爬虫pytesseract requests selenium
413 Request Entity Too Large
1、client_max_body_size client_max_body_size 是一个Nginx配置指令,用于设置客户端请求体的最大大小限制。 在Nginx中,client_max_body_size指令的默认值是1m(即1兆字节)。这个指令用于限制客户端向服务器发送的请求体的最大大小。当客 ......
python爬虫scrapy入门教程
import scrapy class BlogSpider(scrapy.Spider): name = 'blogspider' start_urls = ['https://www.zyte.com/blog/'] def parse(self, response): for title in ......
【慢慢买嗅探神器】基于scrapy+pyqt的电商数据爬虫系统
### 项目预览 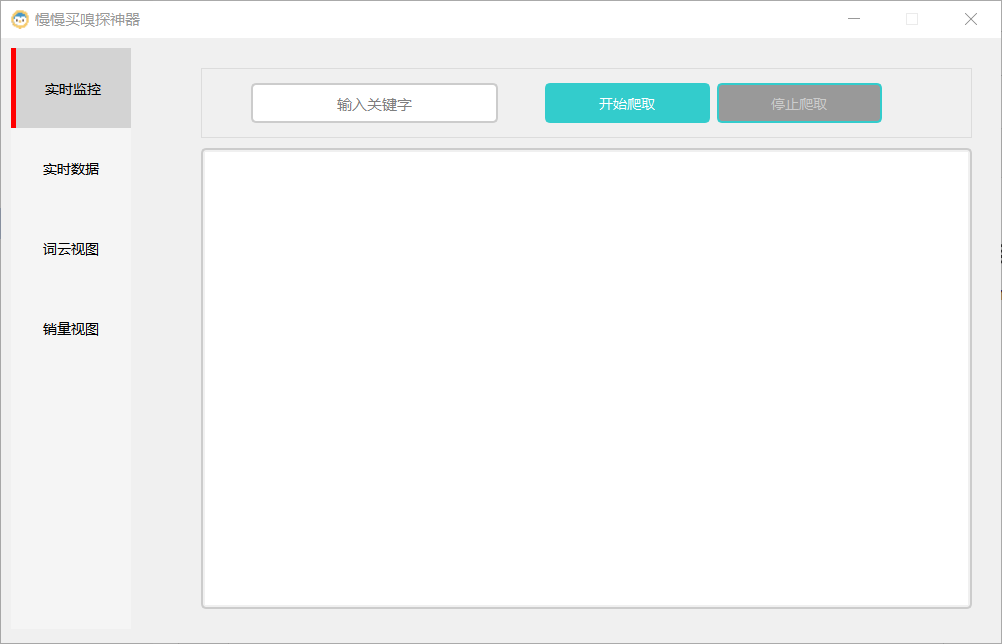 ...解决方案
一、问题描述 进行自动化测试执行程序报错如下图: 二、解决方案 在网上找了好久都没找到答案,最后根据以往经验想到是不是selenium版本有问题,本人python版本是3.11.0,所以将selenium版本也降到3.11.0之后问题解决。 selenium降版本: pip3 install sel ......
requests 下载大文件
# -*- coding: utf-8 -*- from contextlib import closing from requests import get url = 'https://www.test.video/aa' # 但是使用with语句的时候是需要条件的,任何对象,只要正确实现了上下 ......
Python 爬虫实战:驾驭数据洪流,揭秘网页深处
**爬虫,这个经常被人提到的词,是对数据收集过程的一种形象化描述。特别是在Python语言中,由于其丰富的库资源和良好的易用性,使得其成为编写爬虫的绝佳选择。本文将从基础知识开始,深入浅出地讲解Python爬虫的相关知识,并分享一些独特的用法和实用技巧。本文将以实际的网站为例,深入阐述各个处理部分, ......
JMeter中获取Request内容写到Txt文件中
JMeter中获取Request内容写到Txt文件中 参照文档 https://blog.csdn.net/chenqinglanhao/article/details/124125435 import java.net.URLDecoder;import org.json.*; //String ......
Splash与requests结合
Splash与requests结合 render.html 此接口用于获取JavaScript渲染的页面的HTML代码,接口地址就是Splash的运行地址加此接口名称,例如http://localhost:8050/render.html import requests def func1(): ' ......
aiohttp模块引出_aiohttp+多任务异步协程实现异步爬虫
1.为什么要用aiohttp模块引出: 2.异步模块aiohttp对比requests基于同步的区别: 3.需要在response.text()前面添加await进行手动挂起: 4.response.text()前面一定要添加await再次运行程序告警取消: 5.异步爬虫get或post中写入的参数 ......
记录 python request ProxyError报错
【出自】:https://zhuanlan.zhihu.com/p/350015032 侵删 解决办法:在原报错环境中使用下面命令重装低版本 urllib3: pip install urllib3==1.25.11 问题根源 先查了一下 urllib3 的更新日志,应该是 1.26.0 的修改导致 ......
[-003-]-Python3+Unittest+Selenium Web UI自动化测试之显示等待WebDriverWait
1、WebDriverWait基本用法 引入包 # 文件引入 from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as E ......
盘点一个Python网络爬虫抓取股票代码问题(下篇)
大家好,我是皮皮。 ### 一、前言 前几天在Python白银群【厚德载物】问了一个`Python`网络爬虫的问题,这里拿出来给大家分享下。 及常见操作
1、常见的定位方式 id定位:find_element_by_id() name定位:find_element_by_name() class定位:find_element_by_class_name() link定位:find_element_by_link_text() partial link ......
异步爬虫爬取数据碰到的问题
在采用异步http请求模块aiohttp对数据进行获取时,碰到一些奇怪的问题: ```shell OSError: [WinError 121] 信号灯超时时间已到 aiohttp.client_exceptions.ClientConnectorError: Cannot connect to h ......
异步爬虫爬取数据碰到的问题
# 异步爬虫爬取数据碰到的问题 在采用异步http请求模块aiohttp对数据进行获取时,碰到一些奇怪的问题: ```shell OSError: [WinError 121] 信号灯超时时间已到 aiohttp.client_exceptions.ClientConnectorError: Can ......
Application Request Routing 反向代理配置示例
第一步:安装URL Rewrite 第二步:安装Application Request Routing 下载地址:x86 installer / x64 installer第三步:配置 效果图: 对应配置文件 <?xml version="1.0" encoding="UTF-8"?><config ......
Python爬虫简易教程
步骤 1.获取编程软件 Python3 Pycharm社区版(可选,更方便代码编辑) Python软件包 requests selenium requests和selenium的区别 对于“xxx.html”类型地址的网页,他们的内容是静态的,这种网站一般不会做防护,可以直接用requests爬。 ......
盘点一个Python网络爬虫抓取股票代码问题(上篇)
大家好,我是皮皮。 ### 一、前言 前几天在Python白银群【厚德载物】问了一个`Python`网络爬虫的问题,这里拿出来给大家分享下。 
# 绕过系统设置的代理 # 方法一: session = requests.Session() session.trust_env = False response = session.get('http://ff2.pw') # 方法二:(多人亲测可以直接结局这个问题) proxies = { " ......
基于逻辑回归天气预报之爬虫1
# 项目:基于逻辑回归天气预报 **项目简单介绍** 数据来源:ETL(sqoop,Flume,datax,Cannal,Finkx),python爬虫(发送请求->响应请求->(HTML)->解析数据(Xpath,正则,bs4)-> 保存数据(文本文件,数据库) 数据分析:Spark做数据清洗(数 ......
Python错误:selenium自带click方法点击不到元素
问题描述: selenium自带click方法,有的时候不好用,元素定位到了,但是就是点不上。 解决办法: 原因分析:点击不到元素! 解决办法: (1). selenium自带的click()方法: from selenium import webdriverel = driver.find_ele ......
selenium ui自动化遇到切换窗口,点击高级并继续访问的处理方式
在python自动化中(ui),遇到了一个需要浏览器切换窗口,点击“高级”-“接受风险并继续”的操作,前期在本地编写代码调试时,没有任何问题。 切换环境,放到Linux服务中,使用无头模式去运行代码时,发现切换窗口时,总是找不到页面元素,查看截图发现页面为空白,检查两天无果。 场景图片,如下图所示, ......
selenium中操作Cookie
Cookie介绍: Cookie,有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),一般存放在客户端上 以百度首页为例,打开调试工具(F12),点击Application(应用程序),选择 St ......
微信公众号_爬虫_fiddler_抓包_python
# `wechat_python/run.py` ```py from sqlalchemy import Column, Integer, String, create_engine from sqlalchemy.orm import sessionmaker from sqlalchemy.e ......
爬虫-Scrapy框架安装使用2
Scrapy 框架其他方法功能集合笔记 ### 使用LinkExtractor提取链接 - 使用Selector ``` import scrapy from bs4 import BeautifulSoup class BookSpider(scrapy.Spider): name = "book ......