爬虫 增量 头条
python爬虫scrapy入门教程
import scrapy class BlogSpider(scrapy.Spider): name = 'blogspider' start_urls = ['https://www.zyte.com/blog/'] def parse(self, response): for title in ......
【慢慢买嗅探神器】基于scrapy+pyqt的电商数据爬虫系统
### 项目预览 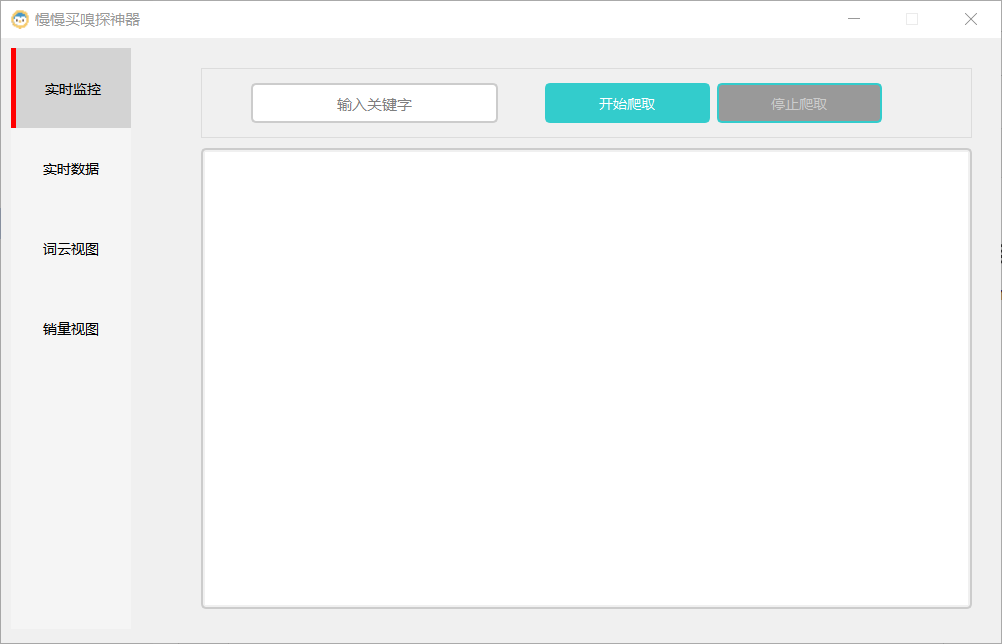 前面添加await进行手动挂起: 4.response.text()前面一定要添加await再次运行程序告警取消: 5.异步爬虫get或post中写入的参数 ......
SpringBoot 版本号(主,次,增量,发布)详解
SpringBoot版本号 访问地址: https://spring.io/projects/spring-boot#learn 每个版本号都有对应的英文CURRENT,GA ,SNAPSHOT对应的名词 3.1.1 CURRENT GA 第一个3 代表的是主版本 第二个1 代表的是次版本,新特性, ......
盘点一个Python网络爬虫抓取股票代码问题(下篇)
大家好,我是皮皮。 ### 一、前言 前几天在Python白银群【厚德载物】问了一个`Python`网络爬虫的问题,这里拿出来给大家分享下。  Python软件包 requests selenium requests和selenium的区别 对于“xxx.html”类型地址的网页,他们的内容是静态的,这种网站一般不会做防护,可以直接用requests爬。 ......
盘点一个Python网络爬虫抓取股票代码问题(上篇)
大家好,我是皮皮。 ### 一、前言 前几天在Python白银群【厚德载物】问了一个`Python`网络爬虫的问题,这里拿出来给大家分享下。 ,python爬虫(发送请求->响应请求->(HTML)->解析数据(Xpath,正则,bs4)-> 保存数据(文本文件,数据库) 数据分析:Spark做数据清洗(数 ......
网关搭建【黑马头条】
一、导入依赖 <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <d ......
微信公众号_爬虫_fiddler_抓包_python
# `wechat_python/run.py` ```py from sqlalchemy import Column, Integer, String, create_engine from sqlalchemy.orm import sessionmaker from sqlalchemy.e ......
爬虫-Scrapy框架安装使用2
Scrapy 框架其他方法功能集合笔记 ### 使用LinkExtractor提取链接 - 使用Selector ``` import scrapy from bs4 import BeautifulSoup class BookSpider(scrapy.Spider): name = "book ......
Java 网络爬虫,就是这么的简单
是 Java 网络爬虫系列文章的第一篇,如果你还不知道 Java 网络爬虫系列文章,请参看 学 Java 网络爬虫,需要哪些基础知识。第一篇是关于 Java 网络爬虫入门内容,在该篇中我们以采集虎扑列表新闻的新闻标题和详情页为例,需要提取的内容如下图所示: 我们需要提取图中圈出来的文字及其对应的链接 ......
go爬虫 简单请求
demo1.go package main import ( "fmt" "io/ioutil" "net/http" ) func fech(url string) string { client := &http.Client{} req, _ := http.NewRequest("GET", ......
爬虫学习基础2
### ```selenium``` - 安装: ``` pip install selenium ``` - 安装浏览器驱动(各个浏览器的驱动是不一样的,推荐**chrome**) ``` - https://registry.npmmirror.com/binary.html?path=chro ......
java爬虫--jsoup的使用
简介: jsoup 是一款基于 Java 的HTML解析器,它提供了一套非常省力的API,不但能直接解析某个URL地址、HTML文本内容,而且还能通过类似于DOM、CSS或者jQuery的方法来操作数据,所以 jsoup 也可以被当做爬虫工具使用。 Document :文档对象。每份HTML页面都是 ......
【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!
[toc] # 一、爬虫对象-豆瓣音乐TOP250 今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣音乐TOP250排行榜数据:https://music.douban.com/top250  今天,我再分 ......
【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
[toc] # 一、爬虫对象-豆瓣读书TOP250 今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣读书TOP250排行榜数据: https://book.douban.com/top250 ![豆瓣网页](https://img2023.cnblogs.com/blog/2864563 ......
Selenium自动化程序被检测为爬虫,怎么屏蔽和绕过
先打开浏览器,再链接操作 1、打开浏览器时添加以下参数: --remote-debugging-port=9222 --user-data-dir="C:\\selenium\\ChromeProfile" 2、selenium中设置浏览器选项,通过上面设置的 9222端口连接浏览器: from s ......