一、选题背景
随着互联网的快速发展和信息化时代的到来,招聘网站成为求职者和招聘公司之间最重要的信息交流平台之一。招聘网站上聚集了大量的职位信息、薪资数据和公司信息,这些数据蕴含着丰富的招聘市场和就业趋势的信息,对求职者和招聘公司都具有重要的参考价值。然而,由于招聘网站上的数据量庞大且复杂,求职者和招聘公司往往难以直观地获取和分析这些数据,从而导致他们在职业决策和招聘策略制定中缺乏准确的信息支持。因此,开发一个基于Python的招聘网站数据分析与可视化系统,能够高效地收集、处理、分析和展示招聘网站的数据,对用户进行数据驱动的决策提供有力支持。
二、设计方案
系统应提供多种数据分析和统计功能,如薪资水平分析、职位需求分析、地域分布分析等,以帮助用户了解招聘市场状况和就业趋势。
用户应能够根据自定义的查询条件进行数据筛选和分析,以获取特定职位、行业或地区的数据分析结果。
系统应能够将数据分析结果以图表、图像等形式进行可视化展示,以增强数据的易读性和可理解性。
三、系统分析
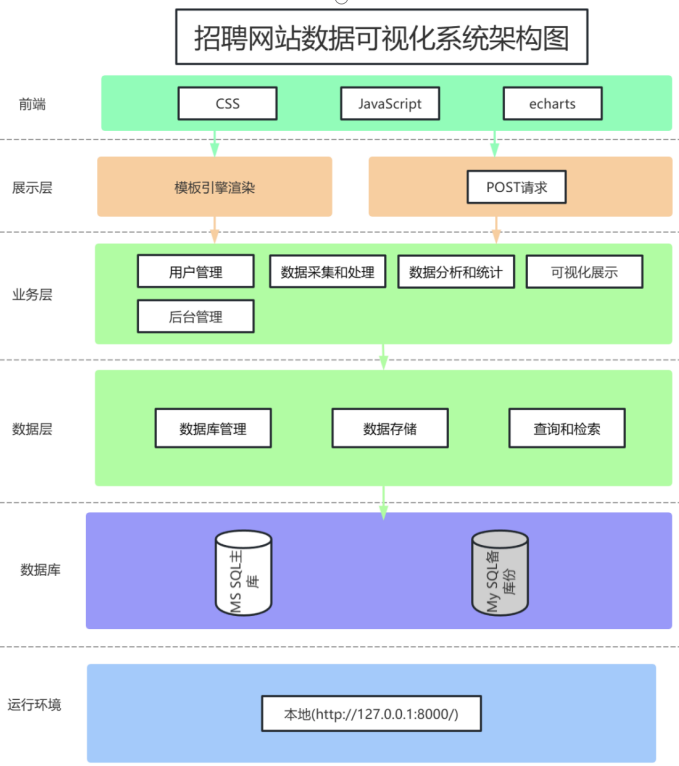
四、系统实现
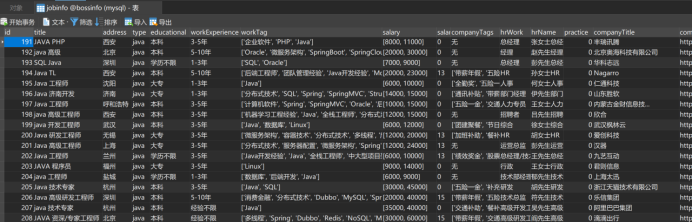
数据爬取
主要代码
def main(self, page):
if self.page > page:
return
brower = self.startBrower()
print("正在爬取的页面路径:" + self.spiderUrl % (self.type, self.page))
brower.get(self.spiderUrl % (self.type, self.page))
time.sleep(8)
job_list = brower.find_elements(by=By.XPATH, value='//ul[@class="job-list-box"]/li')
for index, job in enumerate(job_list):
try:
jobData = []
print("正在爬取第%d个数据" % (index + 1))
# title
title = job.find_element(by=By.XPATH,
value=".//a[@class='job-card-left']/div[contains(@class,'job-title')]/span[@class='job-name']").text
# address
addresses = job.find_element(by=By.XPATH,
value=".//a[@class='job-card-left']/div[contains(@class,'job-title')]/span[@class='job-area-wrapper']/span[@class='job-area']").text.split(
"·")
address = addresses[0]
if len(addresses) != 1:
dist = addresses[1]
else:
dist = ''
这部分是使用Selenium库进行网页元素定位,通过XPath定位到具有特定属性和标签的元素,并获取该元素的文本内容,进行数据清洗后存储在title、address等变量中,最后存入定义好的models模型中。
数据展示
主要代码
def getUserCreateTime():
users = getAllUsers()
data = {}
for u in users:
if data.get(str(u.createTime)) is None or data.get(str(u.createTime)) == 0:
data[str(u.createTime)] = 1
else:
data[str(u.createTime)] += 1
data = dict(sorted(data.items(), key=lambda x: x[0], reverse=True))
result = []
for k, v in data.items():
result.append({
'name': k[0:10],
'value': v
})
return result[0:4]
def getUserTop6():
users = getAllUsers()
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
users = list(sorted(users, key=sort_fn, reverse=True))[:6]
return users
def getAllTags():
jobs = JobInfo.objects.all()
users = User.objects.all()
educationTop = '学历不限'
salaryTop = 0
salaryMonthTop = 0
address = {}
practice = {}
for job in jobs:
if educations[job.educational] < educations[educationTop]:
educationTop = job.educational
if job.practice == 0:
salary = json.loads(job.salary)[1]
if salaryTop < salary:
salaryTop = salary
if int(job.salaryMonth) > salaryMonthTop:
salaryMonthTop = int(job.salaryMonth)
if address.get(job.address, -1) == -1:
address[job.address] = 1
else:
address[job.address] += 1
if practice.get(job.practice, -1) == -1:
practice[job.practice] = 1
else:
practice[job.practice] += 1
addressStr = sorted(address.items(), key=lambda x: x[1], reverse=True)[:3]
addressTop = ''
practiceMax = sorted(practice.items(), key=lambda x: x[1], reverse=True)
for index, item in enumerate(addressStr):
if index == len(addressStr) - 1:
addressTop += item[0]
else:
addressTop += item[0] + ','
return len(jobs), len(users), educationTop, salaryTop, salaryMonthTop, addressTop, practiceMax[0][0]
def getJobInfoDate():
jobs = getAlljobs()
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
jobs = list(sorted(jobs, key=sort_fn, reverse=False)) # 按爬取时间排序
def getDailyData():
job_infos = getAlljobs()
data = collections.defaultdict(lambda: collections.defaultdict(int))
for job_info in job_infos:
type_ = job_info.type
create_time_str = job_info.createTime
create_time = datetime.datetime.strptime(create_time_str, '%Y-%m-%d')
data[create_time][type_] += 1
sorted_dates = sorted(data.keys(), reverse=True)[:5]
result = []
for create_time in sorted_dates:
count_dict = data[create_time]
data_list = [{'name': type_, 'quantity': count} for type_, count in count_dict.items()]
result.append({
'date': create_time.strftime('%Y-%m-%d'),
'data': data_list
})
json_str = json.dumps(result, ensure_ascii=False)
return json_str
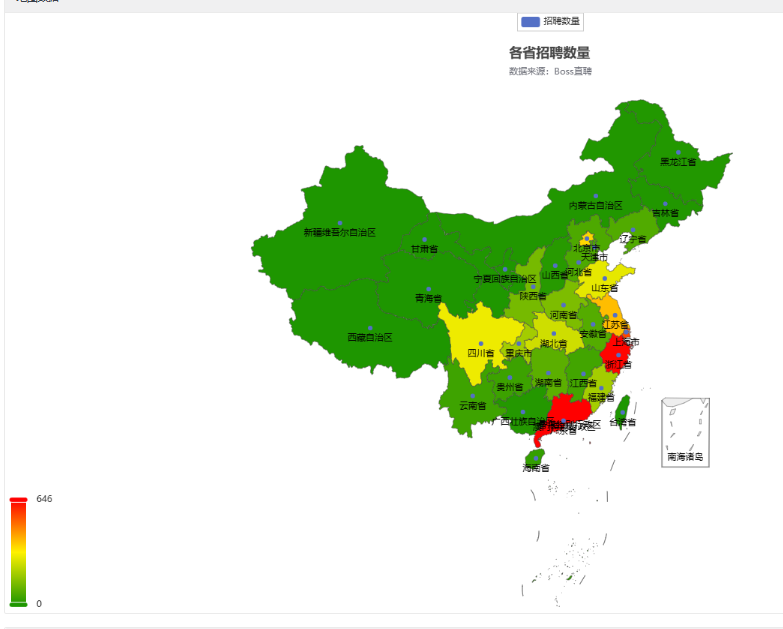
数据展示
关键代码
def getMapData():
mData, maxData, minData = getMapProvinceData()
data = [(k, v) for k, v in mData.items()]
map_ = Map(init_opts=opts.InitOpts(height="800px", width="1455px"))
map_.add(
series_name='招聘数量',
data_pair=data,
maptype='china',
zoom=1.2
)
map_.set_global_opts(
title_opts=opts.TitleOpts(
title='各省招聘数量',
subtitle='数据来源:Boss直聘',
pos_right='center',
pos_top='5%'
),
visualmap_opts=opts.VisualMapOpts(
max_=maxData,
min_=min,
range_color=['#1E9600', '#FFF200', '#FF0000']
),
)
return map_.render_embed()
def getNewWork(work):
jobs = getAlljobsByWork(work)
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
jobs = list(sorted(jobs, key=sort_fn, reverse=True))[:20]
return jobs
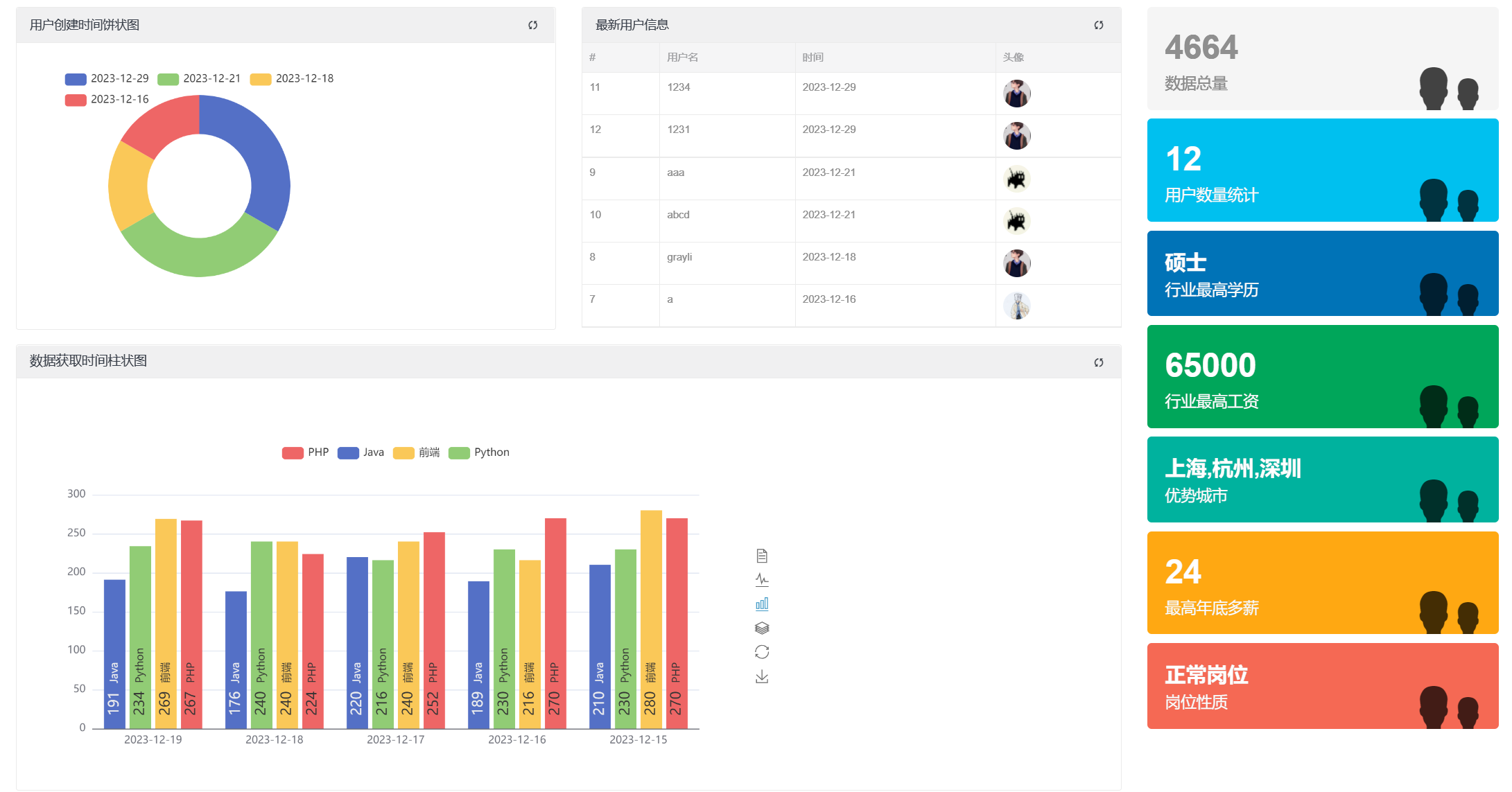
所示为用户创建时间饼状图、最新用户信息、数据获取时间柱状图和数据总结的具体实现代码。从数据库中出取出数据,将数据转为Echarts所要的格式后传给前端HTML。
getUserCreateTime函数的功能是获取用户创建时间的统计信息,并返回包含名称和对应值的字典列表,其中仅包含前4个统计结果。
getUserTop6函数的功能是获取用户列表中创建时间最近的6个用户,并返回这些用户的列表。
getAllTags函数的功能是统计用户对象的数量、职位信息对象的数量、教育要求的最高等级、最高薪资、最高年底奖金、出现频率最高的三个地址、出现频率最高的实习类型。
getJobInfoDate函数的功能是获取职位信息列表,并按照爬取时间进行升序排序后返回。
getDailyData函数的功能是获取每天不同类型职位信息的数量统计,并将统计结果按日期格式化为JSON字符串。每个日期包含了对应的数据列表,其中每个数据项包含类型名称和对应的数量。
getMapData函数的功能是根据各省的招聘数量信息生成中国地图,并设置相应的标题和可视化映射选项。最终返回生成的地图的嵌入代码。
getNewWork函数的功能是获取与指定职位类型或工作领域相关的最新的20条职位信息。
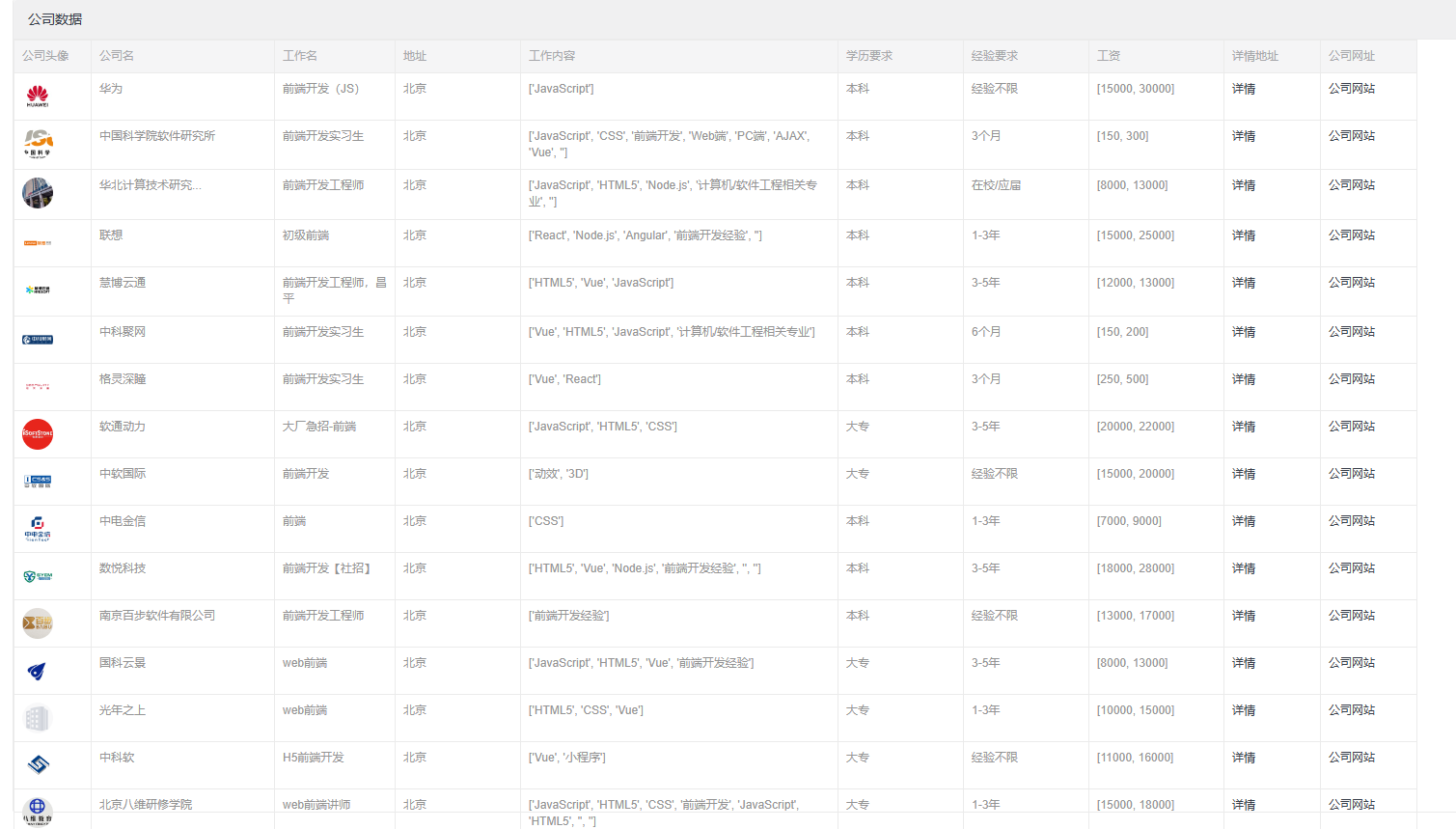
展示了数据库中的所有工作信息
关键代码
def getTableData():
jobs = getAlljobs()
for job in jobs:
salary = job.salary.split(',')
people = job.companyPeople.split(',')
job.salary = salary[0][1:] + '-' + salary[1][0:-1] + '元/月'
job.companyPeople = people[0][1:] + '-' + people[1][0:-1] + '人'
job.workTag = eval(job.workTag)
if job.companyTags != '无':
job.companyTags = eval(job.companyTags)
return jobs
获取数据库中的所有工作信息,然后进行数据格式化后,传给前端HTML。
getTableData函数的功能是获取所有职位信息的列表,并对其中的薪资、公司规模和工作标签等信息进行处理和更新后返回给前端进行显示。
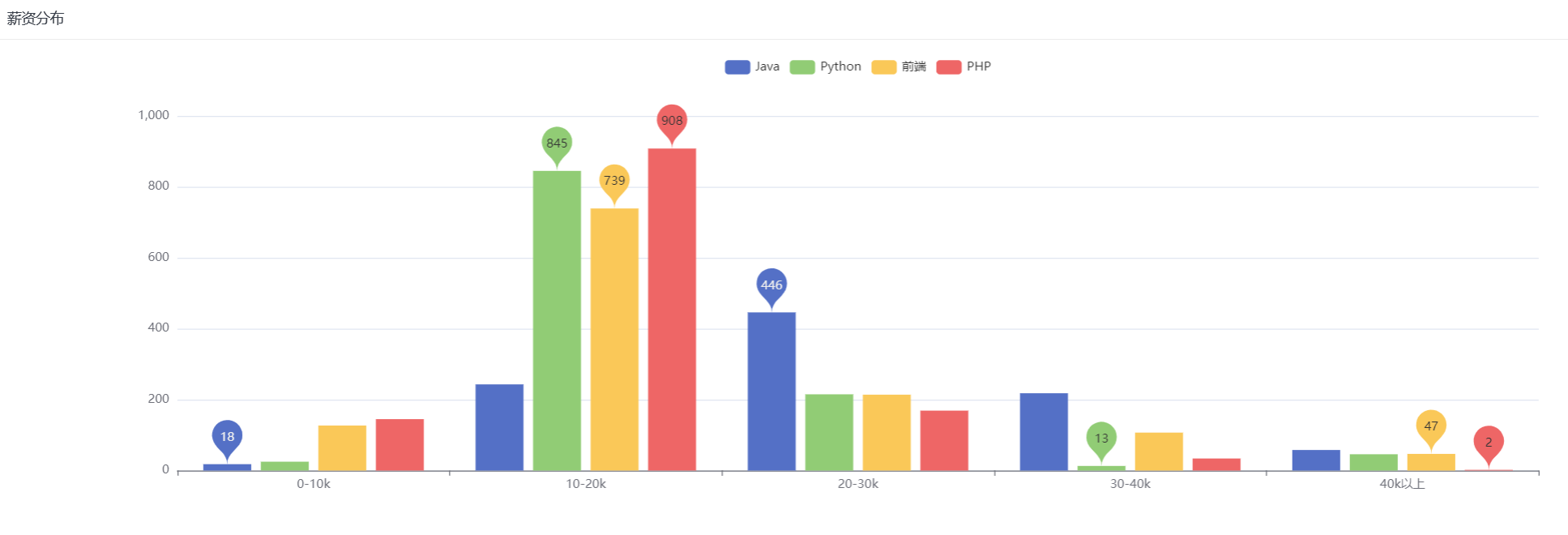
展示了各个工作方向的薪资分布区间
关键代码
def getBarData():
jobs = getAlljobs()
jobsTypes = {}
for j in jobs:
if j.practice == 0:
if jobsTypes.get(j.type, -1) == -1:
jobsTypes[j.type] = [json.loads(j.salary)[1]]
else:
jobsTypes[j.type].append(json.loads(j.salary)[1])
barData = {}
for k, v in jobsTypes.items():
if not barData.get(k, 0):
barData[k] = [0 for x in range(5)]
for i in v:
s = i / 1000
if s < 10:
barData[k][0] += 1
elif 10 <= s < 20:
barData[k][1] += 1
elif 20 <= s < 30:
barData[k][2] += 1
elif 30 <= s < 40:
barData[k][3] += 1
else:
barData[k][4] += 1
legends = list(barData.keys())
if len(legends) == 0:
legends = None
return salaryList, barData, legends
getBarData函数的功能是获取所有职位信息的列表,并对其中的薪资、公司规模和工作标签等信息进行处理和更新后返回给前端Echarts后,生成图表。
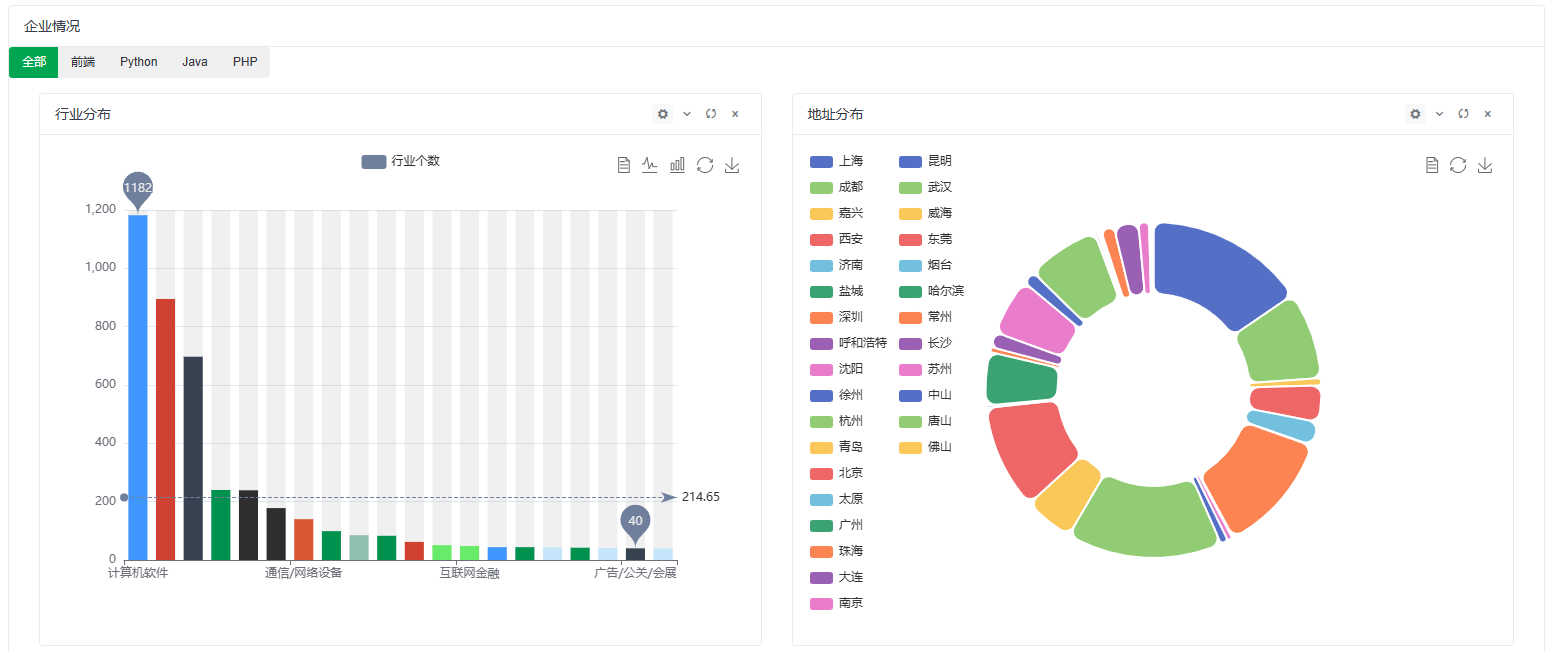
展示了企业所在的行业情况和地址分布情况。
关键代码
if type == 'all':
jobs = JobInfo.objects.all()
else:
jobs = JobInfo.objects.filter(type=type)
natureData = {}
for i in jobs:
if natureData.get(i.companyNature, -1) == -1:
natureData[i.companyNature] = 1
else:
natureData[i.companyNature] += 1
natureList = list(sorted(natureData.items(), key=lambda x: x[1], reverse=True))
rowData = []
columnData = []
for k, v in natureList:
rowData.append(k)
columnData.append(v)
return rowData[:20], columnData[:20]
def getCompanyPie(type):
if type == 'all':
jobs = JobInfo.objects.all()
else:
jobs = JobInfo.objects.filter(type=type)
addressData = {}
for i in jobs:
if addressData.get(i.address, -1) == -1:
addressData[i.address] = 1
else:
addressData[i.address] += 1
result = []
for k, v in addressData.items():
result.append({
'name': k,
'value': v
})
return result[:30]
获取数据库中的所有工作信息,然后进行数据格式化后,传给前端HTML
getCompanyBar函数的功能是获取指定职位类型或工作领域下的公司性质信息,并生成柱状图所需的行数据和列数据,返回柱状图的行数据列表和列数据列表的前20个元素。
getCompanyPie函数的功能是获取指定职位类型或工作领域下的公司地址信息,并生成饼图所需的数据,返回一个包含公司地址和计数的字典列表的前30个元素。

展示了所有工作信息中的公司福利词云和公司标题词云
关键代码
def get_img(field, targerImageSre, resImageSrc):
con = connect(host="localhost", user='root', password='root', database='bossinfo', port=3306, charset='utf8mb4')
cursor = con.cursor()
sql = f"select {field} from jobinfo"
cursor.execute(sql)
data = cursor.fetchall()
text = ''
cnt = 0
for i in data:
text += i[0]
# if i[0] != '无':
# for j in eval(i[0]):
# text += j
cursor.close()
con.close()
data_cut = jieba.cut(text, cut_all=False)
stop_words = []
with open('./stopwords.txt', 'r', encoding='utf8') as rf:
for line in rf:
if len(line) > 0:
stop_words.append(line.split())
data_result = [x for x in data_cut if x not in stop_words]
string = ' '.join(data_result)
img = Image.open(targerImageSre)
img_arr = np.array(img)
wc = WordCloud(
background_color='white',
mask=img_arr,
font_path='STHUPO.TTF'
)
wc.generate_from_text(string)
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off')
plt.savefig(resImageSrc, dpi=800)
get_img('title', '../static/backgroundImg2.png', '../static/title_cloud.png')
制作词云的关键代码,get_img函数的功能是从数据库中指定字段的文本内容中生成词云图,并将生成的词云图保存到指定的路径。
完整代码如下:
#getHomeDate
import time
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.globals import CurrentConfig, NotebookType
from .getPublicData import *
import datetime
import collections
import json
CurrentConfig.NOTEBOOK_TYPE = NotebookType.NTERACT
def getNowDate():
timeFormat = time.localtime()
year = timeFormat.tm_year
month = timeFormat.tm_mon
day = timeFormat.tm_mday
return year, monthList[month - 1], day
def getUserCreateTime():
users = getAllUsers()
data = {}
for u in users:
if data.get(str(u.createTime)) is None or data.get(str(u.createTime)) == 0:
data[str(u.createTime)] = 1
else:
data[str(u.createTime)] += 1
data = dict(sorted(data.items(), key=lambda x: x[0], reverse=True))
result = []
for k, v in data.items():
result.append({
'name': k[0:10],
'value': v
})
return result[0:4]
def getUserTop6():
users = getAllUsers()
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
users = list(sorted(users, key=sort_fn, reverse=True))[:6]
return users
def getAllTags():
jobs = JobInfo.objects.all()
users = User.objects.all()
educationTop = '学历不限'
salaryTop = 0
salaryMonthTop = 0
address = {}
practice = {}
for job in jobs:
if educations[job.educational] < educations[educationTop]:
educationTop = job.educational
if job.practice == 0:
salary = json.loads(job.salary)[1]
if salaryTop < salary:
salaryTop = salary
if int(job.salaryMonth) > salaryMonthTop:
salaryMonthTop = int(job.salaryMonth)
if address.get(job.address, -1) == -1:
address[job.address] = 1
else:
address[job.address] += 1
if practice.get(job.practice, -1) == -1:
practice[job.practice] = 1
else:
practice[job.practice] += 1
addressStr = sorted(address.items(), key=lambda x: x[1], reverse=True)[:3]
addressTop = ''
practiceMax = sorted(practice.items(), key=lambda x: x[1], reverse=True)
for index, item in enumerate(addressStr):
if index == len(addressStr) - 1:
addressTop += item[0]
else:
addressTop += item[0] + ','
return len(jobs), len(users), educationTop, salaryTop, salaryMonthTop, addressTop, practiceMax[0][0]
def getJobInfoDate():
jobs = getAlljobs()
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
jobs = list(sorted(jobs, key=sort_fn, reverse=False)) # 按爬取时间排序
def getDailyData():
job_infos = getAlljobs()
data = collections.defaultdict(lambda: collections.defaultdict(int))
for job_info in job_infos:
type_ = job_info.type
create_time_str = job_info.createTime
create_time = datetime.datetime.strptime(create_time_str, '%Y-%m-%d')
data[create_time][type_] += 1
sorted_dates = sorted(data.keys(), reverse=True)[:5]
result = []
for create_time in sorted_dates:
count_dict = data[create_time]
data_list = [{'name': type_, 'quantity': count} for type_, count in count_dict.items()]
result.append({
'date': create_time.strftime('%Y-%m-%d'),
'data': data_list
})
json_str = json.dumps(result, ensure_ascii=False)
return json_str
def getMapData():
mData, maxData, minData = getMapProvinceData()
data = [(k, v) for k, v in mData.items()]
map_ = Map(init_opts=opts.InitOpts(height="800px", width="1455px"))
map_.add(
series_name='招聘数量',
data_pair=data,
maptype='china',
zoom=1.2
)
map_.set_global_opts(
title_opts=opts.TitleOpts(
title='各省招聘数量',
subtitle='数据来源:Boss直聘',
pos_right='center',
pos_top='5%'
),
visualmap_opts=opts.VisualMapOpts(
max_=maxData,
min_=min,
range_color=['#1E9600', '#FFF200', '#FF0000']
),
)
return map_.render_embed()
def getNewWork(work):
jobs = getAlljobsByWork(work)
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
jobs = list(sorted(jobs, key=sort_fn, reverse=True))[:20]
return jobs
#getPublicData
from RecruitDataWeb.models import *
import pandas as pd
import requests
import json
from django.db import connection
monthList = ['January', 'Fabric', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November',
'December']
educations = {'博士': 1, '硕士': 2, '本科': 3, '大专': 4, '高中': 5, '中专': 6, '中专/中技': 6, '初中及以下': 7,
'学历不限': 8}
workExperience = {'在校/应届生', '经验不限', '1-3年', '3-5年', '5-10年', '10年以上'}
salaryList = ['0-10k', '10-20k', '20-30k', '30-40k', '40k以上']
def getAllUsers():
users = User.objects.all()
for u in users:
u.createTime = str(u.createTime)[0:10]
return users
def getAlljobs():
jobs = JobInfo.objects.all()
for job in jobs:
job.createTime = str(job.createTime)[0:10]
return jobs
def getAlljobsByWork(work):
if work is not None and work != '':
jobs = list(JobInfo.objects.filter(type=work))
else:
jobs = list(JobInfo.objects.all())
for job in jobs:
job.createTime = str(job.createTime)[0:10]
return jobs
def getMapProvinceData():
mapData = {'北京市': 0,
'天津市': 0,
'河北省': 0,
'山西省': 0,
'内蒙古自治区': 0,
'辽宁省': 0,
'吉林省': 0,
'黑龙江省': 0,
'上海市': 0,
'江苏省': 0,
'浙江省': 0,
'安徽省': 0,
'福建省': 0,
'江西省': 0,
'山东省': 0,
'河南省': 0,
'湖北省': 0,
'湖南省': 0,
'广东省': 0,
'广西壮族自治区': 0,
'海南省': 0,
'重庆市': 0,
'四川省': 0,
'贵州省': 0,
'云南省': 0,
'西藏自治区': 0,
'陕西省': 0,
'甘肃省': 0,
'青海省': 0,
'宁夏回族自治区': 0,
'新疆维吾尔自治区': 0,
'台湾省': 0}
jobs = JobInfo.objects.all()
for job in jobs:
province = job.province
mapData[province] = mapData.get(province) + 1
maxData = max(mapData.values())
minData = min(mapData.values())
return mapData, maxData, minData
#getCompanyChar
import json
from RecruitDataWeb.models import JobInfo
from .getPublicData import *
def getPageData():
jobs = getAlljobs()
typeData = []
for i in jobs:
typeData.append(i.type)
return list(set(typeData))
def getCompanyBar(type):
if type == 'all':
jobs = JobInfo.objects.all()
else:
jobs = JobInfo.objects.filter(type=type)
natureData = {}
for i in jobs:
if natureData.get(i.companyNature, -1) == -1:
natureData[i.companyNature] = 1
else:
natureData[i.companyNature] += 1
natureList = list(sorted(natureData.items(), key=lambda x: x[1], reverse=True))
rowData = []
columnData = []
for k, v in natureList:
rowData.append(k)
columnData.append(v)
return rowData[:20], columnData[:20]
def getCompanyPie(type):
if type == 'all':
jobs = JobInfo.objects.all()
else:
jobs = JobInfo.objects.filter(type=type)
addressData = {}
for i in jobs:
if addressData.get(i.address, -1) == -1:
addressData[i.address] = 1
else:
addressData[i.address] += 1
result = []
for k, v in addressData.items():
result.append({
'name': k,
'value': v
})
return result[:30]
#getSalaryChar
import json
from .getPublicData import *
def getBarData():
jobs = getAlljobs()
jobsTypes = {}
for j in jobs:
if j.practice == 0:
if jobsTypes.get(j.type, -1) == -1:
jobsTypes[j.type] = [json.loads(j.salary)[1]]
else:
jobsTypes[j.type].append(json.loads(j.salary)[1])
barData = {}
for k, v in jobsTypes.items():
if not barData.get(k, 0):
barData[k] = [0 for x in range(5)]
for i in v:
s = i / 1000
if s < 10:
barData[k][0] += 1
elif 10 <= s < 20:
barData[k][1] += 1
elif 20 <= s < 30:
barData[k][2] += 1
elif 30 <= s < 40:
barData[k][3] += 1
else:
barData[k][4] += 1
legends = list(barData.keys())
if len(legends) == 0:
legends = None
return salaryList, barData, legends
五、总结
完成情况
项目实现了数据的自动化采集、清洗和预处理,并进行了统计分析和可视化展示。
用户能够通过用户界面进行查询条件的输入,获取数据分析结果,并与系统进行交互操作。
项目亮点
自动化数据采集:通过使用Selenium库,您实现了招聘网站数据的自动化采集。这个功能特色使您的系统能够自动抓取大量的招聘数据,省去了手动复制粘贴的繁琐过程,提高了数据采集的效率和准确性。
综合数据分析和可视化:系统不仅仅收集了数据,还实现了数据的清洗、预处理、统计分析和可视化展示。使用户能够通过系统获取有关招聘市场的深入洞察,并通过图表、图像等形式直观地展示数据分析结果。
灵活的用户交互和个性化查询:系统提供了用户界面,使用户能够灵活地输入查询条件,并根据自己的需求获取定制化的数据分析结果。这种个性化查询的创新点使用户能够根据自己的兴趣和目标进行数据探索,从而更好地理解和利用招聘数据。
展望进一步研究方向:
如果进一步研究,可以进行探索数据挖掘和机器学习应用、增加数据源和拓展行业覆盖范围、实现用户个性化分析和推荐、加强数据隐私和安全性、扩展数据可视化功能。这些方向将提升招聘网站数据分析与可视化系统的功能和适用性,为用户提供更准确、个性化和安全的数据洞察和服务。