贵,两者在不同的情况下都很有用。
需要性能查询!总是保持垂直同步,禁用VSync查看帧率会让玩家头晕,需要使用性能查询来报告GPU工作负载,最简单的实现是测量从第一个到最后一个draw调用。理想情况下,测量以下各项:从Present()到第一次绘图调用的空闲时间、从第一次绘图调用到最后一次绘图调用、从上次绘图调用到现在的Present()的空闲时间。
5 射线检测
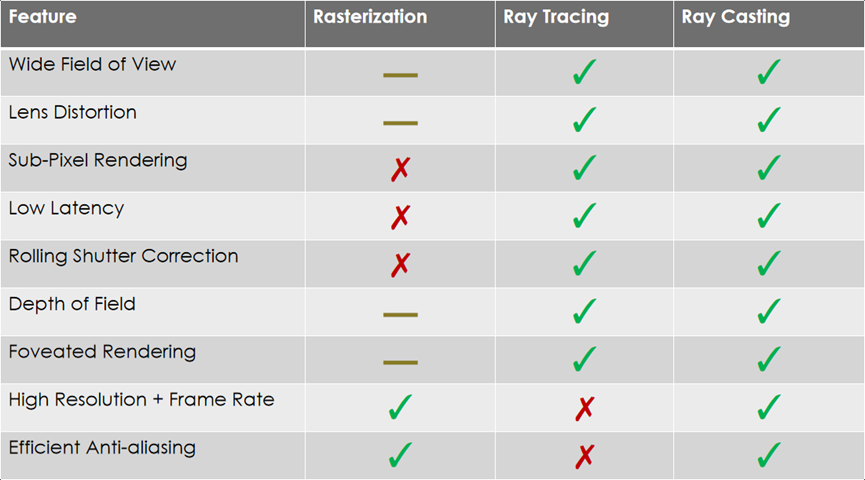
光线投射是VR/AR光栅化的可行替代方法。在VR中,一组新的要求是广阔的视野、透镜畸变、亚像素渲染、低延迟、滚动显示校正、景深、高分辨率和帧速率、注视点渲染、高效的抗锯齿等。
上述特性在不同的渲染方式支持表如下:
虚拟现实的层次可见性:每秒海量射线,包括商品硬件上的着色,完全动态场景支持,任意相干射线分布,包括非点原点!光线采样层次的构建过程示意图如下:

层次采样可获得缓存命中率的提升,亦即获得性能的提升:

抗锯齿
常见的抗锯齿方法有:
- 边缘几何AA,通常硬件加速;
- 图像空间AA,非常适合大多数渲染管线,如FXAA、MLAA、SMAA等;
- 时间AA,使用再投影进行时间超采样。
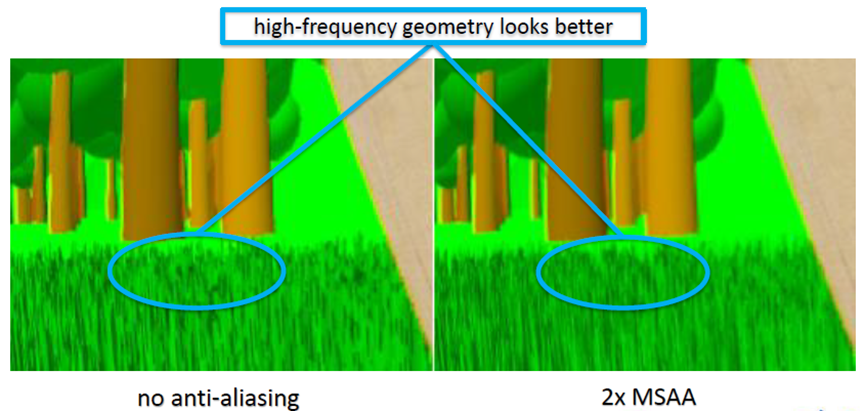

MSAA在高频几何体、几乎垂直的线条、对角线看起来更好,但内部纹理/着色仍然有锯齿。
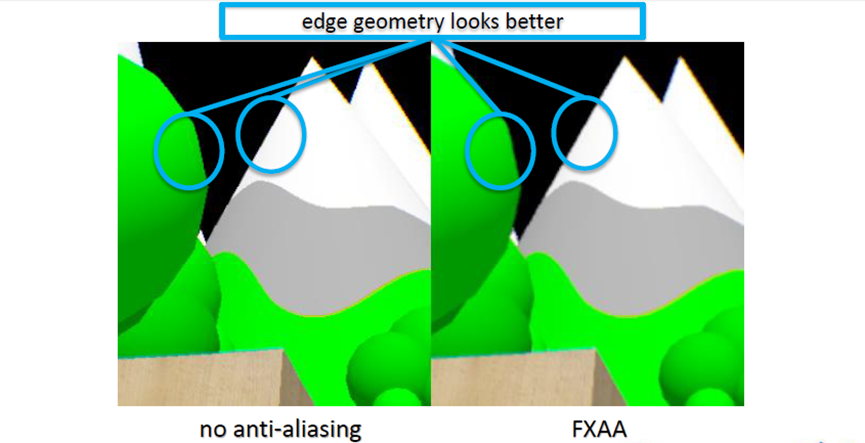

FXAA在边缘几何体、纹理/着色细节看起来更好,但有时会丢失高频数据中的细节。
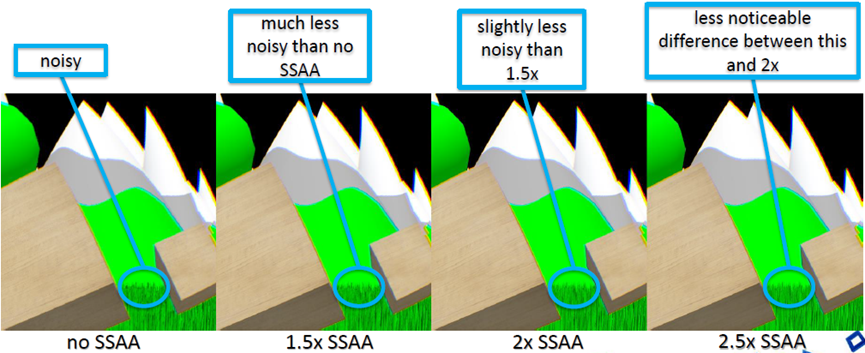
超采样反走样渲染到更大缓冲区的效果良好……如果负担得起的话,与良好的下采样过滤器一起使用。
镜面AA也可以大大改善图像,一个很好的起点是研究LEAN、Cheap LEAN (CLEAN)和Toksvig AA,扭曲着色器减少边缘锯齿,在某些游戏中,可能需要更多地关注LOD。几种AA方法的组合可能会产生更好的结果,每种不同的AA解决方案都能解决不同方面的锯齿问题,使用最适合引擎的方法。
锯齿是VR的头号敌人:相机(玩家的头)永远不会停止移动,因此,锯齿会被放大。虽然要渲染的像素更多,但每个像素填充的角度比以前做的任何事情都大,以下是一些平均值:2560x1600 30英寸显示器:约50像素/度(50度水平视场),720p 30英寸显示器:约25像素/度(50度水平视场),VR:约15.3像素/度(110度视场,是非VR的1.4倍),必须提高像素的质量。
4xMSAA最低质量:前向渲染器因抗锯齿而获胜,因为MSAA正好有效,如果性能允许,使用8xMSAA,必须将图像空间抗锯齿算法与4xMSAA和8xMSAA并排进行比较,以了解渲染器将如何与业内其它渲染器进行比较,使用HLSL的“sample”修饰符时,抖动的SSAA显然是最好的,但前提是可以节省性能。
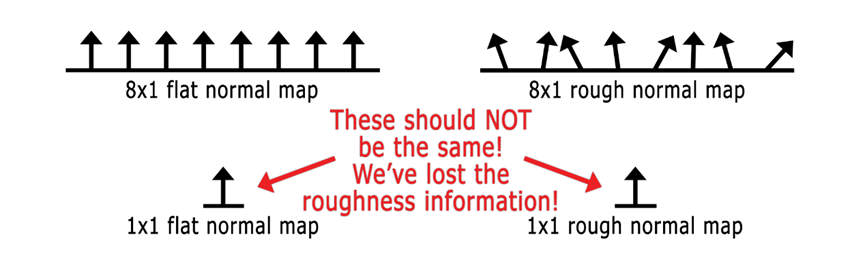
法线贴图依然可用,大多数法线贴图在虚拟现实中效果都很好。无效的情况:跟踪体积内大于几厘米的特性细节不好,以及被跟踪体积内的表面形状不能在法线贴图中。有效的情况:无法近距离查看的被跟踪体积外的远处物体,以及表面“纹理”和精细细节。法线贴图映射错误:

任何只生成平均法线的mip过滤器都会丢失重要的粗糙度信息:

用Mips编码的粗糙度:可以存储一个各向同性值(可视为圆的半径),是所有2D切线法线与促成该纹理的最高mip的标准偏差,还可以分别存储X和Y方向标准偏差的二维各向异性值(可视化为椭圆的尺寸),该值可用于计算切线空间轴对齐的各向异性照明!


添加艺术家创作的粗糙度,创作了2D光泽=1.0–粗糙度,带有简单盒过滤器的Mip,将其与每个mip级别的法线贴图粗糙度相加/求和,因为有各向异性光泽贴图,所以存储生成的法线贴图粗糙度是免费的。

左:各向同性光泽度;右:各向异性光泽度。
XR优化
单GPU情况下,单个GPU完成所有工作,立体渲染可以通过多种方式完成(本例使用顺序渲染),阴影缓冲区由两只眼睛共享。多GPU亲和API,AMD和NVIDIA有多个GPU亲和API,使用关联掩码跨GPU广播绘制调用,为每个GPU设置不同的着色器常量缓冲区,跨GPU传输渲染目标的子矩形,使用传输栅栏在目标GPU仍在渲染时异步传输。2个GPU时,每个GPU渲染一只眼睛,两个GPU都渲染阴影缓冲区,“向左提交”和“应用程序窗口”在传输气泡中执行,性能提高30-35%。4个GPU时,每个GPU渲染一只眼睛的一半,所有GPU渲染阴影缓冲区,PS成本成线性比例,VS成本则不是,驱动程序的CPU成本可能很高。

从上到下:1个、2个、4个GPU渲染示意图。
投影矩阵与VR光学:投影矩阵的像素密度分布与我们想要的相反,投影矩阵在边缘每度像素密度增加,VR光学在中心像素密度增加,我们最终在边缘过度渲染像素。使用NVIDIA的“多分辨率着色”,可以在更少的CPU开销下获得额外约5-10%的GPU性能。

径向密度遮蔽(Radial Density Masking):跳过渲染2x2像素方块的棋盘格图案,以匹配当前的GPU架构。

重建滤波器的过程如下:

径向密度遮蔽的步骤:
- 渲染时Clip掉2x2的像素方块,或使用2x2的棋盘格图案填充模板或深度,然后进行渲染。
- 重建滤波器。
在Aperture Robot Repair中节省5-15%的性能,使用不同的内容和不同的着色器可以获得更高的增益,如果重建和跳过像素的开销没有超过跳过像素四元体的像素着色器节省,那么就是一次wash。在低端GPU上几乎总是能节省很多工作。
处理漏帧,如果引擎未达到帧速率,VR系统可以重用最后一帧的渲染图像并重新投影:仅旋转重投影、位置和旋转重投影,用重投影来填充缺失的帧应该被视为最后的安全网。请不要依赖重投影来维持帧率,除非目标用户使用的GPU低于应用程序的最低规格。
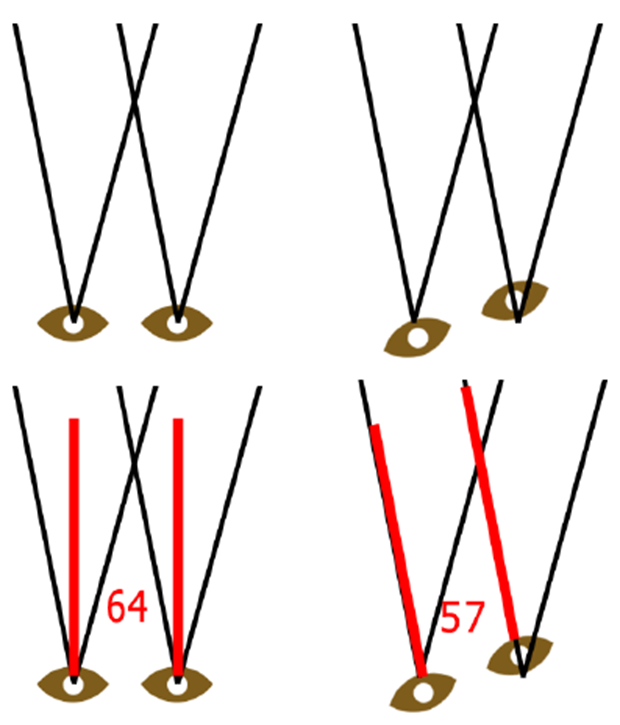
仅旋转重投影:抖动是由摄影机平移、动画和被跟踪控制器移动的对象引起的,抖动表现为两个不同的图像平均在一起。

旋转重投影是以眼睛为中心,而不是以头部为中心,所以从错误的位置重投影,ICD(摄像机间距离)根据旋转量在重投影过程中人为缩小。
好的一面:几十年来,人们对算法有了很好的理解,并且可能会随着现代研究而改进,即使有已知的副作用,它也能很好地处理单个漏帧。所以…有一个非常重要的折衷方案,它已足够好,可以作为错过帧的最后安全网,总比丢帧好。
位置重投影:仍然是一个非常感兴趣的尚未解决的问题,在传统渲染器中只能获得一个深度,因此表示半透明是一个挑战(粒子系统),深度可能存储在已解析颜色的MSAA深度缓冲区中,可能会导致颜色溢出。对于未表示的像素,孔洞填充算法可能会导致视网膜竞争,即使有许多帧的有效立体画面对,如果用户通过蹲下或站起来垂直移动,也有需要填补空白。
异步重投影:理想的安全网,要求抢占粒度等于或优于当前一代GPU,根据GPU的不同,当前GPU通常可以在draw调用边界处抢占
,目前还不能保证vsync能够及时重新发布。应用程序需要了解抢占粒度。
交错重投射提示:旧的GPU不能支持异步重投影,所以需要一个替代方案,OpenVR API有一个交错重投影提示,如果底层系统不支持始终开启的异步重投影,应用程序可以每隔一次请求仅限帧旋转的重投影。应用程序获得约18毫秒/帧的渲染。当应用程序低于目标帧率时,底层VR系统还可以使用交错重投影作为自动启用的安全网,每隔一帧重新投影是一个很好的折衷。
维持帧率很难,虚拟现实比传统游戏更具挑战性,因为用户可以很好地控制摄像机,许多交互模型允许用户重新配置世界,可以放弃将渲染和内容调整到90fps,因为用户可以轻松地重新配置内容,通过调整最差的20%体验,让Aperture Robot Repair达到了帧率。
自适应质量:它通过动态更改渲染设置以保持帧率,同时最大限度地提高GPU利用率。目标是减少掉帧和重投影的机会和在有空闲的GPU周期时提高质量。例如,Aperture Robot Repair VR演示使用两种不同的方法在NVIDIA 680上以目标帧率运行。利益是适用于应用程序的最低GPU规格,增加了艺术资产限制——艺术家现在可以在保真度稍低的渲染与更高的多边形资产或更复杂的材质之间进行权衡,不需要依靠重投影来维持帧率,意想不到的好处:应用程序在所有硬件上都看起来更好。
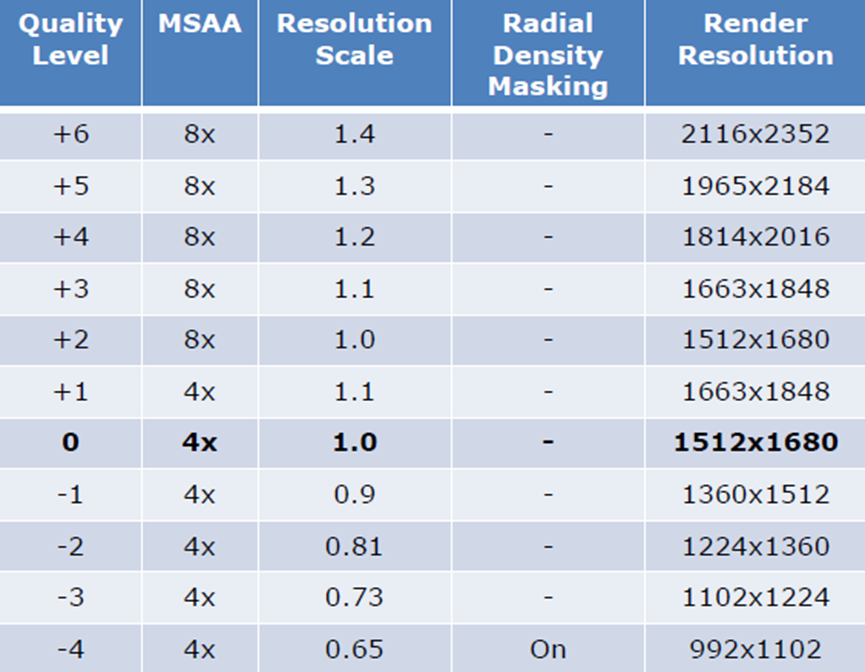
在VR中,无法调整的:无法切换镜面反射等视觉功能,无法切换阴影。可以调整的内容:渲染分辨率/视口(也称为动态分辨率)、MSAA级别或抗锯齿算法、注视点渲染、径向密度遮蔽等。自适应质量示例(黑体是默认配置):
测量GPU工作负载:GPU工作负载并不总是稳定的,可能有气泡,VR系统GPU的工作量是可变的:镜头畸变、色差、伴侣边界、覆盖等。从VR系统而不是应用程序获取计时,例如,OpenVR提供了一个总的GPU计时器用于计算所有GPU工作。

GPU定时器-延迟,GPU查询已经有1帧了,队列中还有1到2个无法修改的帧。

实现细节——3条规则,目标是保持70%-90%的GPU利用率。
- 高GPU利用率=帧的90%(10.0ms),大幅度降低:如果最后一帧在GPU帧的90%阈值之后完成渲染,则降低2级,等待2帧。
- 低GPU利用率=帧的70%(7.8毫秒),保守地增加:如果最后3帧完成时低于GPU帧的70%阈值,则增加1级,等待2帧。
- 预测=帧的85%(9.4ms),使用最后两帧的线性外推来预测快速增长,如果最后一帧高于85%阈值,线性外推的下一帧高于高阈值(90%),则降低2个级别,等待2帧。
10%空闲的规则:90%的高阈值几乎每帧都会让10%的GPU空闲用于其它处理,是件好事。需要与其它处理共享GPU,即使Windows桌面每隔几帧就需要一块GPU。对GPU预算的心理模型从去年的每帧11.11ms变为现在的每帧10.0ms,所以你几乎永远不会饿死GPU周期的其它处理。
解耦CPU和GPU性能,使渲染线程自治,如果CPU没有准备好新的帧,不要重投影!相反,渲染线程使用更新的HMD姿势和动态分辨率的最低自适应质量支持重新提交最后一帧的GPU工作负载。要解决动画抖动问题,请为渲染线程提供两个动画帧,可以在它们之间进行插值以保持动画更新,但是,非普通的动画预测是一个难题。然后,可以计划以1/2或1/3 GPU帧速率运行CPU,以进行更复杂的模拟或在低端CPU上运行。
总之,所有虚拟现实引擎都应支持多GPU(至少2个GPU),注视点渲染和径向密度遮蔽是有助于抵消光学与投影矩阵之争的解决方案,Adaptive Quality可上下缩放保真度,同时将10%的GPU用于其它进程,不要依靠重投影来达到最小规格的帧率!考虑引擎如何通过在渲染线程上重新提交来分离CPU和GPU性能。
技术和设计的优化思路是边开发边优化,编码和构建网格以实现可扩展性,跨所有计划的VR支持硬件进行测试,尽早发现问题。性能方面,可以使用mocap:以动作为导向,支持VR现场表演的表演风格,在VR中指导VR,块状化(blocking)以充分利用空间。
在近两年,移动VR的新挑战是具有长视线的可探索世界,更多角色,更长、更具互动性的电影,拥有各种武器、库存和收藏品等。游戏线程挑战是移动复杂组件层次结构,诞生/销毁卡顿,战斗中的非战斗更新,CPU停顿。
组件层次结构的一般情况:Actor组件而非场景组件,范围内的移动,复杂层次结构每帧最多移动一次,需要时拆离/重新附加。组件层次结构的骨架网格:分离优化:分离骨架网格组件,使用动画图形将根骨骼移动到其应位于的位置,用于玩家棋子、所有敌人和战斗中出现的所有电影角色。缺点是某些动画节点需要修复,部件位置不再正确。组件层次结构的重叠:默认情况下会出现大量不必要的重叠,UE物理/碰撞选项培训,如果可能,切换到保留目标列表。
大多数卡顿问题(hitch)来自actor和组件的诞生/销毁,通过池系统重用对象,提前生成所有内容,使用最高限制。对于非战斗逻辑,添加玩家距离系统以减少战斗中的影响,如果玩家距离太远,则取消放置的物品。游戏线程停顿的原因可能是Quest设备只有少量核心,渲染、音频和游戏同时要求,有些仍然可以解决。Unreal Insights可以帮助查明停顿的原因,对性能的影响比stat capture小,缺点是任务设置很棘手,从4.24开始,没有对象名称使解释变得棘手,无法启动/停止捕获。游戏线程停顿的提示:了解任务图系统,注意勾选先决条件,并行作业可能会被迫提前完成,导致停顿。
其他游戏线程提示:无蓝图tick,tick上没有蓝图可实现/蓝图原生事件,支持非动态委托,谨防蓝图计时器/时间表。
渲染的挑战包含内存、GPU、绘制调用、复杂着色器、复杂的动画、复杂的环境等因素。预计算的可见性(PCV),避免视觉跳变,高采样设置,最大化偶然性,小单元格。效率:设置/维护,计算时间。PCV步骤包含选择性网格放置、导航网格单元放置、世界设置公开配置(栈的单元格数、采样设置、网格数量阈值):
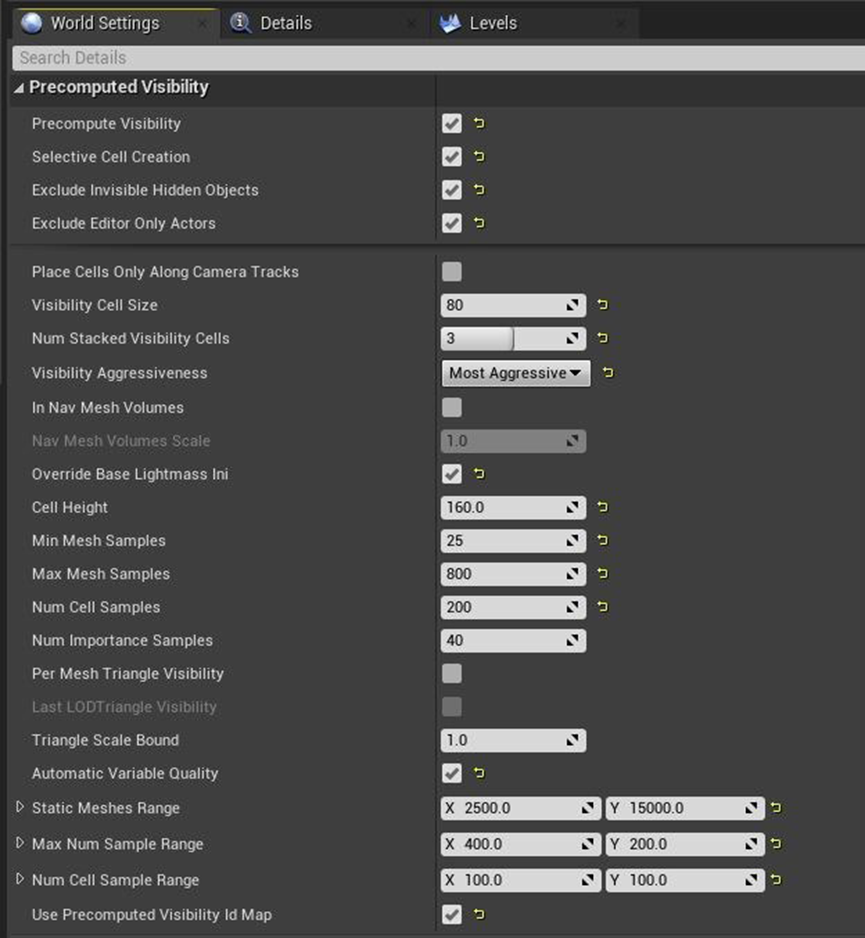
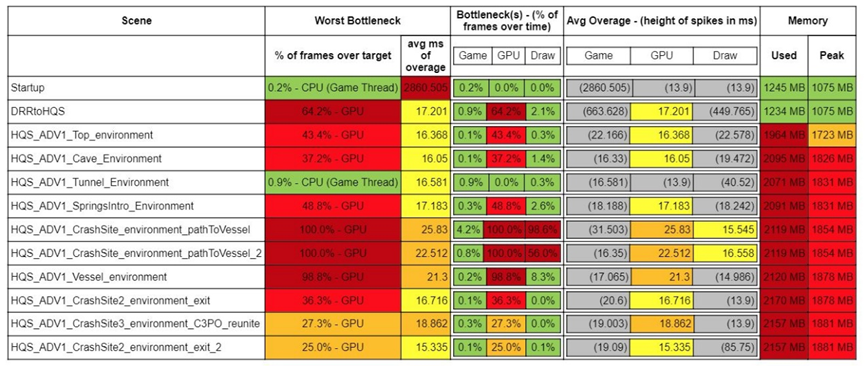
测试场景的各个阶段瓶颈一览:
此外,可以启用HLOD(层次LOD)、自定义HLOD:
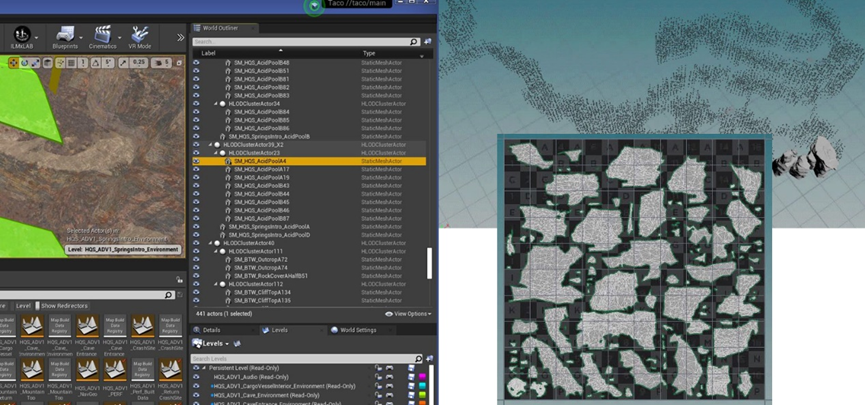
始终打开HLOD,消除过渡POP,消除光照贴图LOD POP,删除源网格,增加光照图分辨率,减少PCV计算,保持实例化碰撞。动态分辨率可以动态调整视口大小,不会产生额外的成本,利用Oculus Rift动态分辨率覆盖。
视觉增强功能:菜单的立体图层(口袋)、移动端视差反射、前向渲染贴花。顶点动画:电影级rigid解算器工具,4000多个动画对象,插值,程序性覆盖。顶点变形和实例化:多个实例,变体,带烘焙光探针采样的自发光。顶点动画和实例化:电影管线的群体工具,200个动画角色,通过图集化实现额外变化。

在UI和场景元素中使用易于阅读的文本。有几种方法可以确保VR中的文本易读性。出于渲染目的,建议在应用程序中使用带符号的距离场字体,可以确保字体即使在缩放或缩小时也能平滑呈现。还应该考虑应用程序支持的语言,组合字母组合的复杂性可能会影响易读性,例如,应用程序可能希望使用一种能够很好地支持东亚语言的字体。本地化还可能影响文本布局,因为某些语言在同一副本中使用的字母比其他语言多。场景中的字体大小和位置也很重要,对于Gear VR,选择大于30 pt的字体通常会在4.5m(单位)的固定z深度处提供最小的易读性,大于48磅通常可以确保舒适的阅读体验。对于Rift,大于25 pt的字体大小将在4.5m(统一)的固定z深度处提供最小的易读性,大于42磅通常可以确保舒适的阅读体验。
闪烁在模拟器疾病的动眼神经成分中起着重要作用,通常被视为部分或全部屏幕上亮度和黑暗的快速“脉冲”。用户感知闪烁的程度是多个因素的函数,包括:显示器在“开”和“关”模式之间循环的速率、“开”阶段发出的光量,视网膜的哪些部分受到刺激,甚至是一天中的时间和个人的疲劳程度。虽然闪烁会随着时间的推移变得不那么明显,但它仍然会导致头痛和眼睛疲劳。有些人对闪烁极为敏感,因此会感到眼睛疲劳、疲劳或头痛。其他人甚至不会注意到它或有任何不良症状。尽管如此,仍有某些因素可以增加或减少任何给定人员感知显示闪烁的可能性。
首先,人们对周围的闪烁比视觉中心的闪烁更敏感。其次,屏幕图像越亮,闪烁就越多。明亮的图像,尤其是外围(例如,站在明亮的白色房间中)可能会产生明显的显示闪烁。尽可能使用较深的颜色,尤其是玩家视角中心以外的区域。通常,刷新率越高,闪烁越不易察觉。
不要故意创建闪烁的内容。高对比度、闪光(或快速交替)刺激可引发某些人的光敏性癫痫发作。与此相关的是,高空间频率纹理(如精细的黑白条纹)也可以触发光敏性癫痫发作。国际标准组织发布了ISO 9241-391:2016作为图像内容标准,以降低光敏性癫痫发作的风险,该标准解决了潜在的有害闪光和模式。必须确保内容符合图像安全方面的标准和最佳做法。
使用视差贴图代替法线贴图。法线贴图提供真实的照明提示,以传达深度和纹理,而无需添加给定3D模型的顶点细节。虽然在现代游戏中广泛使用,但在立体3D中观看时,它的吸引力要小得多。因为法线贴图不考虑双目视差或运动视差,所以它会生成类似于绘制在对象模型上的平面纹理的图像。视差映射建立在法线映射的基础上,但法线映射不能解释景深。视差贴图通过使用内容创建者提供的附加高度贴图来移动采样表面纹理的纹理坐标。使用在着色器级别计算的逐像素或逐顶点视图方向应用纹理坐标偏移。视差贴图最好用于具有不会影响碰撞曲面的精细细节的曲面,例如砖墙或鹅卵石路径。
为开发的平台应用适当的失真校正。VR设备中的镜头会扭曲渲染图像,此失真通过SDK中的后处理步骤进行校正。根据SDK指南正确执行此失真非常重要,不正确的失真可以“看起来”相当正确,但仍然会感到迷失方向和不舒服,因此关注细节至关重要。所有扭曲校正值都需要与物理设备匹配,其中任何一个都不能由用户调整。
总之,详细的优化方法,解锁视觉改善技术,增强的交互和游戏机制,Quest 2有着显著的性能提升和用户体验提升。
其它
早期的XR SDK通常可以有限地支持SLAM定位和深度映射,并且同时地定位和映射:创建地图,同时跟踪您在其中的位置,最初是为机器人技术开发的,包括第一艘火星探测器,新设备具有额外的处理能力,包括所谓的“MVU”来帮助处理。SLAM限制是凌乱的房间比干净的房间好,运动模糊、照明会导致与图像目标识别和跟踪类似的问题。深度摄影机限制是分辨率低于彩色摄像机,需要插值深度点,低帧速率,网格化时必须非常缓慢地移动相机,IR不适用于反射表面(窗户、镜子等)。
对于VR的音频,虽然电影声音和游戏声音之间可能存在相似之处,但在将声音理论和概念从两者转换为电影VR时,也存在着值得注意的显著差异。

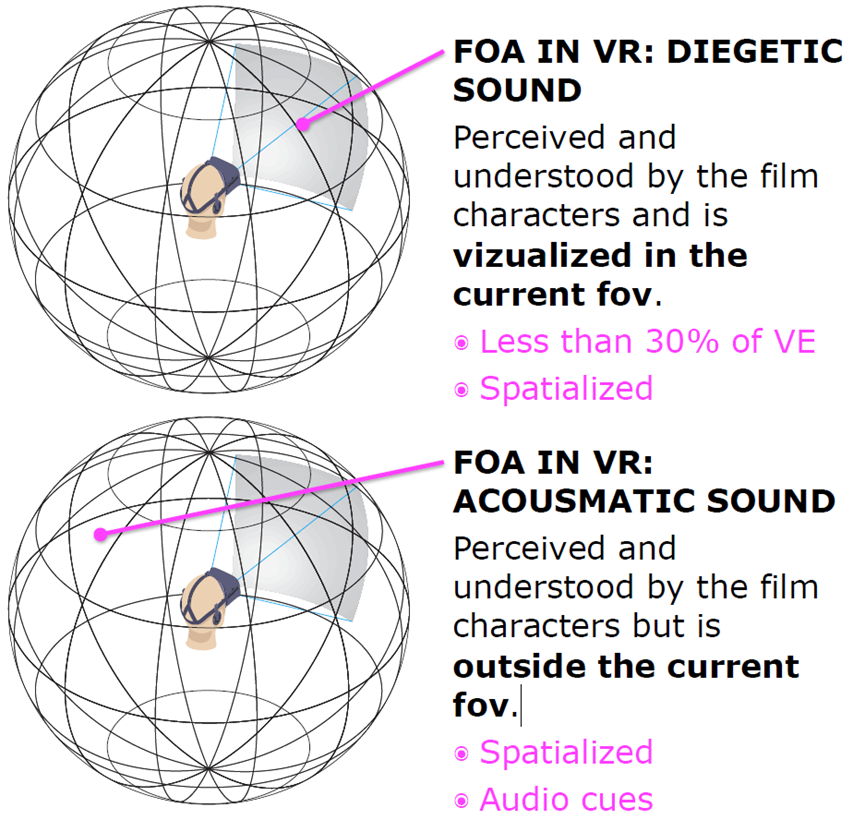
沉浸(Immersion)和现场(Presence)是两件不同的事情,身临其境的音频是实现存在感的一个关键因素,以及电影摄影、阻挡、表演等,而不仅仅是使用位置音频。VR中的FOA有4种声音:一种是被电影人物感知和理解,并在当前视野中可视化(下图上);还有一种是电影角色感知和理解的声音,但不在当前的fov范围内(下图下);还有非/画外音——角色听不到,但观众认为是伴随着屏幕上的动作,可能是解释动作;以及METADIEGETIC声音——观众角色的想象或幻觉,它是VE的一部分,但其他角色听不到。
Conemarching in VR: Developing a Fractal experience at 90 FPS阐述了VR下的分形算法和RayMarch的优化技术。
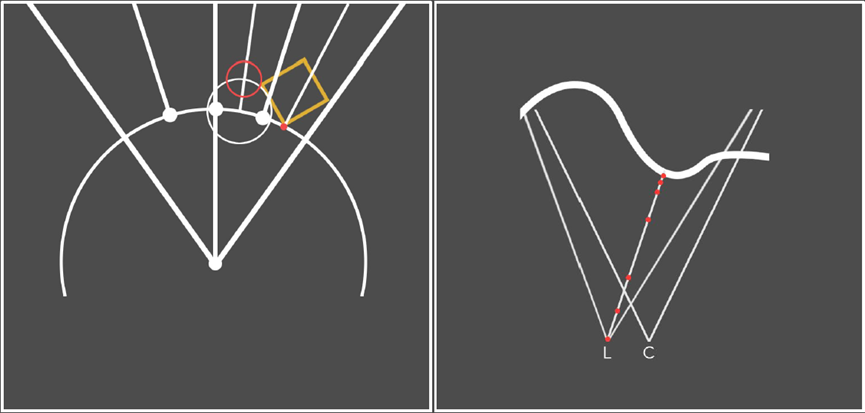
左:射线行进优化,其思想是以不同的分辨率逐步渲染同一场景,每次通过时,球体跟踪,直到我们不能保证没有交点为止,将分辨率提高一倍并重复使用距离,通常需要一些偏差。右:为了解决渲染所有内容两次,可以重新投射深度,使用圆锥体绘制器渲染中心眼,重新投射到左眼和右眼,屏幕空间光线水平偏移行进,为了获得更好的聚集距离,在较低分辨率下使用锥形通道。

使用conemarcher,必须计算两次深度,现在可以直接切断大部分管线,重投影通道通常很快,性能与控制过程成比例提高,着色过程需要进行一些调整,因为某些重投影估计值并不完美。

渲染着色仍然很昂贵,不需要太多关于外围的细节,需要一些动态的东西,可以根据分形进行缩放,并且取决于硬件,在外围以半分辨率渲染,在中心以全分辨率渲染,并混合边(图左和图中)。最后合成结果,较强的暗角节省了一些计算时间(图右)。
此外,在VR中,阴影、法线、遮挡、SSS开销都很大!文中提出了不少优化措施,包含:不要渲染太远,使用均匀散射将其隐藏,深度估计的时间重投影,低频效应重投影,使用屏幕空间法线减少着色复杂性,在外围使用较低质量的着色,使用立体重投影视差提供的轮廓实现TAA+FXAA。
CocoVR - Spherical Multiprojection介绍了球形多投影技术,包含球面投影简介、实践中的球面投影、Art管线、算法细节、开发工具等。球形投影类似于拍摄360度图像并将其应用于skydome,将其应用于场景中的大部分几何体,而不是应用于背景以模拟天空,很多VR体验都是从一个角度出发的。

映射的代码如下:
float2((1 + atan2(InVector.x, - InVector.y) / 3.14159265) / 2, acos(InVector.z) / 3.14159265);
球形多重投影着色器算法如下:
- 对于每个像素:
- 根据探针的深度立方图测试可见性。如果探针可见,则将其穿过计分系统。其中可见性测试过程:
- 每个探测器都包含从其位置渲染的深度立方体贴图。离线渲染。
- Unity不支持用于存储深度的更高精度立方体贴图格式。
- 使用不同的32位浮点编码函数。大多数情况下,可尝试在值中引入了太多的不稳定性,当你远离探测器时,误差会变得更大,增加一个小偏差,随着距离的增加略有增加。
- 从未测试存储深度值的拉特朗(latlong)纹理。可能会解决cubemaps的部分或全部问题。
- 根据探针的深度立方图测试可见性。如果探针可见,则将其穿过计分系统。其中可见性测试过程:

探针可见性视图模式有助于放置探针。
- 最佳探头的投影颜色。还可以添加等级库和反射。
- 如果没有找到探测器,可以回退到单一的颜色,使用全局指定探测器的颜色,使用顶点颜色选择要使用的探测器。
以上技术看起来很棒,开销较低,最昂贵的是每只眼睛渲染大约0.8毫秒。意味着可以用其他很酷的东西来扩展这项技术,可能会占用大量内存,小几何体可能会有问题,因为深度立方体贴图的分辨率不够高(通常约512)。
高质量的移动虚拟现实(VR)是即将到来的图形技术时代的要求:世界各地的用户,无论其硬件和网络条件如何,都可以享受沉浸式的虚拟体验。然而,由于用户行为的高度交互性和VR执行过程中复杂的环境约束,基于最先进软件的移动VR设计无法完全满足实时性能要求。受独特的人类视觉系统效果以及VR运动特征与实时硬件级别信息之间的强相关性的启发,Q-VR: System-Level Design for Future Mobile Collaborative Virtual Reality提出了Q-VR,这是一种通过软硬件协同设计实现未来低延迟高质量移动VR的新型动态协同渲染解决方案。在软件层面,Q-VR提供灵活的高级调整界面,以减少网络延迟,同时保持用户感知。在硬件层面,Q-VR通过有效利用日益强大的VR硬件的计算能力,适应了用户广泛的硬件和网络条件。对真实游戏的广泛评估表明,Q-VR可以达到平均水平与商用VR设备中的传统本地渲染设计相比,端到端性能提高了3.4倍(高达6.7倍),与最先进的静态协同渲染相比,帧速率提高了4.1倍。

Q-VR的软硬件代码设计的处理图。
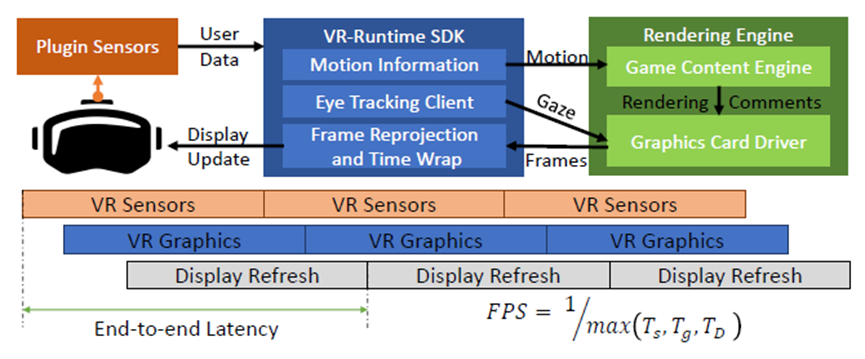
现代VR图形管线示例。
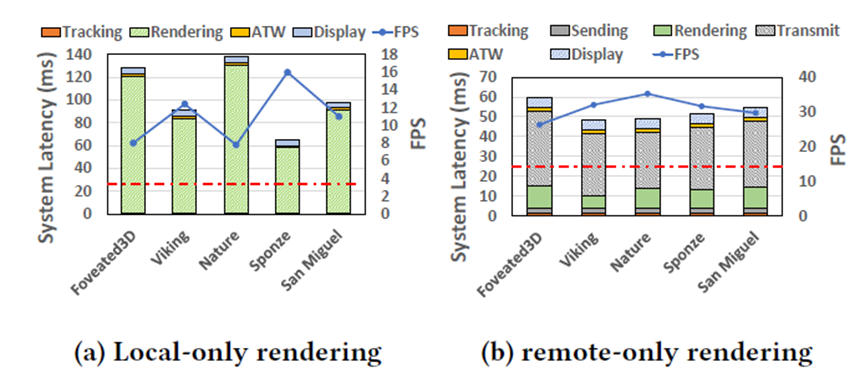
在当前两种移动VR系统设计上运行高端VR应用程序时的系统延迟和FPS。
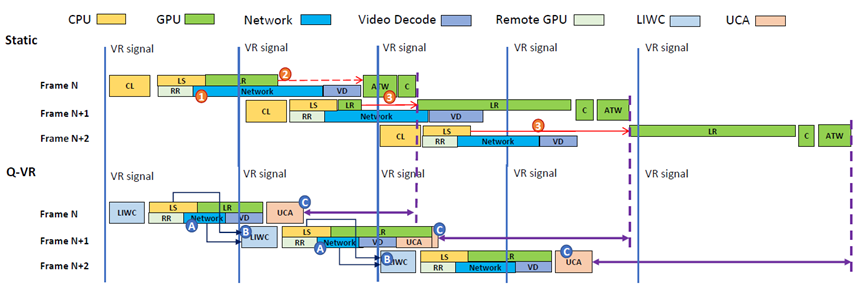
静态协同渲染的执行管线和Q-VR,Q-VR的软件和硬件优化反映在管线上。渲染任务在概念上映射到不同的硬件组件,其中LIWC和UCA是该文新设计的。由于多加速器并行,帧内任务可能会实时重叠(例如RR、网络和VD)。CL:软件控制逻辑;LS:本地设置;LR:局部渲染;C:组成;RR:远程渲染;VD:视频解码;LIWC:轻量级交互感知工作负载控制器;UCA:统一合成和ATW。
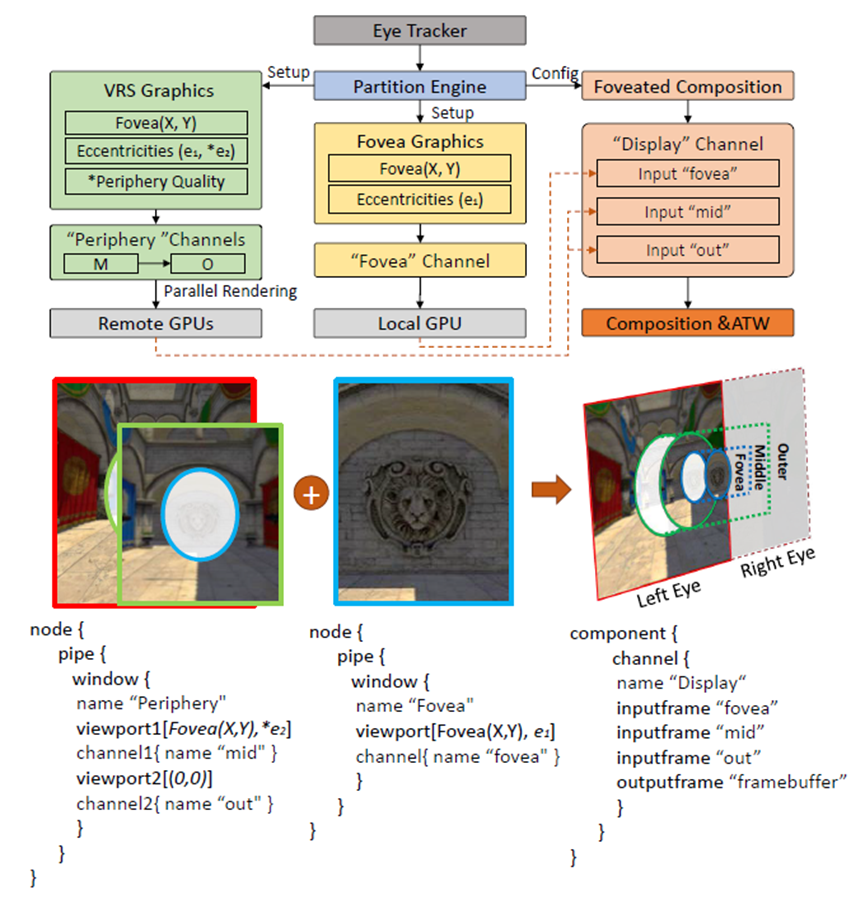
视觉感知启发Q-VR中的软件级设置和配置示例,其编程模型,以及它如何与硬件接口。

该文提议的LIWC架构图。

基线顺序执行和统一合成与ATW(UCA)之间的比较。
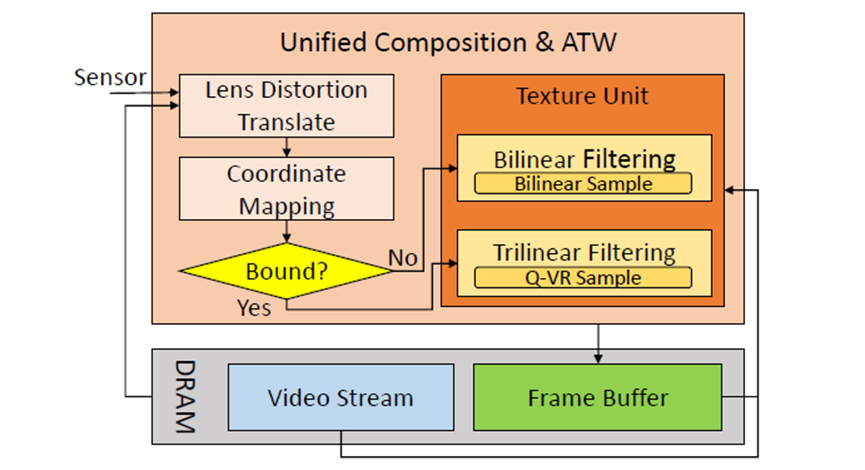
UCA架构图。
Towards a Better Understanding of VR Sickness通过评估VR疾病的身体症状水平来解决VR疾病评估(VRSA)的黑盒问题。对于诱发类似VR疾病级别的VR内容,身体症状可能会因内容的特征而异。现有的VRSA方法大多侧重于评估VR疾病的总体评分。为了更好地了解VR疾病,需要预测和提供VR病的主要症状水平,而不是VR病的总体程度。该文预测了影响VR疾病总体程度的主要身体症状的程度,即定向障碍、恶心和动眼神经。此外,还为VRSA引入了一个新的大规模数据集,包括360个具有不同帧率、生理信号和主观评分的视频。在VRSA基准测试和我们新收集的数据集上,我们的方法不仅有可能实现与主观得分的最高相关性,而且有可能更好地了解哪些症状是VR疾病的主要原因。

身体症状预测的直觉有助于更好地理解VR疾病。一般来说,VR内容根据其时空特征导致不同程度的身体症状。
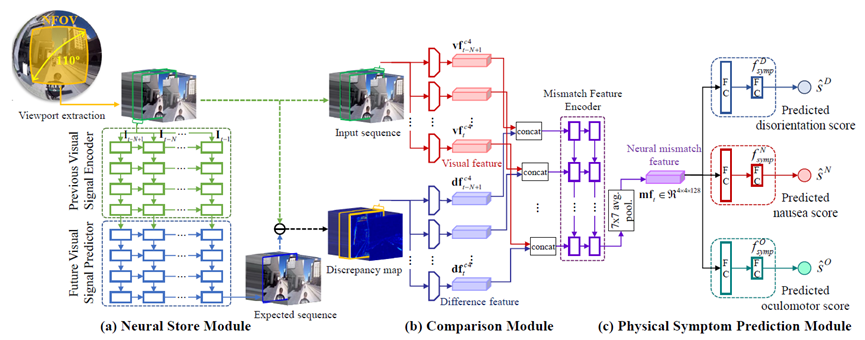
考虑神经失配机制的身体症状预测说明。
该文提出了一种新的客观身体症状预测方法,以更好地理解VR疾病,解决了现有工作中没有考虑身体症状的局限性。此外,构建了80个具有四种不同帧率的360度视频,并进行了广泛的主观实验,以获得生理信号(HR和GSR)和身体症状评分的主观问卷(SSQ分数)。在广泛的实验中,证明了该模型不仅可以提供VR疾病的总体评分,还可以提供VR病的身体症状。这可以作为查看VR内容安全性的实际应用。
A Study of Networking Performance in a Multi-user VR Environment探讨了VR中的多人互动实现和优化技术。

多人VR的一种CS架构。在此体系结构中,服务器可以控制应用程序的所有方面,例如向连接的客户端传输数据。在此上下文中,服务器是客户端可以连接到的游戏实例,客户端也是游戏实例。主要区别在于客户端对场景中的网络对象没有权限,意味着客户端无法更新其场景中其他对象的更改。由于服务器拥有对所有网络对象的权限,因此它负责更新场景中所有更改的连接客户端,并处理传入的请求。客户端仍然可以在本地对其场景进行更改,而不会通知任何其他人。它在许多情况下都很有用,例如处理控制器输入和设置播放器摄像头。
Virtual Hands in VR: Motion Capture, Synthesis, and Perception信息深入地阐述了VR中的动捕、合成和感知相关的技术,感兴趣的童鞋不容错过。[QuickTime VR – An Image-Based Approach to Virtual Environment Navigation](QuickTime VR – An Image-Based Approach to Virtual Environment Navigation.pdf)阐述了一种基于图像的虚拟环境导航方法
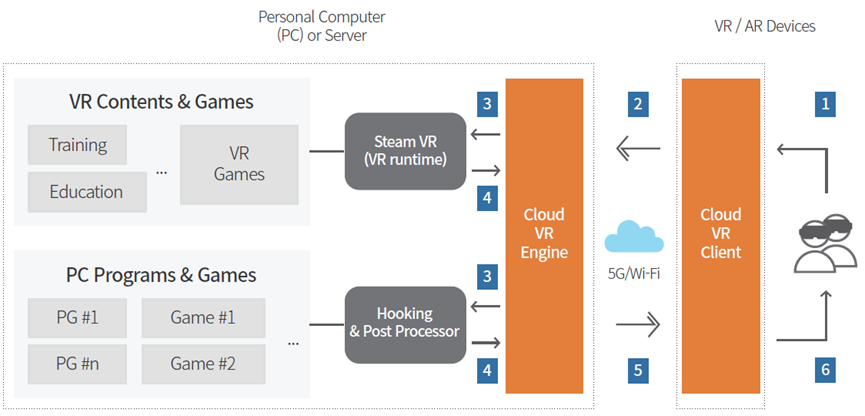
——QuickTimeVR。Capture, Reconstruction, and Representation of the Visual Real World for Virtual Reality解析了VR中的动捕、重建和表达等技术。High-Fidelity Facial and Speech Animation for VR HMDs解析了VR头显中的高保真面部和语音动画捕捉和重建。[Temporally Adaptive Shading Reuse for Real-Time Rendering and Virtual Reality](Temporally Adaptive Shading Reuse for Real-Time Rendering and Virtual Reality.pdf)分享了用于实时渲染和虚拟现实的时间自适应着色重用的技术。此外,有些公司(如华为)在研究基于云渲染的VR架构: