dataframe columns rename pandas
pandas模块---------------------求和,求平均
求和,求平均import pandas as pdstudent = pd.read_excel('C:/Users/Administrator/Desktop/1.xlsx')student = student.set_index('ID')temp = student[['Test_1','Te ......
raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 73 (char 72)
json.loads()函数只能将一个合法的JSON字符串转换为相应的Python对象(例如字典、列表等)。它无法处理包含多个JSON字符串的字符串 第一种str='{"code": 9999, "data": "", "flag": "11", "msg": "该用户不存在!", "success ......
【pandas小技巧】--按类型选择列
本篇介绍的是`pandas`选择列数据的一个小技巧。之前已经介绍了很多选择列数据的方式,比如`loc`,`iloc`函数,按列名称选择,按条件选择等等。 这次介绍的是按照列的**数据类型**来选择列,按类型选择列可以帮助你快速选择正确的数据类型,提高数据分析的效率。 # 1. 类型种类 `panda ......
pandas模块--------------------基础篇学习
1.读取Excel数据 Python通过pandas库可以轻松地读取Excel数据。pandas库是一个专门用于数据分析和处理的库,它可以将Excel中的数据读取为DataFrame格式,便于进行后续的数据分析和操作。 import pandas as pddata = pd.read_excel( ......
pandas模块-------------------一次读取多个excel文件并合并
合并不同excel表格的内容: 代码如下: import pandas as pdimport osinputdir=r'C:\\Users\\Administrator\\Desktop\\test'df_empty=pd.DataFrame(columns=['名称','列1','列2'])fo ......
odoo pandas
fieldstr = '''id,debit,credit,balance''' self.env.cr.execute('''select %s from account_move_line order by id desc''' % fieldstr) try: a = self.env.cr. ......
用concat比较两个dataframe
因为equals会比对索引等,可能出现内容相同但是行序不同比对失败,可以采用concat,去除重复后如果为空则表示数据一致。 1 #比对两个DataFrame 2 3 if df1.equals(df2): 4 return True, None 5 else: 6 diff_row = pd.co ......
大数据量时生成DataFrame避免使用效率低的append方法
转载请注明出处:https://www.cnblogs.com/oceanicstar/p/10900332.html append方法可以很方便地拼接两个DataFrame df1.append(df2) > A B > 1 A1 B1 > 2 A2 B2 > 3 A3 B3 > 4 A4 B4 ......
pandas模块-----------比对不同数据(部分相同)
代码如下: import pandas as pd# 学生成绩表df_grade = pd.read_excel("find.xlsx")df_grade.head()# 学生信息表df_sinfo = pd.read_excel("data.xlsx")df_sinfo.head()# 只筛选第二 ......
lightdb alter table add column 语法支持括号
## 背景 在 Oracle 中,在旧表上用 `alter table` 命令一次添加多列是可以把列定义放在要括号里的,而 lightdb 之前版本 `alter table` 命令必须要多次执行 `add ...`. 此次版本允许 lightdb 有同样功能。LightDB 版本为 `LightD ......
用 Rust 生成 Ant-Design Table Columns
经常开发表格,是不是已经被手写Ant-Design Table的Columns整烦了?尤其是ToB项目,表格经常动不动就几十列。每次照着后端给的接口文档一个个配置,太头疼了,主要是有时还会粘错就尴尬了。那有没有办法能自动生成columns配置呢? ......
Pandas学习笔记之常用功能
一、数值计算和统计 1.数学计算方法 # 主要数学计算方法,可用于Series和DataFrame(1) df = pd.DataFrame({'key1':np.arange(10), 'key2':np.random.rand(10)*10}) print(df) print(' ') prin ......
Pandas学习笔记之时间处理
一、Pandas时刻数据 时刻数据代表时间点,是pandas的数据类型,是将值与时间点相关联的最基本类型的时间序列数据 1.pd.Timestamp date1 = datetime.datetime(2016,12,1,12,45,30) # 创建一个datetime.datetime date2 ......
Schema-validation: wrong column type encountered in column [NAME] in table [BUS]; found [nvarchar2 (Types#NVARCHAR)], but expecting [varchar2(255 char) (Types#VARCHAR)]
属性的类型出错 NVARCHAR 和 VARCHAR 不同 @Column(name = "NAME", columnDefinition = "nvarchar2(50)") private String name; ......
Pandas学习笔记之Dataframe
一、Dataframe基本概念 # 二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。 data = {'name': ['Jack', 'Tom', 'Mary'], 'age': [18, 19, 20], 'gender': [' ......
【pandas小技巧】--随机挑选子集
在 `pandas` 中,如果遇到数据量特别大的情况,随机挑选 DataFrame 的子集可以帮助我们更深入地了解数据,从而更好地进行数据分析和决策。 随机挑选子集的用途主要有: 1. 评估数据质量:随机挑选 DataFrame 的子集可以帮助我们检查数据集的质量,以便进一步探索和挖掘数据。例如,我 ......
Pandas学习笔记之Series
一、Series基本概念及创建 1.基本概念 # Series 数据结构 # Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引 # 导入numpy、pandas模块 import numpy as np import pandas ......
使用pandas.to_html时怎么自定义表格样式
# 一、通过标签名设置`css`样式 使用`pd.to_html()`方法如果不指定文件路径,该函数会返回一个格式化的`html`字符串,我们可以对这个字符串进行自定义操作,比如直接用我们设置的`css`样式加上这个格式化的`html`,就可以实现自定义表格样式,如下: ```python data ......
DataFrame随机选行+纵向拼接
#### `Dataframe`随机选行 (1)`dataframe`实例: ``` city_data = {'city': ['beijing', 'shanghai', 'xining', 'dalian', 'xian', 'chongqing'], 'location': ['north' ......
DataFrame筛选多行和多列
#### Dataframe筛选多行 在实际数据筛选的时候,有时候需要选择多行,例如,有一个列表数据,需要在Dataframe里筛选,某列中在列表数据中的行。 在这种情况下可以使用`isin`语法。具体如下: ``` obj_df = df[df['obj_col'].isin(obj_list)] ......
前端请求报错:'JSON parse error: syntax error, expect {, actual e…1, line 1, column 2selectUid%5B%5D=VluJeA9upFXgJD', code: '500'}
1、如果不用 JSON.stringify(inputJson) 包起来就会报错 let inputJson = {"selectUid" : selectUid}; var response = await $.ajax({ type: 'POST', url: 'xxx', data: inpu ......
rgi heatmap 报错AttributeError: 'DataFrame' object has no attribute 'append'
在使用rgi heatmap 时候运行时候报错: rgi heatmap -i rgi_json/ --output rgi_heatmap -cat gene_family -clus samples 报错: Traceback (most recent call last): File "/gp ......
idea解析sql语句报错:Unable to resolve column 'uname'
### 1. 如题 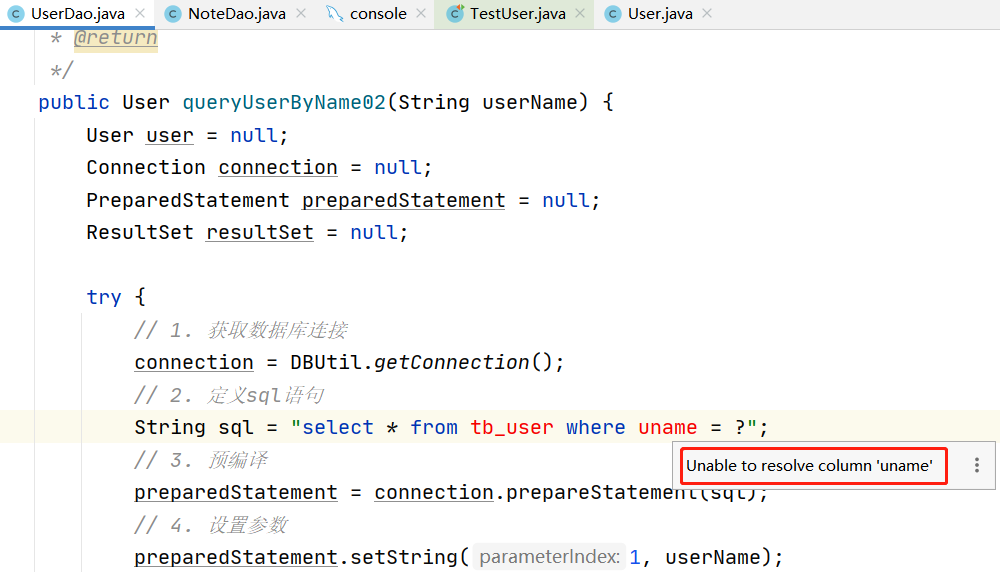 ### 2. 解决办法 : Index column size too large. The maximum column size is 767 bytes.
MySQL版本5.6.35 在一个长度为512字符的字段上创建unique key报错 CREATE DATABASE dpcs_metadata DEFAULT CHARACTER SET utf8; select * from information_schema.SCHEMATA; + + + ......
rename
rename 用字符串替换的方式批量改变文件名 ## 补充说明 rename命令存在两个版本用法上有所区别 ```bash C语言版本, 支持通配符 [常用通配符说明] ? 表示一个任意字符 * 表示一个或一串任意字符 Perl版本, 支持正则表达式 [常用正则表达式符号说明] ^ 匹配输入的开始位 ......
【864】pandas dataframe根据规则批量赋值
ref: Pandas新增一列并按条件赋值? 把下图中的 NaN 都赋值为 0 df.loc[条件判断, 'value'] = 0 m = pd.merge(gdf_africa, df_af_mp, how='left', on='country') m.loc[m['value'].isna() ......
pandas-2023-07-20
1、用pandas读取文件,如果是字符串类型会被当做object类型。 2、用head可以传入要输出显示的行数,但是指定行数不包括表头(并且观察到表头行不作为索引值0),另外,如果不传入参数时会默认输出表头加5行表格内容,weather.csv文件引用自以下博客https://blog.csdn.n ......
【pandas小技巧】--读取多个文件
日常分析数据时,只有单一数据文件的情况其实很少见,更多的情况是,我们从同一个数据来源定期或不定期的采集了很多数据文件;或者从不同的数据源采集多种不同格式的数据文件。 在这样的情况下,分析数据之前,需要将不同的数据集合并起来。合并数据一般有两个维度,一是同构的数据集合并后行数增加;一是异构的数据集合并 ......
invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved
``` ... 1 more Caused by: java.io.FileNotFoundException: File does not exist: hdfs://ns1/user/hive/warehouse/dw.db/dw_uniswapv3_position_detail/pk_day ......