Minimizing the Influence of Misinformation via Vertex Blocking
Motivation and Application
其实就是经典的Rumor Blocking问题,即通过一系列的操作使得rumor在社交网络中的影响力最小。主流的方法有三种:
- 找到一组seed set去和rumor节点竞争,社交网络中的节点都只能被激活一次,且激活了以后状态就不会改变,类似于Competitive IM;
- 阻塞社交网络中的一部分节点
- 阻塞社交网络中的一部分边
本文用的是第二种方法来实现rumor blocking
Contribution
- 第一次证明了通过阻塞边来进行影响力最小化的问题是NP-hard和APX-hard的。(有点离谱,这个问题提出来这么久了居然没人证)
- 提出了一个新的估计方法(结合了ACM里用到的决策树),之前最好的是蒙特卡洛(都2023年了,怎么还能是这么普通的估计方式?!)。并且给出了这个估计方式的近似保证,很简单的chernoff-bound的证明。
- 提出了两个框架:1.普通的贪心框架。2.一个新的置换框架
From Multiple Seeds to One Seed
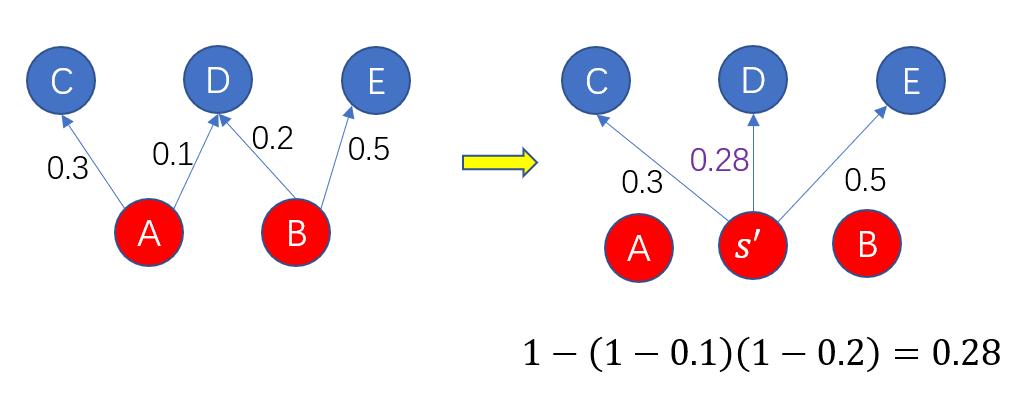
创建一个新的节点$S^{'}$,来替换途中的所有种子节点。具体步骤如下:
对于图中的每个节点$u$,如果有h个不同的种子指向$u$,每条边的概率为$p_i(1≤i≤h)$,将u的所有入边(入邻居节点是种子节点)删除,并以$(1-\prod_{i=1}^{h} (1−p_i))$的概率将边从$S^{'}$添加到$u$。
Baseline
在这篇文章之前,最好的方法就是用蒙特卡洛模拟去估计把某个节点block了以后S所减少的影响力,用贪心算法框架去贪心的选择减少的最多的节点,直至选到k个节点。

Dominator Tree Based Estimation
Dominator
如果s到v的所有路径都经过u,我们称u支配v。
Immediate Dominator
离v最近的支配v的点叫做v的idom。

Dominator Tree
把每个节点和他的直接支配点连起来就是一颗支配树。

有一个关于支配树的lemma:将u删除以后s减少的影响力等于在支配树中以u为根的子树的大小(有几个节点)。比如将D删除了以后s的影响力会减小3,此时在支配树中,以D为根本的子树的size为3.基于此,我们可以对删除某个节点以后s的损失的影响力进行估计。


DecreaseESComputation的时间复杂度为?(?·?·?(?,?)),AdvancedGreedy的时间复杂度是?(?·?·?·?(?,?)),而BaselineGreedy的时间复杂度是?(?·?·?·?),?是 inverse function of Ackerman's function,它远小于n,因此AdvancedGreedy的时间复杂度远小于BaselineGreedy。
The drawback of GreedyFramework



Experiments
Datasets

Setting
传播模型: IC model
边上的概率设置:
- TR: 随机从{0.1, 0.01, 0.001}选择一种概率。
- WC:边上的概率等于入节点的个数分之1.
蒙特卡洛模拟次数和生成sample的个数均为10000.
算法:
- Exact:$C_n^b$种可能都列出来,用蒙特卡洛模拟估计他们的减少值,取最大的seed set。
- Rand:随机取b个blocker。
- OutDegree:取b个出度最大的节点。
- BaselineGreedy
- AdvancedGreedy
- GreedyReplace
Comparison with the Exact Algorithm


Time Cost of Different Algorithms


Varying the Budget (Time)

Comparision with Other Heuristics (Expected Spread)
