Mysql性能优化这5点你知道吗?简单却容易被初学者忽略!
文编|JavaBuild
哈喽,大家好呀!我是JavaBuild,以后可以喊我鸟哥,嘿嘿!俺滴座右铭是不在沉默中爆发,就在沉默中灭亡,一起加油学习,珍惜现在来之不易的学习时光,等工作之后,你就会发现,想学习真的需要挤时间,厚积薄发啦!
在日常工作中,我们常用的数据库无非是Mysql、Oracle、SqlServer、DB2这几种(仅针对关系型数据库中),对于我们来说,数据库的性能优化是一个重点问题,也是很多公司面试时喜欢提及的,这里总结了一些比较常见,但又相对容易忽略的部分,供大家批判学习。

1、切勿使用select * 进行全表查询
select * 会直接查询出数据表中的全量字段数据,可能很多数据并不需要,白白浪费了数据库资源,并且select * 不会走覆盖索引,可能会出现回表操作,在单表数据量较大情况下,导致sql查询的效率低下。
2、尽量用union all 替代union
union组合查询,可以不获取几张表排重后的数据结果。
union all 是用来获取几张表的全量数据,不会排重,包含重复数据。
在union排重的过程中,需要遍历、排序和比较,耗时耗资源。所以,若非一些不可有重复数据的业务场景外,尽量选择union all。
3、小表驱动大表
何为小表驱动大表?顾名思义,两多表联合查询时,用数据量小的表去驱动数据量大的数据表,譬如:有user和order两张表,order表为100万数据量,user表有100条数据,此时想查一下有效用户下过的订单情况。
有如下两种实现方式:
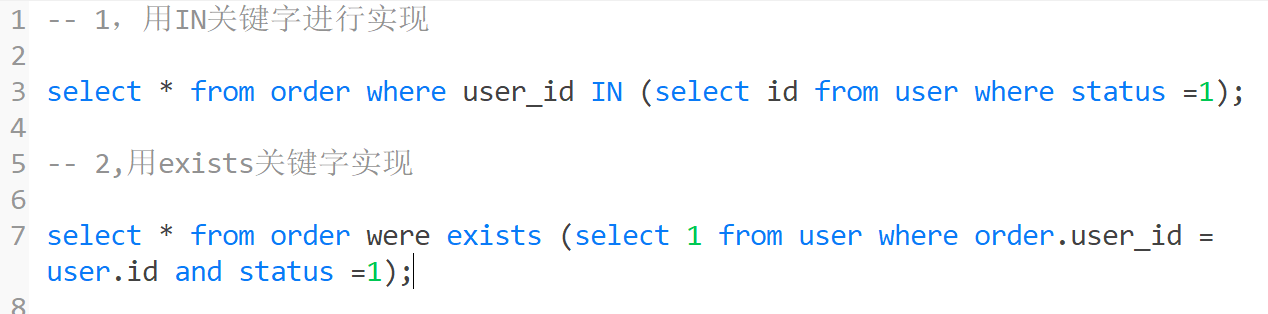
这两种方式,其实使用in查询的效果更好,因为,执行顺序是先执行in中子查询,然后再执行外面的雨具,此时in中数据量少,查询速度快。
当使用exists时,会优先查询左侧的主查询,然后将查询出的结果和右边的语句进行匹配,用100万条数据与100条数据匹配结果,显然效率会查很多。
这种做一个小总结:
1:in关键字适应于左边大表,右边小表;
2:exists关键字适应于左侧小表,右边大表;
后面我们还会提及的join连接查询,也同样是遵循小表驱动大表规则。
4、用连接查询代替子查询
在Mysql中,如果想通过多张表查询数据,一般会使用子查询或者连接查询的方式进行处理(在Mysql8.0之后支持与Oracle相同的WITH AS语法进行数据分块处理 )

通过in关键字实现的子查询方式,需要先查询出内层语句的结果,作为外层语句的过滤条件使用,在这个过程中子查询会被创建为临时表,查询结束后,删除这些临时表,如果几百上千行的sql中频繁使用的话,会多一些性能损耗。
这时候可以考虑通过连接查询,但是!在《阿里巴巴开发者手册》中对于join的使用数量限制在了3个,当一段sql中频繁使用join的话,会带来索引选择的困难,曾经在工作中,使用一个数据量较大的表进行了6次的left join 最终查询耗时很久。
这里建议大家可以采用多种方式混合使用的方式,先用with as 将核心数据进行一次处理,随后在通过 join进行联接查询,汇总结果。
5、建表时选择合适字段
- 能用数字类型,就不用字符串,字符的处理要比数字慢
- 满足使用情况下,用小类型,比如bit用来存布尔值,tinyint存枚举值
- 长度固定的字符串字段,用char类型
- 长度可变字符串用varchar类型
- 金额字段用decimal,避免精度丢失