1. 梯度下降法
无约束最优化问题一般可以概括为:
通过不断迭代到达最优点 \(x^*\),迭代过程为:
其中 \(d^k\) 为当前的 搜索方向,\(\alpha_k\) 为当前沿着搜索方向的 步长 。
我们需要寻找可以不断使得 \(f(x^{k + 1} < f(x^k)\) 的方法。
构造一元辅助函数:
其中 \(d^k\) 是 下降方向,\(\alpha > 0\) 是辅助函数的 自变量。
由一阶泰勒展开式将目标函数进行泰勒展开:
(带皮亚诺余项的一阶泰勒展开)
可得:
为了使得迭代过程 可行,能够达到 收敛,显然有 \(||x^{k + 1} - x^k|| \rightarrow 0\),所以有:
显然,为了能够使得 \(f(x^{k + 1}) < f(x^k)\),需要确保 \(\alpha \nabla f(x^k)^Td^k < 0\),而 \(\alpha > 0\),所以需要保证:
为了使得 下降速度尽可能快,即有关于下降方向的最优化问题:
由 柯西不等式:
根据柯西不等式等号成立的条件,需要使 \(d^k\) 与 \(- \nabla f(x^k)\) 同向。所以,我们需要找到的 最快的下降方向 即:
由此得出 梯度下降法 (最速下降法) 的迭代格式:
其中 步长 \(\alpha_k\) 可以依据线搜索算法(精确解、直接搜索、非精确搜索的一些准则等)得到,也可以选取固定的步长 \(\alpha\) 。
终止条件 一般有 \(||x^{k + 1} - x^k|| < \varepsilon\) 或 \(|f(x^{k + 1}) - f(x^k)| < \varepsilon\) 。其中 \(\varepsilon\) 是一个很小的数。
如下图所示,为一个二元二次函数 \(f(x, y)\),采用 梯度下降法 \(x^{k + 1} = x^k - \alpha_k \nabla f(x^k)\) 的迭代过程。
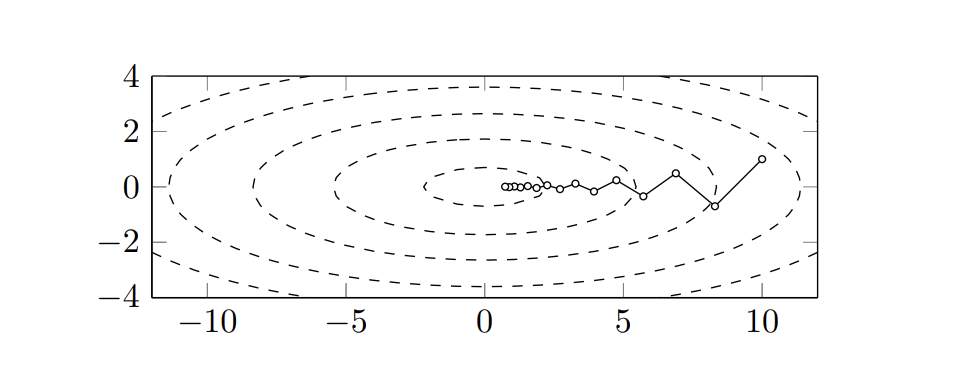
在机器学习领域,梯度下降法有非常广泛的应用。例如梯度下降法解决线性回归问题。[机器学习复习笔记] Grandient Descent 梯度下降法
2. Lipschitz 连续
2.1 梯度利普希茨连续定义
给定可微函数 \(f\),若存在 \(L > 0\),对于任意 \(x, y \in \text{dom} f\) 有:
则称 \(f\) 是 梯度利普希茨连续 的。其中 \(L\) 为 利普希茨常数。
函数 \(f\) 满足 \(\text{Lipschitz}\) 连续可以理解为该函数的变化速率受到了限制。变化速率的上界即为 \(\text{Lipschitz}\) 常数 \(L\)。
2.2 下降引理(二次上界)
设可微函数 \(f\) 定义域 \(\text{dom} f = \mathbb{R}^n\),且 梯度利普希茨连续,则 其 \(\text{Hessian}\) 矩阵满足:
其中 \(L\) 为 利普希茨常数,\(I\) 为单位阵。
导数 \(\nabla f(x)\) 变化 最快的方向 就是它的 \(\text{Hessian}\) 矩阵 \(\nabla ^2 f(x)\) 绝对值 最大特征值所对应的特征向量。
对函数 \(f\) 进行泰勒展开得:
对任意 \(x, y \in \text{dom} f\) 成立,称 \(f(x)\) 有二次上界。
3. 梯度下降收敛性
梯度法迭代式:
-
设函数 \(f(x)\) 为凸函数,且梯度利普希茨连续
-
极小值 \(f(x^*)\) 存在且可达
-
步长应满足 \(0 < \alpha < \frac{1}{L}\)
条件(2)是一个不可或缺的条件,它保证了原始的优化问题存在可行解。
条件(1)和条件(3)使得下降引理成立,保证了梯度下降算法在优化目标函数过程中的正确性。
参考
刘浩洋, 户将, 李勇锋, 文再文《最优化:建模、算法与理论》