flink hudi
阿里云flink操作示例
前期简单查询:(不同版本语法或有不同,当前版本:专有云flink1.11) 1、可以先简单定义自己的源表字段(下图test),进行简单查询,确定结果是否输出(结果输出是一直存在的,源表实时新增一条数据,查询结果就会新增一条数据) 备注:以下示例特殊信息写成自己的信息;可定义多个源表 2、定义结果表( ......
flink个人理解
1.广播 想把配置streamConfig,广播到流stream中 stream.connect(streamConfig.broadcast(映射描述器msd)); // msd的作用有2(a.泛型, b.获取广播数据context.getBroadcastState(msd)只有通过这个msd才 ......
第三章 Flink 集群搭建
# Flink集群搭建 ```text Flink 可以选择的部署方式有: Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。 我们主要对 Standalone 模式和 Yarn 模式下的 Flink 集群部署进行分析。 我们对sta ......
Flink实时数仓
### 为什么分层? 复杂的问题简单化 避免重复计算 参考大厂做法 ### ods层 1. 采集到ods链路: 用户行为数据(前端埋点):前端埋点=》Nginx=》日志服务器(springboot--落盘成log)=》flume==》kafka:topic_log 业务数据(MySQL):mysql ......
Flink 运行架构
# 第四章 Flink 运行架构 ## 4.1 Yarn 模式任务提交流程 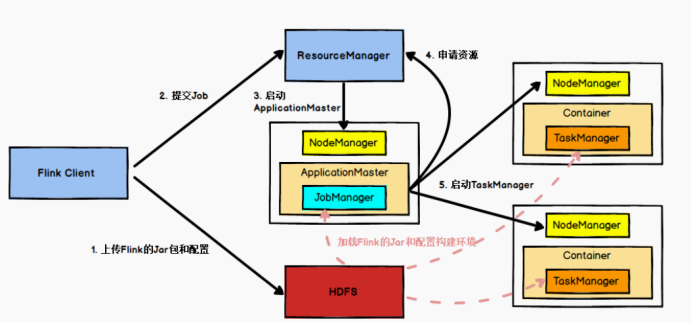 ``` text (1)Fl ......
全网最详细4W字Flink入门笔记(上)
本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord) 微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5 ......
全网最详细4W字Flink入门笔记(下)
本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord) 微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5 ......
大数据生态圈/Hadoop/Spark/Flink/数据仓库/实时分析/推荐系统
课程实用性很强,老师讲的很透彻,都是面试容易问到的;紧扣当前企业所用技术,对于从事大数据或者转行大数据行业,都有很大的帮助。 比屋教育,秉承“活学活用”的教育理念,集合资深专家讲师团队,依托完善的线上教学管控平台,专注于大数据、云计算、互联网架构师等领域的职业技能培训,着力培养满足互联网企业实际需求 ......
大数据Flink之基本架构
第二章 Flink基本架构 2.1 JobManager 与 TaskManager Flink 运行时包含了两种类型的处理器: JobManager 处理器:也称之为 Master,用于协调分布式执行,它们用来调度 task,协调检查点,协调失败时恢复等。Flink 运行时至少存在一个 maste ......
大数据Flink之概述
大数据课程之 Flink 第一章 概述 1.1 流处理技术的演变 在开源世界里,Apache Storm 项目是流处理的先锋。Storm 最早由 Nathan Marz和创业公司 BackType 的一个团队开发,后来才被 Apache 基金会接纳。Storm 提供了低延迟的流处理,但是它为实时性付 ......
flink demo
## 1. 搭建测试环境安装 ### 1.1 下载并启动docker-compose容器 ```bash # 该 Docker Compose 中包含的容器有: # DataGen:数据生成器。容器启动后会自动开始生成用户行为数据,并发送到 Kafka 集群中。默认每秒生成 1000 条数据,持续生 ......
如何不加锁地将数据并发写入Apache Hudi?
最近一位 Hudi 用户询问他们是否可以在不需要任何锁的情况下同时从多个写入端写入单个 Hudi 表。 他们场景是一个不可变的工作负载。 一般来说对于任何多写入端功能,Hudi 建议启用锁定配置。 但这是一个有趣的问题,我们进行探索并找到了解决方案,因此与更广泛的社区分享。 # 需要并发写入的锁提供 ......
flink初识
一、flink:apache开源的一款流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。 二、Flink是一个计算框架和分布 ......
Flink DataStream API
Flink 的 DataSet 和 DataStream 的 API,并模拟了实时计算的场景。 说好的流批一体呢 现状 Flink 很重要的一个特点是“流批一体”,然而事实上 Flink 并没有完全做到所谓的“流批一体”,即编写一套代码,可以同时支持流式计算场景和批量计算的场景。目前截止 1.10 ......
Flink
[官网](https://flink.apache.org/ "官网") ``` https://flink.apache.org/ ``` ##### 下载安装包 ``` https://flink.apache.org/downloads.html https://dlcdn.apache.or ......
Apache Hudi 元数据字段揭秘
# 介绍 Apache Hudi 最初由Uber于 2016 年开发,旨在实现一个交易型数据湖,该数据湖可以快速可靠地支持更新,以支持公司拼车平台的大规模增长。 Apache Hudi 现在被业内许多人广泛用于构建一些非常大规模的数据湖。 Apache Hudi 为快速变化的环境中管理数据提供了一个 ......
Flink 核心技术与实战
你将获得 熟练掌握 Flink SQL 接口的原理与操作方法; 深入理解 Flink DataStream API 的实践原理; 全面剖析 Flink Runtime 的设计与实现机制; 完整构建一个实时推荐数据流系统。 课程介绍目前大部分公司的大数据处理工作,使用的还是离线处理技术,但未来,流式计 ......
虚拟机安装Flink步骤
1、先下载一个flink ,下载地址:https://flink.apache.org/downloads.html#apache-flink-172 2、通过xshell的FTP复制到虚拟机文件夹/usr/flink下 3、执行命令解压:tar -zxvf flink-1.15.0-bin-sca ......
Flink的JobManger-Dispatcher执行流程
# 背景 通过命令行向Flink集群提交任务,都经过哪些环节,中间的调用关系是什么。 这里以Yarn模式为例,通过Flink任务提交至Yarn集群,由Yarn的AM开始执行Flink代码作为入口,尝试进行分析。 Flink里的代码调用关系比较复杂,这里只列了部分关键点,太过于琐碎的代码就没有具体深入 ......
一文解开主流开源变更数据捕获技术之Flink CDC的入门使用
相比前面介绍maxwell,实时数据采集中最主流技术非Flink CDC莫属,其直接省去中间的消息中间件如kafka,且支持增量采集也支持全量采集;本篇先介绍CDC的技术和分类,进一步了解其特性和支持丰富数据源,最后通过FLink DataStream和SQL两种编程示例解开入门。 ......
Flink任务提交至Yarn的流程分析
# 背景 肯定会有人好奇,我们写的Flink任务代码是如何执行的,本着学习的态度,以flink-yarn的方式,在阅读源码的基础上做一个自己的总结。 # 环境信息 jdk:1.8 scala:2.12 flink:1.13 hadoop:3.0 hadoop相关的环境搭建就不赘述了,参考网上文档即可 ......
聊聊Flink CDC必知必会
CDC是(Change Data Capture变更数据获取)的简称。 核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 ## Flink CDC的设 ......
Flink任务提交流程分析
# 背景说明 在早期的Flink1.9时,为了对Flink任务的进行部署管理,对Flink任务提交的流程进行分析。刚好以前的博客图片失效了,那就用Flink1.13来再读一遍相关源码。 # 任务提交 flink任务提交的起点是flink脚本,以提交至Yarn为例,我们运行wordcount的脚本如下 ......
基于 Flink CDC 构建 MySQL 到 Databend 的 实时数据同步
这篇教程将展示如何基于 Flink CDC 快速构建 MySQL 到 Databend 的实时数据同步。本教程的演示都将在 Flink SQL CLI 中进行,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE。 假设我们有电子商务业务,商品的数据存储在 MySQL ,我们需要 ......
性能提升30%!袋鼠云数栈基于 Apache Hudi 的性能优化实战解析
Apache Hudi 是一款开源的[数据湖解决方案](https://www.dtstack.com/dtengine/easylake?src=szsm),它能够帮助企业更好地管理和分析海量数据,支持高效的[数据更新和查询](https://www.dtstack.com/dtengine/ea ......
window wsl 无法访问flink webui
[https://blog.csdn.net/weixin_38988171/article/details/126012785](https://blog.csdn.net/weixin_38988171/article/details/126012785) 修改flink配置文件 ``` res ......
聊聊Flink必知必会(四)
### 概述 Flink Streaming API借鉴了谷歌数据流模型(Google Data Flow Model),它的流API支持不同的时间概念。Flink明确支持以下3个不同的时间概念。 Flink明确支持以下3个不同的时间概念。 (1)事件时间:事件发生的时间,由产生(或存储)事件的设备 ......
聊聊Flink的必知必会(三)
### 概述 在进行流处理时,很多时候想要对流的有界子集进行聚合分析。例如有如下的需求场景: (1)每分钟的页面浏览(PV)次数。 (2)每用户每周的会话次数。 (3)每分钟每传感器的最高温度。 (4)当电商发布一个秒杀活动时,想要每隔10min了解流量数据。 对于这些需求的处理,程序需要处理元素组 ......
Flink提交任务命令整理
环境: Flink 1.13.6和Flink 1.14.4 yarn-session模式: --启动yarn seeion bin/yarn-session.sh \ -s 8 \ -jm 4g \ -tm 16g \ -nm yarn-session-flink \ -d yarn-session ......
Flink1.13.6 部署踩坑记录
环境 Hadoop集群是Ambari2.7.5的版本 Flink是1.13.6_2.12的版本 问题记录 1.缺少jar包 报错:ERROR org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Error while running the Flin ......