内容转自:https://joyspace.jd.com/sheets/YZxilLHtAc98E1k5kHDK
一、背景介绍
最近在技术交流微信群里看大家讨论技术,其中有谈到 Redis 热 Key 的一些问题解决方案,我也仔细思考了一下我们目前系统中 Redis 的使用场景,我们是不是也存在热 Key 问题,或者说如果我们也出现了热 Key 问题会怎么去解决。
目前我在京东做一款 APP (京东读书)的业务量不是特别大,说一个指标就可以了,DAU 在 20W 左右,熟悉这个指标的朋友马上就可以感受什么叫量不是特别大了。所以我的工作中遇到热 Key 的问题可能印象中没有过,如果硬要说出现过,也算是有过,不过那种情况不能算是简单的热 Key 问题,还有一些功能设计以及 Redis 数据结构选择方面的一些问题,这些可以后面专门总结一下,这篇还是只聊热 Key。
目录
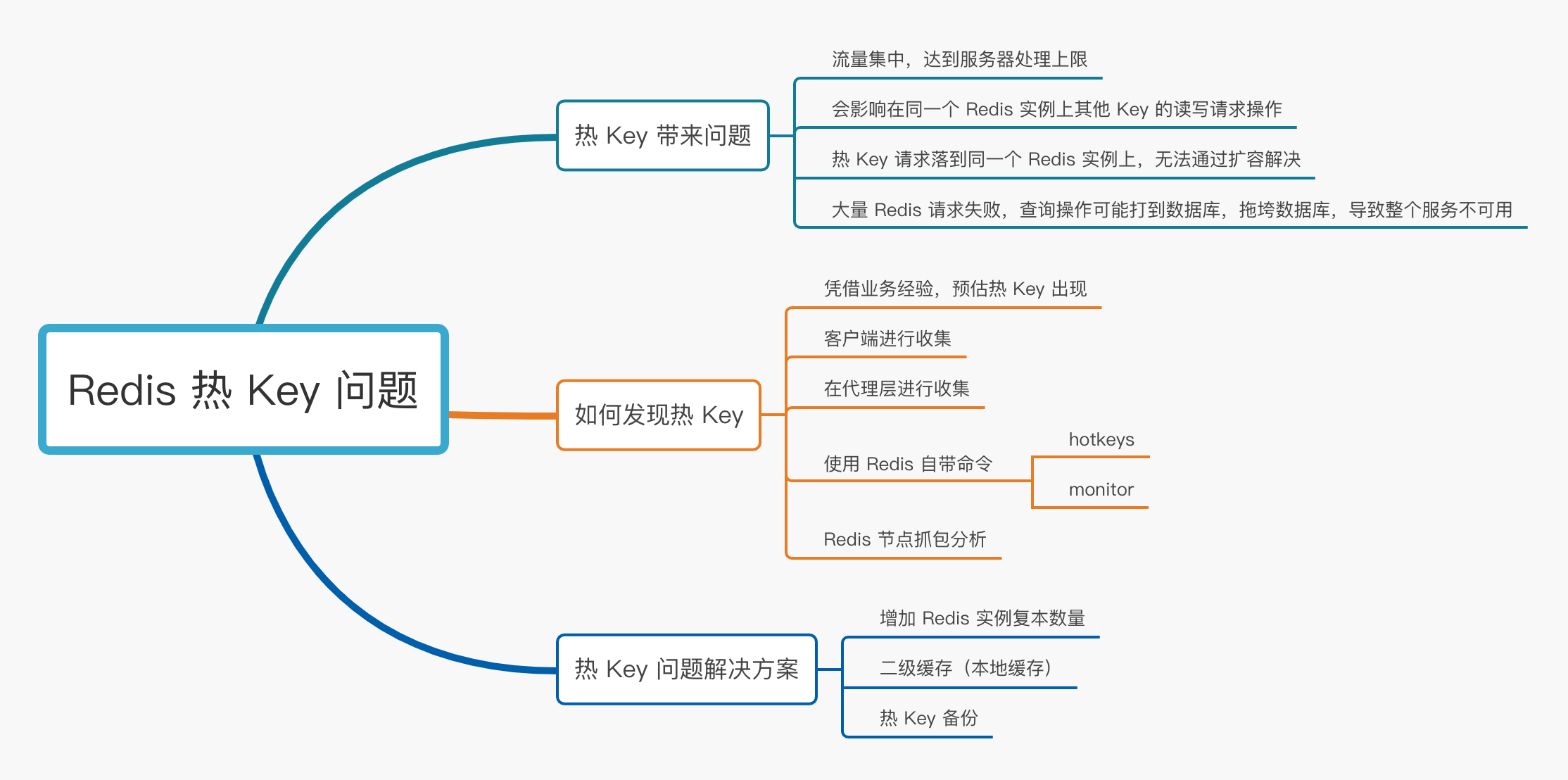
二、热 Key 带来问题
其实,按我理解来说,没有什么所谓的热 Key 问题,所谓的热 Key 问题都是由于对某个 Key 的访问量过大所产生的一些衍生问题。
由于某个 Key 的数据一定是存储到后端某台服务器的 Redis 单个实例上,如果对这个 Key 突然出现大量的请求操作,这样就会造成流量过于集中,达到 Redis 单个实例处理上限,可能会导致 Redis 实例 CPU 使用率 100%,或者是网卡流量达到上限等,对系统的稳定性和可用性造成影响,或者更为严重出现服务器宕机,无法对外提供服务;更有甚者在出现 Redis 服务不可用之后,大量的数据请求全部落地数据库查询上,Redis 都已经顶不住了,数据库也是分分钟挂掉的节奏,这个是所谓的热 Key 问题。
-
流量集中,达到服务器处理上限(
CPU、网络IO等); -
会影响在同一个
Redis实例上其他Key的读写请求操作; -
热
Key请求落到同一个Redis实例上,无法通过扩容解决; -
大量
Redis请求失败,查询操作可能打到数据库,拖垮数据库,导致整个服务不可用。
通过上面的描述,其实热 key 问题不仅是对某个 Key 请求流量过于集中的问题,也和服务器性能有很大的关联,如果是一个普通的 Docker 容器(4C8G,4核CPU,8G内存,大家不要笑,我们系统好多这种规格服务器),和一台性能强劲的物理机,这两种不同的服务器规格配置对热 Key 的认定估计也不会相同,这个可能是我对热 key 问题的一点不同理解。
三、如何发现热 Key
通过上面的分析,出现热 Key 的危害还是很大的,我们不可能等到热 Key 出现已经拖垮了服务再去处理,那个时候业务一定已经收到影响,损失也是不言而喻的;那么能够在热 Key 出现前通过一些手段提前监控到热 Key 的出现,对于保证业务系统的稳定性是非常重要的,那么我们都有哪些手段提前观测到热 Key 的出现呢?
1)凭借业务经验,预估热 Key 出现
根据业务系统上线的一些活动和功能,我们是可以在某些场景下提前预估热 Key 的出现的,比如业务需要进行一场商品秒杀活动,秒杀商品信息和数量一般都会缓存到 Redis 中,这种场景极有可能出现热 Key 问题的。
-
优点:简单,凭经验发现热
Key,提早发现提早处理; -
缺点:没有办法预测所有热
Key出现,比如某些热点新闻事件,无法提前预测。
2)客户端进行收集
一般我们在连接 Redis 服务器时都要使用专门的 SDK(比如:Java 的客户端工具 Jedis、Redisson),我们可以对客户端工具进行封装,在发送请求前进行收集采集,同时定时把收集到的数据上报到统一的服务进行聚合计算。
3)在代理层进行收集
如果所有的 Redis 请求都经过 Proxy(代理)的话,可以考虑改动 Proxy 代码进行收集,思路与客户端基本类似。
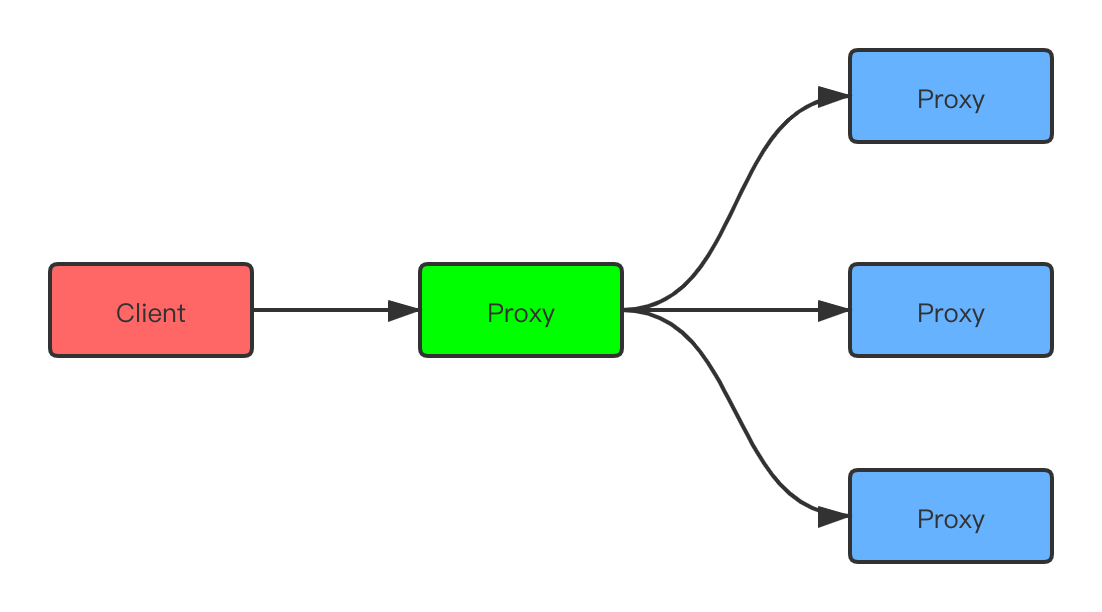
-
优点:对使用方完全透明,能够解决客户端
SDK的语言异构和版本升级问题; -
缺点:
4)使用 Redis 自带命令
hotkeys 参数
Redis 在 4.0.3 版本中添加了 hotkeys 查找特性,可以直接利用 redis-cli --hotkeys 获取当前 keyspace 的热点 key,实现上是通过 scan + object freq 完成的。
-
优点:无需进行二次开发,能够直接利用现成的工具;
-
缺点:
-
由于需要扫描整个
keyspace,实时性上比较差; -
扫描时间与
key的数量正相关,如果key的数量比较多,耗时可能会非常长。
-
monitor 命令
monitor 命令可以实时抓取出 Redis 服务器接收到的命令,通过 redis-cli monitor 抓取数据,同时结合一些现成的分析工具,比如 redis-faina,统计出热 Key。
5)Redis 节点抓包分析
Redis 客户端使用 TCP 协议与服务端进行交互,通信协议采用的是 RESP 协议。自己写程序监听端口,按照 RESP 协议规则解析数据,进行分析。或者我们可以使用一些抓包工具,比如 tcpdump 工具,抓取一段时间内的流量进行解析。
-
优点:对
SDK或者Proxy代理层没有入侵; -
缺点:
-
有一定的开发成本;
-
热
Key节点的网络流量和系统负载已经比较高了,抓包可能会导致情况进一步恶化。
-
四、热 Key 问题解决方案
1)增加 Redis 实例复本数量
对于出现热 Key 的 Redis 实例,我们可以通过水平扩容增加副本数量,将读请求的压力分担到不同副本节点上。
2)二级缓存(本地缓存)
当出现热 Key 以后,把热 Key 加载到系统的 JVM 中。后续针对这些热 Key 的请求,会直接从 JVM 中获取,而不会走到 Redis 层。这些本地缓存的工具很多,比如 Ehcache,或者 Google Guava 中 Cache 工具,或者直接使用 HashMap 作为本地缓存工具都是可以的。
使用本地缓存需要注意两个问题:
-
如果对热
Key进行本地缓存,需要防止本地缓存过大,影响系统性能; -
需要处理本地缓存和
Redis集群数据的一致性问题。
3)热 Key 备份
通过前面的分析,我们可以了解到,之所以出现热 Key,是因为有大量的对同一个 Key 的请求落到同一个 Redis 实例上,如果我们可以有办法将这些请求打散到不同的实例上,防止出现流量倾斜的情况,那么热 Key 问题也就不存在了。
那么如何将对某个热 Key 的请求打散到不同实例上呢?我们就可以通过热 Key 备份的方式,基本的思路就是,我们可以给热 Key 加上前缀或者后缀,把一个热 Key 的数量变成 Redis 实例个数 N 的倍数 M,从而由访问一个 Redis Key 变成访问 N * M 个 Redis Key。 N * M 个 Redis Key 经过分片分布到不同的实例上,将访问量均摊到所有实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// N 为 Redis 实例个数,M 为 N 的 2倍
const M = N * 2
//生成随机数
random = GenRandom(0, M)
//构造备份新 Key
bakHotKey = hotKey + "_" + random
data = redis.GET(bakHotKey)
if data == NULL {
data = redis.GET(hotKey)
if data == NULL {
data = GetFromDB()
// 可以利用原子锁来写入数据保证数据一致性
redis.SET(hotKey, data, expireTime)
redis.SET(bakHotKey, data, expireTime + GenRandom(0, 5))
} else {
redis.SET(bakHotKey, data, expireTime + GenRandom(0, 5))
}
}
|

在这段代码中,通过一个大于等于 1 小于 M 的随机数,得到一个 bakHotKey,程序会优先访问 bakHotKey,在得不到数据的情况下,再访问原来的 hotkey,并将 hotkey 的内容写回 bakHotKey。值得注意的是,bakHotKey 的过期时间是 hotkey 的过期时间加上一个较小的随机正整数,这是通过坡度过期的方式,保证在 hotkey 过期时,所有 bakHotKey 不会同时过期而造成缓存雪崩。
五、总结
在这一篇文章中我们首先分析了在 Redis 中热 Key 带来的一些问题,同时也介绍了在海量的 Redis Key 中找到热 Key 的一些方法,最后也提到了在解决热 Key 问题中我们常用的一些办法;总结来说,Redis 热 Key 问题首先是请求流量过大造成的,但是更深层次原因还是出现了流量倾斜,单个 Redis 实例承担的流量过大造成的,了解到了本质原因,解决的思路也就简单了,就是要想尽一切办法将单个实例承担的流量打散,让每个机器均衡承担热 Key 的流量,不要出现流量倾斜,保证系统的稳定性。