1.算法描述
目前关于步态识别算法研究主要有两种:基于模型的方法和非基于模型的方法。基于模型的步态识别方法优点在于能够很好的体现步态图像序列当前的变化,也能够预测过去和未来的状态。基于非模型的方法是通过对步态相关特征进行预测来建立相邻帧间的关系,其中特征包括位置、速度、形状等,其中基于形状特征的方法较为常见。Lee等先将人体的侧影图像序列进行二值化处理,根据人体的质心比例关系将人体划分为7个区域,用椭圆形的模型对划分的7个区域进行建模,计算椭圆模型的质心、离心率等参数,将计算所得参数作为特征进行分类识别,Cunado等早期运用了基于模型的方法,将大腿部与水平的倾斜变化作为特征进行步态识别,王俊等将步态能量图中动态部分与Gabor小波特征进行融合进行分类识别。
步态识别是一种新兴的生物特征识别技术,旨在通过人们走路的姿态进行身份识别,与其他的生物识别技术相比,步态识别具有非接触远距离和不容易伪装的优点。在智能视频监控领域,比图像识别更具优势。步态是指人们行走时的方式,这是一种复杂的行为特征。罪犯或许会给自己化装,不让自己身上的哪怕一根毛发掉在作案现场,但有样东西他们是很难控制的,这就是走路的姿势。英国南安普敦大学电子与计算机系的马克·尼克松教授的研究显示,人人都有截然不同的走路姿势,因为人们在肌肉的力量、肌腱和骨骼长度、骨骼密度、视觉的灵敏程度、协调能力、经历、体重、重心、肌肉或骨骼受损的程度、生理条件以及个人走路的“风格”上都存在细微差异。对一个人来说,要伪装走路姿势非常困难,不管罪犯是否带着面具自然地走向银行出纳员还是从犯罪现场逃跑,他们的步态就可以让他们露出马脚。
人类自身很善于进行步态识别,在一定距离之外都有经验能够根据人的步态辨别出熟悉的人。步态识别的输入是一段行走的视频图像序列,因此其数据采集与面像识别类似,具有非侵犯性和可接受性。但是,由于序列图像的数据量较大,因此步态识别的计算复杂性比较高,处理起来也比较困难。尽管生物力学中对于步态进行了大量的研究工作,基于步态的身份鉴别的研究工作却是刚刚开始。步态识别主要提取的特征是人体每个关节的运动。到目前为止,还没有商业化的基于步态的身份鉴别系统。
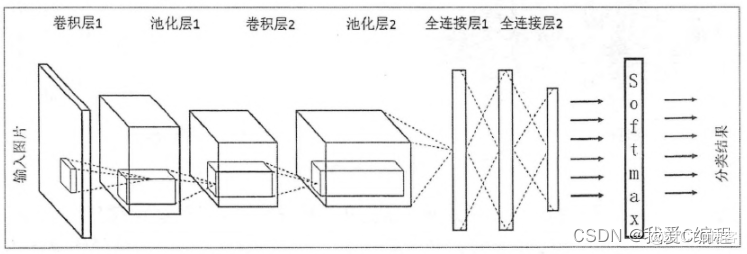
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” 。
对卷积神经网络的研究始于二十世纪80至90年代,时间延迟网络和LeNet-5是最早出现的卷积神经网络 [4] ;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被应用于计算机视觉、自然语言处理等领域 。
卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求 。
卷积层的结构如下所示:
给出经过预处理的二值步态轮廓图像Bt(x,y)表示在t时刻的一个序列图像,灰度图GEI的定义如下:
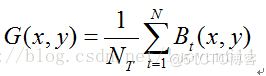
其中是一系列步态轮廓序列的个数,t是当前时刻的序列图,x和y是图像坐标。
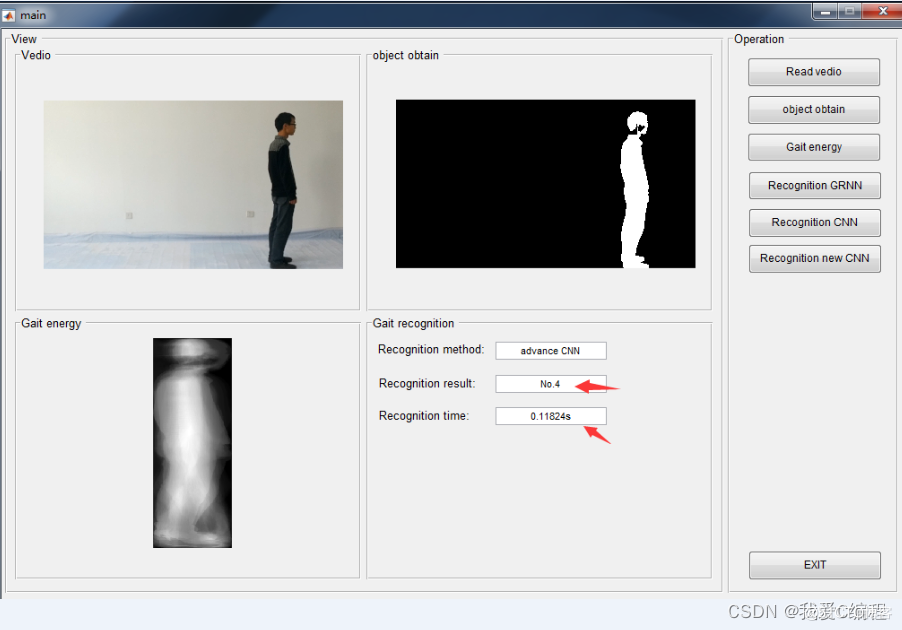
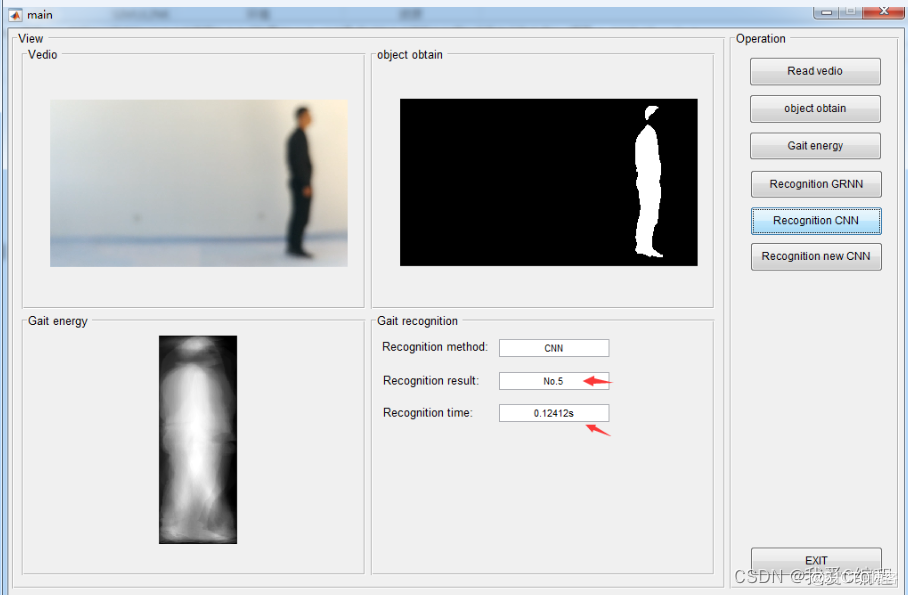
2.仿真效果预览
matlab2022a仿真结果如下:
3.MATLAB核心程序
Lens = floor(v.Duration*v.FrameRate);%视频长度
v=VideoReader(str);
idx = 0;
diff = 0;
RGBlvl = 100;
Width = 2;
axes(handles.axes2);
while hasFrame(v)%开始帧循环
idx
idx = idx + 1;
video1 = readFrame(v);%读取视频帧的图像像素数据
[R,C,K] = size(video1);%计算当前帧的分辨率
diff = zeros(R,C);
%目标提取
%通过颜色模型来提取目标
for i =1:R%开始对像素的每一个像素进行循环
for j= 1:C
if (video1(i,j,1)<RGBlvl & video1(i,j,2)<RGBlvl & video1(i,j,3)<RGBlvl)
diff(i,j) = 1;%提取目标
else
diff(i,j) = 0;%如果不是目标则为0
end
end
end
%形态学滤波
diff2 = bwareaopen(diff,4000);
%形态学填充
diff2 = imfill(diff2, 'holes');
%进一步形态学滤波
diff2_= bwareaopen(diff2,4000);
%提取目标区域的坐标
[L,n] = bwlabel(diff2_);
a1=[];
a2=[];
b1=[];
b2=[];
for jj=1:n
r=[];
c=[];
[r,c]=find(L==jj);
a1(jj)=max(r);
a2(jj)=min(r);
b1(jj)=max(c);
b2(jj)=min(c);
end
%根据坐标信息对目标进行裁剪,并保存,用于后面能量图的计算
II{idx} = diff2_(min(a2):max(a1),min(b2):max(b1));
%画图
imshow(diff2);
drawnow;
end