beautifulsoup jsonpath pyquery xpath
jsonpath用法记录
{ "flag": 1, "code": 0, "msg": "成功", "detail": [ { "name": "重疾险", "value": "1", "children": [ { "name": "中银三星人寿123456789012345678901234567890", "value ......
request.js和xpath的结合使用
request.js和xpath可以结合使用,用于在网页中提取特定的数据。具体步骤如下: 1. 安装request和lxml模块: ``` npm install request lxml ``` 2. 引入request和lxml模块: ```javascript var request = re ......
使用Java Xpath 爬取某易云歌曲
> 本文使用Java xpath 爬取某易云歌曲,并下载至本地。 代码仅用于个人学习使用,欢迎各位大佬提出建议。 # 1、添加依赖 ``` xml cn.wanghaomiao JsoupXpath 2.2 cn.hutool hutool-all 5.8.9 ``` # 2、获取音乐id和url ......
BeautifulSoup:学习使用BeautifulSoup库进行HTML解析和数据提取。
BeautifulSoup是一个用于解析HTML和XML文档的Python库。它可以帮助我们从网页中提取数据,并以易于操作的方式进行分析。 以下是使用BeautifulSoup进行HTML解析和数据提取的基本语法: 1. 安装BeautifulSoup库:首先,你需要在你的Python环境中安装Be ......
XPath:学习使用XPath语法提取HTML/XML文档中的数据使用语法
以下是一些XPath语法示例,用于提取HTML/XML文档中的数据: 1. 选择元素: - 选择所有p元素:`//p` - 选择根元素:`/` 2. 属性匹配: - 选择class属性为"example"的div元素:`//div[@class='example']` 3. 文本内容提取: - 提取 ......
【4.0】爬虫之xpath
# 【**xpath解析**】 - xpath在Python的爬虫学习中,起着举足轻重的地位,对比正则表达式 re两者可以完成同样的工作,实现的功能也差不多,但xpath明显比re具有优势,在网页分析上使re退居二线。 - xpath 全称为**XML Path Language** 一种小型的** ......
13用BeautifulSoup爬取网站
代码如下 from bs4 import BeautifulSoup import requests ''' 本例子通过BeautifulSoup 的常用方法find_all 查询出所有包含电影名字的a标签的父节点h4,再通过父节点遍历得到a标签中的文本。 find_all 里面的参数一般是clas ......
Xpath定位方式
Xpath定位方法 **浏览器中如何找到元素** Chrome浏览器:按F12,将鼠标点击下图中的图标,再到浏览器页面上选择需要定位的元素,Elements页中就会自动定位高亮显示页面中的元素。 1.1.绝对路径定位 顾名思义,将Xpath表达式从html的最外层节点,逐层填写,最后定位到操作元素 ......
BeautifulSoup将字符串网页标签,转换为对象,在使用find_all 方法获取实际内容
导入BeautifulSoup库: `from bs4 import BeautifulSoup` 创建BeautifulSoup对象,将HTML文档作为参数传入 ``` html_doc = """ Apple Banana Orange """ soup = BeautifulSoup(html ......
BeautifulSoup 使用多条件查询
最近开始学习python的爬虫,开始的时候单纯的用requests.get(url)取得源代码后,用正则表达后来取得相关的数据,效率不高,接触到BeautifulSoup,发现确实方便. 正好遇到一个问题,需要取的数据在两个div中,是两个class名,最开始的时候是取得两次来得到数据,就想精简一下 ......
python 使用BeautifulSoup的 html5lib爬取网站内容
1、使用BeautifulSoup的 'html5lib' 能像网页工具一样渲染内容。 缺点:运行比较慢 2、安装包 pip install html5lib 3、直接获取网页的所有有效内容 import requests #数据请求模块 第三方模块 pip install requests fro ......
Beautifulsoup4
[toc] # 一 爬取新闻 ```python # 1 爬取网页 requests # 2 解析 xml包含html格式 xml格式,用了re匹配的 html,bs4,lxml... json: -python :内置的 -java : fastjson 》漏洞 -java: 谷歌 Gson -g ......
【答疑】jsonpath和beanshell配合使用案例
问题 今天提升群小伙伴问了这样一个问题: 接口返回如下(list元素个数不确定),需要提取所有的iautoid,然后用逗号拼接起来,如果是如下返回,需要得到的结果是1687283717749342208,1679392630364184576,后续请求需要使用 { "data": { "firstP ......
lxml及xpath语法学习记录
# lxml库及xpath总结 [1、Lxml库简介及作用](#1) [2、HTML方法、tostring方法](#2) [3、xpath语法](#3) 1、Lxml库简介及作用 - Lxml库是基于libxml2的XML解析库的封装。只用C语言编写,用xpath语法解析定位网页数据 - 导入方法: ......
beautifulsoup学习记录
# BeautifulSoup库总结 [ 1、BeautifulSoup库作用 ](#1) [ 2、BeautifulSoup()方法 ](#2) [ 3、find()、find_all()、selector()、get()方法 ](#3) 1、BeautifulSoup库作用 - 用于将爬取到的网 ......
xpath丶BeautifulSoup丶pyquery丶jsonpath 解析html与json串
XPath与jsonpath 1 import json 2 from jsonpath import jsonpath 3 4 def json_test(): 5 str1 = '{"name":"埃里克森"}' 6 # 将字符串转为Python dict对象 7 js_obj = json.l ......
::before中的元素无法用xpath进行定位
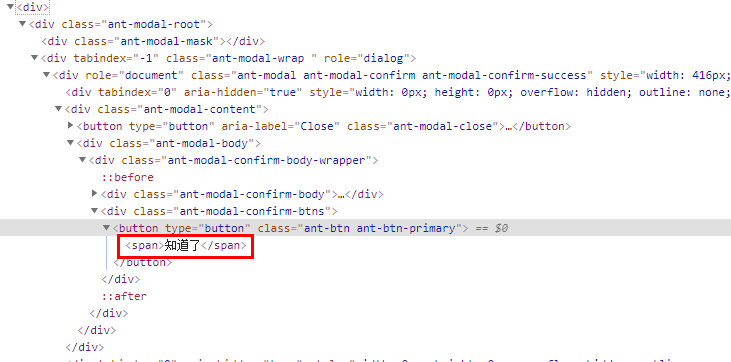 上述代码中定位知道了这个按钮,使用常规的xpath无法定位到,查了很多资料有说什么js转的等等,都不对, ......
【笔记整理】xpath复习
又是xpath.... 10年前学java就学过了...哈哈哈 要就看w3cschool的教程就行了, **函数部分会用得到:** [https://www.w3school.com.cn/xpath/xpath_functions.asp](https://www.w3school.com.cn/ ......
04 selenium:等待元素加载 ,元素操作,执行js,切换选项卡,前进后退,异常处理,登录cnblogs,抽屉半自动点赞,xpath使用,动作链,自动登录12306,打码平台,打码平台自动登录
# 1 selenium等待元素加载 ```python # 程序执行速度很快 》获取标签 》标签还没加载好 》直接去拿会报错 # 显示等待:当你要找一个标签的时候,给它加单独加等待时间 # 隐士等待:只要写一行,代码中查找标签,如果标签没加载好,会自动等待 browser.implicitly_w ......
xpath轴定位
应用场景-> 多用于爬虫 语法-> 轴名称::节点名称 例如://p/ancestor::div 轴名称 结果 ancestor 选取当前节点的所有先辈 (父、祖父等) ancestor-or-self 选取当前节点的所有先辈 (父、祖父等) 以及当前节点本身 attribute 选取当前节点的所有 ......
使用selenium、xpath、半自动点赞、自动登录
## selenium等待元素加载 ```python # 程序执行速度很快 》获取标签 》标签还没加载好 》直接去拿会报错 # 显示等待:当你要找一个标签的时候,给它单独加等待时间 # 隐士等待:只要写一行,代码中查找标签,如果标签没加载好,会自动等待 bro.implicitly_wait(10 ......
selenium、xpath、打码平台
[toc] ## 1 selenium等待元素加载 ```python # 程序执行速度很快 》获取标签 》标签还没加载好 》直接去拿会报错 # 显示等待:当你要找一个标签的时候,给它加单独加等待时间 # 隐士等待:只要写一行,代码中查找标签,如果标签没加载好,会自动等待 browser.impli ......
xpath使用
```plaintext ### xpath使用 ```python 页面中定位元素(标签),两种通用方式 # -css选择器 # -xpath:XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言 # xpath语法 # div 选取di ......
显示网页xpath元素的chrome插件
这个是我用到的最好的xpath浏览器chrome插件(包括edge浏览器) XPath Helper : https://chrome.google.com/webstore/detail/hgimnogjllphhhkhlmebbmlgjoejdpjl 在页面上,按住shift键,然后鼠标经过的地 ......
让python的lxml模块的xpath支持正则表达式
python的lxml模块是处理xml文档的比较好用的工具, 其中的xpath函数可以检索指定的元素, 但是它不支持正则表达式, 比如某个属性的值是否匹配某个正则表达式, 就没有办法实现. 不过可以利用它的自定义函数扩展功能来实现, 如下代码所示: ```python import re from ......
urllib+BeautifulSoup爬取并解析2345天气王历史天气数据
urllib+BeautifulSoup爬取并解析2345天气王历史天气数据 网址:[东城历史天气查询_历史天气预报查询_2345天气预报](https://tianqi.2345.com/wea_history/71445.htm) selenium定位方式Xpath
豆瓣网:https://book.douban.com/ 作为例子,更好的理解和探索Xpath的定位方法(网页定期更新后如果元素不存在了,请参考截图) 简单的定位例子: //div[@class='top-nav-info'] 准备工作: 打开网页elements: ctrl+shift+c 自带的 ......