前言
知识点
- 定级:入门级
- KubeKey 安装部署 ARM 版 KubeSphere 和 Kubernetes
- ARM 版麒麟 V10 安装部署 KubeSphere 和 Kubernetes 常见问题
实战服务器配置 (个人云上测试服务器)
| 主机名 | IP | CPU | 内存 | 系统盘 | 数据盘 | 用途 |
|---|---|---|---|---|---|---|
| ksp-master-1 | 172.16.33.16 | 8 | 16 | 50 | 200 | KubeSphere/k8s-master/k8s-worker |
| ksp-master-2 | 172.16.33.22 | 8 | 16 | 50 | 200 | KubeSphere/k8s-master/k8s-worker |
| ksp-master-3 | 172.16.33.23 | 8 | 16 | 50 | 200 | KubeSphere/k8s-master/k8s-worker |
| 合计 | 3 | 24 | 48 | 150 | 600 |
实战环境涉及软件版本信息
-
服务器芯片:Kunpeng-920
-
操作系统:麒麟 V10 SP2 aarch64
-
KubeSphere:v3.4.0
-
Kubernetes:v1.26.5
-
Containerd:1.6.4
-
KubeKey: v3.0.13
1. 本文简介
本文介绍了如何在 麒麟 V10 aarch64 架构服务器上部署 KubeSphere 和 Kubernetes 集群。我们将使用 KubeSphere 开发的 KubeKey 工具实现自动化部署,在三台服务器上实现高可用模式最小化部署 Kubernetes 集群和 KubeSphere。
KubeSphere 和 Kubernetes 在 ARM 架构 和 x86 架构的服务器上部署,最大的区别在于所有服务使用的容器镜像架构类型的不同,KubeSphere 开源版对于 ARM 架构的默认支持可以实现 KubeSphere-Core 功能,即可以实现最小化的 KubeSphere 和完整的 Kubernetes 集群的部署。当启用了 KubeSphere 可插拔组件时,会遇到个别组件部署失败的情况,需要我们手工替换官方或是第三方提供的 ARM 版镜像或是根据官方源码手工构建 ARM 版镜像。如果需要实现开箱即用及更多的技术支持,则需要购买企业版的 KubeSphere。
本文是我调研 KubeSphere 开源版对 ARM 架构服务器支持程度的实验过程文档。文中详细的记录了在完成最终部署的过程中,遇到的各种问题报错及相应的解决方案。由于能力有限,本文中所遇到的架构不兼容的问题,大部分采用了手工替换第三方仓库或是官方其他仓库相同或是相似 ARM 版本镜像的方案。建议计划在生产中使用的读者最好能具备使用官方源码及 DockerFile 构建与 x86 版本完全相同的 ARM 版容器镜像的能力,不要替换相近版本或是使用第三方镜像。也正是因为本文并没有完全利用官方源码及 Dockerfile 构建 ARM 相关镜像,只是重新构建了比较简单的 ks-console 组件,所以才取名为不完全指南。
由于之前已经写过多篇比较详细的安装部署文档,因此,本文不会过多展示命令执行结果的细节,只提供关键的命令输出。
1.1 确认操作系统配置
在执行下文的任务之前,先确认操作系统相关配置。
- 操作系统类型
[root@ks-master-1 ~]# cat /etc/os-release
NAME="Kylin Linux Advanced Server"
VERSION="V10 (Sword)"
ID="kylin"
VERSION_ID="V10"
PRETTY_NAME="Kylin Linux Advanced Server V10 (Sword)"
ANSI_COLOR="0;31"
- 操作系统内核
[root@ks-master-1 ~]# uname -a
Linux KP-Kylin-ZH-01 4.19.90-24.4.v2101.ky10.aarch64 #1 SMP Mon May 24 14:45:37 CST 2021 aarch64 aarch64 aarch64 GNU/Linux
- 服务器 CPU 信息
[root@ksp-master-1 ~]# lscpu
Architecture: aarch64
CPU op-mode(s): 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 8
NUMA node(s): 1
Vendor ID: HiSilicon
Model: 0
Model name: Kunpeng-920
Stepping: 0x1
BogoMIPS: 200.00
L1d cache: 512 KiB
L1i cache: 512 KiB
L2 cache: 4 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-7
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Not affected
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma d
cpop asimddp asimdfhm
2. 操作系统基础配置
请注意,以下操作无特殊说明时需在所有服务器上执行。本文只选取 Master-1 节点作为演示,并假定其余服务器都已按照相同的方式进行配置和设置。
2.1 配置主机名
hostnamectl set-hostname ksp-master-1
2.2 配置 DNS
echo "nameserver 114.114.114.114" > /etc/resolv.conf
2.3 配置服务器时区
配置服务器时区为 Asia/Shanghai。
timedatectl set-timezone Asia/Shanghai
2.4 配置时间同步
- 安装 chrony 作为时间同步软件。
yum install chrony
- 修改配置文件 /etc/chrony.conf,修改 ntp 服务器配置。
vi /etc/chrony.conf
# 删除或注释所有的 pool 配置
pool pool.ntp.org iburst
# 增加国内的 ntp 服务器,或是指定其他常用的时间服务器
pool cn.pool.ntp.org iburst
# 上面的手工操作,也可以使用 sed 自动替换
sed -i 's/^pool pool.*/pool cn.pool.ntp.org iburst/g' /etc/chrony.conf
注意:这一步也可以忽略,使用系统默认配置。
- 重启并设置 chrony 服务开机自启动。
systemctl enable chronyd --now
- 验证 chrony 同步状态
# 执行查看命令
chronyc sourcestats -v
2.5 禁用 SELinux
系统默认启用了 SELinux,为了减少麻烦,我们所有的节点都禁用 SELinux。
# 使用 sed 修改配置文件,实现彻底的禁用
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 使用命令,实现临时禁用,这一步其实不做也行,KubeKey 会自动配置
setenforce 0
2.6 防火墙配置
systemctl stop firewalld && systemctl disable firewalld
2.7 安装系统依赖
在所有节点上,以 root 用户登陆系统,执行下面的命令为 Kubernetes 安装系统基本依赖包。
# 安装 Kubernetes 系统依赖包
yum install curl socat conntrack ebtables ipset ipvsadm -y
3. 操作系统磁盘配置
服务器新增一块数据盘 /dev/vdb(具体名字取决于虚拟化平台类型),用于 Containerd 和 Kubernetes Pod 的持久化存储。
请注意,以下操作无特殊说明时需在集群所有节点上执行。本文只选取 Master-1 节点作为演示,并假定其余服务器都已按照相同的方式进行配置和设置。
3.1 使用 LVM 配置磁盘
为了满足部分用户希望在生产上线后,磁盘容量不足时可以实现动态扩容。本文采用了 LVM 的方式配置磁盘(实际上,本人维护的生产环境,几乎不用 LVM)。
- 创建 PV
pvcreate /dev/vdb
- 创建 VG
vgcreate data /dev/vdb
- 创建 LV
# 使用所有空间,VG 名字为 data,LV 名字为 lvdata
lvcreate -l 100%VG data -n lvdata
3.2 格式化磁盘
mkfs.xfs /dev/mapper/data-lvdata
3.3 磁盘挂载
- 手工挂载
mkdir /data
mount /dev/mapper/data-lvdata /data/
- 开机自动挂载
tail -1 /etc/mtab >> /etc/fstab
3.4 创建数据目录
- 创建 OpenEBS 本地数据根目录
mkdir -p /data/openebs/local
- 创建 Containerd 数据目录
mkdir -p /data/containerd
- 创建 Containerd 数据目录软连接
ln -s /data/containerd /var/lib/containerd
说明:KubeKey 到 v3.0.13 版为止,一直不支持在部署的时候更改 Containerd 的数据目录,只能用这种目录软链接到变通方式来增加存储空间(也可以提前手工安装 Containerd,建议)。
3.5 磁盘配置自动化 Shell 脚本
上述所有操作,都可以整理成自动化配置脚本。
pvcreate /dev/vdb
vgcreate data /dev/vdb
lvcreate -l 100%VG data -n lvdata
mkfs.xfs /dev/mapper/data-lvdata
mkdir /data
mount /dev/mapper/data-lvdata /data/
tail -1 /etc/mtab >> /etc/fstab
mkdir -p /data/openebs/local
mkdir -p /data/containerd
ln -s /data/containerd /var/lib/containerd
4. 安装部署 KubeSphere 和 Kubernetes
4.1 下载 KubeKey
本文将 master-1 节点作为部署节点,把 KubeKey (下文简称 kk) 最新版 (v3.0.13) 二进制文件下载到该服务器。具体 kk 版本号可以在 kk 发行页面 查看。
- 下载最新版的 KubeKey
cd ~
mkdir kubekey
cd kubekey/
# 选择中文区下载(访问 GitHub 受限时使用)
export KKZONE=cn
curl -sfL https://get-kk.kubesphere.io | sh -
# 正确的执行效果如下
[root@ksp-master-1 ~]# cd ~
[root@ksp-master-1 ~]# mkdir kubekey
[root@ksp-master-1 ~]# cd kubekey/
[root@ksp-master-1 kubekey]# export KKZONE=cn
[root@ksp-master-1 kubekey]# curl -sfL https://get-kk.kubesphere.io | sh -
Downloading kubekey v3.0.13 from https://kubernetes.pek3b.qingstor.com/kubekey/releases/download/v3.0.13/kubekey-v3.0.13-linux-arm64.tar.gz ...
Kubekey v3.0.13 Download Complete!
[root@ksp-master-1 kubekey]# ll
total 107012
-rwxr-xr-x 1 root root 76357877 Oct 30 16:56 kk
-rw-r--r-- 1 root root 33215241 Nov 7 16:11 kubekey-v3.0.13-linux-arm64.tar.gz
注意: ARM 版的安装包名称为 kubekey-v3.0.13-linux-arm64.tar.gz
- 查看 KubeKey 支持的 Kubernetes 版本列表
./kk version --show-supported-k8s
注意:输出结果为 KK 支持的结果,但不代表 KubeSphere 和其他 Kubernetes 也能完美支持。生产环境建议选择 v1.24 或是 v1.26。
4.2 创建 Kubernetes 和 KubeSphere 部署配置文件
创建集群配置文件,本示例中,选择 KubeSphere v3.4.0 和 Kubernetes v1.26.5。因此,指定配置文件名称为 kubesphere-v340-v1265.yaml,如果不指定,默认的文件名为 config-sample.yaml。
./kk create config -f kubesphere-v340-v1265.yaml --with-kubernetes v1.26.5 --with-kubesphere v3.4.0
命令执行成功后,在当前目录会生成文件名为 kubesphere-v340-v1265.yaml 的配置文件。
注意:生成的默认配置文件内容较多,这里就不做过多展示了,更多详细的配置参数请参考 官方配置示例。
本文示例采用 3 个节点同时作为 control-plane、etcd 节点和 worker 节点。
编辑配置文件 kubesphere-v340-v1265.yaml,主要修改 kind: Cluster 和 kind: ClusterConfiguration 两小节的相关配置
修改 kind: Cluster 小节中 hosts 和 roleGroups 等信息,修改说明如下。
- hosts:指定节点的 IP、ssh 用户、ssh 密码、ssh 端口。特别注意: 一定要手工指定 arch: arm64,否则部署的时候会安装 X86 架构的软件包。
- roleGroups:指定 3 个 etcd、control-plane 节点,复用相同的机器作为 3 个 worker 节点,。
- internalLoadbalancer: 启用内置的 HAProxy 负载均衡器
- domain:自定义了一个 opsman.top
- containerManager:使用了 containerd
- storage.openebs.basePath:新增配置,指定默认存储路径为 /data/openebs/local
修改后的示例如下:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: sample
spec:
hosts:
- {name: ksp-master-1, address: 172.16.33.16, internalAddress: 172.16.33.16, user: root, password: "P@88w0rd", arch: arm64}
- {name: ksp-master-2, address: 172.16.33.22, internalAddress: 172.16.33.22, user: root, password: "P@88w0rd", arch: arm64}
- {name: ksp-master-3, address: 172.16.33.23, internalAddress: 172.16.33.23, user: root, password: "P@88w0rd", arch: arm64}
roleGroups:
etcd:
- ksp-master-1
- ksp-master-2
- ksp-master-3
control-plane:
- ksp-master-1
- ksp-master-2
- ksp-master-3
worker:
- ksp-master-1
- ksp-master-2
- ksp-master-3
controlPlaneEndpoint:
## Internal loadbalancer for apiservers
internalLoadbalancer: haproxy
domain: lb.opsman.top
address: ""
port: 6443
kubernetes:
version: v1.26.5
clusterName: opsman.top
autoRenewCerts: true
containerManager: containerd
etcd:
type: kubekey
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
## multus support. https://github.com/k8snetworkplumbingwg/multus-cni
multusCNI:
enabled: false
storage:
openebs:
basePath: /data/openebs/local # base path of the local PV provisioner
registry:
privateRegistry: ""
namespaceOverride: ""
registryMirrors: []
insecureRegistries: []
addons: []
修改 kind: ClusterConfiguration 启用可插拔组件,修改说明如下。
- 启用 etcd 监控
etcd:
monitoring: true # 将 "false" 更改为 "true"
endpointIps: localhost
port: 2379
tlsEnable: true
- 启用应用商店
openpitrix:
store:
enabled: true # 将 "false" 更改为 "true"
- 启用 KubeSphere DevOps 系统
devops:
enabled: true # 将 "false" 更改为 "true"
- 启用 KubeSphere 日志系统
logging:
enabled: true # 将 "false" 更改为 "true"
- 启用 KubeSphere 事件系统
events:
enabled: true # 将 "false" 更改为 "true"
注意:默认情况下,如果启用了事件系统功能,KubeKey 将安装内置 Elasticsearch。对于生产环境,不建议在部署集群时启用事件系统。请在部署完成后,参考 可插拔组件官方文档 手工配置。
- 启用 KubeSphere 告警系统
alerting:
enabled: true # 将 "false" 更改为 "true"
- 启用 KubeSphere 审计日志
auditing:
enabled: true # 将 "false" 更改为 "true"
注意:默认情况下,如果启用了审计日志功能,KubeKey 将安装内置 Elasticsearch。对于生产环境,不建议在部署集群时启用审计功能。请在部署完成后,参考 可插拔组件官方文档 手工配置。
- 启用 KubeSphere 服务网格
servicemesh:
enabled: true # 将 "false" 更改为 "true"
istio:
components:
ingressGateways:
- name: istio-ingressgateway # 将服务暴露至服务网格之外。默认不开启。
enabled: false
cni:
enabled: false # 启用后,会在 Kubernetes pod 生命周期的网络设置阶段完成 Istio 网格的 pod 流量转发设置工作。
- 启用 Metrics Server
metrics_server:
enabled: true # 将 "false" 更改为 "true"
说明:KubeSphere 支持用于 部署 的容器组(Pod)弹性伸缩程序 (HPA)。在 KubeSphere 中,Metrics Server 控制着 HPA 是否启用。
- 启用网络策略、容器组 IP 池,服务拓扑图不启用(名字排序,对应配置参数排序)
network:
networkpolicy:
enabled: true # 将 "false" 更改为 "true"
ippool:
type: calico # 将 "none" 更改为 "calico"
topology:
type: none # 将 "none" 更改为 "weave-scope"
说明:
- 从 3.0.0 版本开始,用户可以在 KubeSphere 中配置原生 Kubernetes 的网络策略。
- 容器组 IP 池用于规划容器组网络地址空间,每个容器组 IP 池之间的地址空间不能重叠。
- 启用服务拓扑图以集成 Weave Scope (Docker 和 Kubernetes 的可视化和监控工具),服务拓扑图显示在您的项目中,将服务之间的连接关系可视化。
- 因为对应版本 weave-scope 的 arm64 架构的镜像不好找,需要自己构建,但是该功能实际上用处不大了,该项目都已经停止维护了,所以本文最后放弃了启用该功能。
4.3 部署 KubeSphere 和 Kubernetes
接下来我们执行下面的命令,使用上面生成的配置文件部署 KubeSphere 和 Kubernetes。
export KKZONE=cn
./kk create cluster -f kubesphere-v340-v1265.yaml
上面的命令执行后,首先 kk 会检查部署 Kubernetes 的依赖及其他详细要求。检查合格后,系统将提示您确认安装。输入 yes 并按 ENTER 继续部署。
[root@ksp-master-1 kubekey]# export KKZONE=cn
[root@ksp-master-1 kubekey]# ./kk create cluster -f kubesphere-v340-v1265.yaml
_ __ _ _ __
| | / / | | | | / /
| |/ / _ _| |__ ___| |/ / ___ _ _
| \| | | | '_ \ / _ \ \ / _ \ | | |
| |\ \ |_| | |_) | __/ |\ \ __/ |_| |
\_| \_/\__,_|_.__/ \___\_| \_/\___|\__, |
__/ |
|___/
16:25:51 CST [GreetingsModule] Greetings
16:25:51 CST message: [ksp-master-3]
Greetings, KubeKey!
16:25:51 CST message: [ksp-master-1]
Greetings, KubeKey!
16:25:52 CST message: [ksp-master-2]
Greetings, KubeKey!
16:25:52 CST success: [ksp-master-3]
16:25:52 CST success: [ksp-master-1]
16:25:52 CST success: [ksp-master-2]
16:25:52 CST [NodePreCheckModule] A pre-check on nodes
16:25:53 CST success: [ksp-master-1]
16:25:53 CST success: [ksp-master-2]
16:25:53 CST success: [ksp-master-3]
16:25:53 CST [ConfirmModule] Display confirmation form
+--------------+------+------+---------+----------+-------+-------+---------+-----------+--------+--------+------------+------------+-------------+------------------+--------------+
| name | sudo | curl | openssl | ebtables | socat | ipset | ipvsadm | conntrack | chrony | docker | containerd | nfs client | ceph client | glusterfs client | time |
+--------------+------+------+---------+----------+-------+-------+---------+-----------+--------+--------+------------+------------+-------------+------------------+--------------+
| ksp-master-1 | y | y | y | y | y | y | y | y | y | | | y | | | CST 16:25:53 |
| ksp-master-2 | y | y | y | y | y | y | y | y | y | | | y | | | CST 16:25:53 |
| ksp-master-3 | y | y | y | y | y | y | y | y | y | | | y | | | CST 16:25:53 |
+--------------+------+------+---------+----------+-------+-------+---------+-----------+--------+--------+------------+------------+-------------+------------------+--------------+
This is a simple check of your environment.
Before installation, ensure that your machines meet all requirements specified at
https://github.com/kubesphere/kubekey#requirements-and-recommendations
Continue this installation? [yes/no]:
安装过程日志输出比较多,本文只展示重要的一点,一定要观察下载的二进制包,格式为 arm64(篇幅所限,只展示了部分日志输出)。
Continue this installation? [yes/no]: yes
16:26:32 CST success: [LocalHost]
16:26:32 CST [NodeBinariesModule] Download installation binaries
16:26:32 CST message: [localhost]
downloading arm64 kubeadm v1.26.5 ...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 43.3M 100 43.3M 0 0 1016k 0 0:00:43 0:00:43 --:--:-- 1065k
部署完成需要大约 10-30 分钟左右,具体看网速和机器配置(实际部署过程中,必然会因为镜像架构的问题导致组件异常需要手工干预)。
实际部署时如果不手工干预,必然会出现下面的情况 :
clusterconfiguration.installer.kubesphere.io/ks-installer created
18:13:51 CST skipped: [ksp-master-3]
18:13:51 CST skipped: [ksp-master-2]
18:13:51 CST success: [ksp-master-1]
Please wait for the installation to complete: <---<<
20:13:51 CST skipped: [ksp-master-3]
20:13:51 CST skipped: [ksp-master-2]
20:13:51 CST failed: [ksp-master-1]
error: Pipeline[CreateClusterPipeline] execute failed: Module[CheckResultModule] exec failed:
failed: [ksp-master-1] execute task timeout, Timeout=2h
注意:当出现等待安装完成的滚动条后,应该立即新开终端,使用
kubectl get pod -A关注所有 Pod 的部署情况。根据报错信息,参考下文的「异常组件解决方案」及时排查解决创建和启动异常的组件。
真正的部署完成后,您应该会在终端上看到类似于下面的输出。提示部署完成的同时,输出中还会显示用户登陆 KubeSphere 的默认管理员用户和密码。
clusterconfiguration.installer.kubesphere.io/ks-installer created
17:35:03 CST skipped: [ksp-master-3]
17:35:03 CST skipped: [ksp-master-2]
17:35:03 CST success: [ksp-master-1]
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://172.16.33.16:30880
Account: admin
Password: P@88w0rd
NOTES:
1. After you log into the console, please check the
monitoring status of service components in
"Cluster Management". If any service is not
ready, please wait patiently until all components
are up and running.
2. Please change the default password after login.
#####################################################
https://kubesphere.io 2023-11-07 17:43:50
#####################################################
17:43:53 CST skipped: [ksp-master-3]
17:43:53 CST skipped: [ksp-master-2]
17:43:53 CST success: [ksp-master-1]
17:43:53 CST Pipeline[CreateClusterPipeline] execute successfully
Installation is complete.
Please check the result using the command:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
注意:
- 上面的信息是后补的,实际部署中必然会有中断,需要解决所有组件异常问题后,删除 Pod ks-install,重建部署任务,任务完成后,通过上面最后的
kubectl logs命令查看最终结果。- 当显示上面的部署完成信息后,也不代表所有组件和服务都能正常部署且能提供服务,请查看下文的「异常组件解决方案」 排查解决创建和启动异常的组件。
5. 异常组件及解决方案
由于 KubeSphere 社区版对 ARM 的支持并不完美,默认仅能保证 KubeSphere-Core 在 ARM 架构下能部署成功,当启用了插件后,并不是所有插件都有 ARM 镜像,当没有对应 ARM 版本镜像时,系统拉取 x86 版本的镜像创建并启动服务,因此会导致架构不同引发的服务启动异常,需要根据报错信息解决异常。
解决异常的方案有以下几种:
- 使用官方组件源代码和 Dockerfile 自己构建 ARM 镜像(最优方案,因能力有限,所以本文只涉及 ks-console,后续可能会有更新)
- 使用异常组件官方其他仓库或是第三方提供的相同版本的 ARM 镜像(次优方案,优先在官方找,实在没有再找第三方用户提供的镜像)
- 使用异常组件官方其他仓库或是第三方提供的相近版本的 ARM 镜像(保底方案,仅限于研发测试环境)
本小节只重点记录描述了本文新遇到的问题,之前文档中解决过的问题在这里只是简单写了最终的处理过程。
5.1 解决 metrics-server 异常
这个异常是第一个要处理的,在 kk 部署任务的最后,出现等待部署完成的任务滚动条时就要关注,如果该 Pod 出现异常需要立即处理。
- 获取适配的 ARM 版镜像(相同版本 KubeSphere 官方 ARM 版镜像)
# 拉取 arm64 镜像
crictl pull registry.cn-beijing.aliyuncs.com/kubesphereio/metrics-server:v0.4.2-arm64 --platform arm64
- 镜像重新打 tag(
可不做)
# 删除 amd64 镜像
#crictl rmi registry.cn-beijing.aliyuncs.com/kubesphereio/metrics-server:v0.4.2
# 重新打 tag
# ctr -n k8s.io images tag registry.cn-beijing.aliyuncs.com/kubesphereio/metrics-server:v0.4.2-arm64 registry.cn-beijing.aliyuncs.com/kubesphereio/metrics-server:v0.4.2
- 重新部署组件
# 修改 Deployment 使用的镜像,并重启
kubectl set image deployment/metrics-server metrics-server=registry.cn-beijing.aliyuncs.com/kubesphereio/metrics-server:v0.4.2-arm64 -n kube-system
kubectl rollout restart deployment/metrics-server -n kube-system
5.2 解决 Argo CD 异常
- 获取适配的 ARM 版镜像(相同版本 KubeSphere 官方 ARM 版镜像)
# 找个相同版本的 ARM 架构的镜像
crictl pull kubespheredev/argocd-applicationset-arm64:v0.4.1
- 镜像重新打 tag(为了保持镜像名称风格一致)
ctr -n k8s.io images tag docker.io/kubespheredev/argocd-applicationset-arm64:v0.4.1 registry.cn-beijing.aliyuncs.com/kubesphereio/argocd-applicationset-arm64:v0.4.1
- 重新部署组件
# 修改 Deployment 使用的镜像,并重启
kubectl set image deployment/devops-argocd-applicationset-controller applicationset-controller=registry.cn-beijing.aliyuncs.com/kubesphereio/argocd-applicationset-arm64:v0.4.1 -n argocd
kubectl rollout restart deployment/devops-argocd-applicationset-controller -n argocd
- 验证新的 Pod 创建并启动成功
kubectl get pods -o wide -n argocd | grep applicationset-controller
5.3 解决 Istio 异常
- 获取适配的 ARM 版镜像 (Istio 官方相近版本 ARM 镜像)
# 找个相近版本的 ARM 架构的镜像(官方没有 1.14.6 的 ARM 镜像,从 1.15 开始才原生支持 ARM,所以用了 1.15.7 代替,生产环境可以尝试用 1.14.6 版本的源码编译构建)
crictl pull istio/pilot:1.15.7 --platform arm64
# 确保镜像架构是 arm64
[root@ks-master-2 ~]# crictl inspecti registry.cn-beijing.aliyuncs.com/kubesphereio/pilot:1.15.7 | grep arch
"architecture": "arm64",
- 镜像重新打 tag
ctr -n k8s.io images tag docker.io/istio/pilot:1.15.7 registry.cn-beijing.aliyuncs.com/kubesphereio/pilot:1.15.7
- 重新部署组件
# 修改 Deployment 使用的镜像,并重启
kubectl set image deployment/istiod-1-14-6 discovery=registry.cn-beijing.aliyuncs.com/kubesphereio/pilot:1.15.7 -n istio-system
kubectl rollout restart deployment/istiod-1-14-6 -n istio-system
- 验证新的 Pod 创建并启动成功
kubectl get pods -o wide -n istio-system | grep istio
5.4 解决 http-backupend 异常
- 获取适配的 ARM 版镜像(第三方相同版本 ARM 镜像)
crictl pull mirrorgooglecontainers/defaultbackend-arm64:1.4
- 镜像重新打 tag(为了保持镜像名称风格一致)
ctr -n k8s.io images tag docker.io/mirrorgooglecontainers/defaultbackend-arm64:1.4 registry.cn-beijing.aliyuncs.com/kubesphereio/defaultbackend-arm64:1.4
- 重新部署组件
# 修改 Deployment 使用的镜像,并重启
kubectl set image deployment/default-http-backend default-http-backend=registry.cn-beijing.aliyuncs.com/kubesphereio/defaultbackend-arm64:1.4 -n kubesphere-controls-system
kubectl rollout restart deployment/default-http-backend -n kubesphere-controls-system
- 验证新的 Pod 创建并启动成功
kubectl get pods -o wide -n kubesphere-controls-system | grep default-http-backend
5.5 解决 Jenkins 异常
- 获取适配的 ARM 版镜像(相近版本 KubeSphere 官方 ARM 版镜像)
# 没有找到同版本的,只能找了一个相近版本的 ARM 架构的镜像
crictl pull docker.io/kubesphere/ks-jenkins:v3.4.1-2.319.3 --platform arm64
# 确保 image 架构是 arm64
[root@ksp-master-1 ~]# crictl inspecti docker.io/kubesphere/ks-jenkins:v3.4.1-2.319.3 | grep arch
"architecture": "arm64",
- 镜像重新打 tag(为了保持镜像名风格一致)
ctr -n k8s.io images tag docker.io/kubesphere/ks-jenkins:v3.4.1-2.319.3 registry.cn-beijing.aliyuncs.com/kubesphereio/ks-jenkins:v3.4.1-2.319.3
- 重新部署组件
# 修改 Deployment 使用的镜像及镜像拉取策略,并重新部署
kubectl set image deployment/devops-jenkins devops-jenkins=registry.cn-beijing.aliyuncs.com/kubesphereio/ks-jenkins:v3.4.1-2.319.3 -n kubesphere-devops-system
kubectl set image deployment/devops-jenkins copy-default-config=registry.cn-beijing.aliyuncs.com/kubesphereio/ks-jenkins:v3.4.1-2.319.3 -n kubesphere-devops-system
kubectl patch deployment devops-jenkins --patch '{"spec": {"template": {"spec": {"containers": [{"name": "devops-jenkins","imagePullPolicy": "IfNotPresent"}]}}}}' -n kubesphere-devops-system
kubectl patch deployment devops-jenkins --patch '{"spec": {"template": {"spec": {"initContainers": [{"name": "copy-default-config","imagePullPolicy": "IfNotPresent"}]}}}}' -n kubesphere-devops-system
# 删除 pod,系统会自动重建
kubectl delete pod devops-jenkins-774fdb948b-fmmls -n kubesphere-devops-system
# 也可以用 rollout(可选,视情况而定)
kubectl rollout restart deployment/devops-jenkins -n kubesphere-devops-system
5.6 解决 thanos-ruler 异常
- 查看异常 Pod
[root@ksp-master-1 ~]# kubectl get pods -A -o wide | grep -v Runn | grep -v Com
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubesphere-monitoring-system thanos-ruler-kubesphere-0 1/2 CrashLoopBackOff 200 (2m49s ago) 17h 10.233.116.19 ksp-master-2 <none> <none>
kubesphere-monitoring-system thanos-ruler-kubesphere-1 1/2 Error 203 (5m21s ago) 17h 10.233.89.23 ksp-master-3 <none> <none>
- 查看异常 Pod 使用的镜像
[root@ksp-master-1 kubekey]# kubectl describe pod thanos-ruler-kubesphere-0 -n kubesphere-monitoring-system | grep Image:
Image: registry.cn-beijing.aliyuncs.com/kubesphereio/thanos:v0.31.0
Image: registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus-config-reloader:v0.55.1
- 查看异常 Pod 镜像架构(镜像架构没问题)
[root@ksp-master-1 ~]# crictl inspecti registry.cn-beijing.aliyuncs.com/kubesphereio/thanos:v0.31.0 | grep arch
"architecture": "arm64",
[root@ksp-master-1 ~]# crictl inspecti registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus-config-reloader:v0.55.1 | grep arch
"architecture": "arm64",
后面的细节没来的及记录,因为 ks-apiserver 服务异常,重启 coreDNS 容器后,thanos-ruler 也自动创建成功。
5.7 解决 Minio 异常
- 获取适配的 ARM 版镜像(相近版本 Minio 官方 ARM 版镜像)
# 找个相近版本的 ARM 架构的镜像
# minio
crictl pull minio/minio:RELEASE.2020-11-25T22-36-25Z-arm64
# mc
crictl pull minio/mc:RELEASE.2020-11-25T23-04-07Z-arm64
- 镜像重新打 tag
# minio
crictl rmi registry.cn-beijing.aliyuncs.com/kubesphereio/minio:RELEASE.2019-08-07T01-59-21Z
ctr -n k8s.io images tag docker.io/minio/minio:RELEASE.2020-11-25T22-36-25Z-arm64 registry.cn-beijing.aliyuncs.com/kubesphereio/minio:RELEASE.2019-08-07T01-59-21Z
# mc
crictl rmi registry.cn-beijing.aliyuncs.com/kubesphereio/mc:RELEASE.2019-08-07T23-14-43Z
ctr -n k8s.io images tag --force docker.io/minio/mc:RELEASE.2020-11-25T23-04-07Z-arm64 registry.cn-beijing.aliyuncs.com/kubesphereio/mc:RELEASE.2019-08-07T23-14-43Z
- 重新部署组件
# 重新部署,删除旧的 Pod,系统会自动重建(此步的操作也可以使用修改 minio 对应的 deployment 使用的镜像名称的方式)
kubectl delete pod minio-757c8bc7f-tlnts -n kubesphere-system
kubectl delete pod minio-make-bucket-job-fzz95 -n kubesphere-system
5.8 解决 ks-console 异常
ks-console 在 openEuler 22.03 SP2 的 ARM 环境并没有出现问题,但是在麒麟 V10 上却出现了异常,说明操作系统的差异对于服务的部署也有一定的影响。
- 查看异常 Pod
[root@ksp-master-2 ~]# kubectl get pods -A -o wide | grep -v Runn | grep -v Com
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubesphere-system ks-console-6f77f6f49d-wgd94 0/1 CrashLoopBackOff 5 (10s ago) 3m18s 10.233.89.25 ksp-master-3 <none> <none>
- 查看异常 Pod 的日志
[root@ksp-master-2 ~]# kubectl logs ks-console-6f77f6f49d-wgd94 -n kubesphere-system
#
# Fatal process OOM in insufficient memory to create an Isolate
#
<--- Last few GCs --->
<--- JS stacktrace --->
- 查看异常 Pod 使用的镜像
[root@ksp-master-3 ~]# crictl image ls | grep ks-console
registry.cn-beijing.aliyuncs.com/kubesphereio/ks-console v3.4.0 42b2364bcafe3 38.7MB
- 查看异常 Pod 的镜像架构(表面上看着没问题,架构匹配)
[root@ksp-master-3 ~]# crictl inspecti registry.cn-beijing.aliyuncs.com/kubesphereio/ks-console:v3.4.0 | grep archite
"architecture": "arm64",
- 解决方案
## 解决方案,网上说可以更换 node14 来解决,也可以在 node 12 的基础上增加配置参数 --max-old-space-size=xxx, 修改成 node 14 比较简单,先试试
# 解决思路:重新构建镜像,推送到自己的镜像仓库
# Clone 源代码
git clone https://github.com/kubesphere/console.git
cd console
git checkout -b v3.4.0 v3.4.0
# 修改 Dockerfile
vi build/Dockerfile
将 FROM node:12-alpine3.14 统一换成 FROM node:14-alpine3.14
# 重新构建(docker.io/zstack 是自己的镜像仓库地址)
REPO=docker.io/zstack make container
# 重新 tag 并推送到 镜像仓库
docker tag zstack/ks-console:heads-v3.4.0 zstack/ks-console:v3.4.0
docker push zstack/ks-console:v3.4.0
- 重新拉取新的镜像
# 服务器拉取新镜像
crictl pull docker.io/zstack/ks-console:v3.4.0
crictl rmi registry.cn-beijing.aliyuncs.com/kubesphereio/ks-console:v3.4.0
ctr -n k8s.io images tag --force docker.io/zstack/ks-console:v3.4.0 registry.cn-beijing.aliyuncs.com/kubesphereio/ks-console:v3.4.0
- 重新部署
# 修改镜像拉取策略,并重新部署
kubectl patch deployment ks-console --patch '{"spec": {"template": {"spec": {"containers": [{"name": "ks-console","imagePullPolicy": "IfNotPresent"}]}}}}' -n kubesphere-system
5.9 解决组件异常通用方案
在部署 ARM 的 KubeSphere 和 Kubernetes 集群时,遇到的异常多数都是因为镜像架构不匹配造成的,当遇到本文没有涉及的异常组件时,可以参考以下流程解决。
-
查看异常 Pod
-
查看异常 Pod 的日志
-
查看异常 Pod 使用的镜像
-
查看异常 Pod 镜像架构
-
获取适配的 ARM 版镜像
-
镜像重新打 tag
-
重新部署组件
当确定镜像架构没问题时,有些问题可以通过多次删除重建的方式解决。
6. 部署验证
上面的部署任务完成以后,只能说明基于 ARM 架构的 KubeSphere 和 Kubernetes 集群部署完成了。 但是整体功能是否可用,还需要做一个验证。
本文只做基本验证,不做详细全功能验证,有需要的朋友请自行验证测试。
6.1 KubeSphere 管理控制台验证集群状态
我们打开浏览器访问 master-1 节点的 IP 地址和端口 30880,可以看到 KubeSphere 管理控制台的登录页面。
输入默认用户 admin 和默认密码 P@88w0rd,然后点击「登录」。
登录后,系统会要求您更改 KubeSphere 默认用户 admin 的默认密码,输入新的密码并点击「提交」。
提交完成后,系统会跳转到 KubeSphere admin 用户工作台页面,该页面显示了当前 KubeSphere 版本为 v3.4.0,可用的 Kubernetes 集群数量为 1。
接下来,单击左上角的「平台管理」菜单,选择「集群管理」。

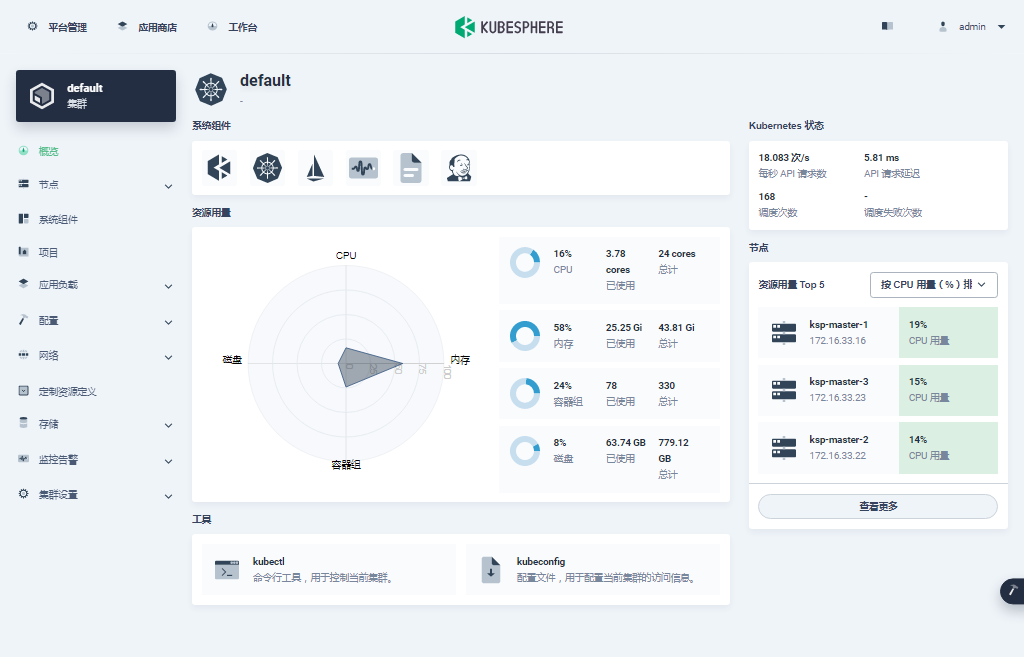
进入集群管理界面,在该页面可以查看集群的基本信息,包括集群资源用量、Kubernetes 状态、节点资源用量 Top、系统组件、工具箱等内容。
单击左侧「节点」菜单,点击「集群节点」可以查看 Kubernetes 集群可用节点的详细信息。

单击左侧「系统组件」菜单,可以查看已安装组件的详细信息。
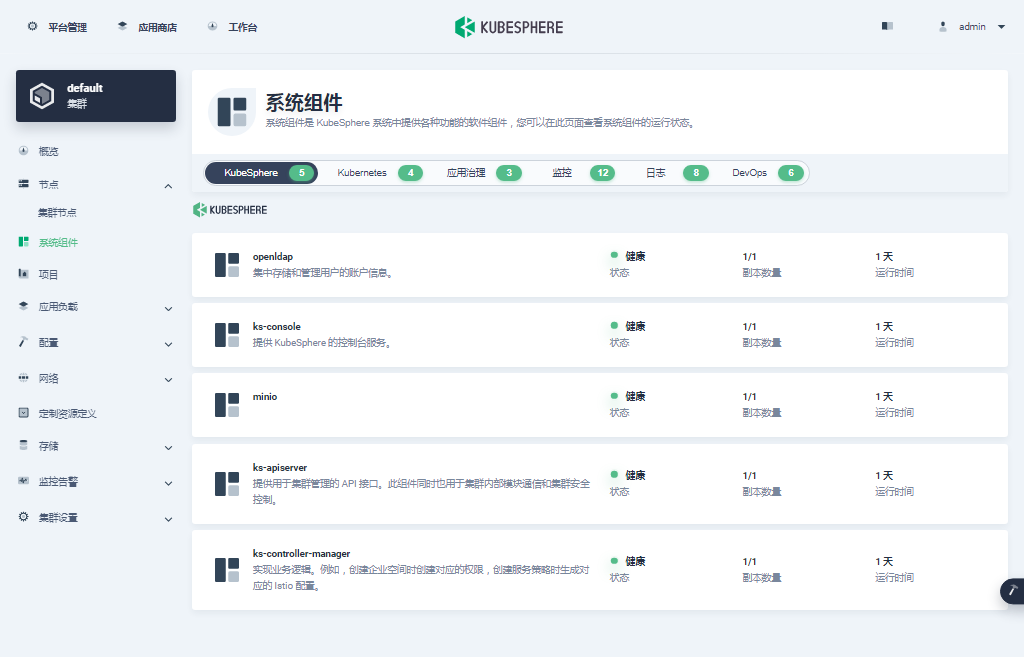
接下来我们粗略的看一下我们部署集群时启用的可插拔插件的状态。
- 应用商店
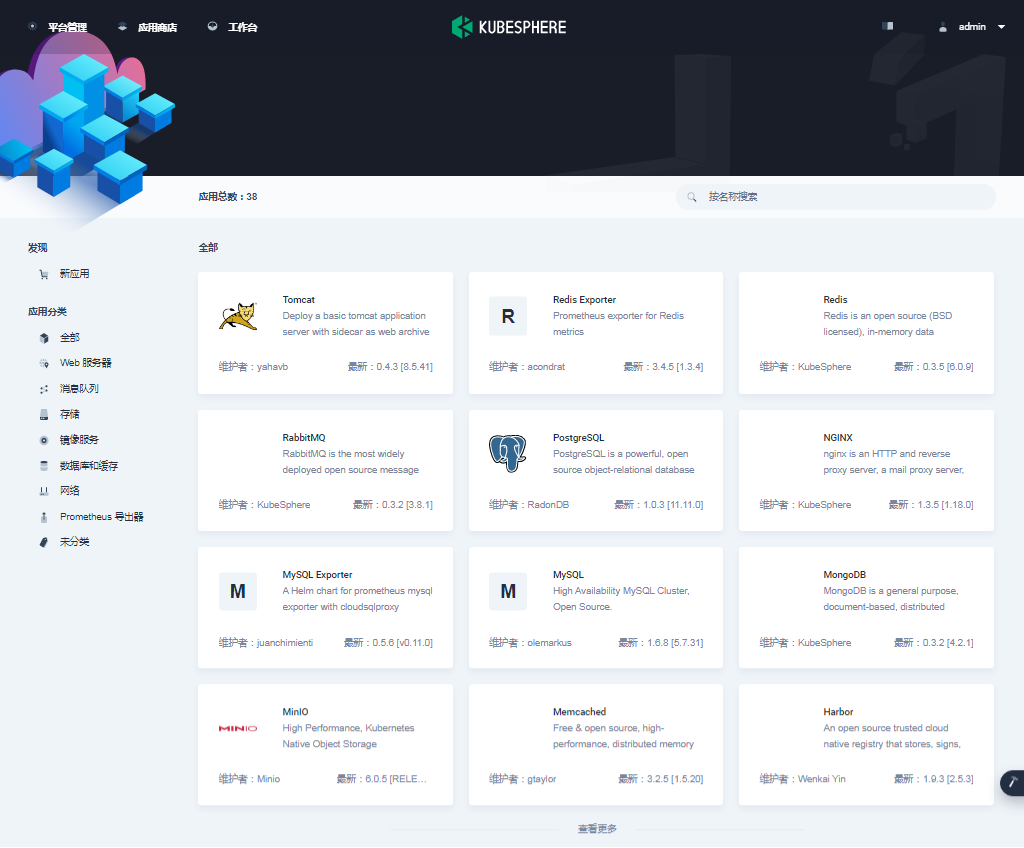
- KubeSphere 日志系统

- KubeSphere 事件系统
- KubeSphere 审计日志
- KubeSphere 告警系统

- KubeSphere 服务网格(实际功能未验证测试)
- Metrics Server(页面没有,需要启用 HPA 时验证)
- 网络策略(实际中也不一定能用到)
- 容器组 IP 池
KubeSphere DevOps 系统是实际使用中的重点,我们通过几张截图专项验证(实现过程略,所有组件状态正常,实际测试中流水线也能正常创建)
- DevOps 系统组件
- DevOps 项目及流水线(创建项目 -> 创建流水线 -> 使用官方提供的模板编辑流水线 -> 运行流水线)
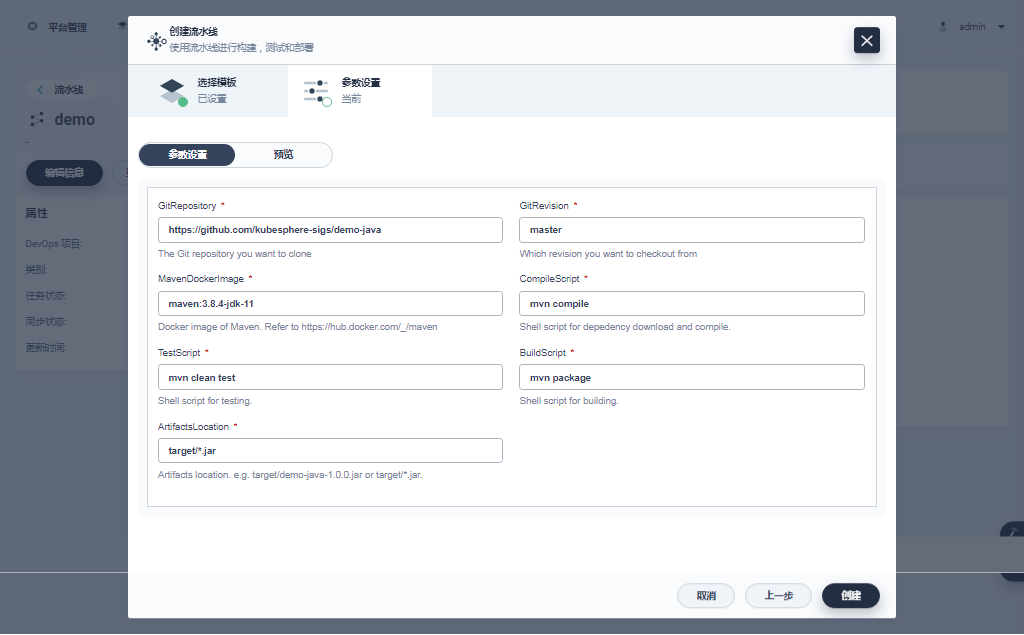
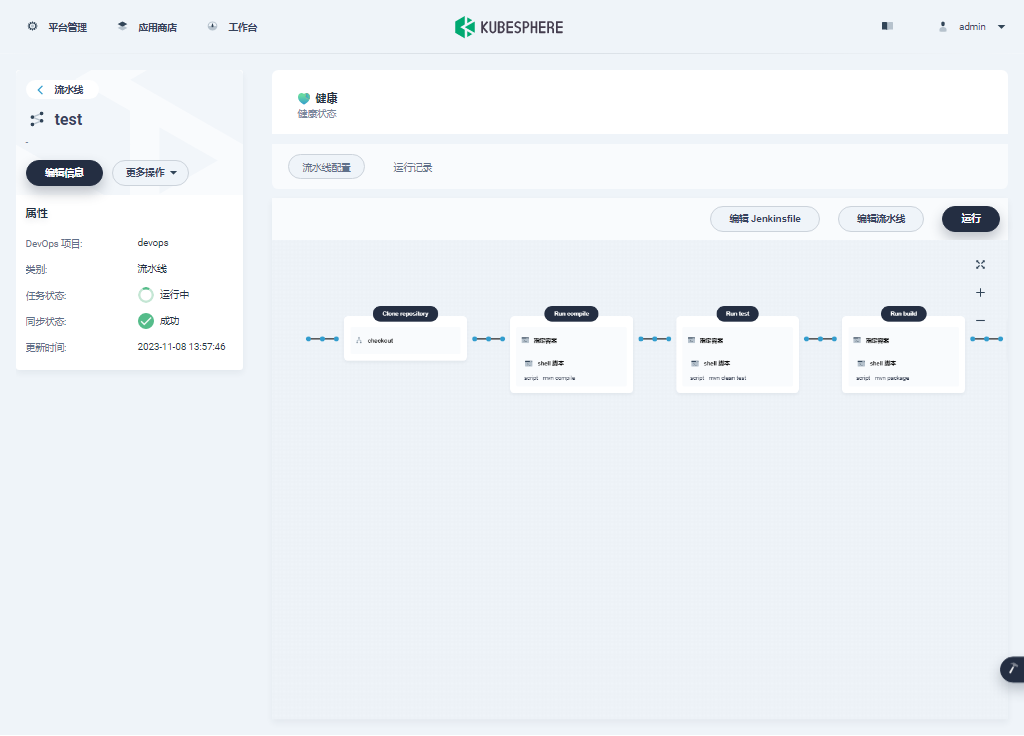
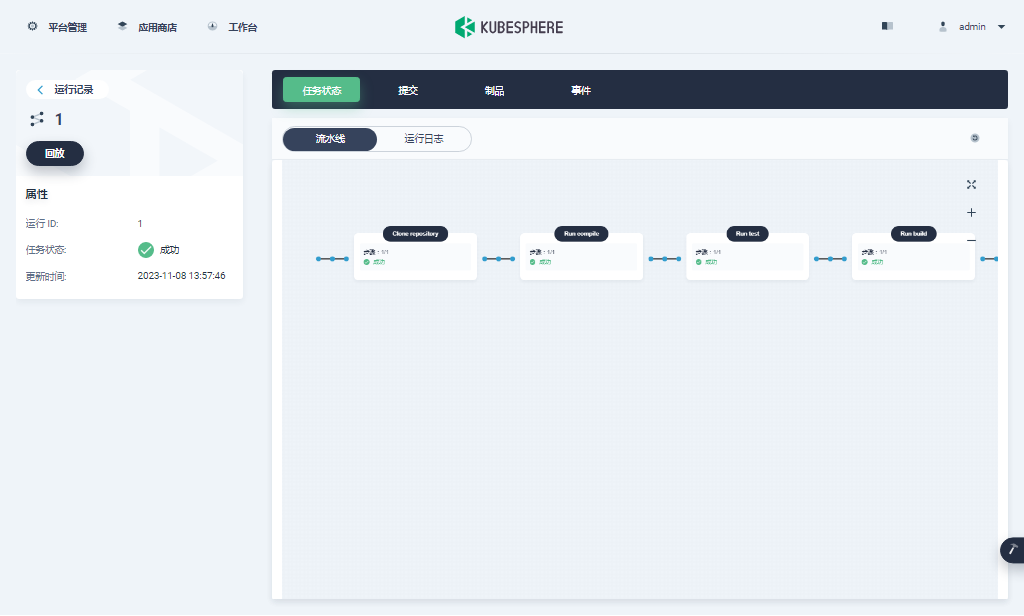
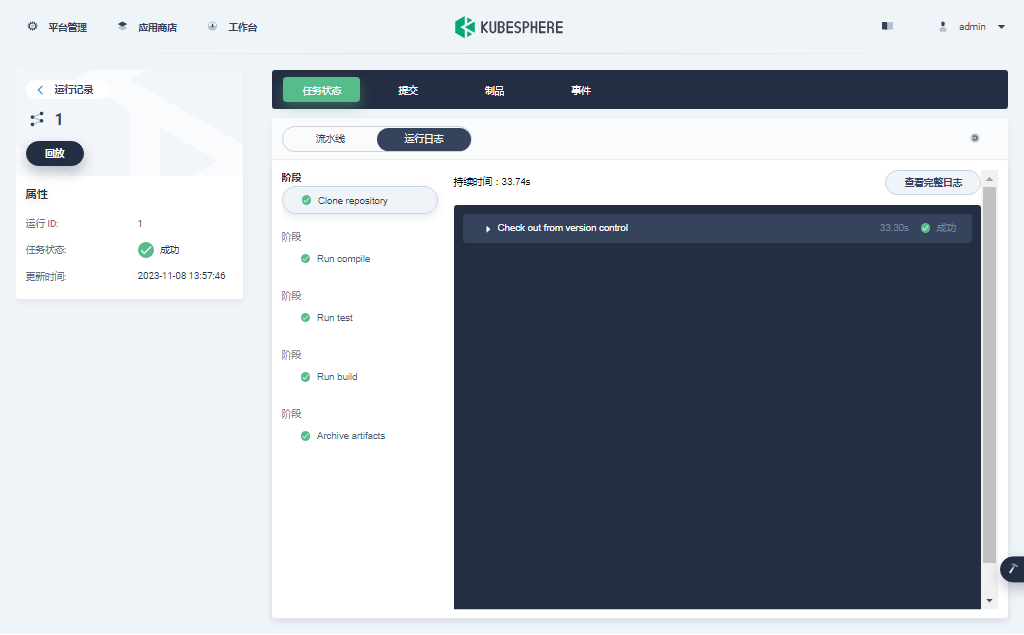
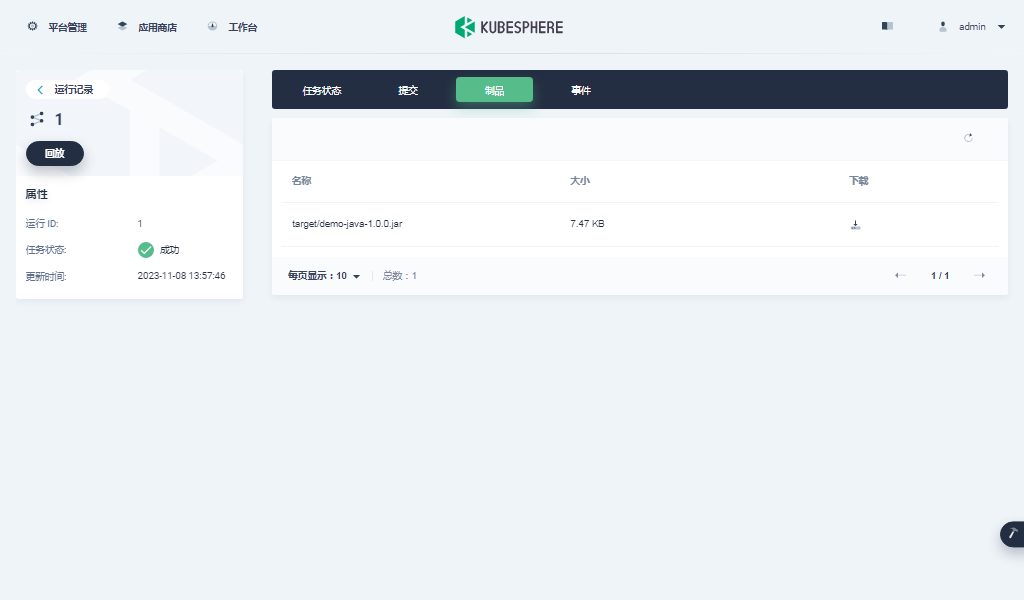
最后看一组监控图表来结束我们的图形验证。
- 概览
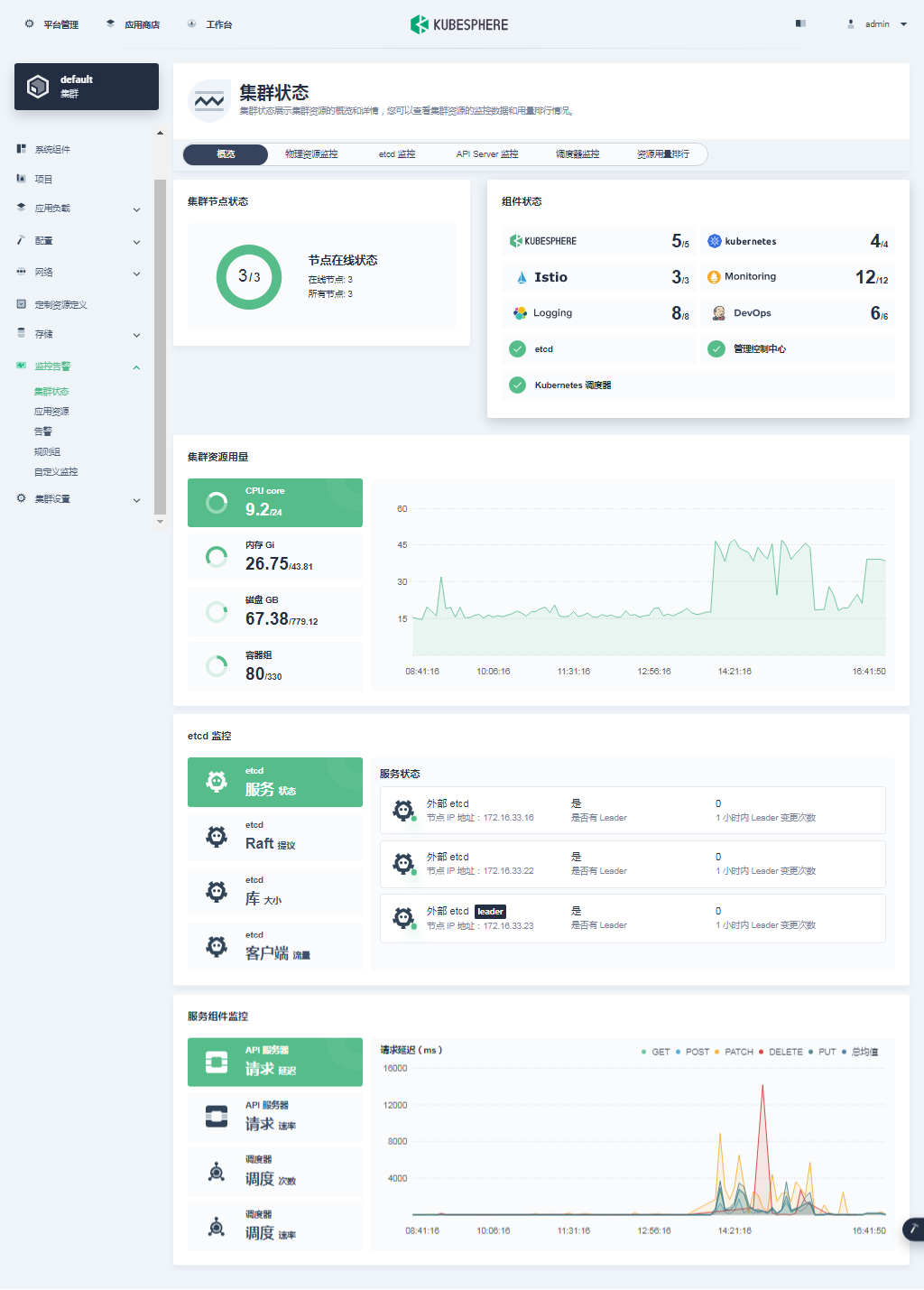
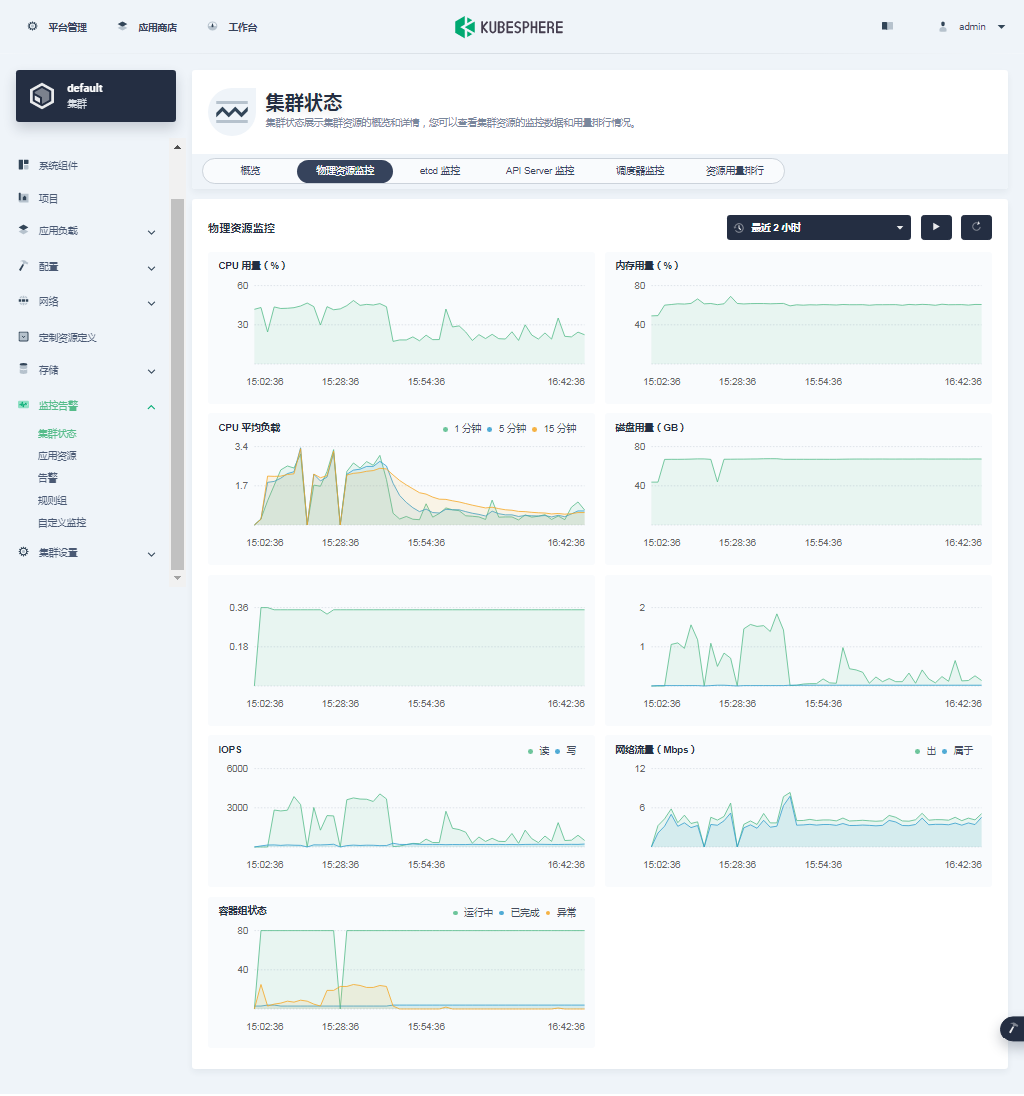
- 物理资源监控
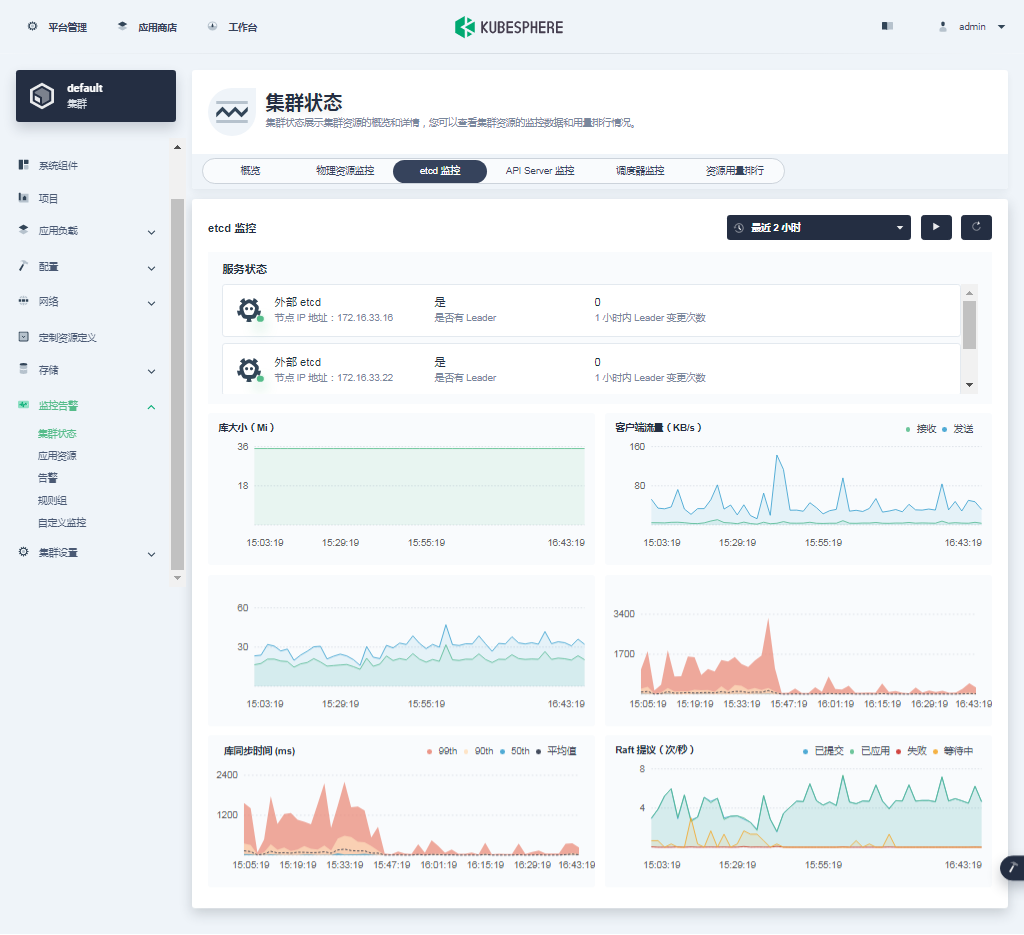
- etcd 监控
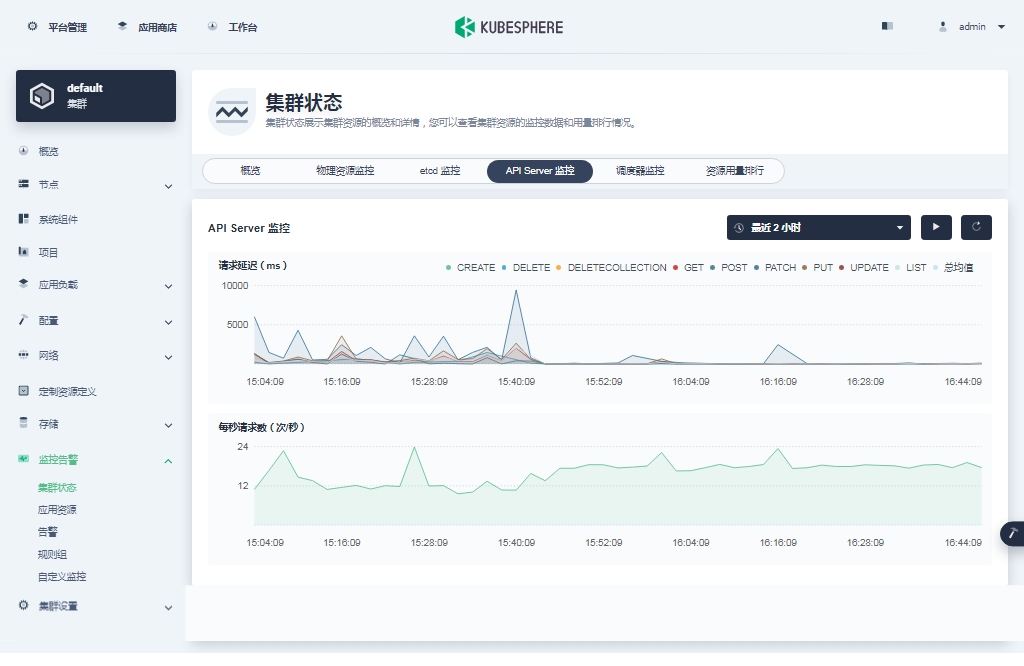
- API Server 监控
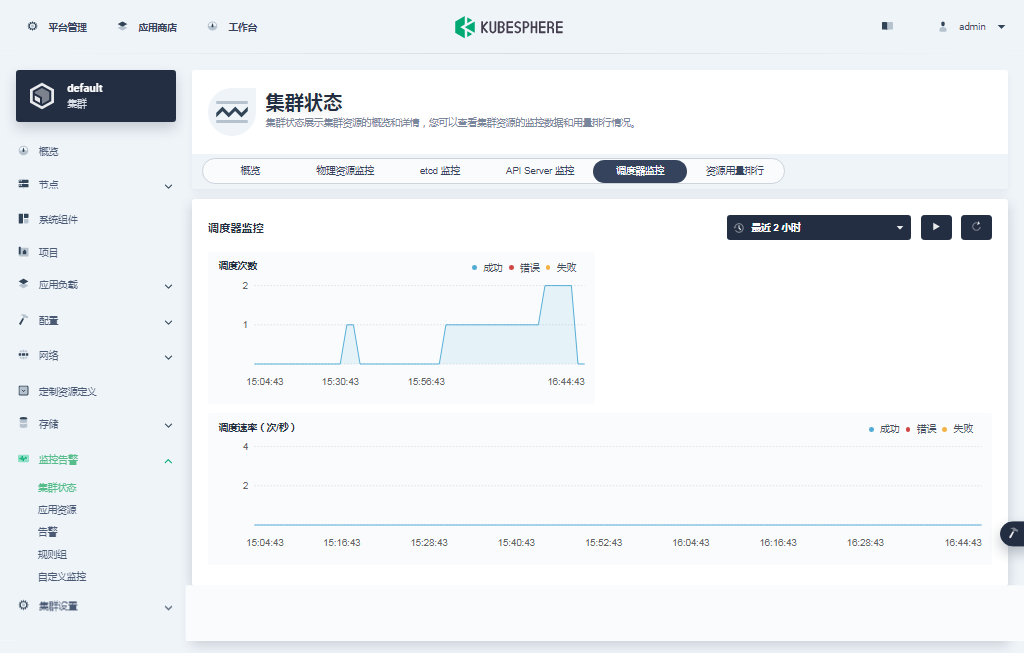
- 调度器监控
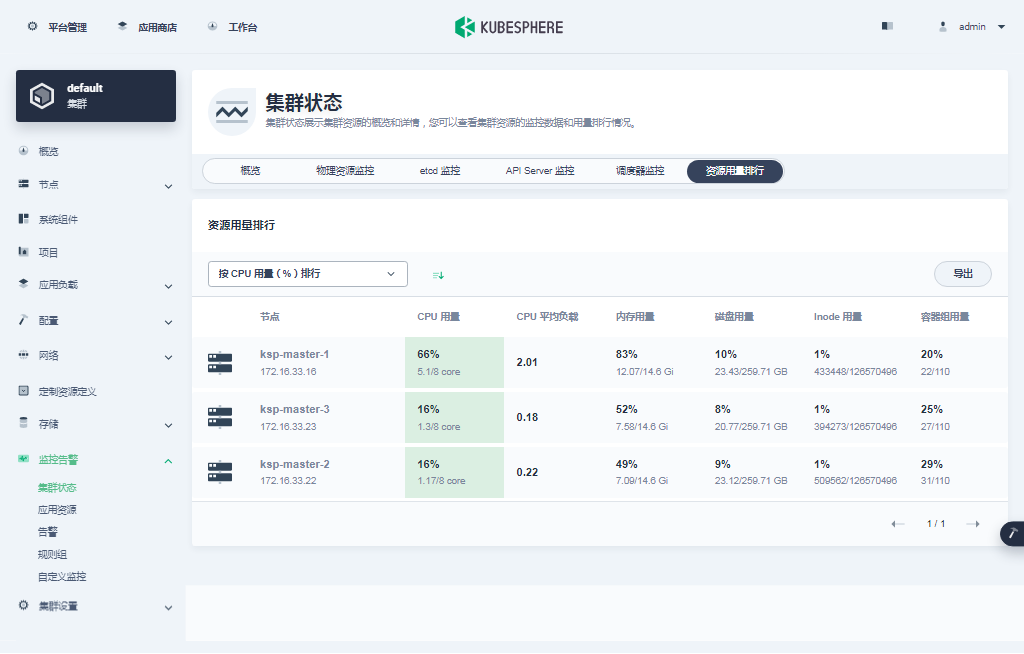
- 资源用量排行
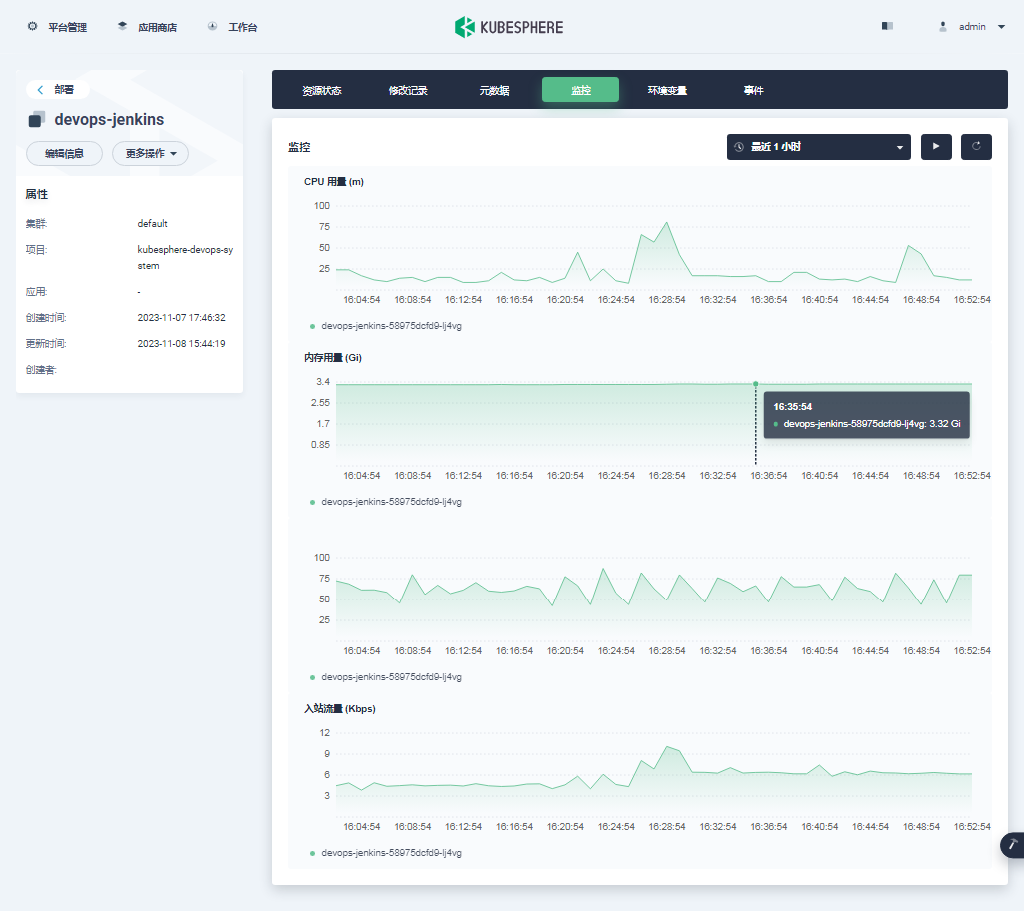
- Pod 监控
6.2 Kubectl 命令行验证集群状态
本小节只是简单的看了一下基本状态,并不全面,更多的细节需要大家自己体验探索。
- 查看集群节点信息
在 master-1 节点运行 kubectl 命令获取 Kubernetes 集群上的可用节点列表。
kubectl get nodes -o wide
在输出结果中可以看到,当前的 Kubernetes 集群有三个可用节点、节点的内部 IP、节点角色、节点的 Kubernetes 版本号、容器运行时及版本号、操作系统类型及内核版本等信息。
[root@ksp-master-1 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-master-1 Ready control-plane,worker 18h v1.26.5 172.16.33.16 <none> Kylin Linux Advanced Server V10 (Sword) 4.19.90-24.4.v2101.ky10.aarch64 containerd://1.6.4
ksp-master-2 Ready control-plane,worker 18h v1.26.5 172.16.33.22 <none> Kylin Linux Advanced Server V10 (Sword) 4.19.90-24.4.v2101.ky10.aarch64 containerd://1.6.4
ksp-master-3 Ready control-plane,worker 18h v1.26.5 172.16.33.23 <none> Kylin Linux Advanced Server V10 (Sword) 4.19.90-24.4.v2101.ky10.aarch64 containerd://1.6.4
- 查看 Pod 列表
输入以下命令获取在 Kubernetes 集群上运行的 Pod 列表,按工作负载在 NODE 上的分布排序。
# 默认按 NAMESPACE 排序
# 按节点排序
kubectl get pods -A -o wide --sort-by='.spec.nodeName'
在输出结果中可以看到, Kubernetes 集群上有多个可用的命名空间 kube-system、kubesphere-control-system、kubesphere-monitoring-system、kubesphere-system、argocd 和 istio-system 等,所有 pod 都在运行。
注意:
- 结果略,请自行查看或是参考上一篇基于 OpenEuler ARM 的部署文档
- 如果 Pod 状态不是 Running 请根据本文的第 5 小节「异常组件及解决方案」中的内容进行比对处理,文中未涉及的问题可以参考本文的解决思路自行解决。
- 查看 Image 列表
输入以下命令获取在 Kubernetes 集群节点上已经下载的 Image 列表。
crictl images ls
# 结果略,请自行查看或是参考上一篇基于 OpenEuler ARM 的部署文档
至此,我们已经完成了部署 3 台 服务器,复用为 Master 节点 和 Worker 节点的最小化的 Kubernetes 集群和 KubeSphere。我们还通过 KubeSphere 管理控制台和命令行界面查看了集群的状态。
接下来我们将在 Kubernetes 集群上部署一个简单的 Nginx Web 服务器,测试验证 Kubernetes 和 KubeSphere 基本功能是否正常。
7. 部署测试资源
本示例使用命令行工具在 Kubernetes 集群上部署一个 Nginx Web 服务器并利用 KubeSphere 图形化管理控制台查看部署的资源信息。
7.1 创建 Nginx Deployment
运行以下命令创建一个部署 Nginx Web 服务器的 Deployment。此示例中,我们将创建具有两个副本基于 nginx:alpine 镜像的 Pod。
kubectl create deployment nginx --image=nginx:alpine --replicas=2
7.2 创建 Nginx Service
创建一个新的 Kubernetes 服务,服务名称 nginx,服务类型 Nodeport,对外的服务端口 80。
kubectl create service nodeport nginx --tcp=80:80
7.3 验证 Nginx Deployment 和 Pod
- 运行以下命令查看创建的 Deployment 和 Pod 资源。
kubectl get deployment -o wide
kubectl get pods -o wide
- 查看结果如下:
[root@ksp-master-1 ~]# kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 2/2 2 2 26s nginx nginx:alpine app=nginx
[root@ksp-master-1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-6c557cc74d-bz6qd 1/1 Running 0 26s 10.233.84.73 ksp-master-1 <none> <none>
nginx-6c557cc74d-z2w9b 1/1 Running 0 26s 10.233.116.50 ksp-master-2 <none> <none>
7.4 验证 Nginx 镜像架构
- 运行以下命令查看 Nginx Image 的架构类型
crictl inspecti nginx:alpine | grep architecture
- 查看结果如下:
[root@ks-master-1 ~]# crictl inspecti nginx:alpine | grep architecture
"architecture": "arm64"
7.5 验证 Nginx Service
运行以下命令查看可用的服务列表,在列表中我们可以看到 nginx 服务类型 为 Nodeport,并在 Kubernetes 主机上开放了 30563 端口。
kubectl get svc -o wide
查看结果如下
[root@ksp-master-1 ~]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 19h <none>
nginx NodePort 10.233.62.164 <none> 80:30792/TCP 97s app=nginx
7.6 验证服务
运行以下命令访问部署的 Nginx 服务,验证服务是否成功部署。
- 验证直接访问 Pod
curl 10.233.84.73
- 验证访问 Service
curl 10.233.62.164
- 验证访问 Nodeport
curl 172.16.33.16:30792
7.7 在管理控制台查看
接下来我们回到 KubeSphere 管理控制台,在管理控制台查看已经创建的资源。
说明: KubeSphere 的管理控制台具有友好地、图形化创建 Kubernetes 各种资源的功能,主要是截图太麻烦了,所以本文采用了命令行的方式简单的创建了测试资源。
只是在查看的时候给大家演示一下 KubeSphere 管理控制台的基本功能,实际使用中,大家可以使用图形化方式创建和管理 Kubernetes 资源。
- 登录 KubeSphere 管理控制台,点击「平台管理」,选择「集群管理」。
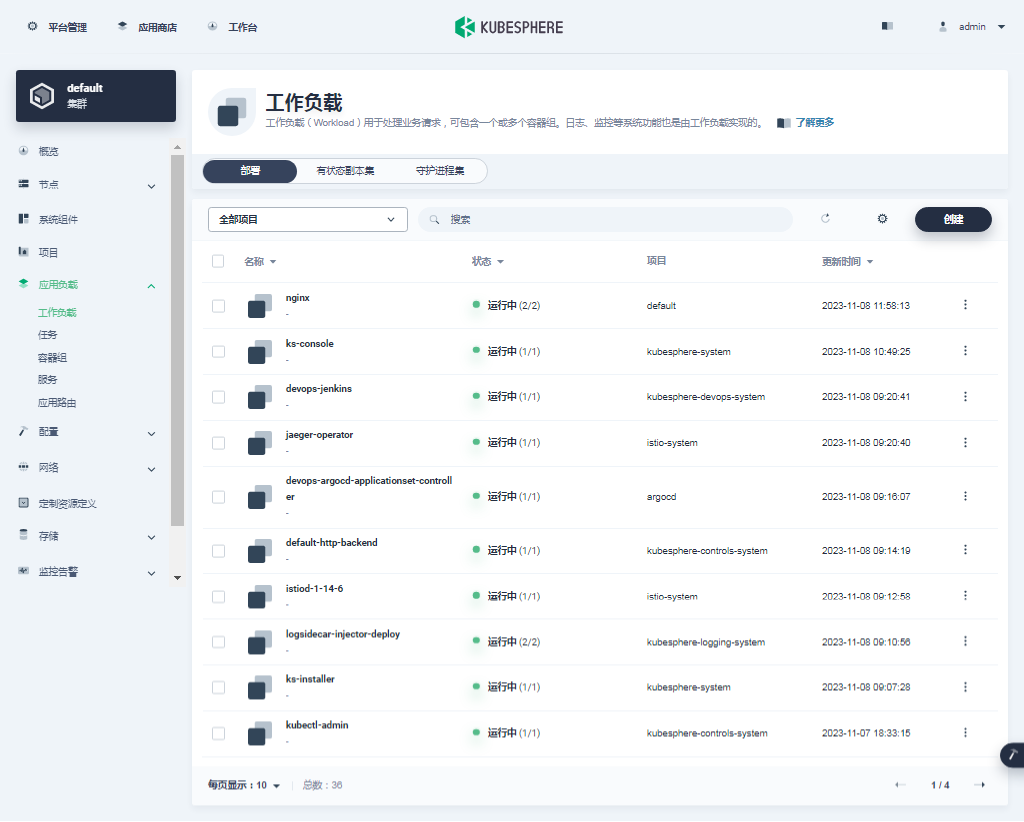
- 单击集群管理页面左侧的「应用负载」,点击「工作负载」。默认会看到所有类型为部署的工作负载。
我们使用的是 admin 账户,因此可以看到所有的工作负载,在搜索框输入 nginx,只显示 nginx 部署工作负载。
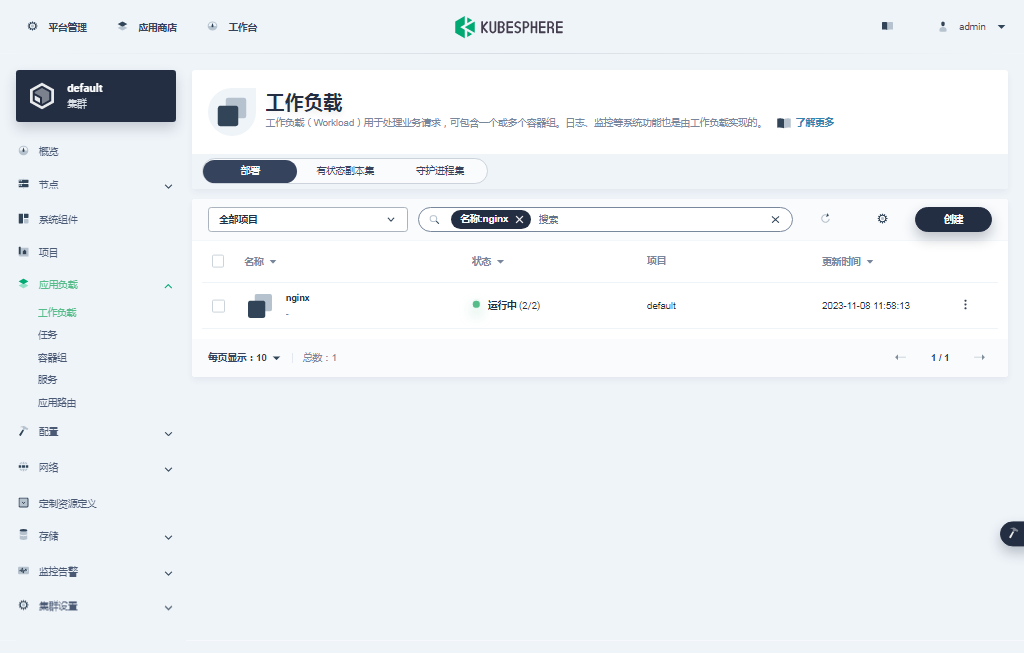
- 单击部署列表中的 nginx,可以查看更详细的信息,并且管理 nginx 部署 (Deployment)。
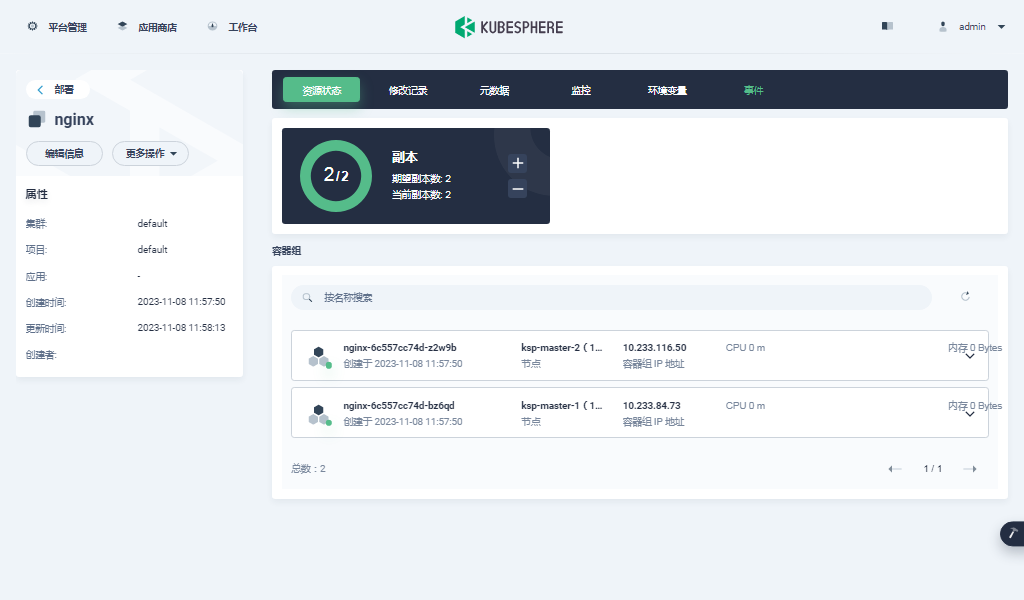
- 单击容器组中的一个 nginx 容器,可以查看容器的状态、监控等信息。
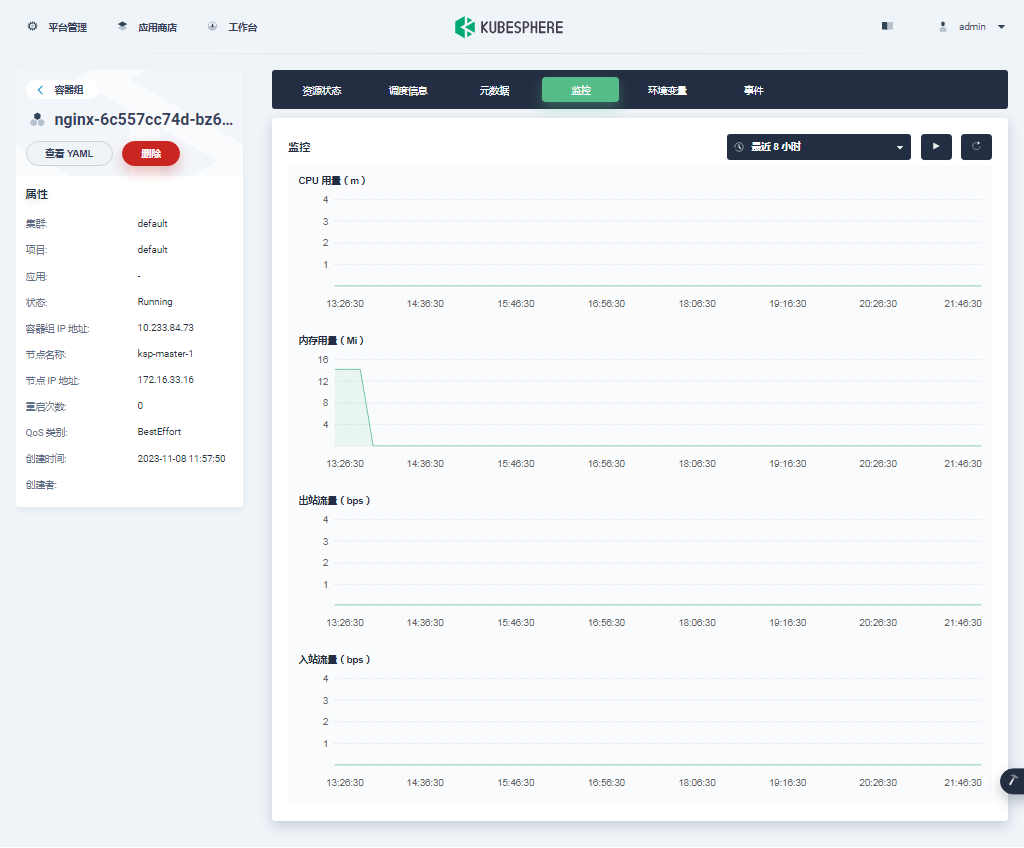
- 回到「平台管理」-「集群管理」页面,单击集群管理页面左侧的「应用负载」,点击「服务」。默认会看到所有类型为服务的工作负载。
我们使用的是 admin 账户,因此可以看到所有的工作负载,在搜索框输入 nginx,只显示 nginx 服务工作负载。
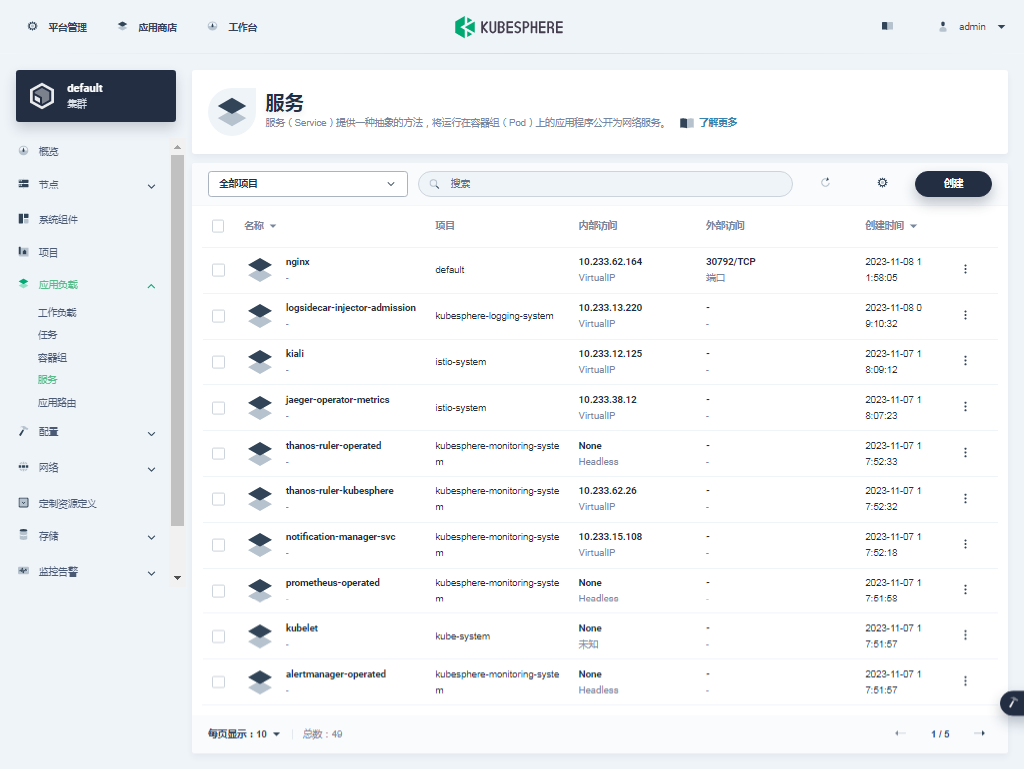
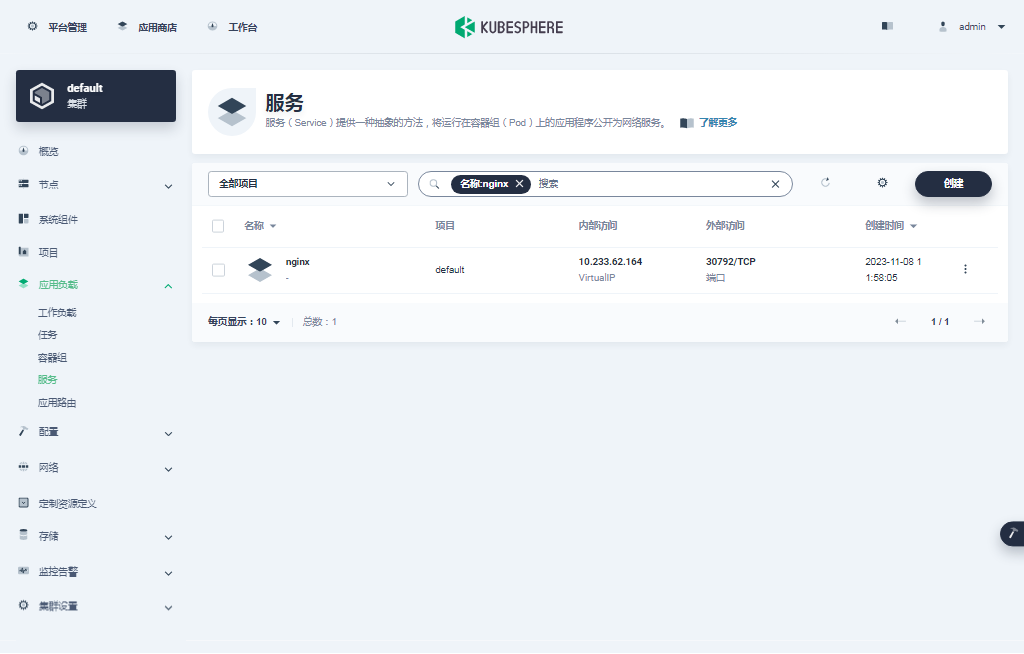
- 单击服务列表中的 nginx,可以查看更详细的信息,并且管理 nginx 服务 (Service)。
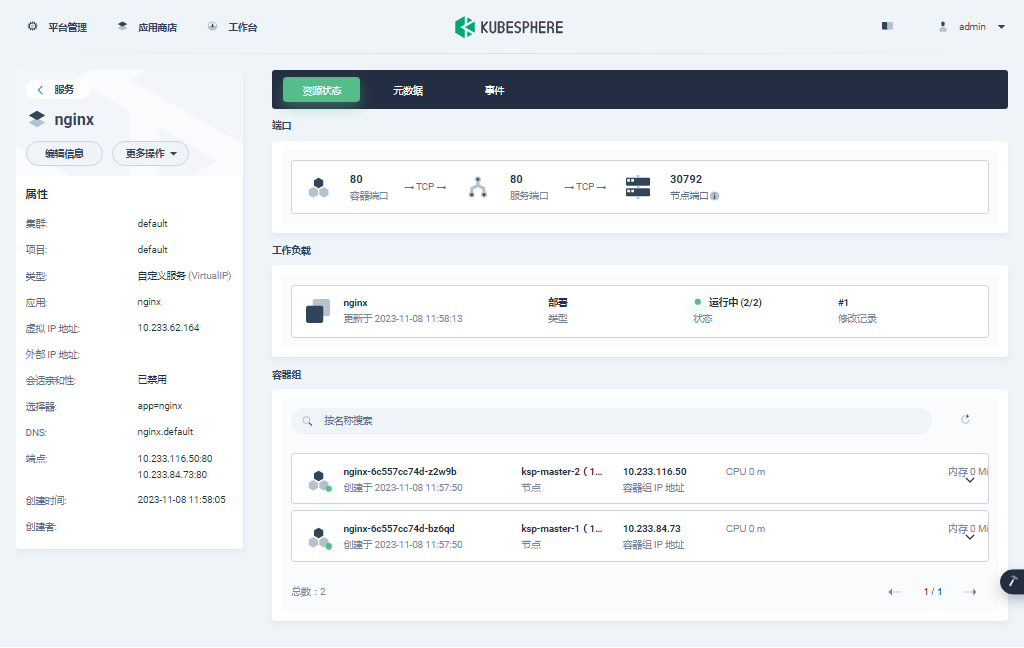
至此,我们实现了将 Nginx Web 服务器部署到 Kubernetes 集群,并通过 KubeSphere 管理控制台查看、验证了部署的 Deployment、Pod、Service 的详细信息。
本文仅对 ARM 架构下部署的 KubeSphere 和 Kubernetes 做了最基本的资源创建的验证测试,更多的完整的可插拔组件的测试并未涉及,请读者根据需求自己验证、测试。
在验证测试过程中遇到的问题多数都应该是镜像架构不匹配造成的,参考本文第 5 小节中解决问题的思路和流程,应该能解决大部分问题。
8. 常见问题
8.1 问题 1
- 问题现象
TASK [metrics-server : Metrics-Server | Waitting for metrics.k8s.io ready] *****
FAILED - RETRYING: Metrics-Server | Waitting for metrics.k8s.io ready (60 retries left).
FAILED - RETRYING: Metrics-Server | Waitting for metrics.k8s.io ready (59 retries left).
FAILED - RETRYING: Metrics-Server | Waitting for metrics.k8s.io ready (58 retries left).
......
fatal: [localhost]: FAILED! => {"attempts": 60, "changed": true, "cmd": "/usr/local/bin/kubectl get apiservice | grep metrics.k8s.io\n", "delta": "0:00:00.077617", "end": "2023-11-07 16:50:27.274329", "rc": 0, "start": "2023-11-07 16:50:27.196712", "stderr": "", "stderr_lines": [], "stdout": "v1beta1.metrics.k8s.io kube-system/metrics-server False (MissingEndpoints) 10m", "stdout_lines": ["v1beta1.metrics.k8s.io kube-system/metrics-server False (MissingEndpoints) 10m"]}
PLAY RECAP *********************************************************************
localhost : ok=6 changed=4 unreachable=0 failed=1 skipped=3 rescued=0 ignored=0
- 解决方案
# 解决 metrics-server 异常后,重启 ks-install pod
kubectl delete pod ks-installer-6674579f54-cgxpk -n kubesphere-system
8.2 问题 2
- 问题现象
# 登陆 console 提示
request to http://ks-apiserver/oauth/token failed, reason: getaddrinfo EAI_AGAIN ks-apiserver
# 检查 coredns pod 日志
kubectl logs coredns-d9d84b5bf-fmm64 -n kube-system
....
[ERROR] plugin/errors: 2 1393460958862612009.7706119398981012766.ip6.arpa. HINFO: read tcp 10.88.0.3:52062->114.114.114.114:53: i/o timeout
[ERROR] plugin/errors: 2 1393460958862612009.7706119398981012766.ip6.arpa. HINFO: read tcp 10.88.0.3:52086->114.114.114.114:53: i/o timeout
- 解决方案
# 销毁所有的 coredns pod,自动重建后恢复
kubectl delete pod coredns-d9d84b5bf-fmm64 -n kube-system
8.3 问题 3
- 问题现象
[root@ksp-master-1 kubekey]# kubectl get pod -A | grep -v Run
NAMESPACE NAME READY STATUS RESTARTS AGE
kubesphere-logging-system opensearch-logging-curator-opensearch-curator-28322940-zsvl5 0/1 Error 0 8h
[root@ksp-master-1 kubekey]# kubectl logs opensearch-logging-curator-opensearch-curator-28322940-zsvl5 -n kubesphere-logging-system
2023-11-07 17:00:52,595 INFO Preparing Action ID: 1, "delete_indices"
2023-11-07 17:00:52,595 INFO Creating client object and testing connection
2023-11-07 17:00:52,598 WARNING Use of "http_auth" is deprecated. Please use "username" and "password" instead.
2023-11-07 17:00:52,598 INFO kwargs = {'hosts': ['opensearch-cluster-data.kubesphere-logging-system.svc'], 'port': 9200, 'use_ssl': True, 'ssl_no_validate': True, 'http_auth': 'admin:admin', 'client_cert': None, 'client_key': None, 'aws_secret_key': None, 'ssl_show_warn': False, 'aws_key': None, 'url_prefix': '', 'certificate': None, 'aws_token': None, 'aws_sign_request': False, 'timeout': 30, 'connection_class': <class 'opensearchpy.connection.http_requests.RequestsHttpConnection'>, 'verify_certs': False, 'aws_region': False, 'api_key': None}
2023-11-07 17:00:52,598 INFO Instantiating client object
2023-11-07 17:00:52,598 INFO Testing client connectivity
2023-11-07 17:00:52,852 WARNING GET https://opensearch-cluster-data.kubesphere-logging-system.svc:9200/ [status:503 request:0.253s]
2023-11-07 17:00:52,856 WARNING GET https://opensearch-cluster-data.kubesphere-logging-system.svc:9200/ [status:503 request:0.004s]
2023-11-07 17:00:52,861 WARNING GET https://opensearch-cluster-data.kubesphere-logging-system.svc:9200/ [status:503 request:0.004s]
2023-11-07 17:00:52,865 WARNING GET https://opensearch-cluster-data.kubesphere-logging-system.svc:9200/ [status:503 request:0.003s]
2023-11-07 17:00:52,865 ERROR HTTP 503 error: OpenSearch Security not initialized.
2023-11-07 17:00:52,865 CRITICAL Curator cannot proceed. Exiting.
- 解决方案
没记录更多细节,最后结果是在 coreDNS 的 pod 重启后,自行修复了。
在出现异常 pod 的时候都可以通过多次销毁,等系统自动重建的方式修复。
8.4 问题 4
- 问题现象
验证日志,事件、审计日志时,发现没有数据,经排查发现是 fluent-bit pod 异常,日志中出现大量的如下错误(这个问题在 OpenEuler 上没有出现)。
2023-11-09T12:05:00.921862916+08:00 <jemalloc>: Unsupported system page size
2023-11-09T12:05:00.921866296+08:00 Error in GnuTLS initialization: ASN1 parser: Element was not found.
2023-11-09T12:05:00.921868756+08:00 <jemalloc>: Unsupported system page size
2023-11-09T12:05:00.921871256+08:00 <jemalloc>: Unsupported system page size
2023-11-09T12:05:00.921881196+08:00 <jemalloc>: Unsupported system page size
2023-11-09T12:05:00.921884556+08:00 malloc: Cannot allocate memory
2023-11-09T12:05:00.922208611+08:00 level=error msg="Fluent bit exited" error="exit status 1"
2023-11-09T12:05:00.922214631+08:00 level=info msg=backoff delay=-1s
2023-11-09T12:05:00.922228062+08:00 level=info msg="backoff timer done" actual=18.39µs expected=-1s
2023-11-09T12:05:00.922644408+08:00 level=info msg="Fluent bit started"
- 解决方案
# 一番搜索发现,fluent-bit jmalloc 调用 pagesize 大小问题引起的,导致 fluent-bit 不能正常工作
# https://github.com/jemalloc/jemalloc/issues/467
# arm 架构上面:
# 在 debian ubuntu 等操作系统,默认的 pagesize 是 4KB
# 但是在 centos rhel 系列,默认的 pagesize 是 64KB
# 银河麒麟 v10的 太大,导致 fluent-bit 不能正常工作
# 查看 麒麟 V10 PAGESIZE 设置
[root@ksp-master-2 ~]# getconf PAGESIZE
65536
## 解决方案:换个版本,v1.9.9 经测试不可用,最终选择 v2.0.6
# 删除 amd64 镜像并重打 Tag(受限于 fluentbit-operator,会自动变更任何手改的配置,就不改 deployment 的配置了)
crictl pull kubesphere/fluent-bit:v2.0.6 --platform arm64
crictl rmi registry.cn-beijing.aliyuncs.com/kubesphereio/fluent-bit:v1.9.4
ctr -n k8s.io images tag --force docker.io/kubesphere/fluent-bit:v2.0.6 registry.cn-beijing.aliyuncs.com/kubesphereio/fluent-bit:v1.9.4
# 销毁 pod 重建(每个节点的都要销毁)
kubectl delete pod fluent-bit-l5lx4 -n kubesphere-logging-system
9. 总结
本文主要实战演示了在 ARM 版麒麟 V10 SP2 服务器上,利用 KubeKey v3.0.13 自动化部署最小化 KubeSphere 3.4.0 和 Kubernetes 1.26.5 高可用集群的详细过程。
部署完成后,我们还利用 KubeSphere 管理控制台和 kubectl 命令行,查看并验证了 KubeSphere 和 Kubernetes 集群的状态。
最终我们通过在 Kubenetes 集群上部署 Nginx Web 服务器验证了 Kubernetes 集群和 KubeSphere 的可用性,并通过在 KubeSphere 管理控制台查看 Nginx Pod 和服务状态的操作,了解了 KubeSphere 的基本用法。
概括总结全文主要涉及以下内容:
- 麒麟 V10 SP2 aarch64 操作系统基础配置
- 操作系统数据盘 LVM 配置、磁盘挂载、数据目录创建
- KubeKey 下载及创建集群配置文件
- 利用 KubeKey 自动化部署 KubeSphere 和 Kubernetes 集群
- 解决 ARM 版 KubeSphere 和 Kubernetes 服务组件异常的问题
- 部署完成后的 KubeSphere 和 Kubernetes 集群状态验证
- 部署 Nginx 验证测试 KubeSphere 和 Kubernetes 基本功能
本文的核心价值在于,重点介绍了在 KubeSphere 和 Kubernetes 集群部署过程中遇到的常见问题及对应的解决方案。同时,指出了在麒麟 V10 和 openEuler 22.03 两种不同操作系统上遇到的不同的问题。
本文部署环境虽然是基于 Kunpeng-920 芯片的 aarch64 版 麒麟 V10 SP2,但是对于 CentOS、openEuler 等 ARM 版操作系统以及飞腾(FT-2500)等芯片也有一定的借鉴意义。
本文介绍的内容可直接用于研发、测试环境,对于生产环境有一定的参考意义,绝对不能直接用于生产环境。
本文的不完全测试结论: KubeSphere 和 Kubernetes 基本功能可用,DevOps 功能可用,已经能满足大部分的普通业务场景。
本文由博客一文多发平台 OpenWrite 发布!