[NIPS 2021]Do Transformers Really Perform Bad for Graph Representation
微软提出的graph transformer,名叫Graphormer
Transformer
通常,transformer layer有一个self-attention module和一个position-wise feed-forward network (FFN)组成。
首先将特征映射成三组:
然后用前两组计算attention,应用到第三组上:
Graphormer
structure encoding
centrality encoding
中心性。文中的衡量方式是用度:
后面两个是入度和出度的embedding
spatial encoding
在原始的transformer中,attention机制的好处是每一个token都可以聚合全局信息,但这也会导致token本身的位置信息会被忽略,毕竟在哪都会聚合全局的信息。所以在时序数据中还要有positional encoding。
同样的,graph上也需要有个位置信息,叫Spatial Encoding。为了测量两点之间的空间关系,需要这样的一个映射:
在文中,对于连通的两点选择使用最短距离(SPD),否则就是-1。
将SPD进行embedding可以得到一个偏置向量\(b_{\phi}(v_i, v_j)\),优化相似度矩阵:
可以判断b也是一个数。如果模型让b是递减的话,那么这个模型会更更关注更近的顶点对。
edge encoding in the attention
在上面的基础上增加边的表征:
其中,假设两点之间的最短距离路径为\(SP_{ij} = (e_1, e_2, \dots, e_n)\),按照顺序对这些边的特征依次进行\(w^E_n \in \mathbb{R}^{d_E}\)的加权,并求和得到c:
因为\(w\)的维度和边特征维度一样,因此最后的c实际上是一个数。
Graphormer Layer
和原始的transformer不同,会在hulti-head attention和FFN前使用layer normalization,这在很多工作中已经被证明了是更有效的:
graph pooling
对于graph pooing,文中给图增加了一个特殊点,该点会和所有其他点连接,并在训练过程中和一般点一样进行更新。该点最终的特征会被当做图特征。此外,为了保证其他点的最短距离不会因为这个点而变成2,会为该点的空间embedding设定不同的可学习标量。
Graphormer效果的分析
- 通过选择合适的\(\phi\),Graphormer能够很好地表示其他GNN中的聚合和拼接过程。而又因为最短距离路径能够分辨出1-WL所无法分辨的情况,因此这种方法能够让模型效果更好。
- 选择合适的权重,self-attention配合虚拟节点能够替换pooling过程。而因为有attention,不会出现过平滑问题。
实验
数据集
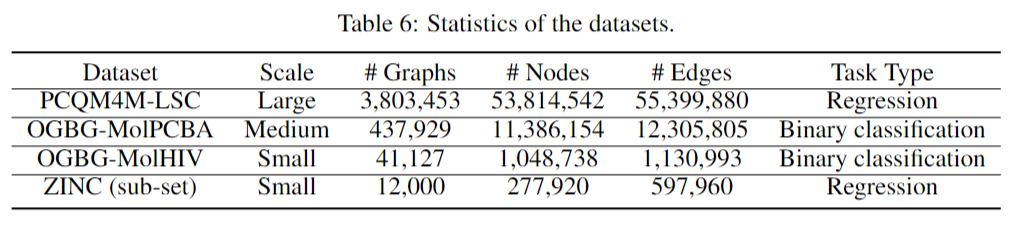
OGB Large-Scale Challenge
对于其他baseline也会使用虚拟节点来做pooling,GT是当时最新的graph transformer模型。Graphormer会有大小两个,大的12层,隐藏层维度768,小的6层512。
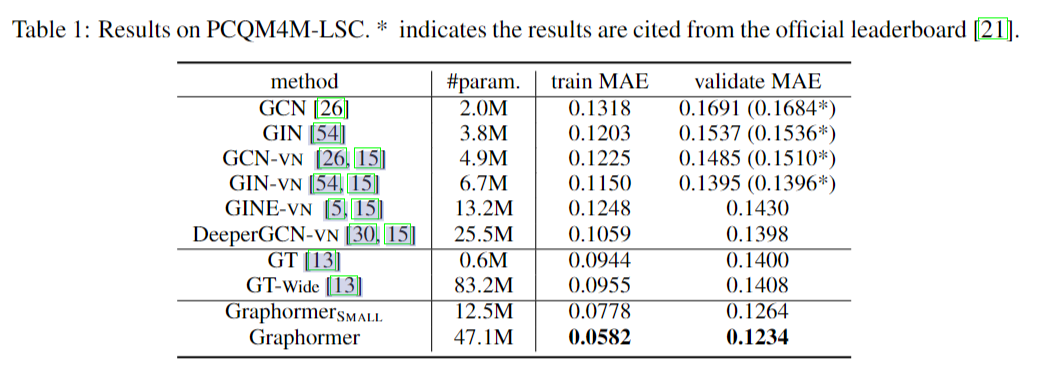
Graph Representation
由于图小模型大,容易出现过拟合的问题,文中提到使用了graph-FLAG的方法,更具体说就是对样本进行一些微小的扰动来增强模型的鲁棒性:
# 为forward函数添加一个perturb参数
def forward(self, x, adj_t, perturb=None):
# 将perturb扰动添加到输入当中,注意不要使用x += perturb。如果输入需要做embedding,请在embedding之后再添加perturb
if perturb is not None:
x = x + perturb
...
外部:
model = GNN(...)
loss_func = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 定义flag, 第一个参数是扰动的维度。
flag = FLAG(data.x.shape[1], loss_func, optimizer)
# 定义一个forward函数获取模型输出
forward = lambda perturb: model(data.x, data.adj_t, perturb)
# 用这行代码替换原来的训练代码
loss, out = flag(model, forward, data.x.shape[0], data.y.squeeze(1))
# 被替换的训练代码:
# optimizer.zero_grad()
# yh = model(data.x, data.adj_t)
# loss = loss_func(yh.float(), data.y.float())
# loss.backward()
# optimizer.step()
对于ZINC,设置SLIM,12层80维度
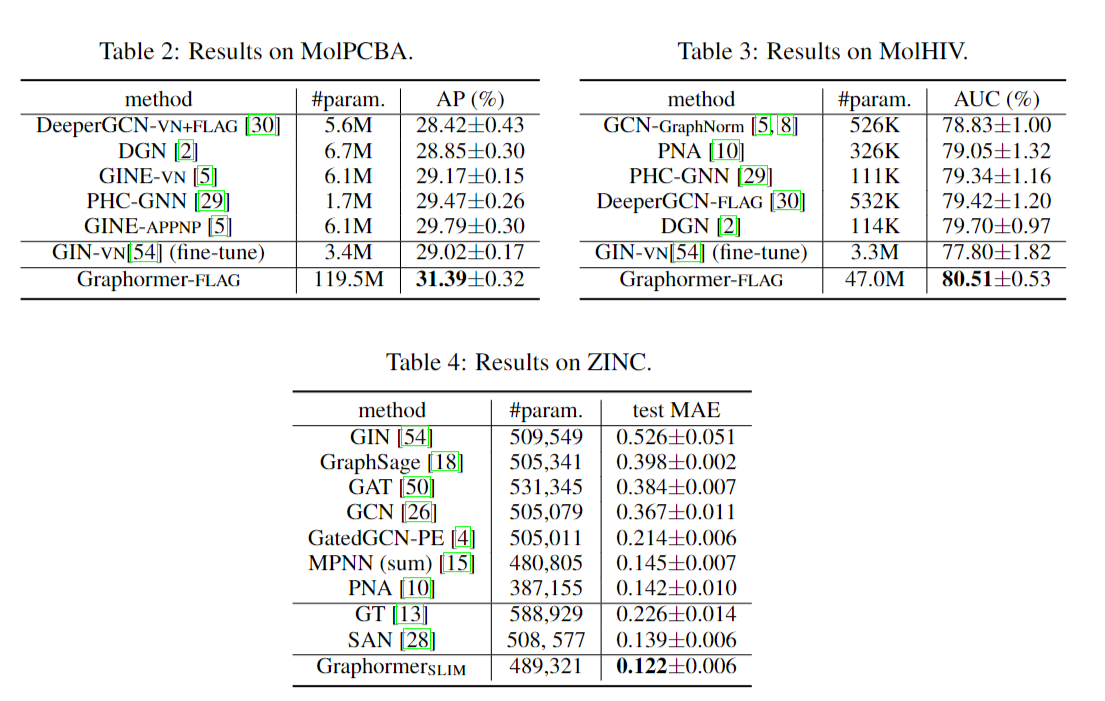
预训练模型比较:
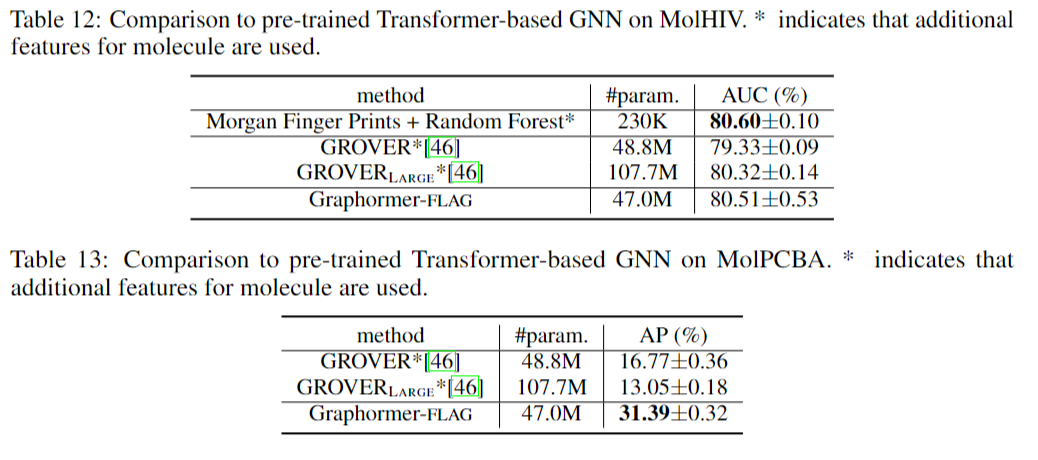
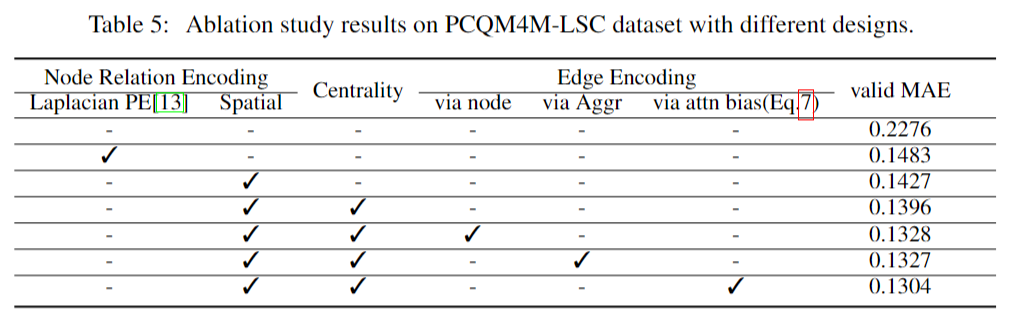
消融实验
- Representation Transformers Perform Really Graphrepresentation transformers perform really representation bidirectional transformers encoder really perform curl_easy_perform management perform ubuntu nvidia curl_easy_perform problem perform access component unmounted perform update 题解 指针perform easily representation