一、mobileV1
MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积块)能够有效降低参数量。
对于常规卷积:假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
对于深度可分离卷积:用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱(进行升维),所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
如下这张图就是depthwise separable convolution的结构;可以看到深度可分离卷积包含:深度可分离卷积核、1*1卷积。
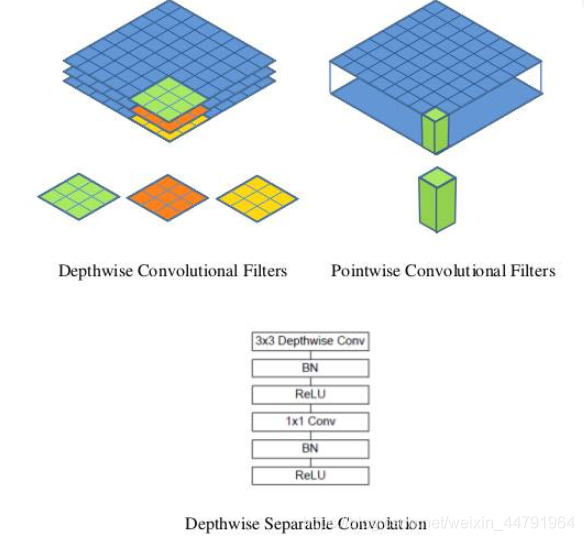
如下图,整个网络几乎都是有深度可分离卷积构成。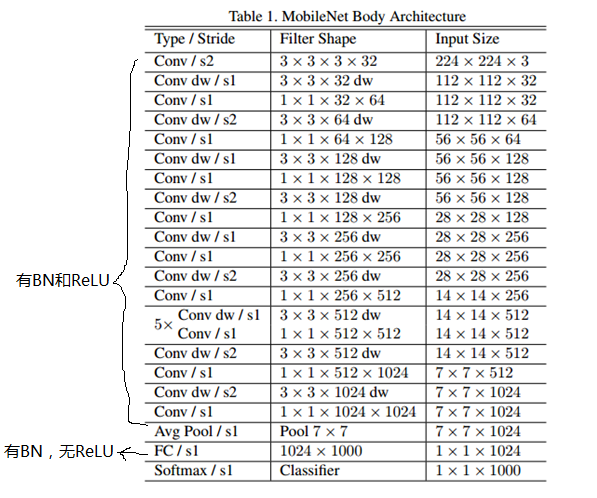
二、mobileNetV2
相对V1的改进:有人在实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是0;将ReLU替换成线性激活函数。
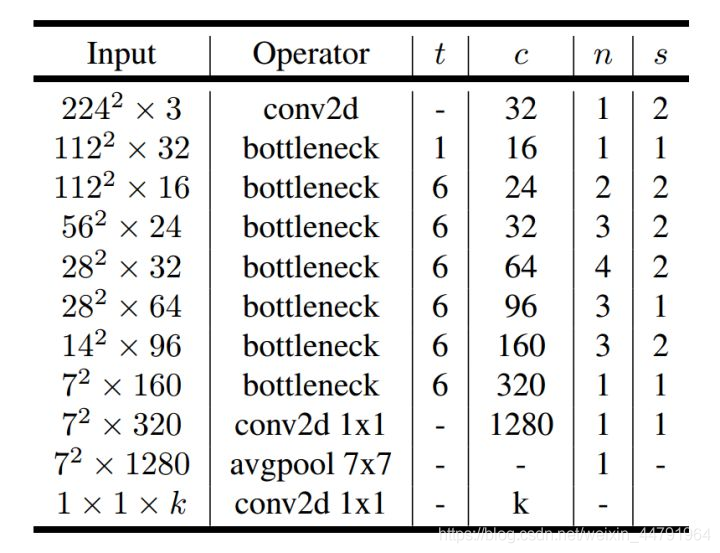
MobileNetV2是MobileNet的升级版,它具有一个非常重要的特点就是使用了Inverted resblock,整个mobilenetv2都由Inverted resblock组成。
Inverted resblock可以分为两个部分:
- 左边是主干部分,首先利用1x1卷积进行升维,然后利用3x3深度可分离卷积进行特征提取,然后再利用1x1卷积降维。
- 右边是残差边部分,输入和输出直接相接。

整体网络结构如下:(其中Inverted resblock进行的操作就是上述结构)
补充:参考:https://blog.csdn.net/Roaddd/article/details/111416386?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.no_search_link&spm=1001.2101.3001.4242.1&utm_relevant_index=2
Inverted Residual(逆残差)
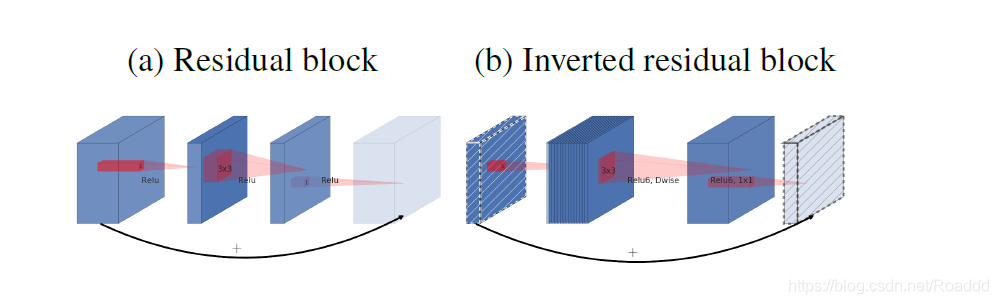
原始Residual block和Inverted residual block对比
(a)Original residual block:reduce – transfer – expand (中间窄两头宽)
Residual block先用1x1卷积降通道过ReLU,再3x3卷积过ReLU,最后再用1x1卷积过ReLU恢复通道,并和输入相加。之所以要1*1卷积降通道,是为了减少计算量,不然中间的3x3卷积计算量太大。所以Residual block是中间窄两头宽。
(b)Inverted residual block:expand – transfer – reduce (中间宽两头窄)
在Inverted Residual block中,3x3卷积变成Depthwise了,计算量很少了,所以通道数可以多一点,效果更好,所以通过1x1卷积先提升通道数,再Depthwise3x3卷积,最后用1x1卷积降低通道数。两端的通道数都很小,所以1x1卷积升通道和降通道计算量都并不大,而中间的通道数虽然多,但是Depthwise 的卷积计算量也不大。下图即为具体实例:

– 为什么要使用Inverted residual
skip connection这种bottleneck的结构被证明很有效,所以想用。但是如果像以前那样先压缩channal,channal数本来就少,再压没了,所以不如先增大后减少。
三、mobileNetV3
mobilenetV3使用了特殊的bneck结构。bneck结构如下图所示:
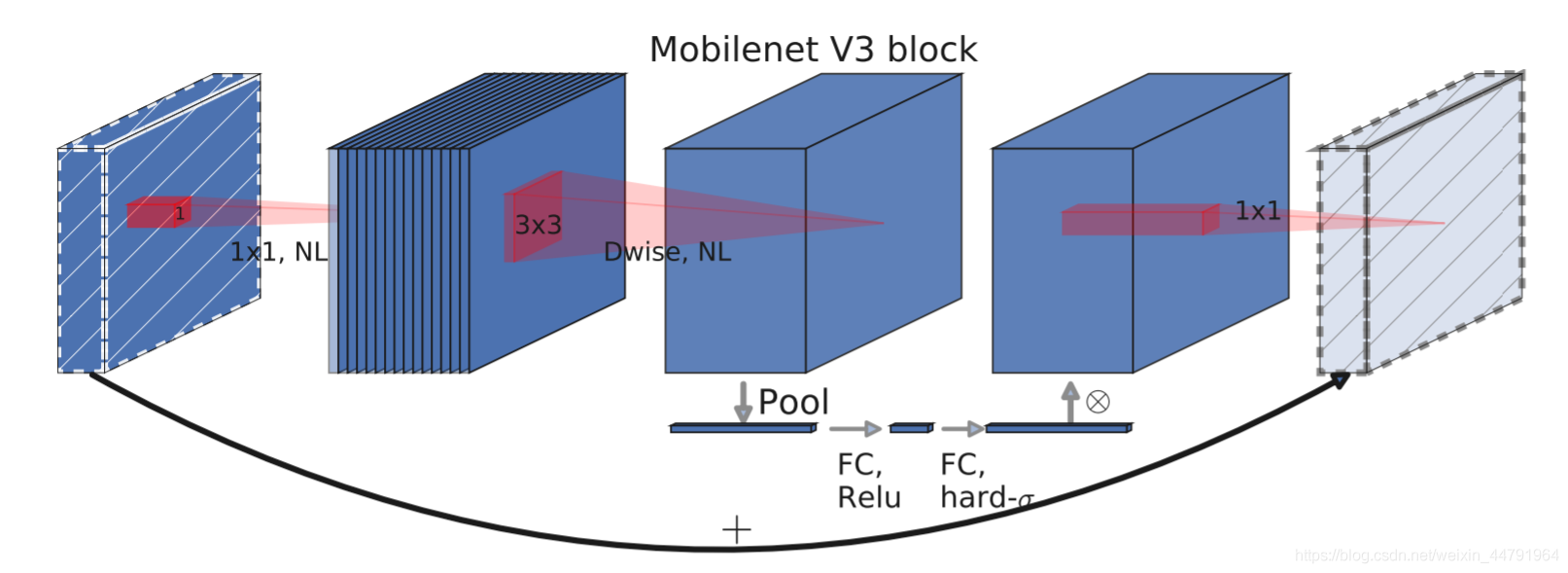
它综合了以下四个特点:
a、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。

即先利用1x1卷积进行升维度,再进行下面的操作,并具有残差边。
b、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。

c、轻量级的注意力模型。
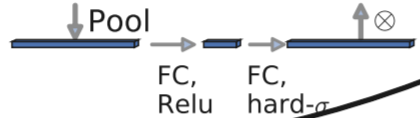
这个注意力机制的作用方式是调整每个通道的权重。
举个例子:SE注意力机制流程:特征图(h,w,c)经过全局平均pooling之后,得到维度为1,1,c的特征图,通过第一个FC+Relu将其调整至维度为C/4的特征图,经过第二个FC+hard-sigmoid将其调整至维度为(1,1,C)的特征图,然后与原特征图每个通道对应相乘。
d、利用h-swish代替swish函数,用hard-sigmoid代替sigmoid
在结构中使用了h-swish激活函数,代替swish函数,减少运算量,提高性能,便于移动端量化。
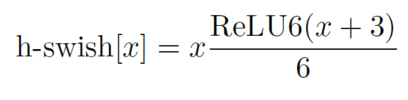

h-swish:https://blog.csdn.net/Harvey_Hawk/article/details/112241168
RELU6:https://blog.csdn.net/jsk_learner/article/details/102822001
下图为整个mobilenetV3的结构图:

如何看懂这个表呢?我们从每一列出发:
第一列Input代表mobilenetV3每个特征层的shape变化;
第二列Operator代表每次特征层即将经历的block结构,我们可以看到在MobileNetV3中,特征提取经过了许多的bneck结构;
第三、四列分别代表了bneck内逆残差结构上升后的通道数、输入到bneck时特征层的通道数。
第五列SE代表了是否在这一层引入注意力机制。
第六列NL代表了激活函数的种类,HS代表h-swish,RE代表RELU。
第七列s代表了每一次block结构所用的步长。