爬虫request网站
如何屏蔽GPTBot抓取网站内容
8月8日,OpenAI 推出了GPTBot,和谷歌、Bing等类似的网络爬虫工具,能够自动抓取网站的数据,用来训练 GPT-4 或 GPT-5,提升未来人工智能系统的准确性和能力。 GPTBot user-agent 可通过以下代码识别 User agent token: GPTBot Full u ......
爬虫之selenium
一、selenium模块 之前,我们爬虫是模拟浏览器,但始终不是用的浏览器,但今天我们要说的是另一种爬虫方式,这次不是模拟浏览器,而是用程序去控制浏览器进行一些列操作,也就是selenium。selenium是python的一个第三方库,对外提供的接口可以操控浏览器,比如说输入、点击,跳转,下拉等动 ......
值得收藏的网站
# 值得收藏的网站 # 搞学习 CSDN:https://www.csdn.net/ TED(最优质的演讲):https://www.ted.com/ 谷粉学术:https://gfsoso.99lb.net/scholar.html 大学资源网:http://www.dxzy163.com/ 简答 ......
python里requests库
import requests res=requests.get('http://www.lemfix.com') # print('请求头:',res.request.headers) # print('状态码:',res.status_code) # print('响应头:',res.heade ......
利用爬虫爬知乎少字回答
利用爬虫爬知乎少字回答 # [感谢马哥python说的指导](https://www.cnblogs.com/mashukui/) 最近在学习有关的知识 如果怕对服务器影响 可以修改sleep 时间每次更长一点。 这样就不用看一些营销号的长篇大论 或者看别人写小说了。 在网站设计中扮演了至关重要的角色。JS设计的网站源码,可以充分发挥JS的优势,提供丰富的功能和动态效果,给用户带来更好的体验。 2. 响应式布局 响应式布局是现代网站设 ......
【HarmonyOS】@ohos.request 上传下载的那些事儿
【关键字】 @ohos.request、上传下载 【写在前面】 在进行HarmonyOS应用开发时,可能需要进行上传或下载文件功能开发,本文章主要进行上传下载相关功能介绍和一些注意事项及FAQ。 【上传开发步骤】 步骤1:上传下载接口需要申请ohos.permission.INTERNET权限, ......
大型网站的演化
初始阶段 应用程序、数据库、文件等所有资源在一台服务器上。 典型架构Linux+Apache+Mysql+PHP,简称LAMP。 应用服务和数据服务分离 随着网站业务的发展,一台服务器逐渐不能满足需求:越来越多的用户访问导致性能越来越差,越来越多的数据导致存储空间不足。这时就需要将应用和数据分离。 ......
python爬虫获取script标签中的var变量值
遇到问题: 资料调研过程中遇到js动态生成页面(在检查中可以看到需要爬取的数据,但是查看网页源代码中都是js动态生成,跟检查中的代码不一致),通过xpath在html中获取不到需要的数据,真正的数据在 所需要的数据为script中的var indData,数据类型为包含有许多dict的list 解决 ......
Python 爬虫实战:驾驭数据洪流,揭秘网页深处
前言随着互联网的发展,数据变得越来越重要,爬虫技术也越来越受到人们的关注。爬虫技术可以帮助我们自动化地抓取网络数据,从而提高数据的利用价值。但是,在爬虫过程中,很容易被目标网站识别出来,甚至被封禁。所以,使用代理IP是非常重要的一步。 本篇文章将介绍如何使用Python编写爬虫,并使用代理IP,实现 ......
软件测试网站压力测试报告-权威第三方软件测试机构
软件测试网站压力测试报告 一、测试目的 本次压力测试旨在模拟实际网站系统承受用户并发访问的情况,检测系统的性能、可靠性和稳定性。通过对网站进行多用户并发访问,验证系统在高负载情况下的处理能力和稳定性,为后续优化提供参考依据。 二、测试环境 硬件环境:服务器配置为四核CPU、8GB内存、100Mbps ......
Django博客开发教程:实现网站首页
实现首页模板前,我们先把共公的页面模板base.html调用好。首先我们先看导航部分,除开首页和关于博主之外,其它的其实是我们的文章分类名。如图: 我们只需要在首页视图函数里,查询出所有的文章分类名称,然后在模板页面上展示就行。 blog/views.py from .models import C ......
[Python爬虫]selenium4新版本使用指南
From: 码同学测试公众号 Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等 ......
利用 iframe将其他网站 某一个部分的内容 嵌入到 自己的网站中
[利用 iframe将其他网站 某一个部分的内容 嵌入到 自己的网站中_iframe嵌入网页的一部分_奔跑的长毛象的博客-CSDN博客](https://blog.csdn.net/weixin_42654817/article/details/83141889) ```h5 <!DOCTYPE h ......
Linux下通过Nginx日志分析网站访问情况
- [1. 前言](#1-前言) - [2. 访问IP相关统计](#2-访问ip相关统计) - [2.1. 统计IP访问量(PV)](#21-统计ip访问量pv) - [2.2. 独立IP访问统计(UV)](#22-独立ip访问统计uv) - [2.3. 查看某一时间段的IP访问量(4-5点)](# ......
记录部署lnmp环境的部署网站,自动生成脚本
网站:https://oneinstack.com/auto/ 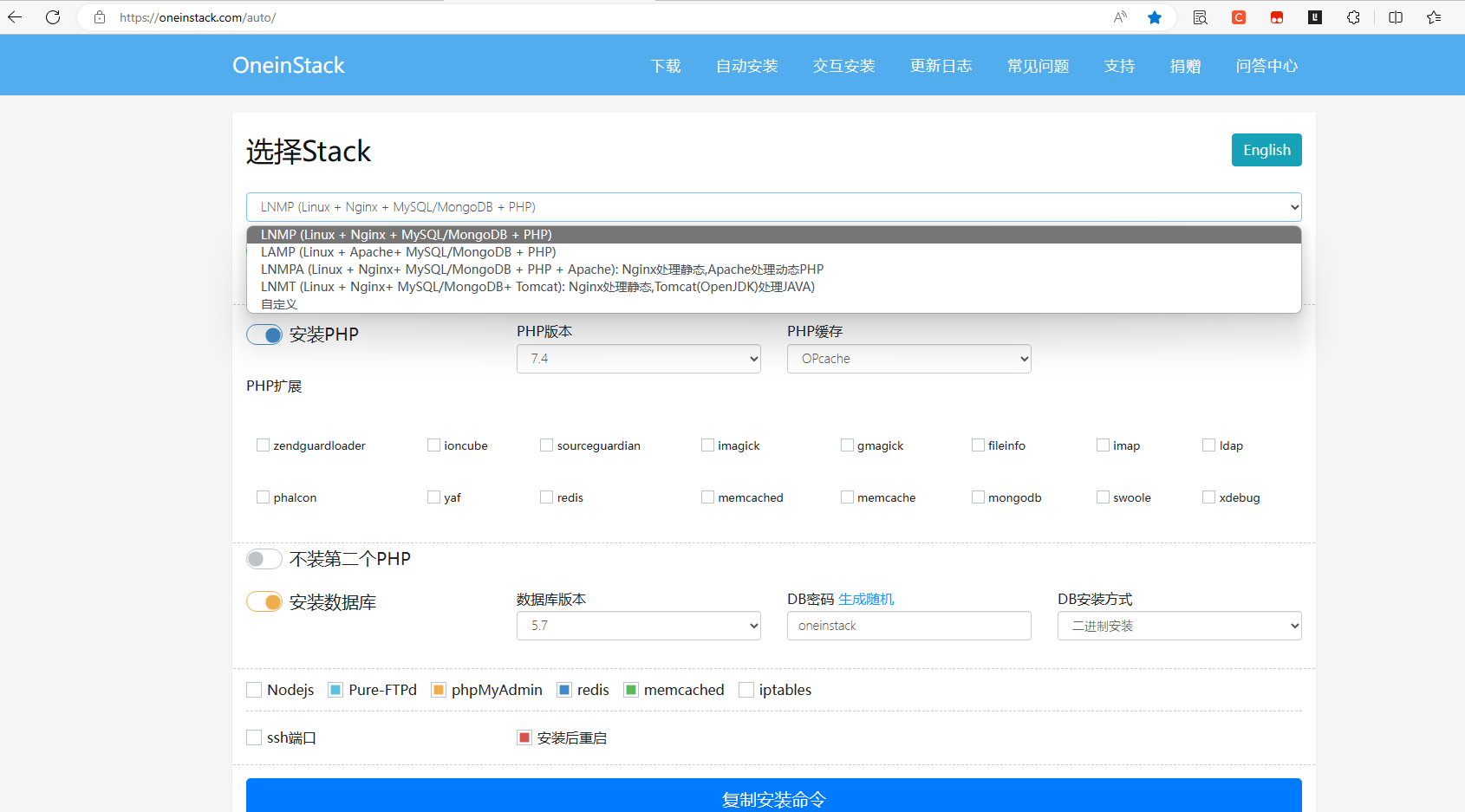 可以选择版本,扩展的插件,很方便,适合快速部署ln ......
构建数据集相关(爬虫、去重、划分)
## 1 爬取图片(crawl_images.py) 爬取百度图片 原文链接:[【Python 爬虫】爬取百度图片](https://zhuanlan.zhihu.com/p/367325899) ```python # -*- coding: utf-8 -*- """ Created on 20 ......
python爬取网站内容保存到文件
1、保存网站内容到文件 知识点: 1、BeautifulSoup 的html5lib 以网页方式展示内容 2、网页打开设置字符集 response_new.encoding = 'UTF-8' 2、文件打开设置字符集 encoding="UTF-8" 3、python对字符串进行处理 ,取list最 ......
python实现简单的爬虫功能
前言Python是一种广泛应用于爬虫的高级编程语言,它提供了许多强大的库和框架,可以轻松地创建自己的爬虫程序。在本文中,我们将介绍如何使用Python实现简单的爬虫功能,并提供相关的代码实例。 如何实现简单的爬虫1. 导入必要的库和模块在编写Python爬虫时,我们需要使用许多库和模块,其中最重要的 ......
Request.url请求路径的一些属性
https://blog.csdn.net/u012726702/article/details/51737795 Request.url请求路径的一些属性1,Request.UrlReferrer.AbsolutePath=获取URL的绝对路径例:"/Manager/Module/Official ......
python 使用BeautifulSoup的 html5lib爬取网站内容
1、使用BeautifulSoup的 'html5lib' 能像网页工具一样渲染内容。 缺点:运行比较慢 2、安装包 pip install html5lib 3、直接获取网页的所有有效内容 import requests #数据请求模块 第三方模块 pip install requests fro ......
安装宝塔上传网站后经常被攻击被挂马,怎么防护呢?
安装宝塔上传网站后经常被攻击被挂马,怎么防护呢? 最近很多人出现网站被挂马,被攻击,被黑的情况, 仔细一问,发现很多人安装个宝塔后,啥防护都没有,啥安全措施也没有弄,这无疑是降低了安全防护。 解决办法: 安装宝塔后,安装一个下面这个防护, 这样就可以给你的服务器和网站添加一道防火墙,虽然不是万能的, ......
PbootCMS网站打开首页报错No input file specified怎么解决
PbootCMS网站打开首页报错No input file specified怎么解决 这个是什么意识呢?怎么解决呢? 解决办法: 网站根目录下有user.ini 删掉刷新就行了 ......
axios 请求拦截(request)与响应拦截(response)
1.请求拦截(request) 请求拦截就是在发ajax之前做些什么!例如:可以在请求拦截里面加个token请求头,做些判断等等! 语法: axios.interceptors.request.use( (config)=>{}, (error)=>{} ) 1.1.参数1:(config)=>{} ......
爬爬《五》:爬虫入门与urllib&requests
# 前情摘要 ## 一、web请求全过程剖析 我们浏览器在输入完网址到我们看到网页的整体内容, 这个过程中究竟发生了些什么? 我们看一下一个浏览器请求的全过程 信息收集工具 - Nmap:网络探测和扫描工具。使用“nmap”命令即可启动,默认运行TCP SYN扫描。 - Dirb:网站目录爆破工具。使用“dirb URL”(其中URL是要扫描的网址)命令即可启动,并根据提示输入其他参数。 # 2)漏洞利用工具 - Metasploit:广泛应用于漏 ......
爬虫不仅仅selenium自动化,还有这些。。。
1.DrissionPage 这款工具既能控制浏览器,也能收发数据包,甚至能把两者合而为一,简单来说:集合了WEB浏览器自动化的便利性和 requests 的高效率优点。 采用全自研的内核,对比 selenium,有以下优点: 无 webdriver 特征,不会被网站识别,无需为不同版本的浏览器下载 ......
python爬虫之scrapy框架介绍
一、Scrapy框架简介Scrapy 是一个开源的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 可以从互联网上自动爬取数据,并将其存储在本地或在 Internet 上进行处理。Scrapy 的目标是提供更简单、更快速、更强大的 ......
【网站搭建】开源社区Flarum搭建记录
## 环境 服务器系统:腾讯云 OpenCloudOS 宝塔版本:免费版8.0.1 Nginx:1.24.0 MySQL:5.7.42 PHP:8.1.21 萌狼蓝天 2023年8月7日 ## PHP设置 1.安装扩展:flieinfo、opcache、exif 2.解除禁用函数:putenv 、 ......
无损音乐从哪找?五个网站+免费下载,你确定不来看看?
hi,大家好我是技术苟,每天晚上22点准时上线为你带来实用黑科技!由于公众号改版,现在的公众号消息已经不再按照时间顺序排送了。因此小伙伴们就很容易错过精彩内容。喜欢黑科技的小伙伴,可以将黑科技百科公众号设为标星,这样就不会走丢啦~ 免责声明 hello,朋友们,黑科技百科所有资源均为免费分享,绝多部 ......