爬虫pytesseract requests selenium
selenium中使用xpath定位
在 XML 文档中,XPath 是一种定位元素的语言。因为 HTML 可以看作 XML 的一种实 现,所以 WebDriver 提供了这种在 Web 应用中定位元素的方法 绝对路径选择 elements = driver.find_elements(By.XPATH, "/html/body/div ......
has been blocked by CORS policy: The request client is not a secure context and the resource is ...
该报错原因为:Chrome浏览器禁止外部请求访问本地,被CORS策略阻止解决方案:1、打开chrome的设置: chrome://flags/#block-insecure-private-network-requests2、将 Block insecure private network requ ......
WEB自动化-selenium-定位方式
定位元素的时候可以修改JS样式来确定定位的元素是否正确 # 通过selenium修改JS属性, 用来确定我定位的元素是什么? driver.execute_script( "arguments[0].setAttribute('style',arguments[1]);", el, "border: ......
elementUI中upload自定义上传行为 http-request属性
需求是上传一个xlsx后台处理完再返回xlsx流upload 请求需要添加responseType: 'blob' 属性所有要扩展一下 若依项目扩展elementUI中upload自定义上传行为 http-request属性 ``` 将文件拖到此处,或点击上传 仅允许导入xls、xlsx格式文件。 ......
(五)selenium定位方式Xpath
豆瓣网:https://book.douban.com/ 作为例子,更好的理解和探索Xpath的定位方法(网页定期更新后如果元素不存在了,请参考截图) 简单的定位例子: //div[@class='top-nav-info'] 准备工作: 打开网页elements: ctrl+shift+c 自带的 ......
Selenium基础:cookie javascript调用 屏幕截图 09
1、cookie操作 绕过登录 get_cookies():以字典形式返回cookie所有信息 get_cookies(name):返回cookie字典中key为name的值 add_cookie(cookie_dict):手动添加cookie。cookie_dict为字典数据格式,cookie_d ......
解决python中requests请求时报错:UnicodeEncodeError: ‘latin-1‘ codec can‘t encode character
当request请求中,带有中文,可能引发报错:  UnicodeEncodeError: 'latin-1' c ......
Python爬虫笔记
爬虫分为四个步骤,首先获取数据,然后解析数据,再提取数据,最后是存储数据 ```python import requests #首先引入requests库 res=requests.get('URL')#向服务器发送了一个请求,把服务器响应结果赋给res,为response对象 res.encodi ......
Selenium基础:文件上传下载操作 08
文件上传 input标签使用send_keys()方法上传,非input标签需要借助工具 1、input标签使用send_keys()方法 #文件上传 #“\\"第一个”\"为转义字符 driver.find_element_by_id('uploadfile').send_keys('D:\\Us ......
requests 请求网页乱码
一般情况下,每个网页有自己的编码,在使用 requests 请求对应网页时,如果遇到中文编码的问题,大多数情况下直接显式指定 encoding 就可以了,但是今天遇到一个网站,还真是怎么指定都不行:https://www.medchemexpress.cn/ 以下所列的参考文档可能能解决编码问题,所 ......
爬虫:爬到的数据存到mysql中、爬虫和下载中间件、加代理,cookie、header、加入selenium、集成selenium、==去重规则源码分析(布隆过滤器)、布隆过滤器、scrapy-redis实现分布式爬虫
[toc] ### 爬到的数据存到mysql中 ```python class FirstscrapyMySqlPipeline: def open_spider(self, spider): print('我开了') self.conn = pymysql.connect( user='root' ......
爬虫:scrapy架构介绍、scrapy解析数据、settings相关配置,提高爬取效率、持久化方案、全站爬取cnblogs文章
[toc] ### scrapy架构介绍 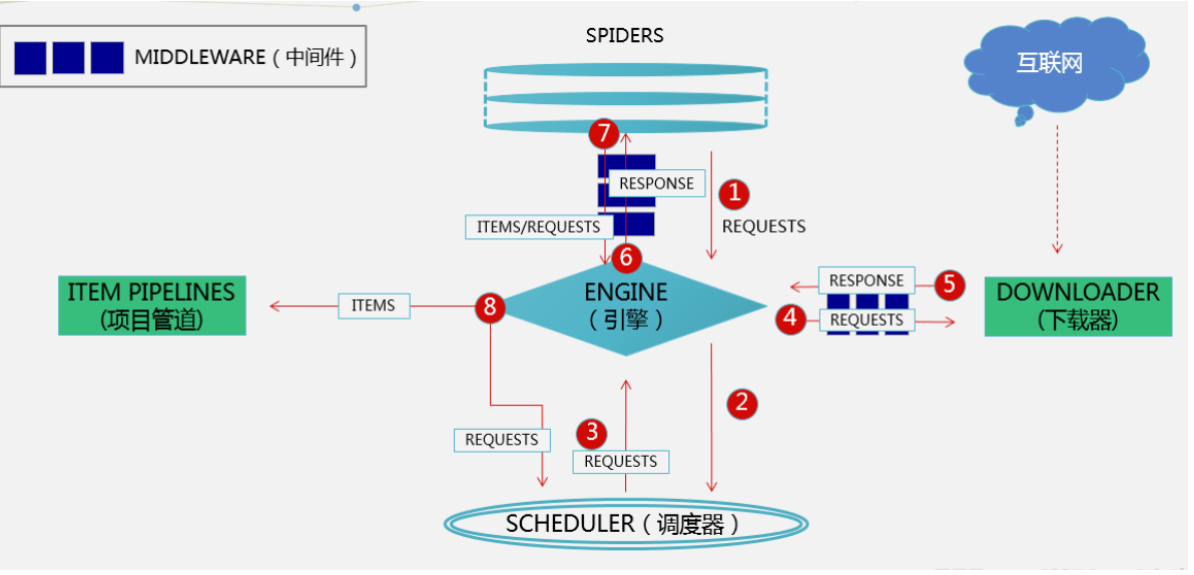 ```python # 引擎(EGINE) 引擎负责控制系统所 ......
selenium中使用CSS 定位
CSS 是一种语言,用来描述 HTML 和 XML 文档的表现。CSS 使用选择器为页面元素 绑定属性。 CSS 选择器可以较为灵活地选择控件的任意属性,一般情况下,CSS 定位速度比 XPath 定位速度快 通过 CSS Selector 选择单个元素的方法是 find_element(By.CS ......
如何利用python做爬虫?
Python爬虫在许多情况下是非常有用的,爬虫可以帮助自动化地从互联网上获取大量数据。这些数据可以是产品信息、新闻文章、社交媒体内容、股票数据等通过爬虫可以减少人工收集和整理数据的工作量,提高效率。在软件开发中,可以使用爬虫来进行自动化的功能测试、性能测试或页面链接检查等。 正常做爬虫都是有一定的模 ......
selenium根据link、partial link选择元素
link 定位 By.LINK_TEXT方法是通过元素标签对之间的文字信息来定位元素的,它专门用来定位文本链接. 百度输入 框上面的几个文字链接的代码如下。 <a class="mnav" name="tj_trnews" href="http://news.baidu.com">新闻</a> <a ......
configure: error: udev support requested but libudev header not installed
./configure --host=arm-none-linux-gnueabi 错误提示:configure: error: udev support requested but libudev header not installed 解决办法 --disable-udev 取消对libude ......
selenium根据class属性、tag名选择元素
根据class属性选择元素 元素也有类型, class 属性就用来标志着元素 类型 若网页html内容如下: <body> <div class="plant"><span>土豆</span></div> <div class="plant"><span>洋葱</span></div> <div c ......
学习爬虫4,selenium基础入门
模拟浏览器测试工具 一般来说 动态就可以用selenium url简化 只抓关键信息 将一些标识自己的内容都可以删除如 webdriver 模拟浏览器 import导入 他可以有页面交互 如find_element_by_id这样去定位id,xpath,name等 模拟输入文字内容 search_b ......
基于Java+selenium+Chrome,实现截取html页面内容并保存为图片
## 1、需求 实现Java程序发送邮件,并将输入的多个页面转为pdf类型附件一同发送出去。而页面如何转为pdf呢?其中的一个方案就是先将html页面转为图片,再将图片合并为pdf。此文记录的是html=>png过程。 ## 2、开发 ### 主要依赖 ```xml org.seleniumhq.s ......
python练习-爬虫(续)
接下来就是查询数据了。 # 识别图片中的文字 #image = Image.open('captcha.png') image = Image.open('G:\Python爬虫\captcha.png') code = pytesseract.image_to_string(image) # 从用 ......
Selenium基础:特殊Dom结构操作 07
特殊Dom结构是指对元素不能直接操作,需要进行特殊定位切换到它所在的Dom结构,然后才能对其元素进行操作 1、windows弹窗 --alert confirm prompt 使用driver.switch_to.alert方法 alert类操作方法: accept():确定 dismiss():取 ......
selenium新的元素定位
> 导包:from selenium.webdriver.common.by import By > > 类型:id、name、class_name、elements、xpath、css_selector、tag_name、link_text、partial_link_text # find_ele ......
【前端开发】好用的可视化爬虫工具
EasySpider 一个可视化爬虫软件,可以无代码图形化的设计和执行爬虫任务 git地址如下 https://github.com/NaiboWang/EasySpider 下载软件地址 https://github.com/NaiboWang/EasySpider/releases 实例效果图 ......
高速——request请求
为防止服务器响应缓慢,导致客服端处理异常,requests请求大多设置 timeout 参数。Requests中timeout不设置默认值。 **读取超时**是没有默认值的,如果不设置,程序将一直处于等待状态。我们的爬虫经常卡死又没有任何的报错信息,原因就在这里了。 ## Timeout 类型: 超 ......
爬虫如何通过HTML和CSS采集数据的 ?
爬虫可以应用于各种应用场景,包括数据分析、市场研究、舆情监测、竞争报、价格比较、内容聚合等。对于需要大量数据的业务和研究领域,爬虫能够提供宝贵的支持。 爬虫可以按照设定的规则从多个网进行批量数据抓取,比人工手动方式更高效。量数据,并支持后续的数据分析和决策。 爬虫可以通过解析HTML和CSS来采集数 ......