背景
基础不牢,地动山摇。在开发编程一途,尤为重要。
有python同学喜欢使用pytest框架实现接口自动化测试方案,在使用参数化过程中,无论是控制台还是测试报告中都没有展示用例名称(中文),而是参数化过程的参数顺序,如下图所示:
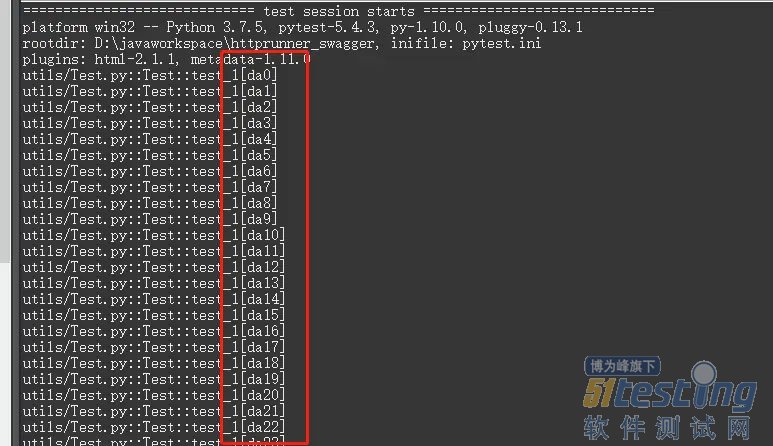
从报告效果上看,存在不知道fail的用例是哪个用例的问题,即使知道是第多少位的用例,但是也要在用例文件中快速找到用例,其难度不小!

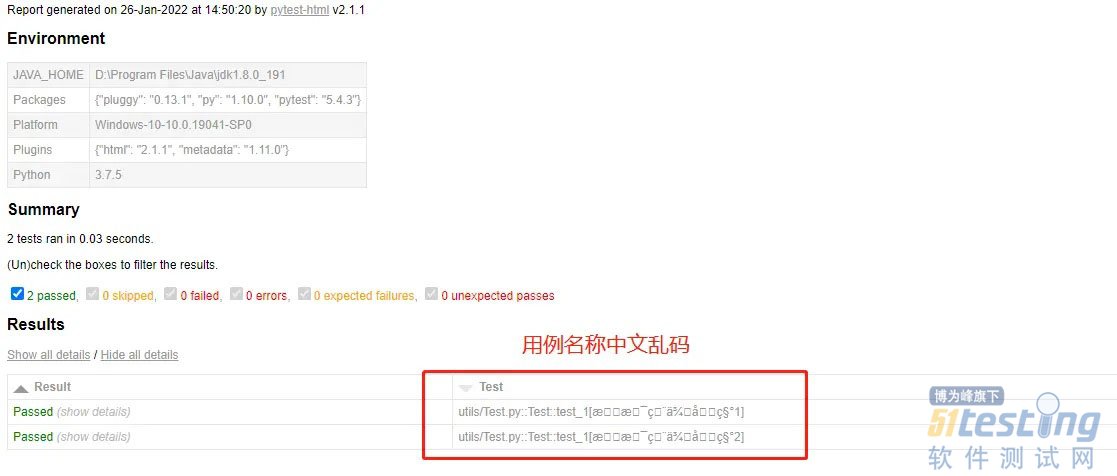
实际期望的结果是要知道参数化过程的每次请求是哪个接口(用例描述),如下:

但是,中文名称在报告中很不友好的展示了乱码,这是后续需要解决的!
先看案例
yaml用例文件demo如下;其实在写入yaml文件使用safe_dump可以将中文正确写入。
- basePath: /prd
host: 192.168.5.160:31081
params:
- Authorization: null
code: '6000000000'
codeType: '31'
name: "\u539F\u6CB9\u5916\u8F93\u6CF5P-2001A"
path: /equipment/getEquipmentType
summary: "\u4E3B\u8981\u8BBE\u5907\u8FD0\u884C\u72B6\u6001--\u83B7\u53D6\u8BBE\u5907\
\u8FD0\u884C\u5217\u8868--\u4E0B\u62C9\u6846"
- basePath: /prd
host: 192.168.5.160:31081
params:
- Authorization: null
code: '2001001000'
end_time: '2021-07-21'
start_time: '2021-07-21'
type: '1'
path: /DynamicTracking/Personneldynamic/terminal/echartData
summary: "\u751F\u4EA7\u52A8\u6001\u8DDF\u8E2A-\u4EBA\u5458\u52A8\u6001-\u7EC8\u7AEF\
-\u56FE\u8868\u7EDF\u8BA1\u6570\u636E"
测试代码
这里需要掌握@pytest.mark.parametrize装饰器的用法,包括其中的参数。
不太正确的用例代码是这样的,以为title会在html报告中展示,结果并不是:
with open("datas.yaml","r",encoding="utf-8") as pf:
datas = yaml.load(pf, Loader=yaml.FullLoader)
class Test():
@pytest.mark.parametrize("da",datas)
def test_1(self,da):
title = da.get("summary")
pass
if __name__ == '__main__':
pytest.main(['--html',"sss.html"])
@pytest.mark.parametrize装饰器的ids参数是个字符串元素的列表,即pytest生成用例的title:
with open("datas.yaml","r",encoding="utf-8") as pf:
datas = yaml.load(pf, Loader=yaml.FullLoader)
class Test():
@pytest.mark.parametrize("da",datas,ids=[i.get("summary") for i in datas])
def test_1(self,da):
# title = da.get("summary") 不需要这样操作
pass
if __name__ == '__main__':
pytest.main(['--html',"sss.html"])
如何在测试报告的标题列展示中文用例名称不乱吗?
找百度解决
千篇一律:就算是错误的解决方案,都被网络传至各个论坛;结果就是导致用户不断在尝试错误的解决方案。
两个办法其一:根路径conftest.py新增如下代码:
"""解决pytest-html报告中文乱码问题,避免修改pytest-html/plugi.py源码""" def pytest_collection_modifyitems(items): for item in items: item.name = item.name.encode('unicode-escape').decode('utf-8') item._nodeid = item.nodeid.encode('unicode-escape').decode('utf-8')
网络错误的写法如下,完全将顺序写反:
item.name = item.name.encode('utf-8').decode('unicode-escape')
item._nodeid = item.nodeid.encode('utf-8').decode('unicode-escape')
两个办法其二:修改pytest-html/plugin.py源码:
修改pytest-html/plugin.py源码,找到class TestResult:注释#self.test_id = report.nodeid.encode("utf-8").decode("unicode_escape");新增self.test_id = report.nodeid
从源码中可以看出,原来已经有self.test_id = report.nodeid.encode("utf-8").decode("unicode_escape");它也是错的。
class TestResult:
def __init__(self, outcome, report, logfile, config):
# self.test_id = report.nodeid.encode("utf-8").decode("unicode_escape")
# 新增一行
self.test_id = report.nodeid
if getattr(report, "when", "call") != "call":
self.test_id = "::".join([report.nodeid, report.when])
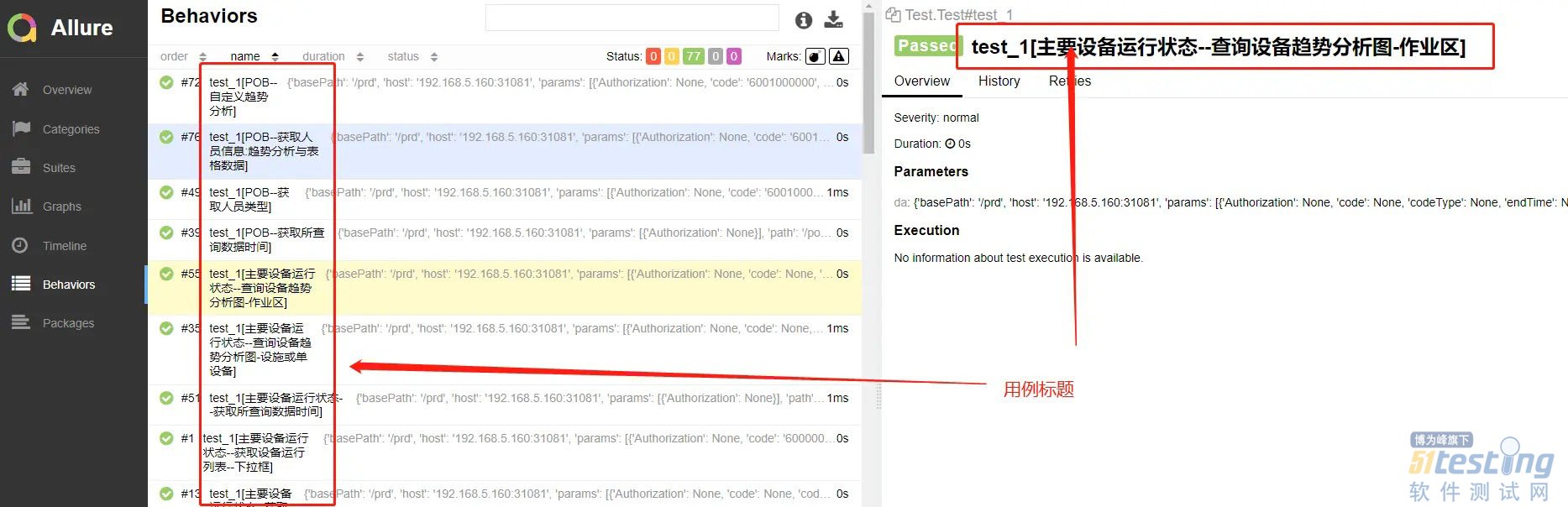
allure报告却没有pytest-html的问题
总结
上面的几个问题没有多余的解释,就是一顿操作猛如虎!但是需要你心细、胆大怀疑一切可能的错误,不然会陷入错误的死循环。谁也没有解释为什么要这么写,只能靠自己去读代码,理解作者的意图!
pytest框架是真的很强大,在组织测试用例和生成测试报告方面,它的诸多装饰器功能强大的无与伦比;这也是考验使用者的基本功扎不扎实。题主也是一边试错一边学习pytest,每有会意不可言传!